sklearn LDA降维算法
sklearn LDA降维算法
LDA(Linear Discriminant Analysis)线性判断别分析,可以用于降维和分类。其基本思想是类内散度尽可能小,类间散度尽可能大,是一种经典的监督式降维/分类技术。
sklearn代码实现
#coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import numpy as np
def main():
iris = datasets.load_iris() #典型分类数据模型
#这里我们数据统一用pandas处理
data = pd.DataFrame(iris.data, columns=iris.feature_names)
data['class'] = iris.target
#这里只取两类
# data = data[data['class']!=2]
#为了可视化方便,这里取两个属性为例
X = data[data.columns.drop('class')]
Y = data['class']
#划分数据集
X_train, X_test, Y_train, Y_test =train_test_split(X, Y)
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X_train, Y_train)
#显示训练结果
print lda.means_ #中心点
print lda.score(X_test, Y_test) #score是指分类的正确率
print lda.scalings_ #score是指分类的正确率
X_2d = lda.transform(X) #现在已经降到二维X_2d=np.dot(X-lda.xbar_,lda.scalings_)
#对于二维数据,我们做个可视化
#区域划分
lda.fit(X_2d,Y)
h = 0.02
x_min, x_max = X_2d[:, 0].min() - 1, X_2d[:, 0].max() + 1
y_min, y_max = X_2d[:, 1].min() - 1, X_2d[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = lda.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
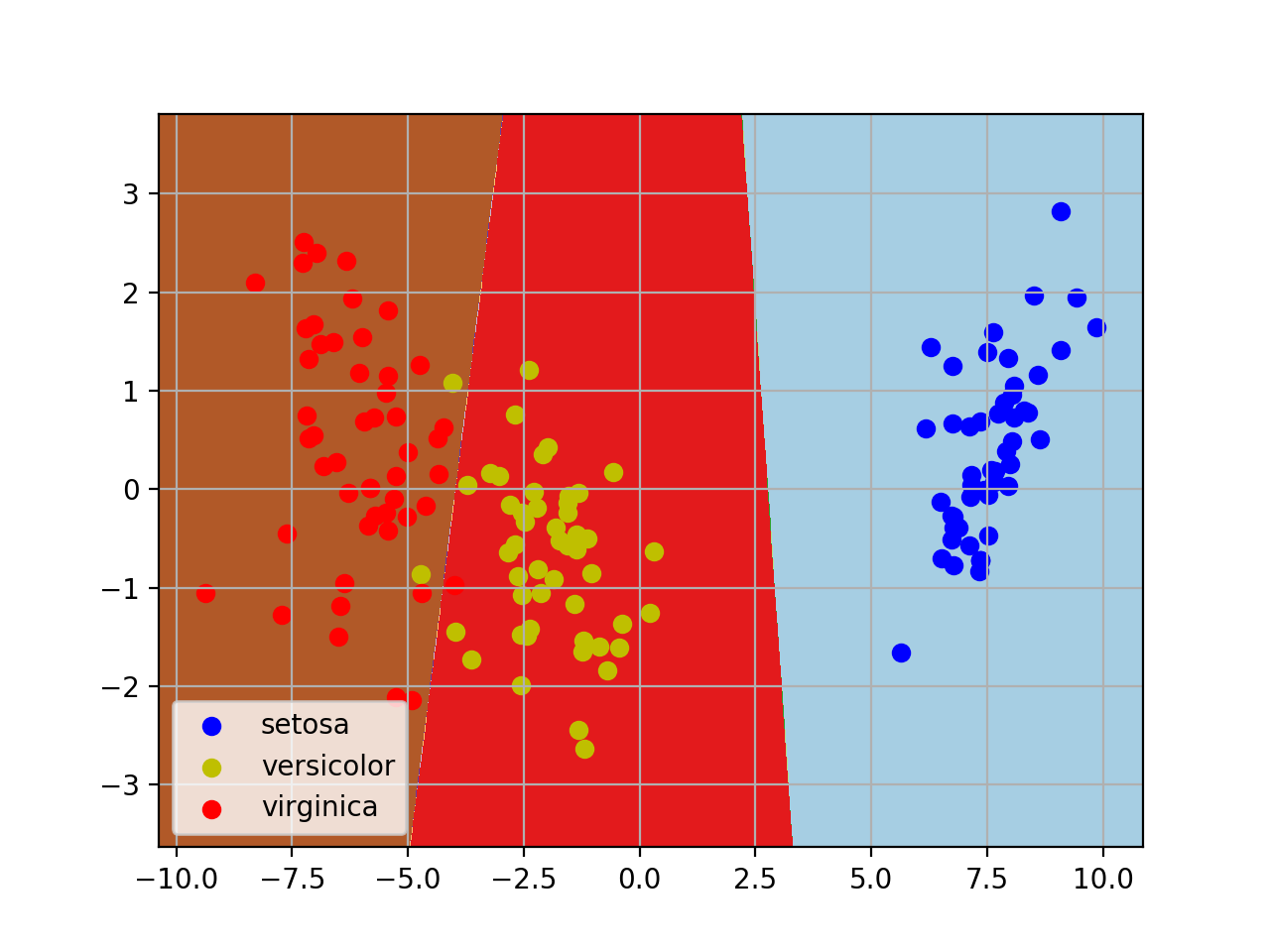
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
#做出原来的散点图
class1_x = X_2d[Y==0,0]
class1_y = X_2d[Y==0,1]
l1 = plt.scatter(class1_x,class1_y,color='b',label=iris.target_names[0])
class1_x = X_2d[Y==1,0]
class1_y = X_2d[Y==1,1]
l2 = plt.scatter(class1_x,class1_y,color='y',label=iris.target_names[1])
class1_x = X_2d[Y==2,0]
class1_y = X_2d[Y==2,1]
l3 = plt.scatter(class1_x,class1_y,color='r',label=iris.target_names[2])
plt.legend(handles = [l1, l2, l3], loc = 'best')
plt.grid(True)
plt.show()
if __name__ == '__main__':
main()
测试结果
Means: #各类的中心点
[[ 5.00810811 3.41891892 1.44594595 0.23513514]
[ 6.06410256 2.80769231 4.32564103 1.33589744]
[ 6.61666667 2.97222222 5.63055556 2.02777778]]
Score: #对于测试集的正确率
0.973684210526
Scalings:
[[ 1.19870893 0.76465114]
[ 1.20339741 -2.46937995]
[-2.55937543 0.42562073]
[-2.77824826 -2.4470865 ]]
Xbar:
[ 5.89285714 3.0625 3.79375 1.19464286]
#X'=np.dot(X-lda.xbar_,lda.scalings_)默认的线性变化方程
sklearn LDA降维算法的更多相关文章
- 机器学习实战基础(二十):sklearn中的降维算法PCA和SVD(一) 之 概述
概述 1 从什么叫“维度”说开来 我们不断提到一些语言,比如说:随机森林是通过随机抽取特征来建树,以避免高维计算:再比如说,sklearn中导入特征矩阵,必须是至少二维:上周我们讲解特征工程,还特地提 ...
- 降维算法整理--- PCA、KPCA、LDA、MDS、LLE 等
转自github: https://github.com/heucoder/dimensionality_reduction_alo_codes 网上关于各种降维算法的资料参差不齐,同时大部分不提供源 ...
- 参考:菜菜的sklearn教学之降维算法.pdf!!
PCA(主成分分析法) 1. PCA(最大化方差定义或者最小化投影误差定义)是一种无监督算法,也就是我们不需要标签也能对数据做降维,这就使得其应用范围更加广泛了.那么PCA的核心思想是什么呢? 例如D ...
- 四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
四大机器学习降维算法:PCA.LDA.LLE.Laplacian Eigenmaps 机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中.降维的本质是学习一个映 ...
- ML: 降维算法-LDA
判别分析(discriminant analysis)是一种分类技术.它通过一个已知类别的“训练样本”来建立判别准则,并通过预测变量来为未知类别的数据进行分类.判别分析的方法大体上有三类,即Fishe ...
- 【转】四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
最近在找降维的解决方案中,发现了下面的思路,后面可以按照这思路进行尝试下: 链接:http://www.36dsj.com/archives/26723 引言 机器学习领域中所谓的降维就是指采用某种映 ...
- 机器学习实战基础(二十三):sklearn中的降维算法PCA和SVD(四) PCA与SVD 之 PCA中的SVD
PCA中的SVD 1 PCA中的SVD哪里来? 细心的小伙伴可能注意到了,svd_solver是奇异值分解器的意思,为什么PCA算法下面会有有关奇异值分解的参数?不是两种算法么?我们之前曾经提到过,P ...
- 机器学习实战基础(二十一):sklearn中的降维算法PCA和SVD(二) PCA与SVD 之 降维究竟是怎样实现
简述 在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响.同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或 ...
- 用scikit-learn进行LDA降维
在线性判别分析LDA原理总结中,我们对LDA降维的原理做了总结,这里我们就对scikit-learn中LDA的降维使用做一个总结. 1. 对scikit-learn中LDA类概述 在scikit-le ...
随机推荐
- SQLServer索引及统计信息
索引除了提高性能,还能维护数据库. 索引是一种存储结构,主要以B-Tree形式存储信息. B-Tree的定义: 1.每个节点最多只有m个节点(m>=2) 2.除了根节点和叶子节点外的每个节点上最 ...
- FormsAuthenticationTicket
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.We ...
- Faster-RCNN tensorflow 程序细节
tf-faster-rcnn github:https://github.com/endernewton/tf-faster-rcnn backbone,例如vgg,conv层不改变feature大小 ...
- .Net core2.0+Mysql5.7部署到CentOS7.5完整实践经验
本文为本人最近学习将.Net Core部署到Linux的一些经验总结,也提供点也和我一样对Linux接触不多的.Net Core开发者. 一.部署用到的环境和工具 1.Linux采用最新的CentOS ...
- 【AtCoder】AGC014
AGC014 链接 A - Cookie Exchanges 发现两个数之间的差会逐渐缩小,所以只要不是三个数都相同,那么log次左右一定会得到答案 #include <bits/stdc++. ...
- @+id/和android:id有什么区别?
Any View object may have an integer ID associated with it, to uniquely identify the View within the ...
- Python_subprocess模块
subprocess中,允许生成新的进程,连接到input/output/error管道,并获取他们的返回(状态)码,主要用于替换os.system/os.spawn*几个旧的模块和方法 subpro ...
- php5.6安装redis各个版本地址集合
igbinary扩展 http://windows.php.net/downloads/pecl/releases/igbinary/2.0.1/ redis扩展 http://windows.php ...
- 003 python中的内置函数
一:如何查看内置函数 1.命令 dir(__builtins__) 2.效果 二:具体的用法 1.input 简单使用: 2.type 返回变量的类型 3.str 将类型转变为字符串 4.isinst ...
- day70 cookie & session 前后端交互分页显示
本文转载自qimi博客,cnblog.liwenzhou.com 概要: 我们的cookie是保存在浏览器中的键值对 为什么要有cookie? 我们在访问浏览器的时候,千万个人访问同一个页面,我们只要 ...