一种特殊场景下的HASH JOIN的优化为NEST LOOP.
应用场景:
有如下的SQL:
select t.*, t1.owner
from t, t1
where t.id=t1.id;
表t ,t1的数据量比较大,比如200W行.但是两张表能关联的行数却很少,比如不到50条. T1表的行比较宽,且在id列上有单列索引.
这里限制t1的索引为单列索引是为了让访问t1表数据的时候要通过rowid回表.因为在实际应用中,我们通常会需要t1表的几个列,但是不可能对它们全都索引.
此时可以优化为下面的SQL.
select /*+ use_nl(t1, t) ordered */ t.*, t1.owner
from t, t1
where t.id=t1.id and t1.id is not null;
改写原理:
1. 当我们使用NEST LOOP的时候,t1表可以使用id列上的index走出INDEX RANGE SCAN,此时如果输入值不在索引范围内时,是能够很快返回的,理论上就无须访问索引的leaf块。只需访问root和部分branch即可.而这里我们能够真正匹配的数据很少,所以大部分时候都没有到达leaf.
不过这种场景实际应用中并不常见,所以在CBO看来, cost= rows of t * 3(假设index深度为3), 这个cost远大于hash join的cost。如果不加hint,CBO是不会选这个执行计划的.
- select /*+ use_nl(p, l) ordered gather_plan_statistics */
- l.l_suppkey from partsupp p ,lineitem l where
- l.l_suppkey=p.ps_suppkey+10000010 and p.ps_suppkey>0
- Plan hash value: 3264550197
- -------------------------------------------------------------------------------------------------------------------------------
- | Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
- -------------------------------------------------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | | | 2405K(100)| | 0 |00:00:00.91 | 1698 |
- | 1 | NESTED LOOPS | | 1 | 480M| 3662M| 2405K (1)| 08:01:03 | 0 |00:00:00.91 | 1698 |
- |* 2 | INDEX FAST FULL SCAN| I_PARTSUPP1 | 1 | 800K| 3125K| 308 (2)| 00:00:04 | 800K|00:00:00.18 | 1685 |
- |* 3 | INDEX RANGE SCAN | I_LINEITEM1 | 800K| 600 | 2400 | 3 (0)| 00:00:01 | 0 |00:00:00.62 | 13 |
- -------------------------------------------------------------------------------------------------------------------------------
比如下图,要访问10051的数据,通过root节点就知道没这个key了,根本不需完成一次index range scan,而在loop join的下一次循环如果是要10052,直接在cache里快速匹配即可,这个是我猜测的,在CBO执行过程中这个应该很容易实现,相当于做预先处理,这样的预处理再结合storage index就形成了smart scan。
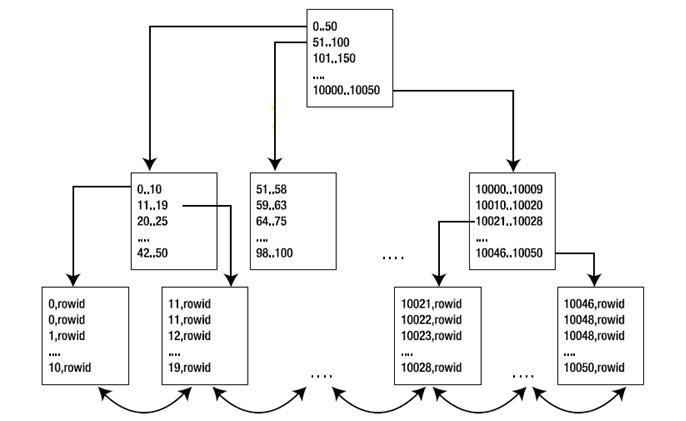
2. HASH JOIN时需要真正拿到索引中t1.id列全部数据后再做匹配,因此此时会走IFS或IFFS,直接遍历索引的所有叶子节点,然后建立hash表.
当索引里记录比较多同时能够匹配的记录有很少是,这种方法不如上面的NEST LOOP.
实验准备:
表的创建和数据的准备,需要的时间比较久,得耐心等待.
--表T
create table t (
id number,
col1 varchar2(30),
col2 varchar2(30),
col3 varchar2(30),
col4 varchar2(30),
col5 varchar2(30),
col6 varchar2(30),
col7 varchar2(30),
col8 varchar2(30),
col9 varchar2(30),
col10 varchar2(30)
);
--随机生成约200W行数据
insert into t select
rownum,
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30)
from dual connect by rownum<2000000;
--T1变的行宽比较大,此时full table scan 读的块较多.
create table t1 (
id number,
id2 number,
id3 varchar2(30),
id4 varchar2(30),
id5 varchar2(30),
id6 varchar2(30),
id7 varchar2(30),
id8 varchar2(30),
id9 varchar2(30),
id10 varchar2(30),
id11 varchar2(30),
id12 varchar2(30),
id13 varchar2(30),
id14 varchar2(30),
id15 varchar2(30),
id16 varchar2(30),
id17 varchar2(30),
id18 varchar2(30),
id19 varchar2(30),
id20 varchar2(30),
id21 varchar2(30),
owner varchar2(30));
--T1表上创建索引
create index t1_idx_id on t1(id);
--随机生成约200W行数据
insert into t1 select
rownum+2000000,
round(dbms_random.value(1,100000000)),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30),
dbms_random.string('u',30)
from dual connect by rownum<2000000;
--收集表的统计信息
exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=>'T',estimate_percent=>100,method_opt=>'for all columns size auto',cascade=>TRUE)
exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=>'T1',estimate_percent=>100,method_opt=>'for all columns size auto',cascade=>TRUE)
--让表T, T1 有少数的关联行,这里是制造10条关联记录.
update t1 set id = (select round(dbms_random.value(1,1999999)) from dual)
where id in (select round(dbms_random.value(2000001,4000000)) from dual connect by rownum<10) and id is not null;
实验开始:
SQL> select t.*, t1.owner
2 from t, t1
3 where t.id=t1.id and t1.id is not null;
已选择10行。
已用时间: 00: 00: 18.54
执行计划
----------------------------------------------------------
Plan hash value: 1444793974
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 352 | | 109K (1)| 00:21:56 |
|* 1 | HASH JOIN | | 1 | 352 | 93M| 109K (1)| 00:21:56 |
|* 2 | TABLE ACCESS FULL| T1 | 1999K| 70M| | 49367 (1)| 00:09:53 |
| 3 | TABLE ACCESS FULL| T | 1999K| 600M| | 24691 (1)| 00:04:57 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T"."ID"="T1"."ID")
2 - filter("T1"."ID" IS NOT NULL)
统计信息
----------------------------------------------------------
97 recursive calls
0 db block gets
454560 consistent gets
283928 physical reads
0 redo size
2086 bytes sent via SQL*Net to client
420 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
10 rows processed
全表扫描的T1时,18S。
SQL> select /*+index(t1 T1_IDX_ID)*/t.*, t1.owner
2 from t, t1
3 where t.id=t1.id and t1.id is not null;
已选择10行。
已用时间: 00: 01: 52.29
执行计划
----------------------------------------------------------
Plan hash value: 2604990230
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 352 | | 246K (1)| 00:49:19 |
|* 1 | HASH JOIN | | 1 | 352 | 93M| 246K (1)| 00:49:19 |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 1999K| 70M| | 186K (1)| 00:37:15 |
|* 3 | INDEX FULL SCAN | T1_IDX_ID | 1999K| | | 4279 (1)| 00:00:52 |
| 4 | TABLE ACCESS FULL | T | 1999K| 600M| | 24691 (1)| 00:04:57 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T"."ID"="T1"."ID")
3 - filter("T1"."ID" IS NOT NULL)
统计信息
----------------------------------------------------------
98 recursive calls
0 db block gets
458819 consistent gets
271761 physical reads
13092036 redo size
2086 bytes sent via SQL*Net to client
420 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
10 rows processed
SQL> select /*+ use_nl(t1, t) ordered */t.*, t1.owner
2 from t, t1
3 where t.id=t1.id and t1.id is not null;
已选择10行。
已用时间: 00: 00: 04.81
执行计划
----------------------------------------------------------
Plan hash value: 3173170385
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 352 | 4026K (1)| 13:25:15 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 1 | 352 | 4026K (1)| 13:25:15 |
| 3 | TABLE ACCESS FULL | T | 1999K| 600M| 24691 (1)| 00:04:57 |
|* 4 | INDEX RANGE SCAN | T1_IDX_ID | 1 | | 2 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 37 | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T"."ID"="T1"."ID")
filter("T1"."ID" IS NOT NULL)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
90946 consistent gets
90914 physical reads
0 redo size
2086 bytes sent via SQL*Net to client
420 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
10 rows processed
select /*+ use_nl(t1, t) ordered gather_plan_statistics*/t.*, t1.owner
from t, t1 where t.id=t1.id and t1.id is not null
Plan hash value: 3173170385
---------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | | | 4026K(100)| | 40 |00:01:04.01 | 363K| 363K|
| 1 | NESTED LOOPS | | 4 | | | | | 40 |00:01:04.01 | 363K| 363K|
| 2 | NESTED LOOPS | | 4 | 1 | 352 | 4026K (1)| 13:25:15 | 40 |00:01:04.01 | 363K| 363K|
| 3 | TABLE ACCESS FULL | T | 4 | 1999K| 600M| 24691 (1)| 00:04:57 | 7999K|00:00:33.47 | 363K| 363K|
|* 4 | INDEX RANGE SCAN | T1_IDX_ID | 7999K| 1 | | 2 (0)| 00:00:01 | 40 |00:00:51.27 | 60 | 0 |
| 5 | TABLE ACCESS BY INDEX ROWID| T1 | 40 | 1 | 37 | 2 (0)| 00:00:01 | 40 |00:00:00.01 | 40 | 0 |
---------------------------------------------------------------------------------------------------------------------------------------------
一种特殊场景下的HASH JOIN的优化为NEST LOOP.的更多相关文章
- FFmpeg命令:几种常见场景下的FFmpeg命令(摄像头采集推流,桌面屏幕录制推流、转流,拉流等等)
前提: 首先你得有FFmpeg(ffmpeg官网快捷通道:http://ffmpeg.org/) 再者,推流你得有个流媒体服务,个人测试用小水管:rtmp://eguid.cc:1935/rtmp/t ...
- oracle多表连接方式Hash Join Nested Loop Join Merge Join
在查看sql执行计划时,我们会发现表的连接方式有多种,本文对表的连接方式进行介绍以便更好看懂执行计划和理解sql执行原理. 一.连接方式: 嵌套循环(Nested Loops (NL) ...
- Oracle 表的连接方式(2)-----HASH JOIN的基本机制3
HASH JOIN的模式 hash join有三种工作模式,分别是optimal模式,onepass模式和multipass模式,分别在v$sysstat里面有对应的统计信息: SQL> sel ...
- 浅谈SQL Server中的三种物理连接操作(HASH JOIN MERGE JOIN NESTED LOOP)
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- oracle Hash Join及三种连接方式
在Oracle中,确定连接操作类型是执行计划生成的重要方面.各种连接操作类型代表着不同的连接操作算法,不同的连接操作类型也适应于不同的数据量和数据分布情况. 无论是Nest Loop Join(嵌套循 ...
- 浅谈SQL Server中的三种物理连接操作(Nested Loop Join、Merge Join、Hash Join)
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- Sort merge join、Nested loops、Hash join(三种连接类型)
目前为止,典型的连接类型有3种: Sort merge join(SMJ排序-合并连接):首先生产driving table需要的数据,然后对这些数据按照连接操作关联列进行排序:然后生产probed ...
- vue-router两种模式,到底什么情况下用hash,什么情况下用history模式呢?
转:https://segmentfault.com/q/1010000010340823/a-1020000010598395 为什么要有 hash 和 history 对于 Vue 这类渐进式前端 ...
- 多表连接的三种方式详解 hash join、merge join、 nested loop
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式.多表之间的连接有三种方式:Nested Loops,Hash Join 和 Sort Merge Join.具体适用哪 ...
随机推荐
- 【树】Binary Tree Zigzag Level Order Traversal
题目: Given a binary tree, return the zigzag level order traversal of its nodes' values. (ie, from lef ...
- 怎么将一张100KB以上大小的电子图片压缩成30KB以内
不多说,直接上干货! 方法一: 怎么将一张100KB以上大小的电子照片压缩成30KB以内. 先将这张100KB以上大小的电子照片,新建一个word,放入.选中照片,右击,另存为,格式依然还是选择.jp ...
- 解决LNMP环境下WordPress后台缺少”WP-ADMIN”路径
LNMP一键安装包也是老左比较喜欢使用的环境之一,昨天帮助一个网友搭建LNMP环境后发现登陆WP后台之后点击左侧的菜单发现直接跳转404错误,开始还以为数据库问题,视线朝上一看原来在地址栏中的路径缺少 ...
- 电信固定ip宽带80与8080端口踩坑
本文只是作为记录,避免后面遇到此类问题耗费时间. 实际情况:公司有个固定电信宽带是固定IP的,想把固定IP映射到测试环境ip,实现可以公网通过固定ip访问,内网通过局域网ip访问. 测试环境服务是占用 ...
- glide 解决 golang.org/x/net 等依赖包无法获取
知道glide有设置镜像功能,可以把某个依赖包的源地址切换为另一个地址,相当于切换到镜像地址,用于某些依赖包被墙的原因 之前碰到 golang.org/x/net,设置镜像: glide mirror ...
- springboot-18-springboot的参数封装
springboot的参数封装, 和springmvc相识 简单参数的封装 1.直接把表单的参数写在Controller相应的方法的形参中,适用于get方式提交,不适用于post方式提交. /** * ...
- PTA (Advanced Level) 1024 Palindromic Number
Palindromic Number A number that will be the same when it is written forwards or backwards is known ...
- 如何学习JavaEE,项目又该如何做?
本文主要分为三个部分: 如何学习java基础 如何学习javaEE 你关心的项目问题 01 java基础学习 建议初学者看视频学习,不推荐看书.入门视频选择非常重要,最好是通俗易懂.深入浅出的教学视频 ...
- DES对 json 、http参数加密解密算法
网上众多大神们的众多方式实现加解密操作及保障数据安全性.今天无意中发现一篇以 DES加密解密算法.摘抄如下 工具类: import java.security.SecureRandom; import ...
- Spring整合Hibernate的XML文件配置,以及web.xml文件配置
利用Spring整合Hibernate时的XML文件配置 applicationContext.xml <?xml version="1.0" encoding=" ...