linux源码分析 - 进程
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/
最近在回想一些知识点的时候,觉得对进程这一块有些模糊,特别写一篇随笔对进程信息进行巩固和复习。
程序和进程
以我个人的理解就是,程序是一段二进制编码甚至是一个简单的可执行文件,而当程序这段二进制编码放入内存运行时,它就会产生一个或多个进程。
CPU时间片
对于CPU来说,它的工作就是不停地执行指令,而由于CPU执行指令的速度非常快,它可以用5ms的时间专门用于执行进程A,5ms的时间专门用于执行进程B,5ms的时间专门用于执行进程C,然后这样不停交替执行进程A、B、C。在我们看来就像进程A、B、C在同时执行一样,而实际上同一个时间点只有一个进程正在CPU上运行。
进程描述符
就是用于描述一个进程的结构体,每个进程有且只有一个进程描述符,它里面包含了这个进程相关的所有信息。
struct task_struct {
......
/* 进程状态 */
volatile long state;
/* 指向内核栈 */
void *stack;
/* 用于加入进程链表 */
struct list_head tasks;
......
/* 指向该进程的内存区描述符 */
struct mm_struct *mm, *active_mm;
........
/* 进程ID,每个进程(线程)的PID都不同 */
pid_t pid;
/* 线程组ID,同一个线程组拥有相同的pid,与领头线程(该组中第一个轻量级进程)pid一致,保存在tgid中,线程组领头线程的pid和tgid相同 */
pid_t tgid;
/* 用于连接到PID、TGID、PGRP、SESSION哈希表 */
struct pid_link pids[PIDTYPE_MAX];
........
/* 指向创建其的父进程,如果其父进程不存在,则指向init进程 */
struct task_struct __rcu *real_parent;
/* 指向当前的父进程,通常与real_parent一致 */
struct task_struct __rcu *parent;
/* 子进程链表 */
struct list_head children;
/* 兄弟进程链表 */
struct list_head sibling;
/* 线程组领头线程指针 */
struct task_struct *group_leader;
/* 在进程切换时保存硬件上下文(硬件上下文一共保存在2个地方: thread_struct(保存大部分CPU寄存器值,包括内核态堆栈栈顶地址和IO许可权限位),内核栈(保存eax,ebx,ecx,edx等通用寄存器值)) */
struct thread_struct thread;
/* 当前目录 */
struct fs_struct *fs;
/* 指向文件描述符,该进程所有打开的文件会在这里面的一个指针数组里 */
struct files_struct *files;
........
/* 信号描述符,用于跟踪共享挂起信号队列,被属于同一线程组的所有进程共享,也就是同一线程组的线程此指针指向同一个信号描述符 */
struct signal_struct *signal;
/* 信号处理函数描述符 */
struct sighand_struct *sighand;
/* sigset_t是一个位数组,每种信号对应一个位,linux中信号最大数是64
* blocked: 被阻塞信号掩码
* real_blocked: 被阻塞信号的临时掩码
*/
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
/* 私有挂起信号队列 */
struct sigpending pending;
........
}
这里只截取了部分之后需要说明的字段。在内核中,会有一个进程链表通过使用进程描述符中的tasks结构把所有进程的进程链表链接起来。
进程内核栈
我们在编程的时候知道,在进程地址空间中有个栈,用于程序的顺利执行,而当程序陷入内核态之后,就不能够使用应用态的栈了,所以,对于每个进程(准确说是对于每个线程),它在内核中也有一个内核态的栈区,在内核中,把栈和thread_info(线程描述符)结构结合起来放在一起,这块存储区域通常为8192字节,也就是两个页框。thread_info结构大小为52字节,也就是说,进程的可用的栈大小为8140个字节。因为进程在内核态中所需要执行的代码量并不算多,所以这个8K的内核栈已经足够使用。在编译内核时也可以设置整个内核栈为一个页框大小(4KB),不过在这种情况下,内核在处理硬中断和软中断时就不使用进程的内核栈栈,而是使用额外的两个个栈:硬中断请求栈(每个CPU一个,大小4K),软中断请求栈(每个CPU一个,大小4K)。不过值得注意的是,在进行异常处理时还是会使用进程的内核栈。
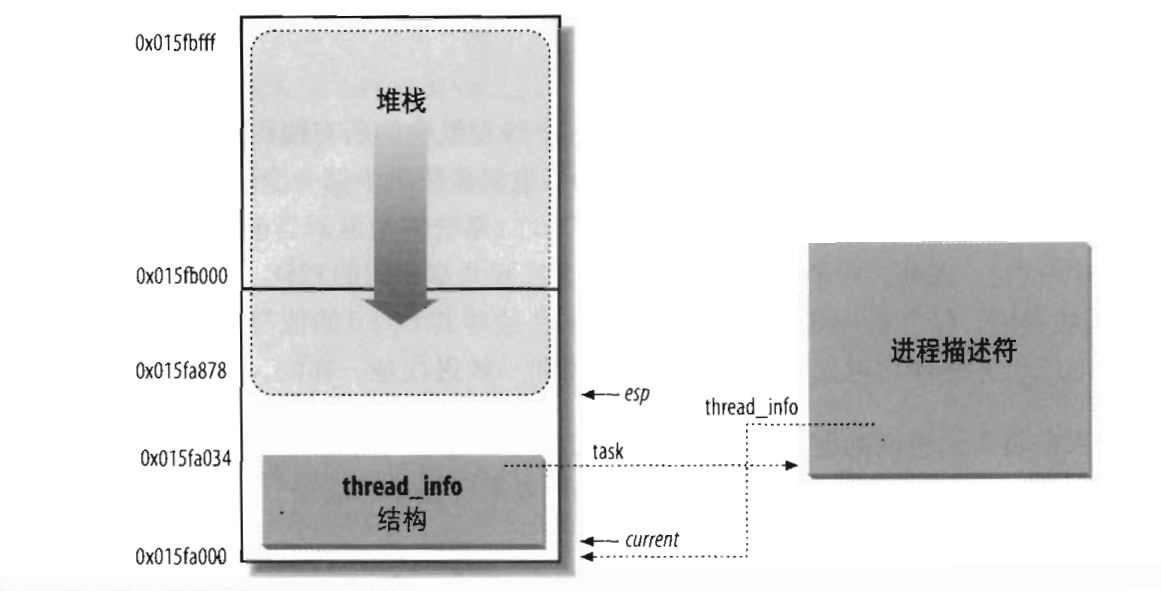
如上图可以看到,进程的内核栈是向下增长的,也就是栈底在高位地址,栈顶在低位地址。对于这个内核栈的作用,我们可以总结一下:
- 进程陷入内核后用于代替应用层的栈区进行使用。
- 中断发生时用于保存进程上下文现场,并且用于中断嵌套的现场保存和返回。
- 当发生进程切换时,部分寄存器的值会保存在进程的内核栈中。
- thread_info中保存着一些重要的字段用于维持进程的正常运行。
轻量级进程
linux使用轻量级进程对多线程应用提供支持,其实它的创建也是基于fork()系统调用,只是在进程描述符的初始化当中有所区别。首先,轻量级进程也是一个进程,它有它自己的pid,有它自己的内核栈和进程描述符,甚至还有它自己的调度策略,而轻量级进程和普通进程不同的就是它没有自己的进程地址空间,并且要响应线程组内其他线程接收到的信号(但可以通过修改信号屏蔽字屏蔽某些信号)。轻量级进程使用的是父进程的内存地址空间,也就是在task_struct结构中的mm和active_mm指针都指向父进程的mm指针所指地址。而信号描述符指针signal会指向父进程指向的地址。而在应用层,线程有自己的栈,我想这个应该是由glibc实现的。
轻量级进程和普通进程区别:
- 没有自己的进程地址空间,使用父进程的进程地址空间
- 与组内所有进程共享信号,但有自己的信号屏蔽字
进程状态
- TASK_RUNNING:可运行状态,进程要么在CPU上执行,要么准备执行。
- TASK_INTERRUPTIBLE:可中断的等待状态,进程被挂起(睡眠),直到某个条件为真,产生一个硬中断、释放进程正等待的系统资源、或传递一个信号都是可以唤醒进程的条件。
- TASK_UNINTERRUPTIBLE:不可中断的等待状态,与可中断等待状态类似,只是不能被信号唤醒。在一些特殊情况下会使用,例如:当进程打开一个设备文件,设备驱动会开始探测相应的硬件时会用到这种状态。
- TASK_STOPED:暂停状态,当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU信号后进入。
- TASK_TRACED:跟踪状态,进程执行由debugger程序暂停,当一个进程被另一个进程监控时,任何信号都可以把这个进程置于TASK_TRACED状态。
还有两个状态是既可以存放在进程描述符的state字段中,也可以存放在exit_state字段中。从这两个字段可以看出,只有当进程执行被终止时,进程的状态才会为这两种状态中的一种:
- EXIT_ZOMBIE:僵死状态,进程将被终止,但父进程还没有发布wait4()或者waitpid()系统调用来返回关于死亡进程的信息。发布wait()类系统调用之前,内核不能丢弃包含在死进程描述符中的数据,因为父进程可能还需要它。
- EXIT_DEAD:僵死撤销状态,进程被终止后的最终状态,父进程发布wait4()或者waitpid()系统调用后,内核删除此进程描述符。
对于一个普通进程,它的执行状态如下图所示:
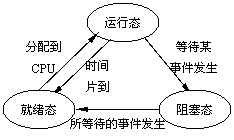
我们使用一个简单地例子说明这种状态的转变,我们有个程序A,它的工作就是做一些计算,然后把计算结构写入磁盘文件中。我们在shell中运行它,起初它就是TASK_RUNNING状态,也就是运行态,CPU会不停地分配时间片供我们的进程A运行,每次时间片耗尽后,进程A都会转变到就绪态(实际上还是TASK_RUNNING状态,只是此时在等待CPU分配时间片,暂时不在CPU上运行)。当进程A使用fwrite或write将数据写入磁盘文件时,就会进入阻塞态(TASK_INTERRUPTIBLE状态),而磁盘将数据写入完毕后,会通过一个中断告知内核,内核此时会将进程A的状态由阻塞态(TASK_INTERRUPTIBLE)转变为就绪态(TASK_RUNNING)等待CPU分配时间片运行。而最后当进程A需要退出时,内核先会将其设置为僵死状态(EXIT_ZOMBIE),这时候它所使用的内存已经被释放,只保留了一个进程描述符供父进程使用,最后当父进程(也就是我们起初启动它的shell)通过wait()类系统调用通知内核后,内后会将进程A设置为僵死撤销状态(EXIT_DEAD),并释放其进程描述符。到这里进程A的整个运行周期完整结束。
PID和tgid字段
PID是一个数字,用于标识一个进程,就像学生的学号一样,每个进程都有一个唯一的编号,保存在进程描述符的pid字段中。一般的,在系统运行期间,PID都是被顺序编号,比如进程A的PID为10,那下个创建的进程的PID则为11。不过PID的值有一个上限,当内核使用的PID达到这个上限后就会循环开始找已闲置的小PID号。在缺省状态下,最大PID值为32767(PID_MAX_DEFAULT - 1);可以通过修改/proc/sys/kernel/pid_max这个文件来减小PID上限值。而在64位系统中,PID可扩大到4194303。
内核是通过一个叫pidmap的位图来管理已分配的PID号和闲置的PID号。在32位系统中,pidmap的大小就是一个页框的大小(4KB),而一个页框大小为32768位,也就是每一位代表一个PID号,1代表此PID已经被分配,0代表此PID号未被使用;而在64位系统下,pidmap会使用多个页框。
在POSIX标准中规定了一个多线程应用程序中所有的线程都必须有相同的PID,在linux内核中,是使用轻量级进程实现线程的功能,但是轻量级进程也是一个进程,他们的PID都不相同,为了实现这一点,内核在进程描述符中引入了tgid字段。在linux的线程组概念中,一个线程组中所有线程使用的该线程组领头线程相同的PID,也就是该组第一个轻量级进程的PID,并保存到进程描述符的tgid字段中,如下图:
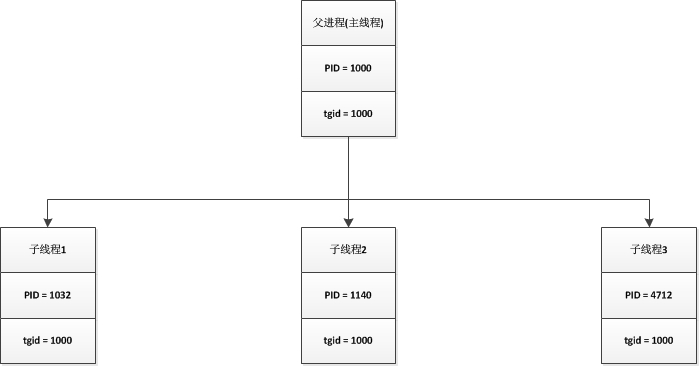
在编程过程中,我们使用的getpid()函数返回的值其实是当前进程的tgid而不是pid的值,而由于线程组中领头线程和pid和tgid相同,因而getpid()对这类进程所起到的作用和一般进程是一样的。
接下来说说内核如何将所有的PID和进程描述符组织在一起,方便系统查找和使用。在系统运行过程中,可能会有成百上千的进程在运行,这时候进程的查找效率就至关重要了,比如系统管理员使用kill 1024命令去终止PID=1024的进程,内核会从这个PID导出对应的进程描述符进行处理。内核为了提高查找效率,专门使用了4个哈希表用于索引进程描述符。为什么要4个,因为我们可以用pid、tgid、pgrp、session去找进程,这几个哈希表说明如下:

在内核中,这四个哈希表一共占16个页框,也就是每个哈希表占4个页框,他们每个可以拥有2048个表项,内核会把把这四个哈希表的地址保存到pid_hash数组中。现在问题来了,拿pid的哈希表为例,怎么在2048个表项中保存32767个PID值,其实内核会对每个已经分配的PID值进行一个处理,得到的结果的数值就是对应的表项,处理结果相同的PID被串成一个链表,如下:
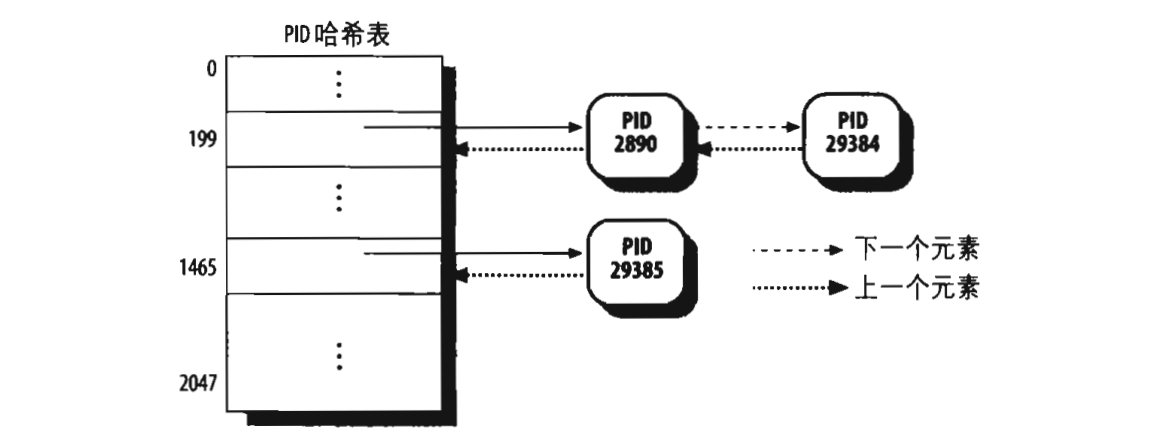
当我们使用kill 29384命令时,内核会根据29384处理得出199,然后以199为下标,获取PID哈希表中对应的链表头,并在此链表中找出PID=29384的进程。进程描述符中使用struct pid_link pids[PIDTYPE_MAX]链入这四个哈希表。对于另外三个哈希表,道理一样。
进程间关系
在系统中,除了进程0,一个进程是由另一个进程创建,它们都具有父子关系。如果一个进程创建多个子进程,则子进程之间有兄弟关系。在整个系统启动期间,会初始化系统的第一个进程init_task,这个进程属于内核中的一个进程,它算是所有进程的祖先,之后它会启动PID为1的init进程和PID为2的kthreadd,这两个进程之后启动的所有进程,而init_task之后会转变为一个idle进程用于CPU空闲时运行。在进程描述符中,使用real_parent、parent、children、sibling这几个指针将进程关系组织在一起,我们看看这几个指针的说明:

而如果一个进程P0创建了进程P1、P2、P3,进程P3又创建了进程P4,它们整个链表情况是这样的
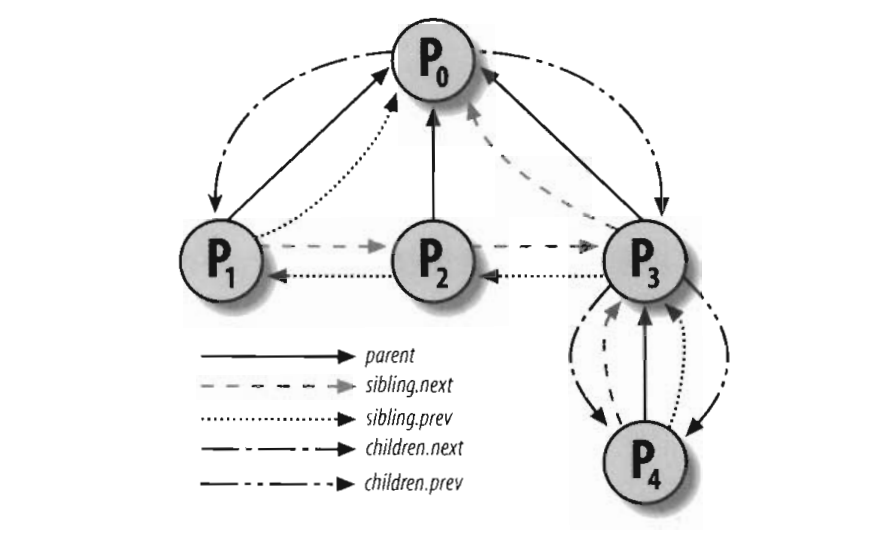
组织进程
所有处于TASK_RUNNING状态的进程都会被放入CPU的运行队列,它们有可能在不同CPU的运行队列中。
系统没有为TASK_STOPED、EXIT_ZOMBIE和EXIT_DEAD状态的进程建立专门的链表,因为处于这些状态的进程访问比较简单,可通过PID和通过特定父进程的子进程链表进行访问。
所有TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE都会被放入相应的等待队列,系统中有很多种等待队列,有些是等待磁盘操作的终止,有些是等待释放系统资源,有些是等待时间经过固定的间隔,每个等待队列它的唤醒条件不同,比如等待队列1是等待系统释放资源A的,等待队列2是等待系统释放资源B的。因此,等待队列表示一组睡眠进程,当某一条件为真时,由内核唤醒这条等待队列上的进程。我们看看内核中一个简单的sleep_on()函数:
/* wq为某个等待队列的队列头 */
void sleep_on (wait_queue_head_t *wq)
{
/* 声明一个等待队列结点 */
wait_queue_t wait; /* 用当前进程初始化这个等待队列结点 */
init_waitqueue_entry (&wait, current); /* 设置当前进程状态为TASK_UNINTERRUPTIBLE */
current->state = TASK_UNINTERRUPTIBLE; /* 将这个代表着当前进程的等待队列结点加入到wq这个等待队列 */
add_wait_queue (wq, &wait); /* 请求调度器进行调度,执行完schedule后进程会被移除CPU运行队列,只有等待队列唤醒后才会重新回到CPU运行队列 */
schedule (); /* 这里进程已经被等待队列唤醒,重新移到CPU运行队列,也就是等待的条件已经为真,唤醒后第一件事就是将自己从等待队列wq中移除 */
remove_wait_queue (wq, &wait);
}
这时候又有一个问题,比如有等待队列是等待系统释放资源A,而等待队列中所有的进程都是希望能够占有这个资源A的,就像我们编程中用到的信号量,这时候系统的做法不是将这个等待队列中所有的进程都进行唤醒,而是只唤醒一个。内核区分这种互斥进程的原理就是这个等待队列中所有的等待队列结点wait_queue_t中的flags被设置为1(默认是0)。
linux源码分析 - 进程的更多相关文章
- 鸿蒙内核源码分析(进程概念篇) | 进程在管理哪些资源 | 百篇博客分析OpenHarmony源码 | v24.01
百篇博客系列篇.本篇为: v24.xx 鸿蒙内核源码分析(进程概念篇) | 进程在管理哪些资源 | 51.c.h .o 进程管理相关篇为: v02.xx 鸿蒙内核源码分析(进程管理篇) | 谁在管理内 ...
- 鸿蒙内核源码分析(进程管理篇) | 谁在管理内核资源 | 百篇博客分析OpenHarmonyOS | v2.07
百篇博客系列篇.本篇为: v02.xx 鸿蒙内核源码分析(进程管理篇) | 谁在管理内核资源 | 51.c.h .o 进程管理相关篇为: v02.xx 鸿蒙内核源码分析(进程管理篇) | 谁在管理内核 ...
- linux源码分析2
linux源码分析 这里使用的linux版本是4.8,x86体系. 这篇是 http://home.ustc.edu.cn/~boj/courses/linux_kernel/1_boot.html ...
- Linux 源码阅读 进程管理
Linux 源码阅读 进程管理 版本:2.6.24 1.准备知识 1.1 Linux系统中,进程是最小的调度单位: 1.2 PCB数据结构:task_struct (Location:linux-2. ...
- 鸿蒙内核源码分析(进程镜像篇)|ELF是如何被加载运行的? | 百篇博客分析OpenHarmony源码 | v56.01
百篇博客系列篇.本篇为: v56.xx 鸿蒙内核源码分析(进程映像篇) | ELF是如何被加载运行的? | 51.c.h.o 加载运行相关篇为: v51.xx 鸿蒙内核源码分析(ELF格式篇) | 应 ...
- 鸿蒙内核源码分析(进程回收篇) | 老父亲如何向老祖宗临终托孤 ? | 百篇博客分析OpenHarmony源码 | v47.01
百篇博客系列篇.本篇为: v47.xx 鸿蒙内核源码分析(进程回收篇) | 临终前如何向老祖宗托孤 | 51.c.h .o 进程管理相关篇为: v02.xx 鸿蒙内核源码分析(进程管理篇) | 谁在管 ...
- 鸿蒙内核源码分析(进程通讯篇) | 九种进程间通讯方式速揽 | 百篇博客分析OpenHarmony源码 | v28.03
百篇博客系列篇.本篇为: v28.xx 鸿蒙内核源码分析(进程通讯篇) | 九种进程间通讯方式速揽 | 51.c.h .o 进程通讯相关篇为: v26.xx 鸿蒙内核源码分析(自旋锁篇) | 自旋锁当 ...
- Linux源码分析之:malloc、free
之前写代码的时候一直有个疑问,malloc申请内存的时候指定了内存大小,但是free的时候却只指定要释放的内存地址,那么free是如何知道它要释放的内存空间大小呢? 源码之前,了无秘密,下面就从源码来 ...
- linux源码分析(五)-start_kernel
前置:这里使用的linux版本是4.8,x86体系. local_irq_disable(); 这个函数是做了关闭中断操作.和后面的local_irq_enable相对应.说明启动的下面函数是不允许被 ...
随机推荐
- 2018-01-03 烂尾工程: Java实现的汇编语言编译器
在半年前的中文编程的尝试历程小记中简单介绍了这一项目. 由于短期内估计不会继续进行, 而且这个项目好像是至今个人在中文命名实践中的代码量最大的一个项目, 谨在此作一小结. 最新的源码库在program ...
- 访问WEB-INF下的jsp页面
访问web-inf下的jsp文件, 1)使用springMVC,一般都会使用springMVC的视图解析器,大概会这样配置 <!--jsp视图解析器--> <bean class ...
- 函数节流scroll,兼容火狐滚轮事件
//函数节流 var wheelTimeout; var wheelFun = function (func) { if (wheelTimeout) { return; } func(); whee ...
- filter(ele)过滤数组
filter也是一个常用的操作,它用于把Array的某些元素过滤掉,然后返回剩下的元素. 例如,在一个Array中,删掉偶数,只保留奇数,可以这么写: function remove(arr) { l ...
- ArcGIS JavaScript API动态图层
矢量动态图层 <!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Typ ...
- 导入数据到MongoDB中
import sys import json import pymongo import datetime from pymongo import MongoClient client = Mongo ...
- android.support不统一的问题
今天supprt28遇到的问题,由于28还是预览版,还存在一些bug 都是因为如果程序内出现不同的,support或者其他外部引用库的多个版本,Gradle在进行合并的时候会使用本地持有的,最高版本的 ...
- Java并发编程(十三)线程间协作的两种方式:wait、notify、notifyAll和Condition
在现实中,需要线程之间的协作.比如说最经典的生产者-消费者模型:当队列满时,生产者需要等待队列有空间才能继续往里面放入商品,而在等待的期间内,生产者必须释放对临界资源(即队列)的占用权.因为生产者如果 ...
- Expo大作战(三十七)--expo sdk api之 GLView,GestureHandler,Font,Fingerprint,DeviceMotion,Brightness
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与官网 我猜去全部机翻+个人 ...
- account
Account Doc V3_ADD 1. 用户头像 用户头像今后会放在阿里云上,所以: dev: http(s)://pyserver.oss-cn-hangzhou.aliyuncs.com/DE ...