Flume NG部署
本次配置单节点的Flume NG
1、下载flume安装包
下载地址:(http://flume.apache.org/download.html)

apache-flume-1.6.0-bin.tar.gz安装包上传解压到集群上的/usr/hadoop/目录下。
[hadoop@centpy hadoop]$ pwd
usr/hadoop
[hadoop@centpy hadoop]$ ls
hadoop-2.6. zookeeper-3.4. hbase-0.98. jdk1..0_60
[hadoop@centpy hadoop]$ rz [hadoop@centpy hadoop]$ ls
apache-flume-1.8.0-bin.tar.gz jdk1..0_60 hbase-0.98. zookeeper-3.4.6 hadoop-2.6.
[hadoop@centpy hadoop]$ tar -zxf apache-flume-1.8.0-bin.tar.gz
[hadoop@centpy hadoop]$ ls
apache-flume-1.8.0-bin hadoop-2.6.
apache-flume-1.8.-bin.tar.gz jdk1..0_60hbase-0.98.19 zookeeper-3.4.
[hadoop@centpy hadoop]$ rm -f apache-flume-1.8.0-bin.tar.gz
[hadoop@centpy hadoop]$ mv apache-flume-1.8.0-bin/ flume-1.8.0
[hadoop@centpy hadoop]$ ls
jdk1..0_60 flume-1.8.0 hbase-0.98. zookeeper-3.4.6 hadoop-2.6.0
2、配置flume
[hadoop@centpy hadoop]$ cd flume-1.8.0/conf/
[hadoop@centpy conf]$ ls
flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
[hadoop@centpy conf]$ cp flume-conf.properties.template flume-conf.properties //需要通过flume-conf.properties.template复制一个flume-conf.properties配置文件
[hadoop@centpy conf]$ ls
flume-conf.properties flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties [hadoop@centpy conf]$ vi flume-conf.properties #Define sources, channels, sinks
agent1.sources = spool-source1
agent1.channels = ch1
agent1.sinks = hdfs-sink1 #Define and configure an Spool directory source
agent1.sources.spool-source1.channels = ch1
agent1.sources.spool-source1.type = spooldir
agent1.sources.spool-source1.spoolDir = /home/hadoop/test
agent1.sources.spool-source1.ignorePattern = event(_\d{}\-\d{}-\d{}_\d{}_\d{})?\.log(\.COMPLETED)?
agent1.sources.spool-source1.deserializer.maxLineLength = #Configure channels
agent1.sources.ch1.type = file
agent1.sources.ch1.checkpointDir = /home/hadoop/app/flume/checkpointDir
agent1.sources.ch1.dataDirs = /home/hadoop/app/flume/dataDirs #Define and configure a hdfs sink
agent1.sinks.hdfs-sink1.channels = ch1
agent1.sinks.hdfs-sink1.type = hdfs
agent1.sinks.hdfs-sink1.hdfs.path = hdfs://centpy:9000/flume/%Y%m%d
agent1.sinks.hdfs-sink1.hdfs.useLocalTimeStamp = true
agent1.sinks.hdfs-sink1.hdfs.rollInterval =
agent1.sinks.hdfs-sink1.hdfs.rollSize =
agent1.sinks.hdfs-sink1.hdfs.rollCount =
#agent1.sinks.hdfs-sink1.hdfs.codeC = snappy
修改集群上的flume-conf.properties配置文件,这里收集日志文件到收集端。配置参数的详细说明可以参考官方文档(https://cwiki.apache.org/confluence/display/FLUME/Getting+Started)。
3、启动并测试Flume
1)首先启动Hadoop集群
[hadoop@centpy hadoop]$ cd hadoop-2.6.0
[hadoop@centpy hadoop-2.6.]$ sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [centpy]
centpy: starting namenode, logging to /usr/hadoop/hadoop-2.6./logs/hadoop-hadoop-namenode-centpy.out
centpy: starting datanode, logging to /usr/hadoop/hadoop-2.6./logs/hadoop-hadoop-datanode-centpy.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/hadoop/hadoop-2.6./logs/hadoop-hadoop-secondarynamenode-centpy.out
starting yarn daemons
starting resourcemanager, logging to /usr/hadoop/hadoop-2.6./logs/yarn-hadoop-resourcemanager-centpy.out
centpy: starting nodemanager, logging to /usr/hadoop/hadoop-2.6./logs/yarn-hadoop-nodemanager-centpy.out
[hadoop@centpy hadoop-2.6.]$ jps
ResourceManager
SecondaryNameNode
NameNode
NodeManager
DataNode
Jps
2)启动Flume
[hadoop@centpy hadoop-2.6.]$ cd ../flume/
[hadoop@centpy flume]$ bin/flume-ng agent -n agent1 -f conf/flume-conf.properties
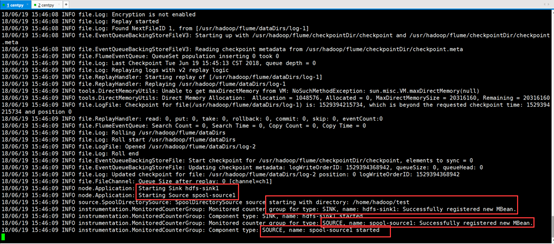
如上图,我们已经成功启动Flume。
3)测试Flume
先上传一个测试文件到我们配置的测试目录中(/home/hadoop/test)
[hadoop@centpy conf]$ cd /home/hadoop/test/
[hadoop@centpy test]$ ls
[hadoop@centpy test]$ rz [hadoop@centpy test]$ ls
template.log
此时Flume会收集日志信息如下:
// :: INFO hdfs.BucketWriter: Creating hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599.tmp
(此处会先在数据收集过程中先生成一个.tmp文件用于记录,等到30秒过后数据收集完成则会生成最终文件FlumeData.1529394914599)
// :: INFO file.EventQueueBackingStoreFile: Start checkpoint for /usr/hadoop/flume/checkpointDir/checkpoint, elements to sync =
// :: INFO file.EventQueueBackingStoreFile: Updating checkpoint metadata: logWriteOrderID: , queueSize: , queueHead:
// :: INFO file.Log: Updated checkpoint for file: /usr/hadoop/flume/dataDirs/log- position: logWriteOrderID:
// :: INFO hdfs.BucketWriter: Closing hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599.tmp
// :: INFO hdfs.BucketWriter: Renaming hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599.tmp to hdfs://centpy:9000/flume/20180619/FlumeData.1529394914599
// :: INFO hdfs.HDFSEventSink: Writer callback called.
我们也可以在Web浏览器查看文件信息

4、Flume 案例分析
下面我们看一下flume的实际应用场景,其示例图如下所示。
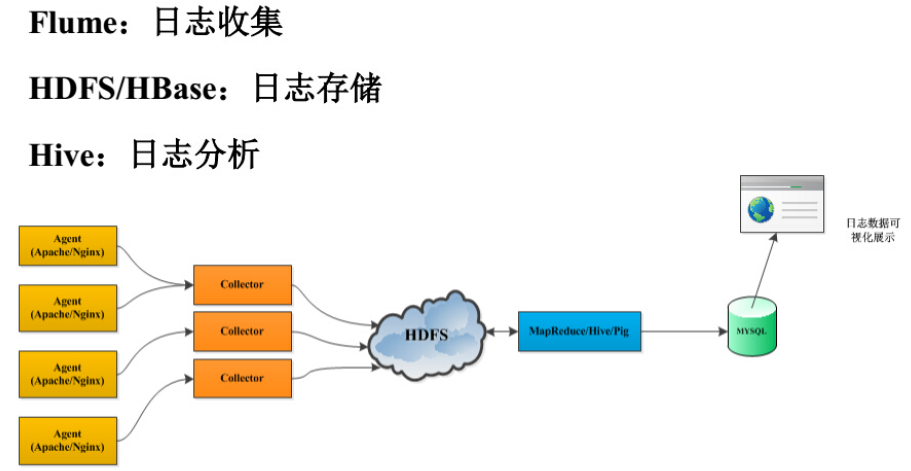
在上面的应用场景中,主要可以分为以下几个步骤。
1、首先采用flume进行日志收集。
2、采用HDFS进行日志的存储。
3、采用MapReduce/Hive进行日志分析。
4、将分析后的格式化日志存储到Mysql数据库中。
5、最后前端查询,实现数据可视化展示。
flume的实际应用场景,相信大家有了一个初步的认识,大家可以根据复杂的业务需求,实现flume来收集数据。这里就不一一讲述,希望大家在以后的学习过程中,学会学习、学会解决实际的问题。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
Flume NG部署的更多相关文章
- Flume NG安装部署及数据采集测试
转载请注明出处:http://www.cnblogs.com/xiaodf/ Flume作为日志收集工具,监控一个文件目录或者一个文件,当有新数据加入时,采集新数据发送给消息队列等. 1 安装部署Fl ...
- Flume NG Getting Started(Flume NG 新手入门指南)
Flume NG Getting Started(Flume NG 新手入门指南)翻译 新手入门 Flume NG是什么? 有什么改变? 获得Flume NG 从源码构建 配置 flume-ng全局选 ...
- Flume NG简介及配置
Flume下载地址:http://apache.fayea.com/flume/ 常用的分布式日志收集系统: Apache Flume. Facebook Scribe. Apache Chukwa ...
- Flume NG 简介及配置实战
Flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用.Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 clo ...
- Flume环境部署和配置详解及案例大全
flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本.HDF ...
- 【Flume NG用户指南】(1)设置
作者:周邦涛(Timen) Email:zhoubangtao@gmail.com 转载请注明出处: http://blog.csdn.net/zhoubangtao/article/details ...
- Flume NG 配置详解(转)
原文链接:[转]Flume NG 配置详解 (说明,名词对应解释 源-Source,接收器-Sink,通道-Channel) 配置 设置代理 Flume代理配置存储在本地配置文件.这是一个文本文件格式 ...
- Flume NG初次使用
一.什么是Flume NG Flume是一个分布式.可靠.和高可用性的海量日志采集.聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据:同时Flume提供对数据的简单处理,并写到各种数 ...
- 高可用Hadoop平台-Flume NG实战图解篇
1.概述 今天补充一篇关于Flume的博客,前面在讲解高可用的Hadoop平台的时候遗漏了这篇,本篇博客为大家讲述以下内容: Flume NG简述 单点Flume NG搭建.运行 高可用Flume N ...
随机推荐
- Ubuntu14.04如何用root账号登陆系统
在虚拟机VMWARE中安装完Ubuntu后,只能用新建的普通用户登陆,很不方便做实验:那如何用root用户登陆账号呢? (1)用普通账号登陆,打开终端terminal: (2)在terminal的输入 ...
- oracle--事物---
一.什么是事务 事务用于保证数据的一致性,它由一组相关的dml语句组成,该组的dml(数据操作语言,增删改,没有查询)语句要么全部成功,要么全部失败. 如:网上转账就是典型的要用事务来处理,用于保证数 ...
- C#的闭包
简单的理解:闭包变量是把局部变量的作用域扩展到回调函数,发生在匿名方法注册到委托上,而匿名方法中使用外部的局部变量 说什么都不如图示那么容易明白啊 先看C#的源码 class Program { st ...
- Windows命令快捷打开
Win+R或者在搜索中输入: control -- 控制面板 mstsc -- 远程连接 SnippingTool -- 截图工具
- Window 显示鼠标的坐标
Window 显示鼠标的坐标 GetCursorPos(POINT *p)函数 windows.h头文件里面的GetCursorPos(POINT *p)函数是用来获取鼠标在屏幕中的坐标信息的. Ge ...
- 《鸟哥的Linux私房菜》读书笔记1
1.MBR 可以说是整个硬盘最重要的地方了,因为在 MBR 里面记录了两个重要的东西,分别是:开机管理程序,与磁盘分割表 ( partition table ).下次记得人家在谈磁盘分割的时候, 不要 ...
- Gson应用:利用map和list来拼装Json消息
import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; i ...
- React 从入门到进阶之路(三)
之前的文章我们介绍了 React 创建组件.JSX 语法.绑定数据和绑定对象.接下来我们将介绍 React 绑定属性( 绑定class 绑定style).引入图片 循环数组渲染数据. 上一篇中我们 ...
- ProtoBuf练习
环境设置 项目地址 https://github.com/silvermagic/ProtoBufDev.git 操作系统 64位 Fedora 24 安装protobuf $ git clone h ...
- 2018宁夏邀请赛G(DFS,动态规划【VECTOR<PAIR>】)
//代码跑的很慢四秒会超时,结尾附两秒代码(标程) #include<bits/stdc++.h>using namespace std;typedef long long ll;cons ...