【Selenium + Python】之 Excel、CSV、XML文件读取数据并运用数据百度查询
目录
一、从Excel读取数据进行百度搜索
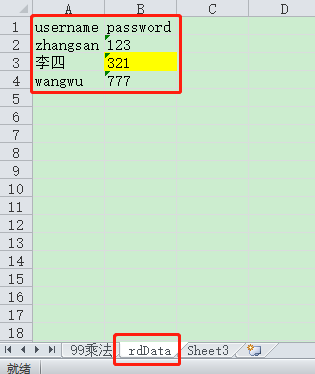
封装读取方法:
import xlrd
from selenium import webdriver
from selenium.webdriver.common.by import By class rdExcel():
def __init__(self,excel_dir,sheet_name):
self.r = []
self.rd = xlrd.open_workbook(excel_dir)
self.sh = self.rd.sheet_by_name(sheet_name)
#首行设置为key
self.key = self.sh.row_values(0)
#获取总行数
self.rownum = self.sh.nrows
#获取总列数
self.colnum = self.sh.ncols def function(self):
if self.rownum<=1:
print("没有获取到数值")
else:
r = []
j=1
#要执行的行数
for i in range(self.rownum - 1):
s = {}
values = self.sh.row_values(j)
for x in range(self.colnum):
s[self.key[x]] = values[x]
r.append(s)
j+=1
# print(r)
return r if __name__ == '__main__':
a = input("excel_dir:")
b = input("sheet_name:")
data = rdExcel(a,b)
print(data.function())
基本操作:指定单元格读取数据
rd = xlrd.open_workbook("C:\\Users\\ZHANGCH\\Desktop\\test99.xlsx")
sh = rd.sheet_by_name("rdData")
value = sh.row_values(1)[0]
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("http://www.baidu.com")
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys(value)
driver.find_element(By.CSS_SELECTOR,"#su").click()
============================================================================
写法进行修改规整,完整获取指定数据进行百度查询:
写法①:
import xlrd
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep base = os.path.dirname(os.path.dirname(__file__))
base_dir = base.replace('/','\\')
file_dir = base_dir + os.sep + "test" + os.sep + "test99.xlsx"
print(file_dir) class test():
def __init__(self,file_dir,sheet_name):
self.rd = xlrd.open_workbook(file_dir)
self.sh = self.rd.sheet_by_name(sheet_name)
self.rows = self.sh.nrows
self.cols = self.sh.ncols def ExcelRd(self):
r = []
for i in range(1,self.rows):
values = self.sh.row_values(i,0,self.cols)
r.append(values)
return r if __name__ == '__main__':
#指定sheet页为:rdData
file_dir = input("路径为:")
sheet_name = input("sheet页为:")
data = test(file_dir,sheet_name).ExcelRd() driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
driver.get("https://www.baidu.com") for footballStar in data:
driver.find_element(By.CSS_SELECTOR,"#kw").clear()
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys(footballStar[1])
driver.find_element(By.CSS_SELECTOR,"#su").click()
sleep(5) driver.quit()
写法②:添加截图方法
function.py:
import os def screenshot(driver,img_name):
base = os.path.dirname(os.path.dirname(__file__))
base_dir = base.replace("/","\\")
img_dir = base_dir + os.sep + "20180515作业" + os.sep + "image" + os.sep + img_name + ".png"
driver.get_screenshot_as_file(img_dir)
Excel读取数据.py:
import xlrd
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
from function import screenshot class test(object):
def __init__(self):
self.base = os.path.dirname(os.path.dirname(__file__))
self.base_dir = self.base.replace('/', '\\') def ExcelRd(self):
file_dir = self.base_dir + os.sep + "20180515作业" + os.sep + "test_xlsx.xlsx"
rd = xlrd.open_workbook(file_dir)
sh = rd.sheet_by_name("rdData")
rows = sh.nrows
cols = sh.ncols r = []
for i in range(1,rows):
values = sh.row_values(i,0,cols)
r.append(values)
return r if __name__ == '__main__': data = test().ExcelRd()
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
driver.get("https://www.baidu.com") for footballStar in data:
fbStar = footballStar[1]
driver.find_element(By.CSS_SELECTOR,"#kw").clear()
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys(fbStar)
driver.find_element(By.CSS_SELECTOR,"#su").click()
sleep(3)
fbStar_xlsx = str("xlsx_" + fbStar)
screenshot(driver,fbStar_xlsx)
sleep(7) driver.quit()
二、从CSV读取数据进行百度搜索
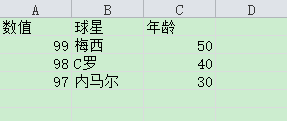
CSV读取数据.py:
import csv
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
from function import screenshot class test(object):
def __init__(self):
base = os.path.dirname(os.path.dirname(__file__))
self.base_dir = base.replace("/","\\") def CSVRd(self):
base_dir = self.base_dir + os.sep + "20180515作业" + os.sep + "test_csv.csv"
opFile = open(base_dir,'r')
rd = csv.reader(opFile) r = []
next(rd,None)
for i in rd:
r.append(i)
return r if __name__ == '__main__': data = test().CSVRd()
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10) for fbStar in data:
fbStar = fbStar[1]
driver.find_element(By.CSS_SELECTOR,"#kw").clear()
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys(fbStar)
driver.find_element(By.CSS_SELECTOR,"#su").click()
sleep(3)
csv_fbStar = str("csv_" + fbStar)
screenshot(driver,csv_fbStar)
sleep(7) driver.quit()
三、从XML读取数据进行登录操作
test_xml文件:
<?xml version="1.0" encoding="utf-8"?>
<info>
<title>博客园登录</title>
<url_dir>https://passport.cnblogs.com/user/signin</url_dir>
<login username="owen_name" password="owen_pwd">登录</login>
</info>
CSV读取数据.py:
import xml.dom.minidom as minidom
# import xml.etree.ElementTree as ele
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
from function import screenshot base = os.path.dirname(os.path.dirname(__file__))
base_dir = base.replace("/","\\")
file_dir = base_dir + os.sep + "20180515作业" + os.sep + "test_xml.xml" #打开xml文档
dom = minidom.parse(file_dir)
#得到文档元素
root = dom.documentElement
#由于下面getElementsByTagName点不出来方法,手写的
tag1 = root.getElementsByTagName("login")
tag2 = root.getElementsByTagName("url_dir")
tag3 = root.getElementsByTagName("title")
#获得标签属性值
username = tag1[0].getAttribute("username")
password = tag1[0].getAttribute("password")
#获得标签之间的数据
url = tag2[0].firstChild.data
title = tag3[0].firstChild.data driver = webdriver.Chrome()
driver.maximize_window()
driver.get(url)
driver.find_element(By.CSS_SELECTOR,"#input1").clear()
driver.find_element(By.CSS_SELECTOR,"#input1").send_keys(username)
sleep(3)
driver.find_element(By.CSS_SELECTOR,"#input2").clear()
driver.find_element(By.CSS_SELECTOR,"#input2").send_keys(password)
sleep(3)
title = str("xml_" + title)
screenshot(driver,title) driver.quit()
四、附:学习资料
《Python不归路_xml.etree.ElementTree模块》感谢作者:深海一尾鱼
《python读取xml文件》感谢作者:虫师
【Selenium + Python】之 Excel、CSV、XML文件读取数据并运用数据百度查询的更多相关文章
- python解析VOC的xml文件并转成自己需要的txt格式
在进行神经网络训练的时候,自己标注的数据集往往会有数据量不够大以及代表性不强等问题,因此我们会采用开源数据集作为训练,开源数据集往往具有特定的格式,如果我们想将开源数据集为我们所用的话,就需要对其格式 ...
- php xml 文件读取 XMLReader
php xml 文件读取 <?php /** $xmlString = '<xml> <persons count="10"> <person ...
- javascript读取xml文件读取节点数据的例子
分享下用javascript读取xml文件读取节点数据方法. 读取的节点数据,还有一种情况是读取节点属性数据. <head> <title></title> < ...
- xml文件读取到数据库
xml文件读取到数据库 第一步,导包 c3p0,dom4j,jaxen,MySQL-connector 第二步 xml文件,config文件 第三步 javabean 第四步 c3p0的工具类 ...
- C#程序中:如何修改xml文件中的节点(数据)
要想在web等程序中实现动态的数据内容给新(如网页中的Flash),不会更新xml文件中的节点(数据)是远远不够的,今天在这里说一个简单的xml文件的更新,方法比较基础,很适合初学者看的,保证一看就懂 ...
- Excel和XML文件导入
using System;using System.Collections;using System.Collections.Generic;using System.Configuration;us ...
- XML文件读取工具类
/// <summary> /// Author: jiangxiaoqiang /// </summary> public class XmlReader { //===== ...
- Excel关联xml文件
1.新建没传值的xml文件,变量名称自己定义好 2.打开excel,如果之前没有设置过,点击选项 如果当前Excel菜单栏中没有开发工具项,在自定义功能区先勾选上开发选项 3.点右下角的xml映射 弹 ...
- Xml 文件读取
.NET 读取Xml文件,用到XmlDocument类. 1.要获取文档的根: DocumentElement. 2.Attributes :获取 XmlAttributeCollection 包含此 ...
随机推荐
- POJ2955 Brackets(区间DP)
给一个括号序列,求有几个括号是匹配的. dp[i][j]表示序列[i,j]的匹配数 dp[i][j]=dp[i+1][j-1]+2(括号i和括号j匹配) dp[i][j]=max(dp[i][k]+d ...
- 分享最新申请IDP账号的过程,包含duns申请的分享(2013年6月)
5月份接到公司要申请开发者账号的任务,就一直在各个论坛找申请的流程,但都是一些09年10年的比较旧的流程,现在都已经不适用了,好不容易找到2012年分享的流程吧,才发现申请过程中少了DUNS编码的步骤 ...
- EDM邮件群发十大技巧提升邮件群发效果
有很多人抱怨现在邮件群发没有什么效果,其实不然,每一种推广方式都有他的优势,没有看到效果说明你没有掌握好方法.个人觉得EDM邮件群发的优势在于传播速度快.不受地域限制.不受时间限制.邮件内容能够多元化 ...
- 小程序redirectTo不跳转
微信小程序解决方案专辑:http://www.wxapp-union.com/special/solution.html 上面有很多新手坑,多搜搜一般都有. 举个例子: redirectTo不跳转的原 ...
- FIREDAC驱动MYSQL数据库
FIREDAC驱动MYSQL数据库 FIREDAC连接MYSQL数据库需要用到LIBMYSQL.DLL这个动态库. 这个LIBMYSQL.DLL分为32位和64位两个不同的版本,对应32位或64位的M ...
- eclipse 启动报错 java was started but returned code=13
eclipse启动不了,出现“Java was started but returned exit code=13......”对话框如下 我的解决方法是:去控制面板--程序--卸载程序和功能下面查看 ...
- Makefile之文件搜索
Makefile之文件搜索 1.Makefile 文件中的"VPATH"变量 如果没有指明这个变量,make只会在当前目录下查找依赖文件和目标文件: 如果定义了这个变量,make会 ...
- 修改Tomcat标题栏内容
你是否遇到过在一个OS任务栏中同时打开多个Tomcat启动程序窗口,这种情况下你会无法区分具体是哪个窗口启动哪个程序,以下方式可以实现Bat启动程序标题栏自定义. 打开Tomcat的Bin目录中,打开 ...
- Spark-Streaming之window滑动窗口应用
Spark-Streaming之window滑动窗口应用,Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作.每次掉落在窗口内的RDD的数据,会被 ...
- JPEG编码(一)
JPEG编码介绍. 转自:http://blog.chinaunix.net/uid-20451980-id-1945156.html JPEG(Joint Photographic Experts ...