高性能MySQL笔记-第5章Indexing for High Performance-001B-Tree indexes(B+Tree)
一、
1.什么是B-Tree indexes?
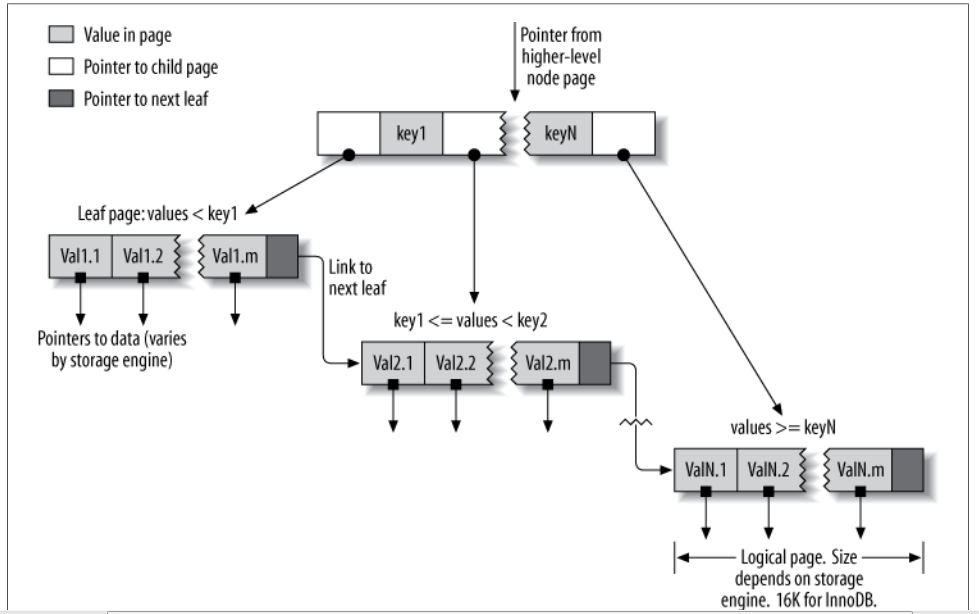
The general idea of a B-Tree is that all the values are stored in order, and each leaf page is the same distance from the root.
A B-Tree index speeds up data access because the storage engine doesn’t have to scan the whole table to find the desired data. Instead, it starts at the root node (not shown in this figure). The slots in the root node hold pointers to child nodes, and the storage engine follows these pointers. It finds the right pointer by looking at the values in the
node pages, which define the upper and lower bounds of the values in the child nodes.Eventually, the storage engine either determines that the desired value doesn’t exist or successfully reaches a leaf page.
Leaf pages are special, because they have pointers to the indexed data instead of pointers to other pages. (Different storage engines have different types of “pointers” to the data.) Our illustration shows only one node page and its leaf pages, but there might be many levels of node pages between the root and the leaves. The tree’s depth depends on how big the table is.
Because B-Trees store the indexed columns in order, they’re useful for searching for ranges of data. For instance, descending the tree for an index on a text field passes through values in alphabetical order, so looking for “everyone whose name begins with I through K” is efficient.
2.例子
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m', 'f')not null,
key(last_name, first_name, dob)
);

3、B-tree index的适用场景
B-Tree indexes work well for lookups by the full key value, a key range, or a key prefix. They are useful only if the lookup uses a leftmost prefix of the index. 3 The index we showed in the previous section will be useful for the
following kinds of queries:
Match the full value
A match on the full key value specifies values for all columns in the index. For example, this index can help you find a person named Cuba Allen who was born on 1960-01-01.
Match a leftmost prefix
This index can help you find all people with the last name Allen. This uses only the first column in the index.
Match a column prefix
You can match on the first part of a column’s value. This index can help you find all people whose last names begin with J. This uses only the first column in the index.
Match a range of values
This index can help you find people whose last names are between Allen and Barrymore. This also uses only the first column.
Match one part exactly and match a range on another part
This index can help you find everyone whose last name is Allen and whose first name starts with the letter K (Kim, Karl, etc.). This is an exact match on last_name and a range query on first_name .
Index-only queries
B-Tree indexes can normally support index-only queries, which are queries that access only the index, not the row storage. We discuss this optimization in “Covering Indexes” on page 177.
Because the tree’s nodes are sorted, they can be used for both lookups (finding values) and ORDER BY queries (finding values in sorted order). In general, if a B-Tree can help you find a row in a particular way, it can help you sort rows by the same criteria. So,our index will be helpful for ORDER BY clauses that match all the types of lookups we just listed.
4.B-tree index的缺点
• They are not useful if the lookup does not start from the leftmost side of the indexed columns. For example, this index won’t help you find all people named Bill or all people born on a certain date, because those columns are not leftmost in the index.Likewise, you can’t use the index to find people whose last name ends with a particular letter.
• You can’t skip columns in the index. That is, you won’t be able to find all people whose last name is Smith and who were born on a particular date. If you don’t specify a value for the first_name column, MySQL can use only the first column of the index.
• The storage engine can’t optimize accesses with any columns to the right of the first range condition. For example, if your query is WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23' , the index access will use only the first two columns in the index, because the LIKE is a range condition (the server can use the rest of the columns for other purposes, though). For a column that has a limited number of values, you can often work around this by specifying equality conditions instead of range conditions. We show detailed examples of this in the indexing case study later in this chapter.
Now you know why we said the column order is extremely important: these limitations are all related to column ordering. For optimal performance, you might need to create indexes with the same columns in different orders to satisfy your queries.
高性能MySQL笔记-第5章Indexing for High Performance-001B-Tree indexes(B+Tree)的更多相关文章
- 高性能MySQL笔记-第5章Indexing for High Performance-004怎样用索引才高效
一.怎样用索引才高效 1.隔离索引列 MySQL generally can’t use indexes on columns unless the columns are isolated in t ...
- 高性能MySQL笔记-第5章Indexing for High Performance-002Hash indexes
一. 1.什么是hash index A hash index is built on a hash table and is useful only for exact lookups that u ...
- 高性能MySQL笔记-第5章Indexing for High Performance-005聚集索引
一.聚集索引介绍 1.什么是聚集索引? InnoDB’s clustered indexes actually store a B-Tree index and the rows together i ...
- 高性能MySQL笔记-第5章Indexing for High Performance-003索引的作用
一. 1. 1). Indexes reduce the amount of data the server has to examine.2). Indexes help the server av ...
- 高性能MySQL笔记 第6章 查询性能优化
6.1 为什么查询速度会慢 查询的生命周期大致可按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段. ...
- 高性能MySQL笔记 第5章 创建高性能的索引
索引(index),在MySQL中也被叫做键(key),是存储引擎用于快速找到记录的一种数据结构.索引优化是对查询性能优化最有效的手段. 5.1 索引基础 索引的类型 索引是在存储引擎层而 ...
- 高性能MySQL笔记 第4章 Schema与数据类型优化
4.1 选择优化的数据类型 通用原则 更小的通常更好 前提是要确保没有低估需要存储的值范围:因为它占用更少的磁盘.内存.CPU缓存,并且处理时需要的CPU周期也更少. 简单就好 简 ...
- 高性能MySQL笔记-第1章MySQL Architecture and History-001
1.MySQL架构图 2.事务的隔离性 事务的隔离性是specific rules for which changes are and aren’t visible inside and outsid ...
- 高性能MySQL笔记-第4章Optimizing Schema and Data Types
1.Good schema design is pretty universal, but of course MySQL has special implementation details to ...
随机推荐
- hive_异常_01_ Terminal initialization failed; falling back to unsupported
一.异常现象 hive初始化数据库时,在执行了 schematool -initSchema -dbType mysql 这个命令时,终端抛出如下异常: [ray@rayner bin]$ schem ...
- Codeforces Round #254(div2)A
很有趣的题.想到了就非常简单,想不到就麻烦了. 其实就是一种逆向思维:最后结果肯定是这样子: WBWBWBWB... BWBWBWBW... WBWBWBWB... ... 里面有“-”的地方改成“- ...
- mount: error mounting /dev/root on /sysroot as ext3: Invalid argument
/************************************************************************ * mount: error mounting /d ...
- map的内存分配机制分析
该程序演示了map在形成的时候对内存的操作和分配. 因为自己对平衡二叉树的创建细节理解不够,还不太明白程序所显示的日志.等我明白了,再来修改这个文档. /* 功能说明: map的内存分配机制分析. 代 ...
- 修改altibase MDB中的复制表的表结构
前提条件:有MDB两个数据库,且知道普通用户和sys用户的密码等基本信息.操作:1:用sys用户登录isqlisql -s 127.0.0.1 -u sys -p manager -port 2030 ...
- UML类图与类的关系详解【转】
在画类图的时候,理清类和类之间的关系是重点. 类的关系有泛化(Generalization).实现(Realization).依赖(Dependency)和关联(Association).其中关联又分 ...
- IE8提示console未定义
在开发的过程中由于调试的原因,在代码中加入console.info("xxxx"),而未进行删除 在IE8下测试该代码所在的页面报错,如下: 需要注意的是,使用console对象查 ...
- h5的video标签支持的视频格式
关于<video>标签所支持的视频格式和编码: MP4 = MPEG 4文件使用 H264 视频编解码器和AAC音频编解码器 WebM = WebM 文件使用 VP8 视频编解码器和 Vo ...
- 一:HTML文本编译器 kindeditor-4.1.10 的使用 SpringMVC+jsp的实现
一:我用的kindeditor版本是4.1.10 下载完成打开目录结构如下: 二:下面是工程目录也很重要, 三: 好了,准备工作已经做好了,现在就直接上代码了. 首先是页面JSP代码 ...
- 侯捷STL学习(11)--算仿+仿函数+适配器
layout: post title: 侯捷STL学习(十一) date: 2017-07-24 tag: 侯捷STL --- 第三讲 标准库内核分析-算法 标准库算法形式 iterator分类 不同 ...