为什么是梯度下降?SGD
在机器学习算法中,为了优化损失函数loss function ,我们往往采用梯度下降算法来进行优化。举个例子:
线性SVM的得分函数和损失函数分别为:

一般来说,我们是需要求损失函数的最小值,而损失函数是关于权值矩阵的函数。为了求解权值矩阵,我们一般采用数值求解的方法,但是为什么是梯度呢?
在CS231N课程中给出了解释,首先我们采用
策略1:随机搜寻(不太实用),也就是在一个范围内,任意选择W的值带入到损失函数中,那个损失函数值最小就取谁,这个很不实用。
策略2:随机局部搜索 ,就是在W值的附近,指定一个小方向,沿着这个小方向改变W,将改变方向后的W带入损失函数进行判断。具体步骤是对于一个当前W,我们每次实验和添加δW′,然后看看损失函数是否比当前要低,如果是,就替换掉当前的W。这个方向不明确
策略3 顺着梯度下滑 和策略2对比,实际上上述小方向指定了,也就是说δW′应该等于stepsize*|grad|
然而,为什么是梯度方向呢?上一张图解释:
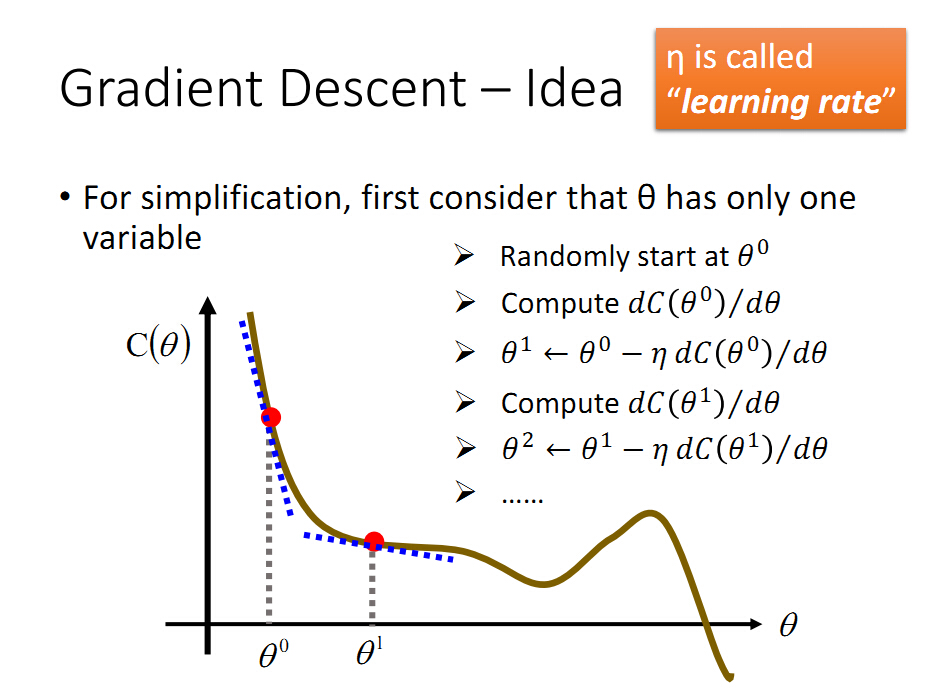
C(θ)是损失函数,θ是权值,为了得到在那个θ下C(θ)最小。一般选取初始点θ0,然后依据上面的搜索策略对θ0进行变更,
但是到底是向前还是向后运动呢?当我们知道图像后,很明显是向前运动,才能使得损失函数变小,但是在我们不知道图像的时候,梯度/导数会告诉我们答案。根据上图可知,在θ0点处的导数,也就是斜率是负的,为了减小损失函数,一般是沿着斜率的负方向运动,也就是
θ1=θ0-ηdc(θ0)/d(θ)
相当于θ1比θ0向正方向运动,也就是向前运动,满足我们的判断。
到此,我们可以看出,梯度下降的方法的步骤就是选择权值一个初始点,然后对权值进行小范围的迭代更新,然而小范围更新的方向为损失函数
对权值选择点的导数负方向,这样就能保证损失函数逐渐取得最小值。
比较三种梯度下降法:批量梯度下降法(Batch Gradient Descent,简称BGD)、随机梯度下降法(Stochastic Gradient Descent,简称SGD)和
小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)
设特征有n+1维度,对应特征向量是X0-XN,系数向量是θ0-θN
每一个特征向量为x(i) ,一共有M个特征向量,或者说M个数据。
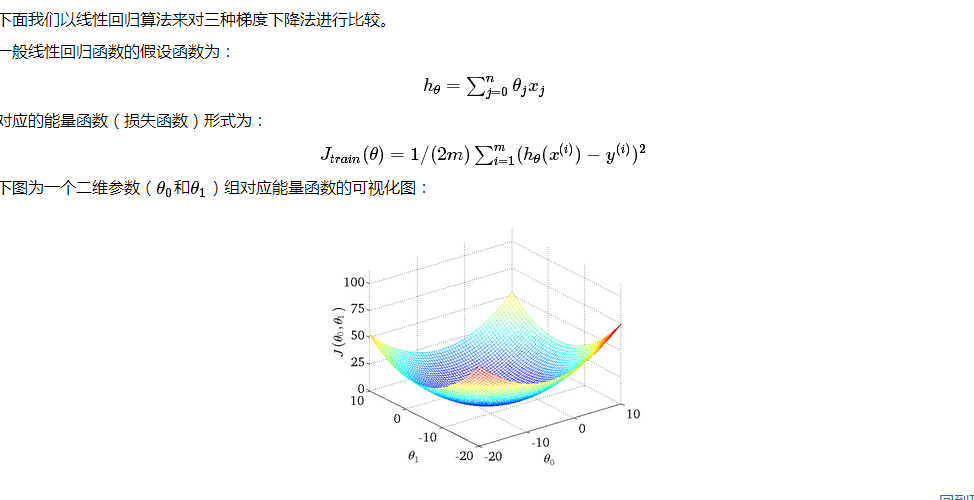
BGD:最原始的梯度下降,它的具体思路是在更新每一参数时都使用所有的样本来进行更新,其数学形式如下:

SGD:由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。
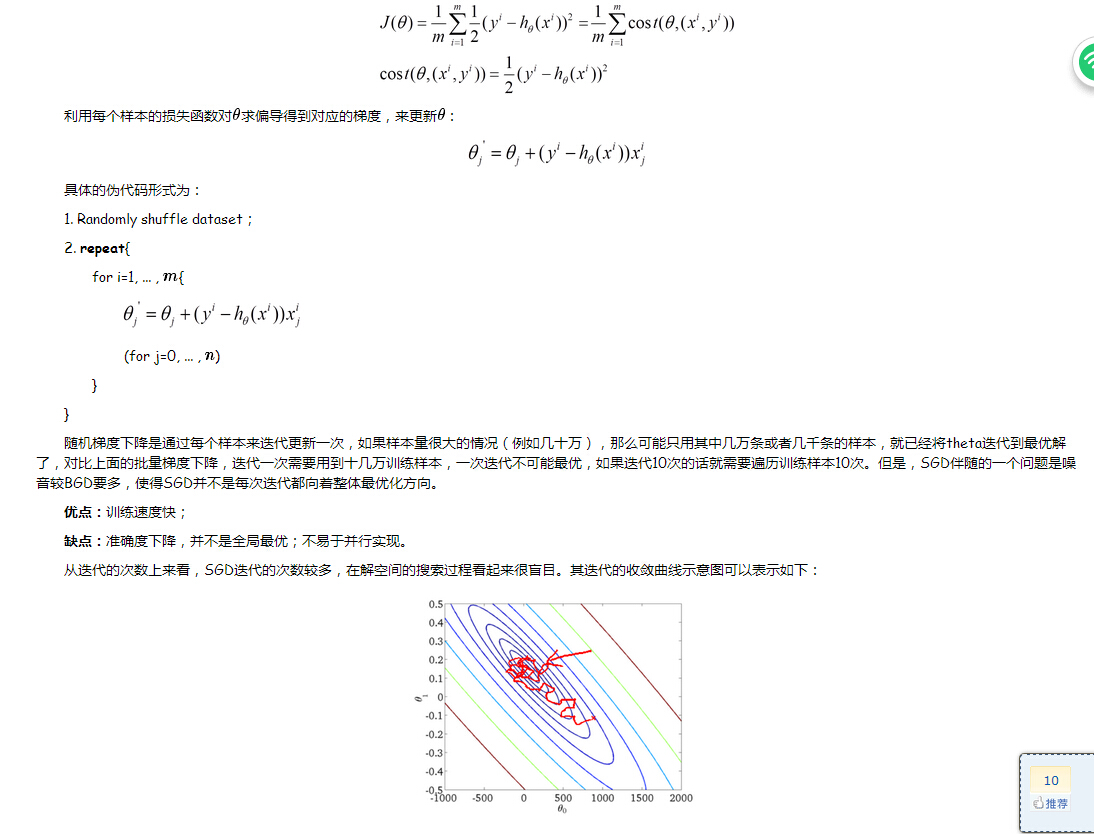
实际上,这个只是把上面的1-M所有的数据求和去掉了,也就是来一个数据更新一次。
MBGD:是一个折中的方案,也就是说M太大了,1太小了,自己定义一个batch值来更新数据,每多少个batch值更新一下权值。

显而易见,只是把上面的M换成了10.
为什么是梯度下降?SGD的更多相关文章
- 优化-最小化损失函数的三种主要方法:梯度下降(BGD)、随机梯度下降(SGD)、mini-batch SGD
优化函数 损失函数 BGD 我们平时说的梯度现将也叫做最速梯度下降,也叫做批量梯度下降(Batch Gradient Descent). 对目标(损失)函数求导 沿导数相反方向移动参数 在梯度下降中, ...
- 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent).随机梯度下降(Stochastic Gradient Descent ...
- [sklearn] 实现随即梯度下降(SGD)&分类器评价参数查看
直接贴代码吧: 1 # -*- coding:UTF-8 -*- 2 from sklearn import datasets 3 from sklearn.cross_validation impo ...
- 梯度下降GD,随机梯度下降SGD,小批量梯度下降MBGD
阅读过程中的其他解释: Batch和miniBatch:(广义)离线和在线的不同
- Pytorch_第七篇_深度学习 (DeepLearning) 基础 [3]---梯度下降
深度学习 (DeepLearning) 基础 [3]---梯度下降法 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数" ...
- 各种梯度下降 bgd sgd mbgd adam
转载 https://blog.csdn.net/itchosen/article/details/77200322 各种神经网络优化算法:从梯度下降到Adam方法 在调整模型更新权重和偏差 ...
- 深度学习笔记之【随机梯度下降(SGD)】
随机梯度下降 几乎所有的深度学习算法都用到了一个非常重要的算法:随机梯度下降(stochastic gradient descent,SGD) 随机梯度下降是梯度下降算法的一个扩展 机器学习中一个反复 ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- 梯度下降:SGD vs Momentum vs NAG vs Adagrad vs Adadelta vs RMSprop vs Adam
原文地址:https://www.jianshu.com/p/7a049ae73f56 梯度下降优化基本公式:\({\theta\leftarrow\theta-\eta\cdot\nabla_\th ...
随机推荐
- Mac中使用port升级gcc版本
Mac OS中的gcc版本可能不会满足实际使用要求,需要对其升级. 这里介绍使用port方式来升级gcc版本.Macports是Mac OS中的软件包管理工具. 首先,安装Macports 这里提供O ...
- 转帖:Python应用性能分析指南
原文:A guide to analyzing Python performance While it’s not always the case that every Python program ...
- javascript 设计模式-----外观模式
外观模式是为外部提供简单的接口一种方式,由于模块内部方法庞杂,不能一一对外公开,那么我们需要一个统一的和简单的对外方法(API)来调用这些内在的函数.这时候我们可以用到外观模式: var module ...
- Javascript事件机制兼容性解决方案
本文的解决方案可以用于Javascript native对象和宿主对象(dom元素),通过以下的方式来绑定和触发事件: 或者 var input = document.getElementsByTag ...
- 第三次作业:PSP耗时
PSP个人项目耗时对比记录表:四则运算 Personal Software Process Stages Time(%) Planning 7 Estimate 9 开发 76 •需求分析 ...
- 认识SQLServer索引以及单列索引和多列索引的不同
一.索引的概念 索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 索引是什么:数据库中的索引类似于一本书的目录,在一本书中使 ...
- NPOIExcelHelper
using System.Data; using System.Configuration; using System.Web; using System.IO; using System.Text; ...
- JS基础知识总结
js基础知识点总结 如何在一个网站或者一个页面,去书写你的js代码:1.js的分层(功能):jquery(tool) 组件(ui) 应用(app),mvc(backboneJs)2.js的规划() ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用青花瓷抓取网络数据
网络爬虫-使用青花瓷抓取网络数据 由于最近在研究网络爬虫相关技术,刚好看到一篇的的搬了过来! 望谅解..... 写本文的契机主要是前段时间有次用青花瓷抓包有一步忘了,在网上查了半天也没找到写的完整的教 ...
- 学习ASP.NET MVC(二)——我的第一个ASP.NET MVC 控制器
MVC全称是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,是一种软件设计典范,用一种业务逻辑和数据显示分离的方法组织代码,将 ...