scrapy爬虫,爬取图片
一、scrapy的安装:
本文基于Anacoda3,
Anacoda2和3如何同时安装?
将Anacoda3安装在C:\ProgramData\Anaconda2\envs文件夹中即可。
如何用conda安装scrapy?
安装了Anaconda2和3后,

如图,只有一个命令框,可以看到打开的时候:
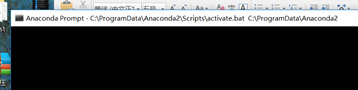
可以切到Anaconda3对应的路径下即可。
安装的方法:cmd中:conda install scrapy即可。
当然,可能会出现权限的问题,那是因为安装的文件夹禁止了读写。可以如图:
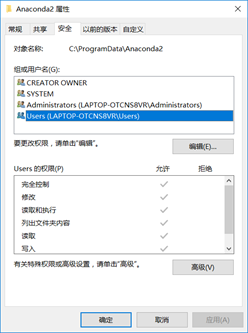
将权限都设为“允许“。
注意:此时虽然scapy安装上了,但是在cmd中输入scapy可能会不认,可以将安装scrapy.exe的路径添加到环境变量中。
二、scapy的简单使用
例子:爬取图片
1、 创建scrapy工程
譬如,想要创建工程名:testImage
输入:scrapy startproject testImage
即可创建该工程,按照cmd中提示的依次输入:
cd testImage
scrapy genspider getPhoto www.27270.com/word/dongwushijie/2013/4850.html
其中:在当前项目中创建spider,这仅仅是创建spider的一种快捷方法,该方法可以使用提前定义好的模板来生成spider,后面的网址是一个采集网址的集合,即为允许访问域名的一个判断。注意不要加http/https。
至此,可以在testImage\testImage\spiders中找到创建好的爬虫getPhoto.py,可以在此基础上进行修改。
2、创建爬虫
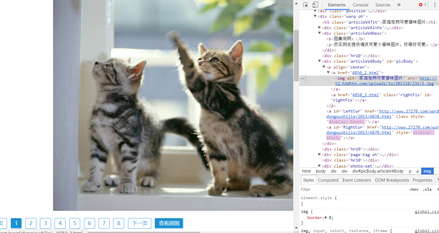
如图,可以在图片的位置右键,检查,查看源码,在图片所在的位置处,将xpath拷贝出来。
此时,可以找出图片的地址:
class GetphotoSpider(scrapy.Spider):
name = 'getPhoto'
allowed_domains = ['www.27270.com']
start_urls = ['http://www.27270.com/word/dongwushijie/2013/4850.html']
def parse(self, response):
urlImage = response.xpath('//*[@id="picBody"]/p/a[1]/img/@src').extract()
print(urlImage)
pass
此时,注意网络路径的正确书写,最后没有/,
http://www.27270.com/word/dongwushijie/2013/4850.html/
此时将4850.html 当作了目录,会出现404找不到路径的错误!
3、 下载图片
items.py:
class PhotoItem(scrapy.Item):
name = scrapy.Field()
imageLink = scrapy.Field()
pipelines.py:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class ImagePipeline(ImagesPipeline):
def get_media_requests(self,item,info):
image_link = item['imageLink']
yield scrapy.Request(image_link)
settings.py:
IMAGES_STORE = r"C:\Users\24630\Desktop\test"
另外,对于上面的网址,还需要ROBOTSTXT_OBEY = False
并且,访问该网址会出现302错误,这是一个重定向的问题,
MEDIA_ALLOW_REDIRECTS =True
设置该选项,就可以正确下载,但是下载的还是不对,问题不好解决。
当然在爬虫中,还要对items赋值:
from testImage import items
。。。 for urllink in urlImage:
item = items.PhotoItem()
item['imageLink'] = urllink
三、 进一步爬取(读取下一页)
# -*- coding: utf-8 -*-
import scrapy
from testImage import items
class GetphotoSpider(scrapy.Spider):
name = 'getPhoto'
allowed_domains = ['www.wmpic.me']
start_urls = ['http://www.wmpic.me/93912']
def parse(self, response):
#//*[@id="content"]/div[1]/p/a[2]/img
urlImage = response.xpath('//*[@id="content"]/div[1]/p/a/img/@src').extract()
print(urlImage)
for urllink in urlImage:
item = items.PhotoItem()
item['imageLink'] = urllink
yield item ifnext = response.xpath('//*[@id="content"]/div[2]/text()').extract()[0]
# 当没有下一篇,即最后一页停止爬取
if("下一篇" in ifnext):
nextUrl = response.xpath('//*[@id="content"]/div[2]/a/@href').extract()[0]
url=response.urljoin(nextUrl)
yield scrapy.Request(url=url)
此时,便可以看到路径下的下载后的文件了。(由于该网址每页的图片所在的xpath都不一样,故下载的图片不全)
scrapy爬虫,爬取图片的更多相关文章
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
- 使用scrapy框架爬取图片网全站图片(二十多万张),并打包成exe可执行文件
目标网站:https://www.mn52.com/ 本文代码已上传至git和百度网盘,链接分享在文末 网站概览 目标,使用scrapy框架抓取全部图片并分类保存到本地. 1.创建scrapy项目 s ...
- Python 爬虫 爬取图片入门
爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 用户看到的网页实质是由 HTML 代码构成的,爬 ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- <scrapy爬虫>爬取校花信息及图片
1.创建scrapy项目 dos窗口输入: scrapy startproject xiaohuar cd xiaohuar 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- 使用scrapy ImagesPipeline爬取图片资源
这是一个使用scrapy的ImagesPipeline爬取下载图片的示例,生成的图片保存在爬虫的full文件夹里. scrapy startproject DoubanImgs cd DoubanIm ...
- <scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)
1.创建scrapy项目 dos窗口输入: scrapy startproject images360 cd images360 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) ...
随机推荐
- django的缓存,信号,序列化
一 Django的缓存机制 1.1 缓存介绍 1.缓存的简介 在动态网站中,用户所有的请求,服务器都会去数据库中进行相应的增,删,查,改,渲染模板,执行业务逻辑,最后生成用户看到的页面. 当一个网站的 ...
- Linux基础-yum软件包管理
任务目标:自定义yum仓库:createrepo,自定义repo文件,使用yum命令安装httpd软件包,卸载httpd软件包:yum –y remove 软件名 ,使用yum安装组件'KDE 桌面' ...
- 《区块链100问》第73集:达世币Dash是什么?
达世币诞生于2014年1月18日,匿名程度较比特币更高. 达世币有三种转账方式,一是像比特币一样的普通转账:二是即时交易.不需要矿工打包确认,就可以确认交易,几乎可以实现秒到:三是匿名交易.从区块链上 ...
- [转]ubuntu16.04~qt 5.8无法输入中文
编译fcitx-qt需要cmake,安装cmake命令,如果已经安装,请略过. sudo apt-get install cmake 安装 fcitx-libs-dev sudo apt-get in ...
- MySQL分布式集群之MyCAT(三)rule的分析【转】
首先写在最前面,MyCAT1.4的alpha版本已经发布了,这里面修复了不少的bug,也完善了一细节,之前两篇博客已经做了一些修改 ---------------------------------- ...
- jQuery-对标签的样式操作
一.操作样式类 // 1.给标签添加样式类 $("选择器").addClass("类名") // 2.移除标签的样式类 $("选择器").r ...
- RobotFramework安装扩展库包autoitlibrary(四)
Robot Framework扩展库包 http://robotframework.org/#libraries 一,自动化测试PC端程序 1, 安装pywin32(autoitlibrary使用需 ...
- ipad webapp禁止长按选择
1.禁止长按屏幕弹出对话框并选中文字 /*禁止长按选择文字事件*/ * { -webkit-touch-callout: none; -webkit-user-select: none; -khtml ...
- 洛谷P1038神经网络
传送门啦 一个拓扑排序的题,感觉题目好难懂... #include <iostream> #include <cstdio> #include <cstring> ...
- 洛谷P2341受欢迎的牛
传送门啦 这是一个tarjan强连通分量与出度结合的例题. 先明确一下题意,如果这个点(缩点之后的)没有出度,这个点才能成为明星牛(明星牛的定义是:所有牛都喜欢他才可以). 由于我们进行了缩点,所以我 ...