Zeppelin使用spark解释器
Zeppelin为0.5.6
Zeppelin默认自带本地spark,可以不依赖任何集群,下载bin包,解压安装就可以使用。
使用其他的spark集群在yarn模式下。
配置:
vi zeppelin-env.sh

添加:
export SPARK_HOME=/usr/crh/current/spark-client
export SPARK_SUBMIT_OPTIONS="--driver-memory 512M --executor-memory 1G"
export HADOOP_CONF_DIR=/etc/hadoop/conf
Zeppelin Interpreter配置

注意:设置完重启解释器。
Properties的master属性如下:

新建Notebook
Tips:几个月前zeppelin还是0.5.6,现在最新0.6.2,zeppelin 0.5.6写notebook时前面必须加%spark,而0.6.2若什么也不加就默认是scala语言。
zeppelin 0.5.6不加就报如下错:
Connect to 'databank:4300' failed
%spark.sql
select count(*) from tc.gjl_test0
报错:
com.fasterxml.jackson.databind.JsonMappingException: Could not find creator property with name 'id' (in class org.apache.spark.rdd.RDDOperationScope)
at [Source: {"id":"2","name":"ConvertToSafe"}; line: 1, column: 1]
at com.fasterxml.jackson.databind.JsonMappingException.from(JsonMappingException.java:148)
at com.fasterxml.jackson.databind.DeserializationContext.mappingException(DeserializationContext.java:843)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.addBeanProps(BeanDeserializerFactory.java:533)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.buildBeanDeserializer(BeanDeserializerFactory.java:220)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.createBeanDeserializer(BeanDeserializerFactory.java:143)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer2(DeserializerCache.java:409)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer(DeserializerCache.java:358)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCache2(DeserializerCache.java:265)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCacheValueDeserializer(DeserializerCache.java:245)
at com.fasterxml.jackson.databind.deser.DeserializerCache.findValueDeserializer(DeserializerCache.java:143)
at com.fasterxml.jackson.databind.DeserializationContext.findRootValueDeserializer(DeserializationContext.java:439)
at com.fasterxml.jackson.databind.ObjectMapper._findRootDeserializer(ObjectMapper.java:3666)
at com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:3558)
at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:2578)
at org.apache.spark.rdd.RDDOperationScope$.fromJson(RDDOperationScope.scala:85)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at scala.Option.map(Option.scala:145)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:136)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.ConvertToSafe.doExecute(rowFormatConverters.scala:56)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:130)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:187)
at org.apache.spark.sql.execution.Limit.executeCollect(basicOperators.scala:165)
at org.apache.spark.sql.execution.SparkPlan.executeCollectPublic(SparkPlan.scala:174)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:56)
at org.apache.spark.sql.DataFrame.withNewExecutionId(DataFrame.scala:2086)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$execute$1(DataFrame.scala:1498)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$collect(DataFrame.scala:1505)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1375)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.withCallback(DataFrame.scala:2099)
at org.apache.spark.sql.DataFrame.head(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.take(DataFrame.scala:1456)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.zeppelin.spark.ZeppelinContext.showDF(ZeppelinContext.java:297)
at org.apache.zeppelin.spark.SparkSqlInterpreter.interpret(SparkSqlInterpreter.java:144)
at org.apache.zeppelin.interpreter.ClassloaderInterpreter.interpret(ClassloaderInterpreter.java:57)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:93)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:300)
at org.apache.zeppelin.scheduler.Job.run(Job.java:169)
at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:134)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
原因:
进入/opt/zeppelin-0.5.6-incubating-bin-all目录下:
# ls lib |grep jackson
jackson-annotations-2.5.0.jar
jackson-core-2.5.3.jar
jackson-databind-2.5.3.jar
将里面的版本换成如下版本:
# ls lib |grep jackson
jackson-annotations-2.4.4.jar
jackson-core-2.4.4.jar
jackson-databind-2.4.4.jar
测试成功!
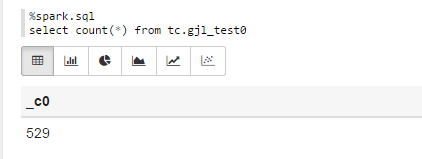
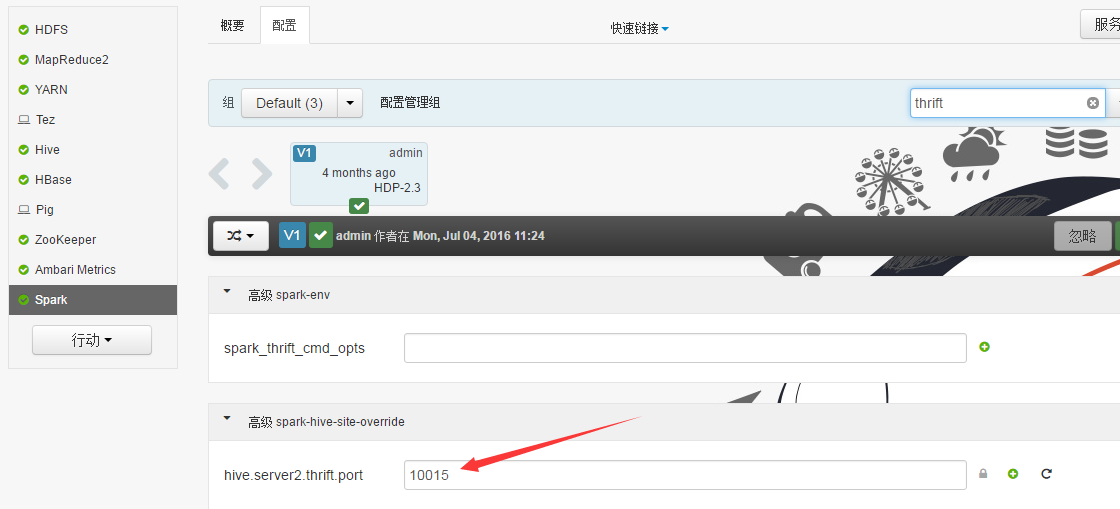
Sparksql也可直接通过hive jdbc连接,只需换端口,如下图:

Zeppelin使用spark解释器的更多相关文章
- Zeppelin使用Spark的yarn-client模式
Zeppelin版本0.6.2 1. Export SPARK_HOME In conf/zeppelin-env.sh, export SPARK_HOME environment variable ...
- Zeppelin0.5.6使用spark解释器
Zeppelin为0.5.6 Zeppelin默认自带本地spark,可以不依赖任何集群,下载bin包,解压安装就可以使用. 使用其他的spark集群在yarn模式下. 配置: vi zeppelin ...
- Zeppelin添加mysql解释器
安装Apache zeppelin 1 wget http://apache.fayea.com/zeppelin/zeppelin-0.6.2/zeppelin-0.6.2-bin-all.tgz ...
- Zeppelin使用phoenix解释器
Interpreters设置
- Zeppelin 0.6.2使用Spark的yarn-client模式
Zeppelin版本0.6.2 1. Export SPARK_HOME In conf/zeppelin-env.sh, export SPARK_HOME environment variable ...
- Spark实战2:Zeppelin的安装和SparkSQL使用总结
zeppelin是spark的web版本notebook编辑器,相当于ipython的notebook编辑器. 一Zeppelin安装 (前提是spark已经安装好) 1 下载https://zepp ...
- Ubuntu下基于Saprk安装Zeppelin
前言 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析,即一个Web笔记形式的交互式数据查询分析工具,可以在线用scal ...
- Zeppelin原理简介
Zeppelin是一个基于Web的notebook,提供交互数据分析和可视化.后台支持接入多种数据处理引擎,如spark,hive等.支持多种语言: Scala(Apache Spark).Pytho ...
- Spark in meituan http://tech.meituan.com/spark-in-meituan.html
Spark在美团的实践 忽略元数据末尾 回到原数据开始处 引言:Spark美团系列终于凑成三部曲了,Spark很强大应用很广泛, 文中Spark交互式开发平台和作业ETL模板的设计都很有启发借鉴意义. ...
随机推荐
- 仿QQ空间视差效果,ListView.setHeader( )
根据listview的手指移动事件,动态设置listview上面的图片的宽高,并在手指放开的时候 实现图片的动画(随时间变化的动画值) ValueAnimator.ofInt ( ) import a ...
- python新手 实践操作 作业
#有如下值集合 [11,22,33,44,55,66,77,88,99],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中.即: {'k1': 大于66的所 ...
- Linked List - leetcode
138. Copy List with Random Pointer //不从head走 前面加一个dummy node 从dummy走先连head 只需记录当前节点 //这样就不需要考虑是先new ...
- spark yarn任务的executor 无故 timeout之原因分析
问题: 用 spark-submit --master yarn --deploy-mode cluster --driver-memory 2G --num-executors 6 --execu ...
- IOS开发调整UILabel的行间距
CGFloat heih = 20; NSString * cLabelString = @"这是测试UILabel行间距的text.这是测试UILabel行间距的text.n 这是测试 ...
- 简单工厂设计模式(Simple Factory Design Pattern)
[引言]最近在Youtub上面看到一个讲解.net设计模式的视频,其中作者的一个理解让我印象很深刻:所谓的设计模式其实就是运用面向对象编程的思想来解决平时代码中的紧耦合,低扩展的问题.另外一点比较有见 ...
- Python 代码规范
命名 module_name, package_name, ClassName, method_name, ExceptionName, function_name, GLOBAL_VAR_NAME, ...
- Chapter 2 Open Book——37
I couldn't concentrate on Mike's chatter as we walked to Gym, and RE. didn't do much to hold my atte ...
- redis整合spring
最近公司项目有用到 所以找了一下实例.感觉很清晰. 完整项目路径http://www.cnblogs.com/dennisit/p/3614521.html看了一下应该没问题
- [Q]AdobePDF虚拟打印机自动保存PDF
使用打图精灵打印时,选择“Adobe PDF”虚拟打印机打印(注意不选择“打印到文件”),每张图纸都会弹出一个保存对话框,如何避免? 从 操作系统->控制面板->硬件和声音->设备和 ...