Redis源码分析-底层数据结构盘点
前段时间翻看了Redis的源代码(C语言版本,Git地址:https://github.com/antirez/redis),
过了一遍Redis数据结构,包括SDS、ADList、dict、intset、ziplist、quicklist、skiplist。
在此进行总结
一、SDS(Simple Dynamic String) 简单动态字符串
SDS是redis最简单的数据结构
sds(简单动态字符串)特点,预先分配内存,记录字符串长度,在原字符串数组里新增加一串字符串。
新长度newlen为原len+addlen,若newlen小于1M,则为SDS分配新的内存大小为2*newlen;若newlen大于等于1M,则SDS分配新的内存大小为newlen + 1M
SDS是以len字段来判断是否到达字符串末尾,而不是以'\0'判断结尾。所以sds存储的字符串中间可以出现'\0',即sds字符串是二进制安全的。
当要清空一个SDS时,并不真正释放其内存,而是设置len字段为0即可,这样当之后再次使用到该SDS时,可避免重新分配内存,从而提高效率。
SDS的好处就是通过预分配内存和维护字符串长度,实现动态字符串。
二、ADList(A generic doubly linked list) 双向链表
ADList就是个具有头尾指针的双向链表,没什么可以多说的,看一下结构体的定义
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
三、skipList 跳表
Redis 使用跳跃表作为有序集合键的底层实现之一: 如果一个有序集合包含的元素数量比较多, 又或者有序集合中元素的成员(member)是比较长的字符串时, Redis 就会使用跳跃表来作为有序集合键的底层实现。
1.跳表描述
先看一下比较抽象的描述
1.跳表是一种有序数据结构, 它通过在每个节点中维持多个指向其他节点的指针, 从而达到快速访问节点的目的。
2.跳跃表支持平均 O(log N) 复杂度的节点查找, 还可以通过顺序性操作来批量处理节点。
3.在大部分情况下, 跳跃表的效率可以和平衡树相媲美, 并且因为跳跃表的实现比平衡树要来得更为简单, 所以有不少程序都使用跳跃表来代替平衡树。
这样的描述对数据结构理解不够深刻的同学或许难以理解,别着急,下面看楼主对跳表给出的解释。
1.跳表本质是一个有序链表。(此刻你应想一下一个有序链表是怎样的)
2.跳表的查询、插入、删除的时间复杂度均为O(logn),跟平衡二叉树的时间复杂度是一样的。
3.跳表是一种通过空间冗余来换取时间效率的数据结构。(怎么样的空间冗余的有序链表能换取更高的查询效率呢?)
下来看一下跳表的数据结构的示意图
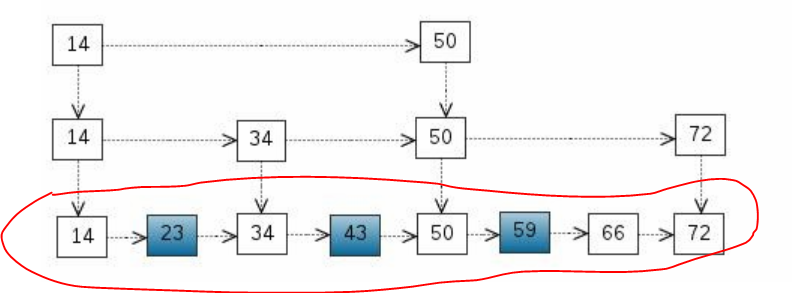
注意观察示意图中圈起来的链表,它是有序的原始链表,存入跳表的数据,就存在这张链表中。
那么上面额外的两条链表又是什么呢,他们有什么作用呢?
上面的两条链表就是所谓的冗余空间,他们相当于是跳表的索引,通过这样的冗余空间就可以在有序链表的基础上实现更高效率的查询。
2.跳表如何提高效率
举个例子
譬如查询72这个元素,如果只有原始链表,你需要依次遍历14-23-34-43-50-59-66-72,总共8个节点,而通过上面2条链表,你将依次遍历14-50-50-72,总共4个节点。
这个例子已经说明了跳表通过冗余空间对查询效率的优化,但是我们还需要理论证明它带来的查询效率的优化对于所有case存在而不是仅仅某些特定的case。
3.跳表查询优化证明
跳表查询优化实际上利用了二分查找的思想,基于有序链表的二分查找。
观察跳表结构,从最底层开始,每隔一个或者两个节点向上抽取一个节点作为索引链表,当抽取到最顶层时,最终只剩两个元素。
查询时,从顶层链表开始将查询关键字与链表节点进行对比,逐层向下进行查找。
譬如查询72这个元素的过程如下:
对比72、14,发现59>14。
对比72、50,发现59>50.
50在顶层是最后一个元素,从50节点下降一层。
对比72、72,查找成功返回节点
通过这样的查找方式,优化了时间效率。
一般来说,跳表存储的关键字越多,跳表的冗余数据也会越多,跳表的层数也越高,并且,
实际上,到底隔多少个节点向上抽取一个节点并不是固定的。
若抽取节点的间距越大,则使用冗余空间越少,跳表总层数越小,查询效率越低 。
若抽取节点的间距越小(最小为1),则使用冗余空间越多,跳表总层数越大,查询效率越高。
这便是以空间换取时间。
4.跳表结构体c语言定义
跳表的示意图看起来很复杂,那么怎么用c语言实现跳表呢。其实,跳表的实现非常简单,看一下跳表结构体的基本定义。
struct skipList{
int lenth;
skipListNode* head;
}skiplist;
跳表结构体记录了存储的元素个数和跳表头节点。
struct skipListNode{
skipListNode* levelnext[3];
int currentlevel;
int totallevel;
int value;
}
跳表节点结构体除了维护保存的关键字外还保存下一个链表节点指针levelnext和当前层数currentlevel。可以看见,下一个链表节点指针是一个大小为3的数组.
数组中的元素指向该节点在某一层的下一个节点。
譬如示意图中的14节点,它的level[0]指向23,level[1]指向34,level[2]指向50。当需要降层查询时,只需要将clevel-1即可。这样便实现了跳表的基本查询逻辑。
而跳表的插入删除逻辑,在经过O(logn)复杂度查找到待删除节点或插入位置后,经过O(1)的时间复杂度(O(1)是指插入底层链表,更新索引需要O(logn)的复杂度)即可完成。
5.跳表索引更新
下面考虑这样的问题
如果我往例子中的跳表插入24、25、26、27,那么在14-34之间元素就会新增加4个,那么如果我在这之间继续插入更多元素,但又不更新索引,那么随着插入元素的增加,跳表的查询效率将会退化成O(n)。
其实,这就像二叉排序树的失衡问题,平衡二叉树通过额外的翻转操作来维护树的左右平衡来确保它的效率,在跳表中,这个额外的操作就是更新索引,那么,跳表是怎么更新索引的呢?
在redis 中是通过一个随机函数,来决定将这个结点插入到哪几层索引中,比如随机函数生成了值K,那么我就将这个结点添加到第一级的到第K级的索引中,以此来避免复杂度的退化,而索引更新的复杂度是O(logn)。
最后补充一点,redis中的 跳表实际上是双向的,并且保存头尾指针,支持双向遍历。
四、ziplist(压缩链表)
1.ziplist介绍
ziplist是经过特殊编码的方式压缩的集合
redis中,当list和hash元素较少并且数值较小时,使用ziplist实现,因为在数据量小的时候ziplist的查询效率接近于O(1),与hash效率相似,ziplist是一整块连续内存,实质是个数组,不利于插入删除和查找。删除节点时,将节点之后的所有节点前移。由于节点保存前一个节点的长度(可能一个字节,可能4个字节),如果删除某节点后导致之后的节点长度发生变化,需要级联更新之后的各个节点长度,直到不用更新长度的节点为止。
ziplist唯一的优势:以字节为单位,通过压缩变长编码的方式节省大量存储空间,当需要使用时,数据可以从磁盘中快速导入内存中处理,而数据在内存中的操作速度是极快的,通过节省存储空间的方式节省了时间。
2.ziplist数据结构
我们先看一个普通数组arr[100]的空间利用情况
struct Node{
int value1;
long value2;
}arr[100];
arr数组内存2个变量value1、value2,分别是int及long类型,分别占用4个字节和8个字节,当我们存储小数值时,就会导致内存的浪费,如arr[0].value1=100,实际上100仅使用了1个字节,但是却占用了4个字节。
而ziplisl就是redis为充分利用存储空间所设计的数据结构,实际上就是一个字节数组。
char ziplist[];
所有类型的数据,包括long、int、指针类型、字符串类型,在存入ziplist时都会先被压缩编码。
3.关于ziplist的两个问题
问:由于保存进ziplist的元素都会被压缩编码,ziplist中每个节点所占的字节数并不是固定的,那么ziplist能否用链表来存储呢?
答:如果用链表的方式来保存节点,会占用离散空间,离散的空间容易产生内存碎片、并且不易导入内存,而用数组的方式,则可以使用连续内存空间。比起离散空间的链表,连续空间的数组更有利于将ziplist导入内存,这就是ziplist使用数组实现的原因。
问:ziplist使用字节数组实现,但是由于每个节点的字节数不固定,ziplist又该如何区分两个节点呢?
答:为了区分两个节点,ziplist中的节点需要保存自身节点的长度,通过自身节点的长度,从而可以定位到该节点下一个节点的首字节,相当于是下一个节点的指针。
另外,ziplist中的节点还保存了前一个节点的长度,通过它,可以定位到该节点的前一个节点的首字节,相当于是前一个节点的指针。从这个角度上来讲,ziplist又是一个双向链表。
4.zpilist格式
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
zlbytes:ziplist占总字节数
zltail:最后一个元素的偏移量,相当于ziplist的尾指针。
zllen:entry元素个数
zlend :ziplist结束标志位
entry:ziplist的各个节点
ziplist的entry 的格式:
<prevlen> <encoding> <entry-data>
prevlen :前一个元素的长度,相当于节点保存前一个元素的指针。
encoding: 记录了当前节点保存的数据的类型以及当前节点长度,相当于节点保存后一个元素的指针。
entry-data :经过压缩后的数据
5.ziplist总结
通过观察ziplist结构体的定义可知,ziplist就是用一个字节数组,保存了双向链表,既压缩了数据,又保证了存储空间的连续性,从而极大方便了将数据从硬盘导入内存进行快速处理。
五、quicklist(快速链表)
1.quicklist介绍
Redis对外暴露的list数据结构,其底层实现所依赖的内部数据结构就是quicklist。quicklist就是一个块状的双向压缩链表。
考虑到双向链表在保存大量数据时需要更多额外内存保存指针并容易产生大量内存碎片,以及ziplist的插入删除的高时间复杂度,两个数据结构的缺陷会导致在数据量很大或插入删除操作频繁的极端情况时,性能极其低下。
Redis为了避免数据结构在极端情况下的低性能,将双向链表和ziplist综合起来,成为了较双向链表及ziplist性能更加稳定的quicklist。
2.quicklist结构体定义
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* 列表中所有数据项的个数总和 total count of all entries in all ziplists */
unsigned int len; /* quicklist节点的个数,即ziplist的个数 number of quicklistNodes */
int fill : 16; /* / / ziplist大小限定,由list-max-ziplist-size给定 fill factor for individual nodes */
unsigned int compress : 16; /* 节点压缩深度设置,由list-compress-depth给定 depth of end nodes not to compress;0=off */
} quicklist;typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; // 数据指针,如果没有被压缩,就指向ziplist结构,反之指向quicklistLZF结构
unsigned int sz; /* 表示指向ziplist结构的总长度(内存占用长度)ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* 编码方式,1--ziplist,2--quicklistLZF RAW==1 or LZF==2 */
unsigned int container : 2; /* 预留字段,存放数据的方式,1--NONE,2--ziplist NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /*解压标记,当查看一个被压缩的数据时,需要暂时解压,标记此参数为1,之后再重新进行压缩 was this node previous compressed? */
unsigned int attempted_compress : 1; /*测试相关 node can't compress; too small */
unsigned int extra : 10; /* 扩展字段,暂时没用 more bits to steal for future usage */
} quicklistNode;
需要特别说明的一点是,REDIS使用quicklist的目的是使数据结构在最坏情况下也能有较稳定的性能,然而为了获得稳定的性能,quicklist在最好情况下的操作的性能不如单纯的adlist或者ziplist。
这一点在新人刚开始学习复杂数据结构的时候常常会被忽略,所以说,没有最好的数据结构,只有最适用的场景
六、dict(字典)
1.dict介绍
在redis中数据结构中,dict字典,就是hash表。
它的实现原理与jdk中的hashmap的实现原理非常类似,都是通过链表的方式(jdk1.8后引入红黑树)解决hash冲突。
2.dict rehash
dict与hashmap的不同主要体现在在扩容时的rehash操作。
jdk中的hashmap的rehash操作是一次性rehash,被调用后就会将整表rehash完之后再允许操作;
redis中的dict的rehash操作是渐进式rehash,渐进式rehash是指,分多次将hash表中的元素进行rehash;
redis dict使用渐进式rehash的好处是,避免保存大量数据的的dict在rehash时使redis一段时间内无法响应用户指令。
3.渐进式rehash原理
redis dict结构体包含两个hash表,ht[0]、ht[1],其中ht[0]指向优先被使用的hash表,ht[1]指向扩容用的hash表,rehash使用dict结构体中的rehashidx属性辅助完成,rehashidx属性指向哪个slot,每次就将ht[0]的那个slot的元素移动到ht[1]中,然后自增rehashidx,直到遍历完整个hash表。由于不是一次性完成rehash,rehash进行时可能穿插着查找等操作,查找的过程是先从ht[0]中查找,若查找不到,则在ht[1]中查找元素。
redis的 rehash包括了lazy rehashing和active rehashing两种方式
lazy rehashing:在每次对dict进行操作的时候执行一个slot的rehash
active rehashing:每100ms里面使用1ms时间进行rehash。这种方式在redis的事件循环,servercron中有相应体现。
(欢迎加qq:1363890602,讨论qq群:297572046,备注:编程艺术)
Redis源码分析-底层数据结构盘点的更多相关文章
- redis源码分析之数据结构--dictionary
本文不讲hash算法,而主要是分析redis中的dict数据结构的特性--分步rehash. 首先看下数据结构:dict代表数据字典,每个数据字典有两个哈希表dictht,哈希表采用链式存储. typ ...
- redis源码分析之数据结构:跳跃表
跳跃表是一种随机化的数据结构,在查找.插入和删除这些字典操作上,其效率可比拟于平衡二叉树(如红黑树),大多数操作只需要O(log n)平均时间,但它的代码以及原理更简单. 和链表.字典等数据结构被广泛 ...
- redis源码分析之事务Transaction(下)
接着上一篇,这篇文章分析一下redis事务操作中multi,exec,discard三个核心命令. 原文地址:http://www.jianshu.com/p/e22615586595 看本篇文章前需 ...
- Redis源码分析:serverCron - redis源码笔记
[redis源码分析]http://blog.csdn.net/column/details/redis-source.html Redis源代码重要目录 dict.c:也是很重要的两个文件,主要 ...
- Redis源码分析(intset)
源码版本:4.0.1 源码位置: intset.h:数据结构的定义 intset.c:创建.增删等操作实现 1. 整数集合简介 intset是Redis内存数据结构之一,和之前的 sds. skipl ...
- redis源码分析之发布订阅(pub/sub)
redis算是缓存界的老大哥了,最近做的事情对redis依赖较多,使用了里面的发布订阅功能,事务功能以及SortedSet等数据结构,后面准备好好学习总结一下redis的一些知识点. 原文地址:htt ...
- redis源码分析之事务Transaction(上)
这周学习了一下redis事务功能的实现原理,本来是想用一篇文章进行总结的,写完以后发现这块内容比较多,而且多个命令之间又互相依赖,放在一篇文章里一方面篇幅会比较大,另一方面文章组织结构会比较乱,不容易 ...
- redis源码分析之有序集SortedSet
有序集SortedSet算是redis中一个很有特色的数据结构,通过这篇文章来总结一下这块知识点. 原文地址:http://www.jianshu.com/p/75ca5a359f9f 一.有序集So ...
- Redis源码分析(dict)
源码版本:redis-4.0.1 源码位置: dict.h:dictEntry.dictht.dict等数据结构定义. dict.c:创建.插入.查找等功能实现. 一.dict 简介 dict (di ...
随机推荐
- 3.微信小程序-B站:wxml和wxss文件
WXML WXML(WeiXin Markup Language)是微信的一套标签语言,结合基础组件.事件系统,可以构建出页面的结构. (小安娜:好像很厉害的样子,那基础组件.事件系统是什么?感觉更厉 ...
- 机器学习(十九)— xgboost初试kaggle
1.官网下载kaggle数据集Homesite Competition数据集,文件结构大致如下: 2.代码实战 #Parameter grid search with xgboost #featur ...
- svn_学习_01_TortoiseSVN使用教程
二.参考资料 1.TortoiseSVN新人使用指南 2.
- Tomcat启动分析(我们为什么要配置CATALINA_HOME环境变量)
原文:http://www.cnblogs.com/heshan664754022/archive/2013/03/27/2984357.html Tomcat启动分析(我们为什么要配置CATALIN ...
- php 代码中的箭头“ ->”与“=>”是什么意思?
类是一个复杂数据类型,这个类型的数据主要有属性.方法两种东西. 属性其实是一些变量,可以存放数据,存放的数据可以是整数.字符串,也可以是数组,甚至是类. 方法实际上是一些函数,用来完成某些功能. 引用 ...
- 解编码框架的比较(protobuf,thrift,Marshalling,xml)
1.ProtoBuf 特点: 1.结构化数据存储格式 2.高效的解编码性能. 3.语言无关,平台无关,扩展性好. 4.官方支持java,c++,python三种语言. 5.性能比较好 (与之对比xml ...
- Gym - 100513K :Treeland (按距离还原一棵树)
题意:一个顶点数为N的生成树,对于每个点i,我们按照与i的距离给出顺序,即dis i 1<=dis i 2<=dis i 3<=...,现在让你输出N-1条边,即还原这棵树. 思路: ...
- Poj 2853,2140 Sequence Sum Possibilities(因式分解)
一.Description Most positive integers may be written as a sum of a sequence of at least two consecuti ...
- svn、git等比较---总结
免费的版本控制系统: CVS:集中式的版本控制系统,必须联网,速度慢,CVS作为最早的开源而且免费的集中式版本控制系统,直到现在还有不少人在用.由于CVS自身设计的问题,会造成提交文件不完整,版本库莫 ...
- idea崩溃导致的svn插件丢失问题, maven dependencies视图丢失问题
Idea丢失Svn解决办法 今天打开Idea,习惯用ctrl+t来更新svn,杯具出现了,快捷键失效了,我觉得可能是其他的什么软件占用了这个快捷键,于是重启了一下,发现还是不行,svn信息怎么没了,c ...