走进JDK(二)------String
本文基于java8.
基本概念:
- Jvm 内存中 String 的表示是采用 unicode 编码
- UTF-8 是 Unicode 的实现方式之一
一、String定义
public final class String implements java.io.Serializable, Comparable<String>, CharSequence
String是个final类,不允许继承。并且实现了Serializable, Comparable<String>, CharSequence接口
- java.io.Serializable
这个序列化接口没有任何方法和域,仅用于标识序列化的语意。
- Comparable<String>
这个接口只有一个compareTo(T 0)接口,用于对两个实例化对象比较大小。
- CharSequence
这个接口是一个只读的字符序列。包括length(), charAt(int index), subSequence(int start, int end)这几个API接口,值得一提的是,StringBuffer和StringBuild也是实现了改接口。
二、主要成员变量
//String的底层是一个字符数组,并且为private final,决定了String一旦创建,无法通过方法去改变该String对象的值
private final char value[];
//hash是String实例化的hashcode的一个缓存。因为String经常被用于比较,比如在HashMap中。如果每次进行比较都重新计算hashcode的值的话,那无疑是比较麻烦的,而保存一个hashcode的缓存无疑能优化这样的操作。
private int hash;
//Java的序列化机制是通过判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,
否则就会出现序列化版本不一致的异常,即是InvalidCastException。
private static final long serialVersionUID = -6849794470754667710L;
三、构造函数
public String() {
this.value = "".value;
}
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
//当传入char[]时,通过Arrays.copyOf()复制该数组给到Stirng的成员变量value[]中
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
//传入char[],可以自定义起始位置,元素个数
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
//也可以传入byte[],并且指定起始位置,长度以及编码类型
public String(byte bytes[], int offset, int length, Charset charset) {
if (charset == null)
throw new NullPointerException("charset");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charset, bytes, offset, length);
}
//也可以传入byte[],并且指定起始位置,长度
public String(byte bytes[], int offset, int length) {
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
总之,String提供的构造函数可以将String、char[]、byte[]、StringBuffer、StringBuilder等多种参数类型的初始化方法。但本质上,其实就是将接收到的参数传递给全局变量value[]。
四、length()、isEmpty()、charAt()
//返回当前字符串的字符数量
public int length() {
return value.length;
}
//判断字符串为空的方法就是判断字符数组的长度是否为0
public boolean isEmpty() {
return value.length == 0;
}
//根据对应的index获取char
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
//根据指定的编码格式,将String转换成byte[]
public byte[] getBytes(String charsetName) throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, value, 0, value.length);
}
public byte[] getBytes(Charset charset) {
if (charset == null) throw new NullPointerException();
return StringCoding.encode(charset, value, 0, value.length);
}
//得到一个操作系统默认的编码格式的字节数组
public byte[] getBytes() {
return StringCoding.encode(value, 0, value.length);
}
五、equals()、compareTo()
1、equals()
public boolean equals(Object anObject) {
//如果引用的是同一个对象,自然是相等的
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = ;
//挨个字符进行比较
while (n-- != ) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
2、compareTo()
//compareTo():
//1、当当前String对象<入参,返回-1
//2、当前String对象=入参,返回0
//3、当前String对象>入参,返回1
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
//取两个String中较小的长度
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value; int k = ;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
//当出现第一个不同字符的时候,比较大小
if (c1 != c2) {
return c1 - c2;
}
k++;
}
//如果在规定的长度内,两个字符串一致,则比较字符串的长度
return len1 - len2;
}
六、hashCode()、getBytes()
public int hashCode() {
//hash用于保存当前字符串的hash值
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
//为啥乘以31?主要是因为31是一个奇质数,所以31*i=32*i-i=(i<<5)-i,这种位移与减法结合的计算相比一般的运算快很多。
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
getBytes()的实现主要有以下几种:
//按照给定的字符编码返回对应的字节数组
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, value, 0, value.length);
} public byte[] getBytes(Charset charset) {
if (charset == null) throw new NullPointerException();
return StringCoding.encode(charset, value, 0, value.length);
}
//按照系统默认编码方式进行
public byte[] getBytes() {
return StringCoding.encode(value, 0, value.length);
}
七、intern()
public native String intern();
作用:将该字符串人工写入到字符串常量池。
先来看一组面试当中经常会出现的,如下:
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel" + new String("lo");
String s5 = new String("Hello");
String s6 = s5.intern();
String s7 = "H";
String s8 = "ello";
String s9 = s7 + s8; System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // true
System.out.println(s1 == s4); // false
System.out.println(s1 == s9); // false
System.out.println(s4 == s5); // false
System.out.println(s1 == s6); // true
在java中,给String赋值主要有两种方式:
//一、直接字面量进行赋值
String str = "Hello";
//二、通过new关键字创建一个String对象
String str = new String("Hello");
再来看一下jvm中的内存模型:
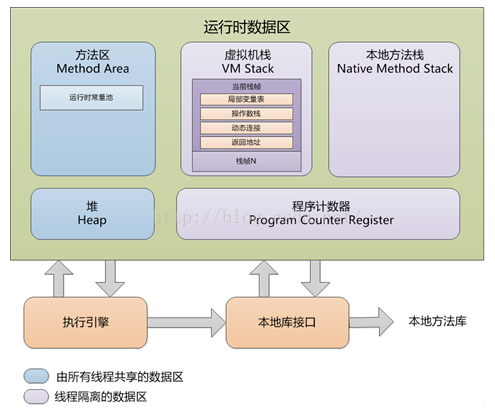
先说第二种方式,由于是new一个对象,无可厚非,先在堆中开辟一块空间,然后创建一个String对象,并且在需要使用此对象的地方保存一个引用,指向堆中的位置。
而由于String又是不可改变的,自然就会想到利用缓存的概念。试想如果一段代码或是一个jvm中有一万个String str = "阿里马云";难道要在堆中保存一万个对象吗?很明显这种设计是比较low的。因此jvm对于字面量声明的方式,在堆中创建字符串,
、然后将字符串的引用存放在方法区的字符串常量池中,也就是说如果都是String str = "阿里马云";的声明方式,那么整个jvm中只会有一个对象存放在堆中,常量池中保存该对象的引用。
ok,那么上面的面试题就可以一题题来解释了
1、s1、s2都是字面量声明,是一个对象,true
2、s3则是两个字面量拼接而成,编译器会进行优化(编译器优化的目的只有一个,就是提高性能),在编译时s3就变成“Hello”了,所以s1==s3。
3、s4虽然也是拼接,但“lo”是通过new关键字创建的,在编译期无法知道它的地址,所以不能像s3一样优化。所以必须要等到运行时才能确定,必然新对象的地址和前面的不同。
4、同理,s9由两个变量拼接,编译期也不知道他们的具体位置,不会做出优化。
5、s5是new出来的,在堆中的地址肯定和s4不同。
6、s6利用intern()方法得到了s5在字符串池的引用,并不是s5本身的地址。由于它们在字符串池的引用都指向同一个“Hello”对象,自然s1==s6。
总结:
- 字面量创建字符串会先在字符串池中找,看是否有相等的对象,没有的话就在堆中创建,把地址驻留在字符串池;有的话则直接用池中的引用,避免重复创建对象。
- new关键字创建时,在运行时会创建一个新对象,变量所引用的都是这个新对象的地址。
其他还有类似indexOf、substring等相对简单,不补充说明了
走进JDK(二)------String的更多相关文章
- JDK中String类的源码分析(二)
1.startsWith(String prefix, int toffset)方法 包括startsWith(*),endsWith(*)方法,都是调用上述一个方法 public boolean s ...
- 调试过程中发现按f5无法走进jdk源码
debug 模式 ,在fis=new FileInputStream(file); 行打断点 调试过程中发现按f5无法走进jdk源码 package com.lzl.spring.test; impo ...
- 走进JDK(十二)------TreeMap
一.类定义 TreeMap的类结构: public class TreeMap<K,V> extends AbstractMap<K,V> implements Navigab ...
- 走进JDK(十)------HashMap
有人说HashMap是jdk中最难的类,重要性不用多说了,敲过代码的应该都懂,那么一起啃下这个硬骨头吧!一.哈希表在了解HashMap之前,先看看啥是哈希表,首先回顾下数组以及链表数组:采用一段连续的 ...
- 走进JDK(一)------Object
阅读JDK源码也是一件非常重要的事情,尤其是使用频率最高的一些类,通过源码可以清晰的清楚其内部机制. 如何阅读jdk源码(基于java8)? 首先找到本地电脑中的jdk安装路径,例如我的就是E:\jd ...
- 走进JDK(九)------AbstractMap
map其实就是键值对,要想学习好map,得先从AbstractMap开始. 一.类定义.构造函数.成员变量 public abstract class AbstractMap<K,V> i ...
- 走进JDK(八)------AbstractSet
说完了list,再说说colletion另外一个重要的子集set,set里不允许有重复数据,但是不是无序的.先看下set的整个架构吧: 一.类定义 public abstract class Abst ...
- 走进JDK(四)------InputStream、OutputStream、Reader、Writer
InputStream InputStream是java中的输入流,下面基于java8来分析下InputStream源码 一.类定义 public abstract class InputStream ...
- 走进JDK(三)------AbstractStringBuilder、StringBuffer、StringBuilder
AbstractStringBuilder是一个抽象类,StringBuffer.StringBuilder则继承AbstractStringBuilder,所以先说AbstractStringBui ...
随机推荐
- 20165312 2017-2018-2《Java程序设计》第9周学习总结
20165312 2017-2018-2<Java程序设计>第9周学习总结 上周错题总结 1.进程的基本状态有:新建.运行.阻塞.死亡. A . true B . false 解析:A 这 ...
- 查询 SQL_Server 所有表的记录数: for xml path
--我加了 top 10 用的时候可以去掉 declare @select_alltableCount varchar(max)='';with T as (select top 10 'SELECT ...
- C语言数据结构基础学习笔记——栈和队列
之前我们学过了普通的线性表,接下来我们来了解一下两种特殊的线性表——栈和队列. 栈是只允许在一端进行插入或删除的线性表. 栈的顺序存储结构也叫作顺序栈,对于栈顶指针top,当栈为空栈时,top=-1: ...
- Android Studio设置连续按两次退出APP
主要是在onKeyDown方法中进行操作,直接上代码. private long mTime; @Override public boolean onKeyDown(int keyCode, KeyE ...
- 【.NET架构】BIM软件架构01:Revit插件产品架构梳理
一.前言 BIM:Building Information Modeling 建筑信息模型,就是将建筑的相关信息附着于模型中,以管理该建筑在设计.算量.施工.运维全生命周期的情况.创建模 ...
- python 的序列化和反序列化
什么是序列化?简单来说就是将数据存储到物理内存上的过程叫序列化. 什么是反序列化?将数据从物理内存存储到程序内存的过程叫做反序列化. 下面来看一下python中使用json进行序列化和反序列化的实例d ...
- Servlet的几个关键知识点
1.ServletConfig ServletConfig是Servlet的配置文件.对应于web.xml中的<servlet></servlet>标签.ServletConf ...
- py库:把python打包成exe文件(pyinstaller)
http://blog.csdn.net/be_quiet_endeavor/article/details/73929077 用Pyinstaller把Python3.4程序打包成可执行文件exe ...
- mysql 5.7 配置
MySQL安装文件分为两种,一种是msi格式的,一种是zip格式的.如果是msi格式的可以直接点击安装. zip格式是自己解压,解压缩之后其实MySQL,配置完就可以使用了. 1,配置环境变量很简单: ...
- Python : *args和**kwargs是什么东东呢?
def foo(*args, **kwargs): print 'args = ', args print 'kwargs = ', kwargs print '------------------- ...