python爬虫框架(3)--Scrapy框架安装配置
1.安装python并将scripts配置进环境变量中
2.安装pywin32
在windows下,必须安装pywin32,安装地址:http://sourceforge.net/projects/pywin32/
下载对应版本的pywin32,直接双击安装即可,安装完毕之后验证:

在python命令行下输入
import win32com
如果没有提示错误,则证明安装成功
3.安装pip
pip是用来安装其他必要包的工具,首先下载 get-pip.py
python get-pip.py
执行命令后便会安装好pip,并且同时,它帮你安装了setuptools
安装完了之后在命令行中执行
pip --version
4.安装pyOPENSSL
在Windows下,是没有预装pyOPENSSL的,而在Linux下是已经安装好的。
安装地址:https://launchpad.net/pyopenssl

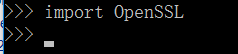
在python命令行下输入
import OpenSSL
如果没有提示错误,则证明安装成功
5.安装 lxml
lxml是一种使用 Python 编写的库,可以迅速、灵活地处理 XML
直接执行如下命令
pip install lxml
6.安装Scrapy
执行如下命令
pip install Scrapy
pip 会另外下载其他依赖的包,这些就不要我们手动安装啦,等待一会,大功告成!
7.验证安装
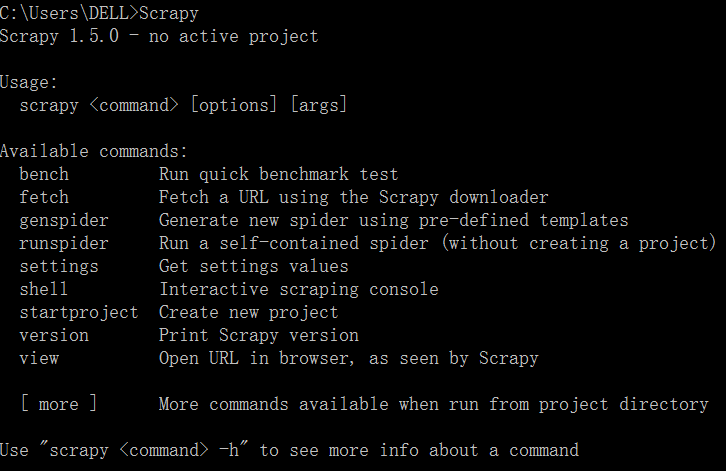
输入 Scrapy
如果提示如下命令,就证明安装成功啦,如果失败了,请检查上述步骤有何疏漏。
可能会遇到AttributeError: 'module' object has no attribute 'OP_NO_TLSv1_1'的问题,原因是使用pip install Scrapy自动安装了较高版本的Twisted
解决办法:安装低版本的twisted
pip install twisted==13.1.0
python爬虫框架(3)--Scrapy框架安装配置的更多相关文章
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- python 爬虫相关含Scrapy框架
1.从酷狗网站爬取 新歌首发的新歌名字.播放时长.链接等 from bs4 import BeautifulSoup as BS import requests import re import js ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 【Python爬虫实战】Scrapy框架的安装 搬运工亲测有效
windows下亲测有效 http://blog.csdn.net/liuweiyuxiang/article/details/68929999这个我们只是正确操作步骤详解的搬运工
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
随机推荐
- 初学者的Node.js学习历程
废话篇: 对于我这个新手的不能再白菜的人来说,nodejs的大名都有耳闻,所以说他是一项不可不克服的技能也是可以说的.但是之前没有搞清楚的情况之下胡乱的猜测,是的我对node.js没有一个具体的概念的 ...
- 分布式_理论_07_ZAB
一.前言 二.参考资料 1.分布式理论(七)—— 一致性协议之 ZAB
- Git学习--创建版本库
什么是版本库呢?版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改.删除,Git都能跟踪,以便任何时刻都可以追踪历史,或 ...
- uva489(需要考虑周全)
这个题是简单题,但是我的思路本身不周全,忽略了一种比较“无理”的情况,而导致WA多次.我是把猜的串全扫一遍以后判断出结果,但是实际上可能是前面已经全猜对了,但是这个选手是个逗比,已经猜对了还要猜,而且 ...
- Unity3D教程:制作与载入AssetBundle
通常我们在游戏程式执行过程,并不希望一次将全部的资源都载入,而比较希望实际上有使用到的才载入,以免占用多余的记忆体,所以我们可能会尽量规划好不同功能的场景,在需要时才载入场景并释放掉前个场景中不需要的 ...
- 使用Python和OpenCV通过网址URL获取图片
在OpenCV中通过图片的URL地址获取图片: # -*- coding: utf-8 -*- import numpy as np import urllib import cv2 # URL到图片 ...
- C++中预定义的宏
以下信息摘自与标准C++的文档中. 如果把这些宏加在程序的日志中,它将为开发人员进行问题分析提供了很好的帮助. standard c++ 1998版The following macro names ...
- 观后感|当幸福来敲门 The Pursuit of Happyness
更好的阅读体验请点击:当幸福来敲门 The Pursuit of Happyness 看到时光机点亮的那一刻,我想儿子克里斯托夫正在侏罗纪的世界内探险,看着山川河流,穿梭在恐龙的脚下,在山洞中安稳的度 ...
- nodepad++的python环境变量设置
转:http://blog.csdn.net/memray/article/details/42041975
- 寻找php.ini之旅
/usr/local/php-fpm/lib/php.ini 可以通过phpinfo()来查看 https://www.cnblogs.com/ChineseMoonGod/p/6474772.htm ...