Hive--可执行SQL的Hadoop数据仓库管理工具
Hive是一个基于HDFS的数据仓库软件,可理解为数据库管理工具;Hive的功能主要有:
1. 支持使用SQL对分布式存储的大型数据集进行读、写、管理,将SQL转化成MapReduce任务执行;
2. 将数据结构映射到已存储的数据中,即将存储在HDFS上结构化的文件内容定义成Hive的外部表。
3. Hive提供了命令行的操作工具和JDBC的开发接口。

我们知道HBase也是基于HDFS的数据库,两者之间有何异同点呢?简言之,Hive和HBase都是Hadoop集群下的工具(bi),Hive是对MapReduce的优化(使用SQL操作MR),而HBase则是HDFS数据存储的大管家。
| Hive | HBase | |
| 出发点 | 使用SQL简化对MapReduce的操作 | 将HDFS上无序的数据映射成有序的表格,便于管理和使用数据 |
| 数据存储 | 1. Hive是纯逻辑表,无物理存储结构;只定义表格元数据,元数据保存在其他数据库上如MySQL,表格数据存储在HDFS上; 2. Hive是逻辑表,属于稠密型,定义列数,每一行有固定的列数。 |
1. HBase表则是物理表,适合存放非结构化的数据; 2. HBase的存储表存储密度小,用户可以对行定义成不同的列。 |
| 数据访问 | Hive是在MapReduce的基础上对数据进行处理,而MapReduce的数据处理依照行模式; | HBase为列模式,这样使得对海量数据的随机访问变得可行。 |
| 使用场景 | 1. Hive使用Hadoop来分析处理数据,而Hadoop系统是批处理系统,所以数据处理存在延时的问题; 2. Hive没有row-level的更新,它适用于大量append-only数据集(如日志)的批任务处理; 3. Hive全面支持SQL,一般可以用来进行基于历史数据的挖掘、分析; 4. Hive主要针对的是OLAP应用,其底层是hdfs分布式文件系统,重点是基于一个统一的查询分析层,支撑OLAP应用中的各种关联,分组,聚合类SQL语句。Hive一般只用于查询分析统计,而不能是常见的CUD操作,要知道Hive是需要从已有的数据库或日志进行同步最终入到HDFS文件系统中,当前要做到增量实时同步都相当困难。 |
1. HBase是准实时系统,可以实现数据的实时查询; 2. HBase的查询,支持和row-level的更新; 3. HBase不适用于有join,多级索引,表关系复杂的应用场景; 4. HBase的应用场景通常是采集网页数据的存储,因为它是key-value型数据库,从而可以到各种key-value应用场景,例如存储日志信息,对于内容信息不需要完全结构化出来的类CMS应用等。注意HBase针对的仍然是OLTP应用为主。 |
结合两者的特点,我们可以将Hbase和Hive应用在大数据架构中的不同位置,使用Hbase解决实时数据查询问题,使用Hive解决数据处理和计算问题。
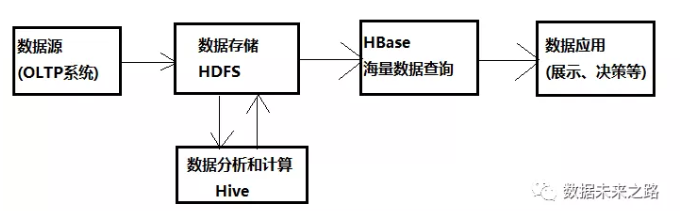
那么Hive具体是如何工作的,其结构原理是怎样的,下面我们具体分析:
1. Hive在0.11版本中引入HiveServer2,是HiveServer(ThriftServer)的升级版本,增加了支持多用户并发和安全认证等功能;HiveServer2是Hive的服务端,接受客户端的任务请求并执行;
2. HiveServer2的客户端有:Beeline、JDBC、Python Client、Ruby Client等。Beeline是HiveServer2的命令行工具,Hive CLI由于不支持多用户等特性已被弃用,JDBC、Python Client、Ruby Client等接口需要用户开发客户端程序连接Hive。
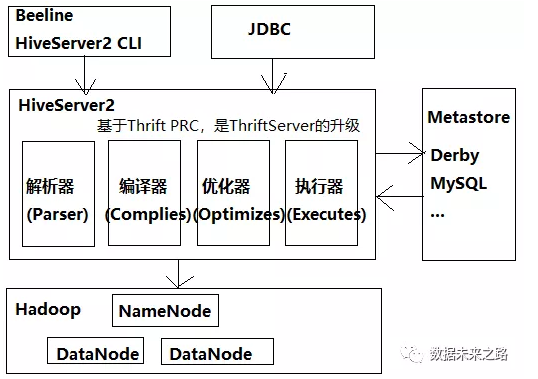
3. HiveServer2的任务执行流程:
(1) Hive将客户端提交的HQL任务解析编译成一组操作符(Operator),比如GroupByOperator,JoinOperator等;
(2)操作符Operator是Hive的最小处理单元;
(3)每个操作符代表一个HDFS操作或者MapReduce作业;
(4)Hive通过ExecMapper和ExecReducer执行MapReduce程序。
(5) Hive 编译器的工作职责:
a. Parser:将 HQL 语句转换成抽象语法树(AST:Abstract Syntax Tree);
b. Semantic Analyzer:将抽象语法树转换成查询块;
c. Logic Plan Generator:将查询块转换成逻辑查询计划;
d. Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划;
e. Physical Plan Gernerator:将逻辑计划转化成物理计划(MapReduce Jobs);
f. Physical Optimizer:选择最佳的 Join 策略,优化物理执行计划。
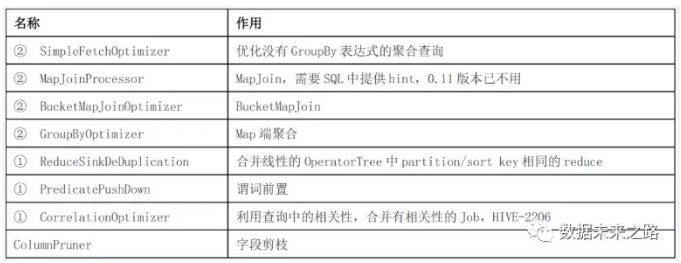
(6) 优化器类型:
下表中带①符号的,优化目的都是尽量将任务合并到一个Job中,以减少 Job数量,带②的优化目的是尽量减少shuffle数据量。
一句话概括上述过程,将HQL语句翻译成MapReduce任务执行,在Hadoop平台提供SQL语言的操作接口,降低大数据平台的使用难度。所以接下来的问题是HQL语言如何使用,Hive的数据结构到底是怎样设计的。
1. HQL是SQL的一个子集,支持SQL的大部分功能。在Beeline上编写SQL语句即可实现对Hive的操作,如:

2. Hive的数据模型:(1)Hive数据库
类似传统数据库的DataBase,存储在MetaStore(MySQL)的元数据实际是一张表。
//创建一个数据库hive > create database test_database;
(2)内部表
Hive的内部表与数据库中的Table在概念上是类似。每一个Table在Hive中都有一个相应的目录存储数据。例如一个表pvs,它在HDFS中的路径为/wh/pvs,其中wh是在hive-site.xml中由${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的Table数据(不包括External Table)都保存在这个目录中。删除表时,元数据与数据都会被删除。
(3)外部表
外部表可理解为指向HDFS文件的链接,仅为HDFS上的结构化数据定义了表结构,便于操作文件。
外部表指向已经在HDFS中存在的数据,可以创建Partition。它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
内部表的创建过程和数据加载过程这两个过程可以分别独立完成,也可以在同一个语句中完成,在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除内部表时,表中的数据和元数据将会被同时删除。
而外部表只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在LOCATION后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个External Table时,仅删除该链接。
//创建一个外部表hive > create external table test_external_table (key string)
(4)分区表
Partition对应于数据库中的Partition列的密集索引,但是Hive中Partition的组织方式和数据库中的很不相同。在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。例如pvs表中包含ds和city两个Partition,则对应于ds = 20090801, ctry = US 的HDFS子目录为/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的HDFS子目录为/wh/pvs/ds=20090801/ctry=CA。
//创建一个分区表hive >create table test_partition_table (key string) partitioned by (dt string)
(5)桶表
Buckets是将表的列通过Hash算法进一步分解成不同的文件存储。它对指定列计算hash,根据hash值切分数据,目的是为了并行,每一个Bucket对应一个文件。例如将user列分散至32个bucket,首先对user列的值计算hash,对应hash值为0的HDFS目录为/wh/pvs/ds=20090801/ctry=US/part-00000;hash值为20的HDFS目录为/wh/pvs/ds=20090801/ctry=US/part-00020。适用于多Map任务的场景。
//创建一个桶表hive >create table test_bucket_table (key string) clustered by (key) into 20 buckets
(6)Hive的视图
视图与传统数据库的视图类似。视图是个虚表,只读的,它基于基本表,如果增加数据不会影响视图的呈现;如果删除,会出现问题。如果不指定视图的列,会根据select语句后的生成。
//创建一个试图hive >create view test_view as select * from test
Hive的具体安装配置和使用方法,官网http://hive.apache.org/上的wiki有详细介绍,这里不再赘述。最后我们简要介绍Hive使用Zookeeper实现HA功能。
Hive从0.14开始,使用Zookeeper实现了HiveServer2的HA功能(ZooKeeper Service Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和port。
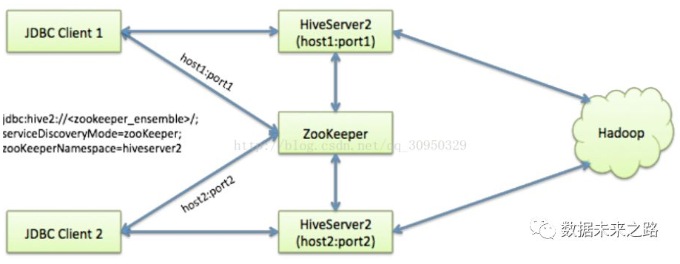
1. 将HiveServer2注册到Zookeeper上,以apache-hive-2.0.0-bin为例,编辑hive-site.xml:

启动HiveServer2后,可到Zookeeper中观察到已注册的Hive服务。
2. 使用JDBC连接服务
JDBC连接的URL格式为:

HiveServer2的多实例高可用配置完成,解决生产中并发、负载均衡、单点故障、安全等问题。Hive--可执行SQL的Hadoop数据仓库管理工具的更多相关文章
- 【原创】大叔经验分享(1)在yarn上查看hive完整执行sql
hive执行sql提交到yarn上的任务名字是被处理过的,通常只能显示sql的前边一段和最后几个字符,这样就会带来一些问题: 1)相近时间提交了几个相近的sql,相互之间无法区分: 2)一个任务有问题 ...
- Hive和SparkSQL:基于 Hadoop 的数据仓库工具
Hive 前言 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,将类 SQL 语句转换为 MapReduce 任务执行. ...
- Hive和SparkSQL: 基于 Hadoop 的数据仓库工具
Hive: 基于 Hadoop 的数据仓库工具 前言 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,将类 SQL 语句转 ...
- hive元数据格式化 在hive中执行sql语句:SemanticException org.apache.hadoop.hive.ql.metadata.HiveException:
https://blog.csdn.net/xiaoqiu_cr/article/details/80913437
- hive批量执行sql命令及使用小技巧
root@hadoop-senior hive-0.13.1]$ bin/hive -helpusage: hive -d, --define <key=value> Variable s ...
- Mysql Workbench 执行sql语句删除数据时提示error code 1175
error code 1175是因为有安全模式限制 执行命令SET SQL_SAFE_UPDATES = 0;之后可以进行操作
- mysql动态执行sql批量删除数据
CREATE PROCEDURE `sp_delete_pushmsg_data`() BEGIN ); ); declare l_dutyno int; ; ; ; ; day),'%Y-%m-%d ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
随机推荐
- redis 集群目标、集群查看、配置方法及过程、哨兵配置启动
集群目标 主从复制,读写分离:故障切换(通过哨兵实现) 查看集群状态 info replication 配置方法 只设置从数据库就可以了:最佳实践,在主数据库配置masterauth <mast ...
- winform listbox 使用DrawMode使用OwnerDrawVarialbe或OwnerDrawFixed无水平滚动条
因为需要使用DrawMode自行DrawItem,所以需要将DrawMode设置为OwnerDrawVarialbe或OwnerDrawFixed模式,代码如下: private void listB ...
- 结对编程——四则运算器(UI第十组)
博客目录: 一.问题描述 二.设计思路 三.UI开发过程 四.对接过程 ...
- 使用Babel和ES7创建JavaScript模块
[编者按]本文主要介绍通过 ES7 与 Babel 建立 JavaScript 模块.文章系国内 ITOM 管理平台 OneAPM 工程师编译呈现,以下为正文. 去年,新版的JavaScript发布了 ...
- spring boot(9)-mybatis关联映射
一对多 查询type表的某一条数据,并且要同时查出所有typeid与之配置的user,最终要得到一个以下类型的Type对象 public class Type { String id; String ...
- 32位Windows7 利用多余的不能识别的电脑内存 RAMDISK5.5教程
32位Windows7 利用多余的不能识别的电脑内存 RAMDISK5.5教程 环境:Windows7 32位 Ultimate 内存8GB 只能识别2.95GB内存 ramdisk5.5只适用于Wi ...
- 机器学习之step by step实战及知识积累笔记
数据工作者工作时间划分 据crowdflower数据科学研究报告,数据科学工作者的时间分配主要在以下几个领域: 首先是数据收集要占20%左右的时间和精力,接着就是数据清洗和再组织需要占用60%的时间. ...
- Django之modelform简介
在django中内置了form类和model类,当页面中的form值和model字段值完全一样时,此时可以通过model生成一个完全一样的form,Django中的modelForm就因此而生. 目标 ...
- IPv4到IPv6的三种过渡技术
1. 双协议栈 ( Dual Stack, RFC2893 ) 主机同时运行IPv4和IPv6两套协议栈,同时支持两套协议. 2. 隧道技术 ( Tunnel, RFC2893 ) 这种机制用来在IP ...
- 使用UISearchDisplayController
使用UISearchDisplayController 虽然UISearchDisplayController名字中带有controller,可他不是一个UIView相关的controller,因为, ...