Lucene7.1.0版本的索引创建与查询以及维护,包括新版本的一些新特性探索!
一 吐槽
lucene版本更新实在太快了,往往旧版本都还没学会,新的就出来,而且每个版本改动都特别大,尤其是4.7,6,6,7.1.......ε=(´ο`*)))唉,但不可否认,新版本确实要比旧版本好用,这里就小记一下7.1.0版本中
lucene的创建索引,查询索引,搜索排序,通过权值查询,以及适配新版本的luke查询器,IK中文分词,高亮显示等最基本的使用!
maven:
<!-- 核心包 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.1.0</version>
</dependency>
<!-- 高亮 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>7.1.0</version>
</dependency>
<!-- 中文分词器 SmartChineseAnalyzer -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>7.1.0</version>
</dependency>
<!-- 文件操作包 -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
二 索引创建
因为接触的旧版本也不是很多,新版本的网上资料又少,所以只能自己硬着头皮不断试水,翻中文文档,但是这里尽量补全基本的变动以及内容:
IndexWriter writer=null;
// 1 指定索引库存放路径
// 硬盘路径
try {
//好像是从5.x版本中打开目录就必须用Path类了,方法如下,不能像4.x版本之前的直接写路径
File indexrepository_file = new File("D:\\others\\lucene\\index");
Path path = indexrepository_file.toPath();
Directory directory=null;
directory = FSDirectory.open(path);//使用path
// 索引建立在内存中
//Directory directory01=new RAMDirectory();
// 2 创建writer
//指定一个分词器
Analyzer analyzer=new IKAnalyzer();//使用IK,需要用特定的高版本适配版,后面放链接
IndexWriterConfig config=new IndexWriterConfig(analyzer);
writer=new IndexWriter(directory,config);
// 3 创建document对象,并添加Filed域属性
Document doc=null;
File f=new File("D:\\others\\lucene\\doc");//文档目录
for(File file : f.listFiles()){//遍历每个文档
doc=new Document();
/**
* 新版本中使用了Int/Long/DoublePoint来表示数值型字段,但是默认不存储,不排序,也不支持加权
* 创建索引加权值在6.6版本后就已经废除了,并给了搜索时设置的新query,这个后面查询时再说
* 如果存储需要用StoredField写相同的字段,排序还要再使用NumericDocValuesField写相同的排序,
* 如下的fileSize,添加long值索引,存储并添加排序支持
/
//文件名
doc.add(new TextField("fileName", file.getName(), Store.YES););
//大小,数字类型使用point添加到索引中,同时如果需要存储,由于没有Stroe,所以需要再创建一个StoredField进行存储
// 即 IntPoint,DoublePoint等
doc.add(new LongPoint("fileSize", file.length()));
//大小
doc.add(new StoredField("fileSize", file.length()));
//同时添加排序支持
doc.add(new NumericDocValuesField("fileSize",file.length()));
//路径
doc.add(new StoredField("filePath",file.getPath()));
//内容
doc.add(new TextField("fileContent",FileUtils.readFileToString(file),Store.NO));
//doc.add(new TextField("fileContent",new FileReader(file)));
// 4 使用indexWriter将doc对象写入索引库,此过程创建索引,并将索引和文档对象写入索引库
writer.addDocument(doc);
}
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
这里再放一下lucene常用的Filed域资料:

7.1.0版本中数值型的都使用Point了,所以Long被废弃,
使用luke查询索引:
luke是一个查询索引的工具,使用时必须注意:版本要与lucene的版本完全一致,否则可能打不开索引信息
java -jar luke-xx-xx.jar可以打开索引,也可直接双击
选择索引说存储的目录,就可以使用luke查询和操作相应的索引信息,并且可以在search中根据QueryParser来查询相应的信息
但是由于maven已经不再适配高版本,所以要在网上找相应的适配版,这里放一个7.1.0的可用版链接:
https://download.csdn.net/download/zxk948433600/10116352?web=web
三 索引查询
这里先举个简单例子,使用内容关键字查询,通用使用Path类打开索引目录,其他区别不是很大:
try {
//1 创建Directory对象,索引存放位置
File indexrepository_file = new File("D:\\others\\lucene\\index");
Path path = indexrepository_file.toPath();
Directory directory = FSDirectory.open(path);
//2 创建IndexReader
IndexReader indexReader = DirectoryReader.open(directory);
//3 创建IndexSearch对象
IndexSearcher indexSearch=new IndexSearcher(indexReader);
//4 创建TermQuery对象,指定查询的域和关键字
Query query=new TermQuery(new Term("fileContent","姚振"));
//5 查询
TopDocs topDocs = indexSearch.search(query, 5);//前5个
//6 遍历结果
ScoreDoc[] scoreDocs = topDocs.scoreDocs;//文档id数组
for (ScoreDoc scoreDoc : scoreDocs) {
//根据id获取文档
Document doc = indexSearch.doc(scoreDoc.doc);
//获取结果,没有存储的是null,比如内容
System.out.println("文档名: "+doc.get("fileName"));
System.out.println("文档路径: "+doc.get("filePath"));
System.out.println("文档大小: "+doc.get("fileSize"));
System.out.println("文档内容: "+doc.get("fileContent"));
System.out.println("-------------------");
}
//7 关闭reader
indexReader.close();
} catch (IOException e) {
e.printStackTrace();
}
这里再说一下IK分词器,IK分析对中文的支持特别好,但是maven上的也不更新了,没有适配高版本,所以还需要自己下载可用版,
或者使用其他分析器,我使用IK的一点是可以自己维护一些关键词,比如我如果想搜我的好朋友姚振,如果使用lucene自带的中文分词,是搜不到的,因为它会把词分成姚和振,
而且IK可以过滤掉常用词,优化索引,这里就不多说了,放链接:
https://download.csdn.net/download/u012809062/9730367
IK的使用:
下载后的解压目录:
导入lib包,并将三个配置都导入到resources目录下即可,然后进行配置:

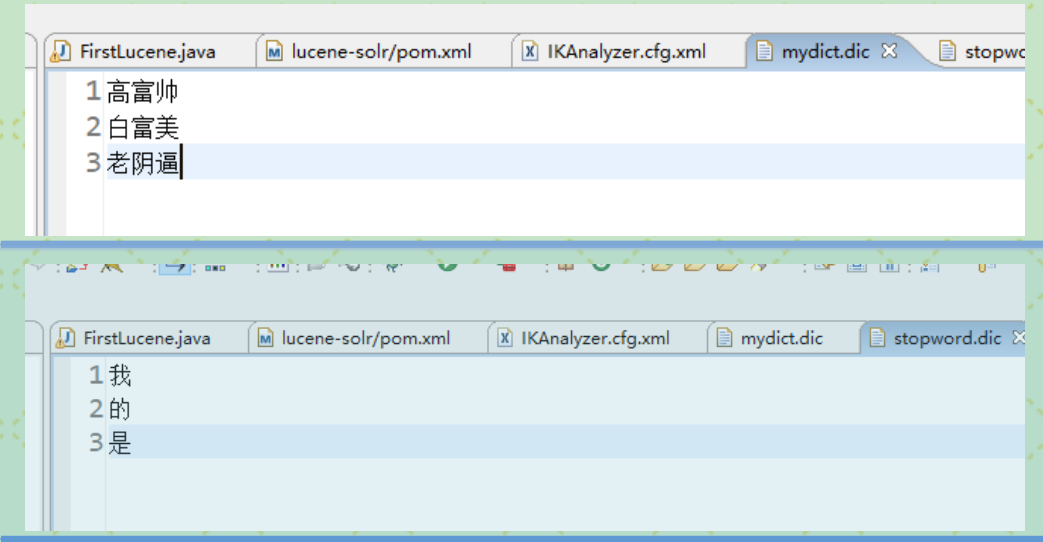
比如,我的配置:
四 多种查询
查询主要有两种,一种是Query的子类查询,一种是语法解析查询,这里先说子类查询:
可以先写一个获取search的公共方法,以及遍历打印搜索结果的方法,之后就可以对各种查询进行方便测试了:
//获取IndexWriter
public IndexWriter getIndexWriter() throws Exception{
File indexrepository_file = new File("D:\\others\\lucene\\index");
Path path = indexrepository_file.toPath();
Directory directory=null;
directory = FSDirectory.open(path);
Analyzer analyzer=new IKAnalyzer();//使用IK
IndexWriterConfig config=new IndexWriterConfig(analyzer);
return new IndexWriter(directory,config);
}
//获取IndexSearch
public IndexSearcher getIndexSearcher() throws Exception{
return new IndexSearcher(getIndexReader());
}
//执行查询并打印结果
public void printResult(IndexSearcher indexSearcher,Query query,Integer num) throws Exception{
//使用排序
Sort sort =new Sort();
SortField f =new SortField("fileSize",Type.LONG,true); // 按照fileSize字段排序,true表示降序
sort.setSort(f);
// 多个条件排序
// Sort sort = new Sort();
// SortField f1 = new SortField("createdate", SortField.DOC, true);
// SortField f2 = new SortField("bookname", SortFiedl.INT, false);
// sort.setSort(new SortField[] { f1, f2 });
//高亮显示start
//算分
QueryScorer scorer=new QueryScorer(query);
//显示得分高的片段
Fragmenter fragmenter=new SimpleSpanFragmenter(scorer);
//设置标签内部关键字的颜色
//第一个参数:标签的前半部分;第二个参数:标签的后半部分。
SimpleHTMLFormatter simpleHTMLFormatter=new SimpleHTMLFormatter("<b><font color='red'>","</font></b>");
//第一个参数是对查到的结果进行实例化;第二个是片段得分(显示得分高的片段,即摘要)
Highlighter highlighter=new Highlighter(simpleHTMLFormatter, scorer);
//设置片段
highlighter.setTextFragmenter(fragmenter);
//高亮显示end
TopDocs topDocs = indexSearcher.search(query, num,sort);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;//文档id数组
for (ScoreDoc scoreDoc : scoreDocs) {
//根据id获取文档
Document doc = indexSearcher.doc(scoreDoc.doc);
String name = doc.get("fileName");
if(name!=null){
//把全部得分高的摘要给显示出来
//第一个参数是对哪个参数进行设置;第二个是以流的方式读入
TokenStream tokenStream=new IKAnalyzer().tokenStream("fileName", new StringReader(name));
//获取最高的片段
System.out.println("高亮文档名: "+highlighter.getBestFragment(tokenStream, name));
}
//获取结果,没有存储的是null,比如内容
System.out.println("文档名: "+doc.get("fileName"));
System.out.println("文档路径: "+doc.get("filePath"));
System.out.println("文档大小: "+doc.get("fileSize"));
System.out.println("文档内容: "+doc.get("fileContent"));
System.out.println("-------------------");
}
}
1 Query子类查询
//查询
@Test
public void testSelect01() throws Exception{
IndexSearcher indexSearcher = getIndexSearcher();
//数字范围查询, 两边都是闭区间 43< index <103
//新版本中数值都使用Point进行查询,原理的Numic被废弃
//Query query=LongPoint.newRangeQuery("fileSize", 43L, 103L);
//数值精确匹配,只会查找参数里的数值索引 index in param
List<Long> list=new ArrayList<Long>();
list.add(43L);
list.add(103L);
Query query2=LongPoint.newSetQuery("fileSize", 43L,100L);//不定参数
Query query1=LongPoint.newSetQuery("fileSize", list); //集合参数
printResult(indexSearcher,query1,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
/**
* TermRangeQuery是用于字符串范围查询的,既然涉及到范围必然需要字符串比较大小,
* 字符串比较大小其实比较的是ASC码值,即ASC码范围查询。
* 一般对于英文来说,进行ASC码范围查询还有那么一点意义,
* 中文汉字进行ASC码值比较没什么太大意义,所以这个TermRangeQuery了解一下就行
*/
@Test
public void testSelect02() throws Exception{
String lowerTermString = "侯征";//范围的下端的文字,后面boolean为真,对应值为闭区间
String upperTermString = "词语";//范围的上限内的文本,后面boolean为真,对应值为闭区间
IndexSearcher indexSearcher = getIndexSearcher();
//lucene 使用 BytesRef 在索引中表示utf-8编码的字符,此类含有偏移量_长度以及byte数组,可使用utf8toString API转换字符串
Query query=new TermRangeQuery("fileName",new BytesRef(lowerTermString),new BytesRef(upperTermString),true,true);
printResult(indexSearcher,query,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
/**
* BooleanQuery也是实际开发过程中经常使用的一种Query。
* 它其实是一个组合的Query,在使用时可以把各种Query对象添加进去并标明它们之间的逻辑关系。
* 所有的Query都可以通过booleanQUery组合起来
* BooleanQuery本身来讲是一个布尔子句的容器,它提供了专门的API方法往其中添加子句,
* 并标明它们之间的关系
*/
@Test
public void testSelect03() throws Exception{
IndexSearcher indexSearcher = getIndexSearcher();
//组合条件
Query query1=new TermQuery(new Term("fileName","歌曲"));
Query query2=new TermQuery(new Term("fileContent","美国"));
//相当于一个包装类,将 Query 设置 Boost 值 ,然后包装起来。
//再通过复合查询语句,可以突出 Query 的优先级
BoostQuery query=new BoostQuery(query2, 2f);
//创建BooleanQuery.Builder
BooleanQuery.Builder builder=new BooleanQuery.Builder();
//添加逻辑
/**
* 1.MUST和MUST:取得两个查询子句的交集。 and
2.MUST和MUST_NOT:表示查询结果中不能包含MUST_NOT所对应得查询子句的检索结果。
3.SHOULD与MUST_NOT:连用时,功能同MUST和MUST_NOT。
4.SHOULD与MUST连用时,结果为MUST子句的检索结果,但是SHOULD可影响排序。
5.SHOULD与SHOULD:表示“或”关系,最终检索结果为所有检索子句的并集。
6.MUST_NOT和MUST_NOT:无意义,检索无结果。
*/
builder.add(query1, Occur.SHOULD);// 文件名不包含词语,但是内容必须包含姚振
builder.add(query, Occur.SHOULD);
//build query
BooleanQuery booleanQuery=builder.build();
printResult(indexSearcher,booleanQuery,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
@Test
public void testSelect() throws Exception{
IndexSearcher indexSearcher = getIndexSearcher();
//查询所有
Query queryAll=new MatchAllDocsQuery();
printResult(indexSearcher,queryAll,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
@Test
public void test05() throws Exception{
IndexSearcher indexSearcher = getIndexSearcher();
//查询文件名以新开头的索引 前缀匹配查询
Query query=new PrefixQuery(new Term("fileName","新"));
System.out.println(query);
printResult(indexSearcher,query,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
/**
* PhraseQuery,是指通过短语来检索,比如我想查“姚振 牛逼”这个短语,
* 那么如果待匹配的document的指定项里包含了"姚振 牛逼"这个短语,
* 这个document就算匹配成功。可如果待匹配的句子里包含的是“姚振 真他妈 牛逼”,
* 那么就无法匹配成功了,如果也想让这个匹配,就需要设定slop,
* 先给出slop的概念:slop是指两个项的位置之间允许的最大间隔距离
*/
@Test
public void test06() throws Exception{
IndexSearcher indexSearcher = getIndexSearcher();
Builder build = new PhraseQuery.Builder();
build.add(new Term("fileContent","白富美"));
build.add(new Term("fileContent","老阴逼"));
//设置slop,即最大相隔多远,即多少个文字的距离,
build.setSlop(6);//表示如果这两个词语相隔6个字以下的位置就匹配
PhraseQuery phraseQuery = build.build();
printResult(indexSearcher,phraseQuery,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
@Test
public void test07() throws Exception{
IndexSearcher indexSearcher = getIndexSearcher();
//FuzzyQuery是一种模糊查询,它可以简单地识别两个相近的词语
Query query=new FuzzyQuery(new Term("fileContent","牛逼"));
printResult(indexSearcher,query,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
@Test
public void test09() throws Exception{
IndexSearcher indexSearcher = getIndexSearcher();
//Lucene也提供了通配符的查询,这就是WildcardQuery。
// 通配符“?”代表1个字符,而“*”则代表0至多个字符。
Query query=new WildcardQuery(new Term("fileName","?词语")); //名字以词语结尾
Query query1=new WildcardQuery(new Term("fileName","新*")); //名字以新开头
printResult(indexSearcher,query1,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
2 QueryParser条件解析查询
@Test
public void test08() throws Exception{
/**
* 解析查询表达式
* QueryParser实际上就是一个解析用户输入的工具,可以通过扫描用户输入的字符串,生成Query对象
*/
IndexSearcher indexSearcher = getIndexSearcher();
Query query=new TermQuery(new Term("fileName","词语"));
// 参数: 默认域 分词解析器
QueryParser queryParser = new QueryParser("fileContent", new IKAnalyzer());
//解析 ,如果不指定域,使用默认域 使用语法书写
Query parse = queryParser.parse("侯征 姚振 何毅");
Query parse1 = queryParser.parse("fileName:侯征 姚振 何毅");//指定域
Query parse2 = queryParser.parse("fileName:侯*");//匹配
Query parse3 = queryParser.parse("+fileName:游戏 fileName:新词语");//匹配
printResult(indexSearcher,parse3,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
@Test
public void test10() throws Exception{
/**
* 解析查询表达式
* MultiFieldQueryParser支持多默认域
*/
IndexSearcher indexSearcher = getIndexSearcher();
// 指定多默认域数组
String[] arr=new String[]{"fileName","fileContent"};
//搜索时设置权重
Map<String,Float> boosts = new HashMap<String,Float>();
boosts.put("fileContent", 10.0f);//权重默认是1, 文件名字符合条件的排序在前面
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(arr, new IKAnalyzer(),boosts);//指定搜索权重
//解析 ,如果不指定域,使用默认域 使用语法书写
Query parse = queryParser.parse("游戏");//查询所有默认域里有姚振的文档
printResult(indexSearcher,parse,10);
//关闭reader
indexSearcher.getIndexReader().close();
}
还有一点,就是加权了,查询时设置权重,6.6版本后创建索引设置权重值已经被废弃,并提供了两种新的加权方式就是BoostsQuery 和语法查询时多默认域的扩展可以使用,上面例子里有,可自行选择,
五 索引维护
最后就是索引的更新,删除,恢复了,这个没多大区别,主要是创建,查询时候有恨多不一样的地方,还有一点就是文档的编码一定要对,否则会索引不到
//按条件删除
@Test
public void testDelete() throws Exception{
IndexWriter indexWriter = getIndexWriter();
Query query=new TermQuery(new Term("fileContent","老阴逼"));
indexWriter.deleteDocuments(query);//可传入多个参数
indexWriter.close();
}
//全删除
@Test
public void testDeleteAll() throws Exception{
IndexWriter indexWriter = getIndexWriter();
indexWriter.deleteAll();
//强制删除,不会恢复
//indexWriter.forceMergeDeletes();
indexWriter.close();
}
//更新
@Test
public void testUpdate() throws Exception{
IndexWriter indexWriter = getIndexWriter();
Document doc =new Document();
doc.add(new TextField("","",Store.YES));
// .... 修改的内容
indexWriter.updateDocument(new Term("fileName","词语"), doc);
indexWriter.close();
}
//恢复,从回收站恢复
@Test
public void testDELETE() throws Exception{
IndexWriter indexWriter = getIndexWriter();
indexWriter.rollback();
}
Lucene7.1.0版本的索引创建与查询以及维护,包括新版本的一些新特性探索!的更多相关文章
- MongoDB地理空间(2d)索引创建与查询
LBS(Location Based Services)定位服务,即根据用户位置查询用户附近相关信息,这一功能在很多应用上都有所使用.基于用户位置进行查询时,需要提供用户位置的经纬度.为了提高查询速度 ...
- SpringCloud-Greenwich版本新特性探索(1)---SpringCloudGateway
一.前言 1.SpringCloudGateway是SpringCloud新推出的网关框架,比较于上一代Zuul,功能和性能有很大的提升.Zuul1.x采用的是阻塞多线程方式,也就是一个线程处理一个连 ...
- Spring Boot 2.3.0正式发布:优雅停机、配置文件位置通配符新特性一览
当大潮退去,才知道谁在裸泳..关注公众号[BAT的乌托邦]开启专栏式学习,拒绝浅尝辄止.本文 https://www.yourbatman.cn 已收录,里面一并有Spring技术栈.MyBatis. ...
- Servlet2.5版本和Servlet3.0版本
在学习这节之前你需要在你自己的电脑进行如下配置: 配置Java运行环境:JDK+JRE的安装配置,参考博客Windows下配置Java开发环境: 安装Eclipse:参考博客Windows下配置Jav ...
- cocos2dx2.0 与cocos2dx3.1 创建线程不同方式总结
尽管内容是抄过来的.可是经过了我的验证.并且放在一起就清楚非常多了,cocos2dx版本号常常变化非常大.总会导致这样那样的问题. cocos2dx2.0 中 1. 头文件 #include < ...
- MySQL 8.0 新特性梳理汇总
一 历史版本发布回顾 从上图可以看出,基本遵循 5+3+3 模式 5---GA发布后,5年 就停止通用常规的更新了(功能不再更新了): 3---企业版的,+3年功能不再更新了: 3 ---完全停止更新 ...
- 精进不休 .NET 4.5 (12) - ADO.NET Entity Framework 6.0 新特性, WCF Data Services 5.6 新特性
[索引页][源码下载] 精进不休 .NET 4.5 (12) - ADO.NET Entity Framework 6.0 新特性, WCF Data Services 5.6 新特性 作者:weba ...
- Servlet 3.0 新特性
Servlet 3.0 作为 Java EE 6 规范体系中一员,随着 Java EE 6 规范一起发布.该版本在前一版本(Servlet 2.5)的基础上提供了若干新特性用于简化 Web 应用的开发 ...
- [iOS微博项目 - 1.7] - 版本新特性
A.版本新特性 1.需求 第一次使用新版本的时候,不直接进入app,而是展示新特性界面 github: https://github.com/hellovoidworld/HVWWeibo ...
随机推荐
- 深入理解JAVA虚拟机阅读笔记2——垃圾回收
线程私有的程序计数器.虚拟机栈和本地方法栈随线程而生,随线程而灭.栈中的栈帧随方法的进入和退出有条不紊的入栈和出栈. 而Java堆和方法区因为需要多大内存.创建多少对象都是不确定的,因此这两个区域是垃 ...
- 【移动端debug-5】可恶的1px万能实现方案
最近和设计同学调ui,遇到的是一位对1px有极致追求的同学,像素眼一眼看出我写的是不是1px,所以让我好好地研究了一番1px到底怎么写最方便. 一.为什么出不来1px? 简而言之:css的1px只是一 ...
- oracle 存储过程创建报错 Procedure created with compilation errors
出现这错误的话,存储过程还是会成功创建的,创建好后再逐个打开查找存储过程的问题 问题:基本上就是存储过程里面的表不存在,dblink 不存在 ,用户名.xx表 要么用户名不存在要么表不存在 创 ...
- 【算法】Tarjan大锦集
Task1 Description 一位冷血的杀手潜入 Na-wiat,并假装成平民.警察希望能在 N 个人里面,查出谁是杀手. 警察能够对每一个人进行查证,假如查证的对象是平民,他会告诉警察,他认识 ...
- 【bzoj4016】 FJOI2014—最短路径树问题
http://www.lydsy.com/JudgeOnline/problem.php?id=4016 (题目链接) 题意 给出一张无向图,求出它的最小路径树,然后求最小路径树上节点数为${K}$的 ...
- Redis事务介绍
概述 相信学过Mysql等其他数据库的同学对事务这个词都不陌生,事务表示的是一组动作,这组动作要么全部执行,要么全部不执行.为什么会有这样的需求呢?看看下面的场景: 微博是一个弱关系型社交网络,用户之 ...
- UML类图与类间六种关系表示
UML类图与类间六种关系表示 1.类与类图 类封装了数据和行为,是面向对象的重要组成部分,它是具有相同属性,操作,关系的对象集合的总称. 类图是使用频率最高的UML图之一. 类图用于描述系统中所包含的 ...
- Git1:Git简介
目录 什么是版本控制系统 集中式版本控制系统 分布式版本控制系统 Git起源 Git特性 什么是版本控制系统 版本控制系统是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统.版本控制 ...
- ElasticStack系列之十六 & ElasticSearch5.x index/create 和 update 源码分析
开篇 在ElasticSearch 系列十四中提到的问题即 ElasticStack系列之十四 & ElasticSearch5.x bulk update 中重复 id 性能骤降,继续这个问 ...
- 2017年Java面试题整理
原文出处:CSDN邓帅 面试是我们每个人都要经历的事情,大部分人且不止一次,这里给大家总结最新的2016年面试题,让大家在找工作时候能够事半功倍. 1.Switch能否用string做参数? a.在 ...