结队第二次作业——WordCount进阶需求
结队第二次作业——WordCount进阶需求
博客地址
051601135 岳冠宇 博客地址
051604103 陈思孝 博客地址
Github地址
具体分工
队友实现了爬虫功能,我实现了wordcount代码部分
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | 910 | 870 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 70 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 50 | 30 |
| · Coding | · 具体编码 | 700 | 650 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 120 | 130 |
| · Test Repor | · 测试报告 | 90 | 90 |
| · Size Measurement | · 计算工作量 | 0 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 40 |
| | 合计 |1060 |1035
解题思路与设计实现
爬虫实用
因为之前学过python,知道用python做爬虫很方便,于是就用python写了一个小程序爬取论文信息。
核心模块是BeautifulSoup,用来处理网页的信息和爬取需要的内容
思路:先得到论文主页的网址,根据网页的源代码信息获得每篇论文的地址,再分别分析每个网页的源代码,定位标题标签和摘要标签,然后爬取信息,写入文件。
homeurl="http://openaccess.thecvf.com/CVPR2018.py"
file = urllib.request.urlopen(homeurl).read()
page = BeautifulSoup(file , "html.parser")
得到主页的网页内容,并转码。
for link in page.find_all("dt",class_="ptitle"):
uuu=link.find('a')
url=str(uuu.get('href'))
定位每篇论文的网址,需要注意的是从网页源代码得到的网址不能直接用,要在前面加上http://openaccess.thecvf.com/才是完整的网址。
title = re.findall('
',page1.decode('utf-8'),re.S)
abstract=re.findall('
',page1.decode('utf-8'),re.S)
通过正则表达式定位和提取标题和摘要信息
最后写入文本文件,值得注意的是我们我们爬取的信息的格式是utf-8,但是记事本写入的默认格式是GBK,有些英文是不能识别的,会报错,
f=open(r'C:\Users\csxcs\Desktop\result.txt','w',encoding='utf-8')
打开文件时要设置一下。
爬取过程如下,运行..py程序即可,可能是网络问题,打开网页的速度很慢,爬取所有的论文也需要一段时间。


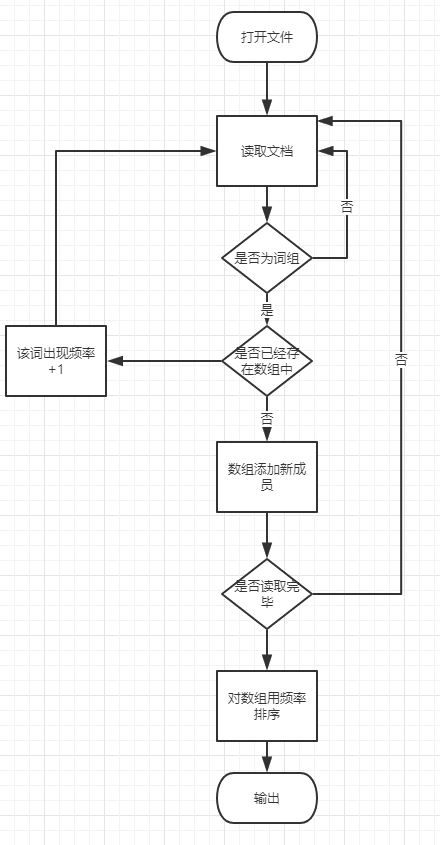
代码实现
代码组织与内部实现设计(类图)
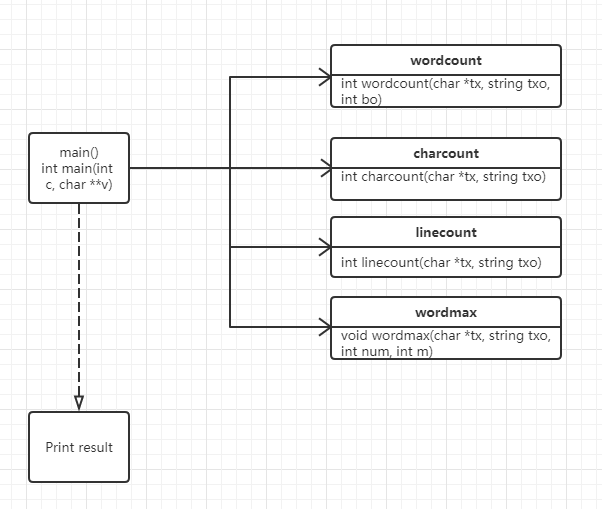

代码的关键与关键部分流程图
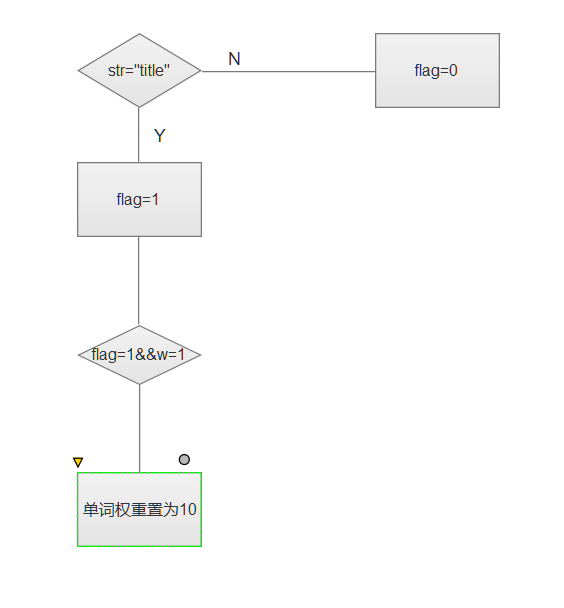
处理新增权重的要求
先定位title和abstract标签的位置,设置flag。遇到title,flag置为1,并且w=1,后面的统计单词权重置为10,遇到abstarct,flag置为0。
关键代码解释
int wordcnt = 0;
int k, i, j, x=1, y=1;
if (bo == 1)
y = 10;
char p,m;
while (!feof(fp))
{
char c = getc(fp);
if ((c >= 'a'&&c <= 'z') || (c >= 'A'&&c <= 'Z'))//可能是单词
{
k = 0;//从第0位开始判断
while ((c >= 'a'&&c <= 'z') || (c >= 'A'&&c <= 'Z') || (c >= '0'&&c <= '9'&&k >= 4))//继续后几位的验证
{
if (c >= 'A'&&c <= 'Z')//大写改小写
{
c = c + 32;
}
temp.s[k] = c;
m = temp.s[k];
k++;//下一位
c = getc(fp);
p = c;
if (c == ':'&&m == 'e')
temp.bl = y;
if (c == ':'&&m == 't')
temp.bl = x;//改变权重
}
temp.s[k] = '\0';//结束标识
k++;//此词位数+1
j = n;
if (strlen(temp.s) >= 4)//确保大于4位英文字母
{
wordcnt++;//词频置1
if (temp.bl == y)
temp.frq = y;
if (temp.bl == x)
temp.frq = x;
}
性能改进及分析

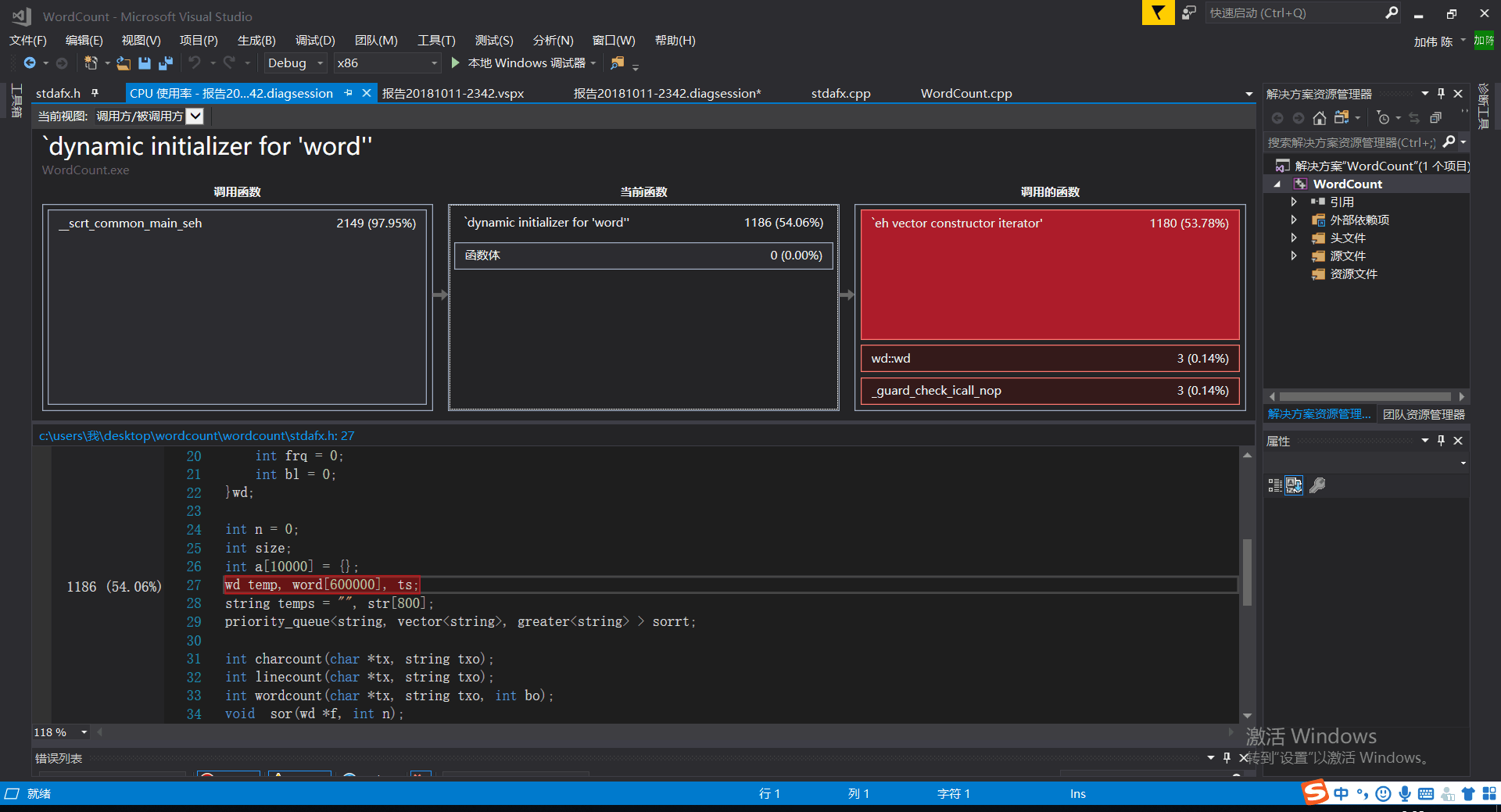
可以看出,时间主要消耗在了创建数组上,而且整个代码效率不高。
改进思路
可以用链表STL map工具来实现这次作业,效率能高很多,而且对空间的利用恰到好处
单元测试
对实现的每个功能模块进行单元测试,assert断言判断正确与否,同一个模块用不同的文本测试。
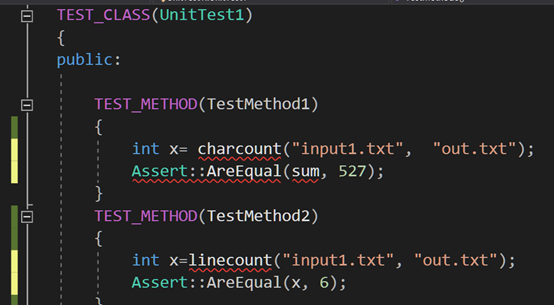
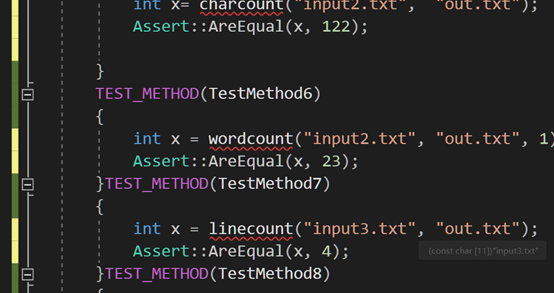
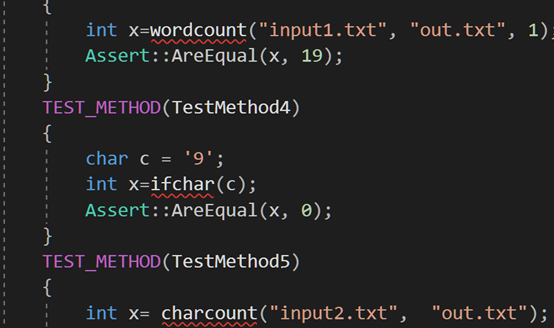
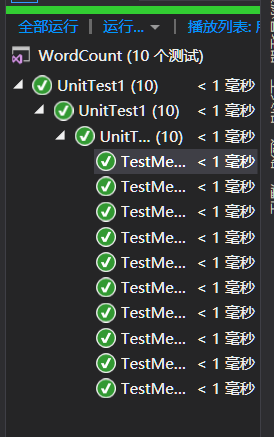
遇到的代码模块异常或结对困难及解决方法
- 问题描述
我使用数组来实现主要功能,后来发现不知道材料具体长度只能创建的足够大,浪费了很多空间和时间,还有可能越界。 - 解决方案
使用链表和STL map可以使整个代码优化很多。 - 体会
写代码对制定算法大方向和使用的数据结构要进行深刻的分析。
贴出Github的代码签入记录
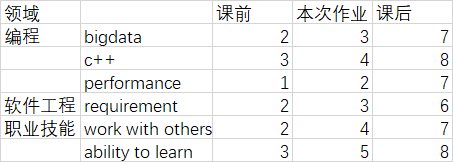
学习进度条
评价队友
行动力强,是个大佬。
结队第二次作业——WordCount进阶需求的更多相关文章
- 第二次结对作业-WordCount进阶需求
原博客 队友博客 github项目地址 目录 具体分工 需求分析 PSP表格 解题思路描述与设计实现说明 爬虫使用 代码组织与内部实现设计(类图) 算法的关键与关键实现部分流程图 附加题设计与展示 设 ...
- 《软件工程实践》第五次作业-WordCount进阶需求 (结对第二次)
在文章开头给出结对同学的博客链接.本作业博客的链接.你所Fork的同名仓库的Github项目地址 本作业博客链接 github pair c 031602136魏璐炜博客 031602139徐明盛博客 ...
- 软工实践第五次作业-WordCount进阶需求
软工实践作业(五) GitHub 作业链接 结对博客 031602240 具体分工 PSP表格 代码规范 解题思路与设计说明 爬虫使用 代码组织与内部实现设计(类图) 算法关键 实现方法 流程图 附加 ...
- 结对第2次作业——WordCount进阶需求
作业题目链接 队友链接 Fork的同名仓库的Github项目地址 具体分工 玮哥负责命令参数判断.单词权重统计,我只负责词组词频统计(emmmm). PSP表格 预估耗时(分钟) 实际耗时(分钟) P ...
- 软工实践——结对作业2【wordCount进阶需求】
附录: 队友的博客链接 本次作业的博客链接 同名仓库项目地址 一.具体分工 我负责撰写爬虫爬取信息以及代码整合测试,队友子恒负责写词组词频统计功能的代码. 二.PSP表格 PSP2.1 Persona ...
- 结对作业-WordCount进阶版
1.在文章开头给出博客作业要求地址. 博客园地址:https://www.cnblogs.com/happyzm/p/9559372.html 2.给出结对小伙伴的学号.博客地址,结对项目的码云地址. ...
- 软件质量与测试--第二周作业 WordCount
github地址: https://github.com/wzfhuster/software_test_tasks psp表格: PSP2.1 PSP 阶段 预估耗时 (分钟) 实际耗时 (分钟) ...
- 软件测试第二周作业 WordCount
本人github地址: https://github.com/wenthehandsome23 psp阶段 预估耗时 (分钟) 实际耗时 (分钟) 计划 30 10 估计这个任务需要多少时间 20 ...
- 结对作业——WordCount进阶版
Deadline: 2018-10-7 22:00PM,以博客提交至班级博客时间为准 要求参考来自:https://www.cnblogs.com/xinz/archive/2011/11/27/22 ...
随机推荐
- PostgreSQL PITR实验
磨砺技术珠矶,践行数据之道,追求卓越价值 回到上一级页面: PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页 看PostgreSQL中与PITR相关的设定 ...
- 二维码Data Matrix编码、解码使用举例
二维码Data Matrix的介绍见: http://blog.csdn.net/fengbingchun/article/details/44279967 ,这里简单写了个生成二维码和对二维码进行 ...
- BZOJ 2395 [Balkan 2011]Time is money
题面 题解 将\(\sum_i c_i\)和\(\sum_i t_i\)分别看做分别看做\(x\)和\(y\),投射到平面直角坐标系中,于是就是找\(xy\)最小的点 于是可以先找出\(x\)最小的点 ...
- Kubernetes学习之路(二)之ETCD集群二进制部署
ETCD集群部署 所有持久化的状态信息以KV的形式存储在ETCD中.类似zookeeper,提供分布式协调服务.之所以说kubenetes各个组件是无状态的,就是因为其中把数据都存放在ETCD中.由于 ...
- spark遇到的一些问题及其解决办法
1.报错:ERROR storage.DiskBlockObjectWriter: Uncaught exception while reverting partial writes to file ...
- 5 行 Python 代码调用电脑摄像头
前提: 确保 python 中安装了 opencv-python 模块.如果没有安装,可以参考:https://pypi.org/project/opencv-python/ 进行安装.话不多少,直接 ...
- TensorFlow Python3.7环境下的源码编译(一)环境准备
参考: https://blog.csdn.net/yhily2008/article/details/79967118 https://tensorflow.google.cn/install/in ...
- 中国的互联网企业逐步走向“单一企业多样化,商业生态同质化”,美国的互联网企业则会走向“单一企业专业化,商业生态多样化”:3.5星|《VUCA时代,想要成功,这些原则你一定得明白》
VUCA时代,想要成功,这些原则你一定得明白(<哈佛商业评论>增刊) <哈佛商业评论>的10篇文章的合集.主题是VUCA时代,也就是当前复杂多变难预测的时代.大部分文章都是点到 ...
- java多线程相关代码
1.创建线程的三种方式 使用Thread package com.wpbxx.test; //1.自定义一个类,继承java.lang包下的Thread类 class MyThread extends ...
- texlive2018和texstudio的安装及汉化教程
latex是编写论文的利器,尤其是公式的编辑是word等不可比的,且公式可以支持转换为Matgtype,十分方便且学习周期短. 下文是texlive2018和texstudio的安装教程: 本文转自: ...