Sequence Classification
Natural Language Processing with Python
Charpter 6.1
import nltk
from nltk.corpus import brown def pos_features(sentence,i,history):
features = {"suffix(1)":sentence[i][-1:],
"suffix(2)":sentence[i][-2:],
"suffix(3)":sentence[i][-3:]}
if i == 0:
features["prev-word"]="<STAR>"
features["prev_tag"] ="<STAR>"
else:
features["prev_word"]=sentence[i-1]
features["prev_tag"]=history[i-1]
return features class ConsecutivePosTagger(nltk.TaggerI):
def __init__(self,train_sents):
train_set=[]
for tagged_sent in train_sents:
history=[]
untagged_sent = nltk.tag.untag(tagged_sent)
for i,(word,tag) in enumerate(tagged_sent):
featureset=pos_features(untagged_sent,i,history)
train_set.append((featureset,tag))
history.append(tag)
self.classifier=nltk.NaiveBayesClassifier.train(train_set) def tag(self,sentence):
history=[]
for i,word in enumerate(sentence):
featureset=pos_features(sentence,i,history)
tag=self.classifier.classify(featureset)
history.append(tag)
return zip(sentence,history) def test_ConsecutivePosTagger():
tagged_sents=brown.tagged_sents(categories='news')
size = int(len(tagged_sents) * 0.1)
train_sents, test_sents = tagged_sents[size:], tagged_sents[:size]
tagger = ConsecutivePosTagger(train_sents) print tagger.evaluate(test_sents)
流程为:
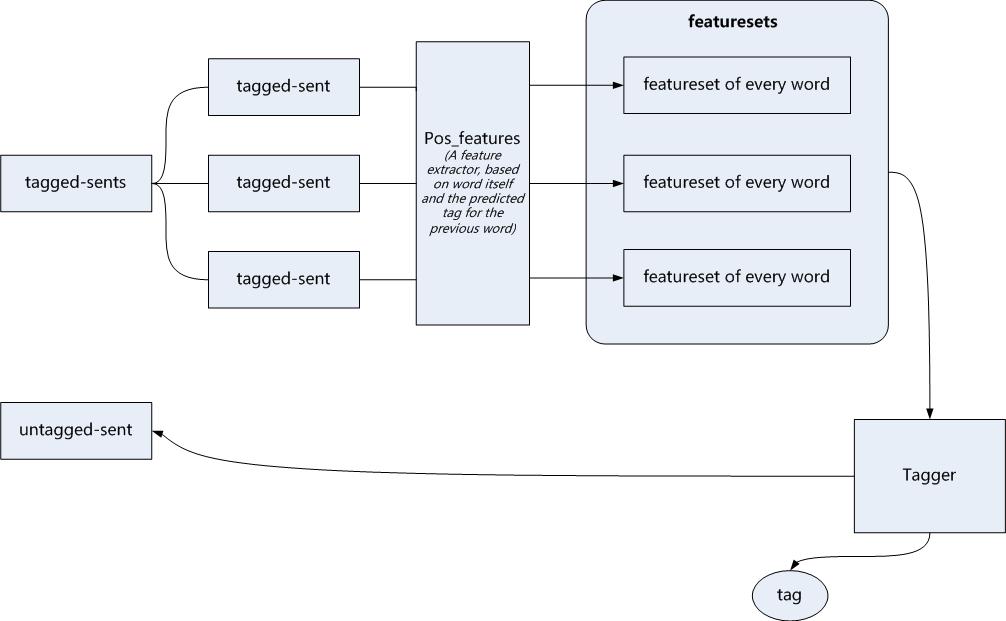
结果为:
0.796940194715
Sequence Classification的更多相关文章
- Kraken taxonomic sequence classification system
kraken:是一个将分类标签打到短DNAreads上的分类序列器.
- .NET平台开源项目速览(13)机器学习组件Accord.NET框架功能介绍
Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET Framework更注重与机器 ...
- RNN,写起来真的烦
曾经,为了处理一些序列相关的数据,我稍微了解了一点递归网络 (RNN) 的东西.由于当时只会 tensorflow,就从官网上找了一些 tensorflow 相关的 demo,中间陆陆续续折腾了两个多 ...
- 文本分类实战(十)—— BERT 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- Accord.NET Framework 介绍
阅读目录 1.基本功能与介绍 Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET ...
- [Tensorflow] RNN - 02. Movie Review Sentiment Prediction with LSTM
From: Predicting Movie Review Sentiment with TensorFlow and TensorBoard Ref: http://www.cnblogs.com/ ...
- 自然语言处理领域重要论文&资源全索引
自然语言处理(NLP)是人工智能研究中极具挑战的一个分支.随着深度学习等技术的引入,NLP领域正在以前所未有的速度向前发展.但对于初学者来说,这一领域目前有哪些研究和资源是必读的?最近,Kyubyon ...
- [转]NLP Tasks
Natural Language Processing Tasks and Selected References I've been working on several natural langu ...
- .NET数据挖掘与机器学习开源框架
1. 数据挖掘与机器学习开源框架 1.1 框架概述 1.1.1 AForge.NET AForge.NET是一个专门为开发者和研究者基于C#框架设计的,他包括计算机视觉与人工智能,图像处理,神经 ...
随机推荐
- eclipse配置tomcat及修改tomcat默认根目录
1.安装eclipse for j2ee和tomcat: 2.下载tomcat对eclipse的插件:http://www.eclipsetotale.com/tomcatPlugin.html 下载 ...
- # 泰语字符串字符分割 --- UTF-8编码格式
1.泰语编码格式 泰语用的编码格式是:ISO 8859-11,这个是Latin编码系列,是从"ISO-8859-1"发展过来的,采用的是8bit一个字,所以泰语中的英文字母或者数字 ...
- log4j打印出线程号和方法名
先参考实现配置,如果想要更加详细的配置,可加上更多参数: log4j.rootLogger = INFO,FILE,CONSOLE log4j.appender.FILE.Threshold=INFO ...
- WPF从我炫系列4---装饰控件的用法
这一节的讲解中,我将为大家介绍WPF装饰控件的用法,主要为大家讲解一下几个控件的用法. ScrollViewer滚动条控件 Border边框控件 ViewBox自由缩放控件 1. ScrollView ...
- css 重新学习系列(1)
来源: http://www.cnblogs.com/Zigzag/archive/2009/04/16/1394356.html CSS之Position详解(1) CSS的很多其他属性大多容易理解 ...
- LightOJ 1370 Bi-shoe and Phi-shoe 数论
题目大意:f(x)=n 代表1-x中与x互质的数字的个数.给出n个数字a[i],要求f(x)=a[i],求x的和. 思路:每个素数x 有x-1个不大于x的互质数.则f(x)=a[i],若a[i]+1为 ...
- iOS字符串转化成CGFloat
NSString *str = @"abc"; [str floatValue];
- The Rings Akhaten
在其他的平行宇宙中存在着一个古老的星系--Akhaten,星系中有七个世界,上面生活着Panbabylonian.Lucanian等物种,不过外界也常常把他们统称为Akhet,因为这七个世界环绕着同一 ...
- unity LineRenderer
using UnityEngine; using System.Collections; public class Spider:MonoBehaviour { private LineRendere ...
- java 内存分配全面解析
JVM是什么? 首先要知道的是Java程序运行在JVM(Java Virtual Machine,Java虚拟机)上;可以把JVM理解成Java程序和操作系统之间的桥梁,JVM实现了 Java的平台无 ...