9.json和jsonpath
数据提取之JSON与JsonPATH
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JSON和XML的比较可谓不相上下。
Python 2.7中自带了JSON模块,直接import json就可以使用了。
官方文档:http://docs.python.org/library/json.html
Json在线解析网站:http://www.json.cn/#
JSON
json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构
对象:对象在js中表示为
{ }括起来的内容,数据结构为{ key:value, key:value, ... }的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。数组:数组在js中是中括号
[ ]括起来的内容,数据结构为["Python", "javascript", "C++", ...],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种。
import json
json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
1. json.loads()
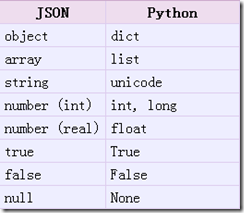
把Json格式字符串解码转换成Python对象 从json到python的类型转化对照如下:
# json_loads.pyimport json
strList = '[1, 2, 3, 4]'
strDict = '{"city": "北京", "name": "大猫"}'
json.loads(strList)
# [, , , ]
json.loads(strDict) # json数据自动按Unicode存储
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u732b'}
2. json.dumps()
实现python类型转化为json字符串,返回一个str对象 把一个Python对象编码转换成Json字符串
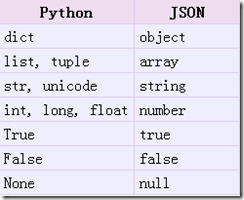
从python原始类型向json类型的转化对照如下:
# json_dumps.pyimport json
import chardet listStr = [, , , ]
tupleStr = (, , , )
dictStr = {"city": "北京", "name": "大猫"} json.dumps(listStr)
# '[1, 2, 3, 4]'
json.dumps(tupleStr)
# '[1, 2, 3, 4]' # 注意:json.dumps() 序列化时默认使用的ascii编码
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
# chardet.detect()返回字典, 其中confidence是检测精确度 json.dumps(dictStr)
# '{"city": "\\u5317\\u4eac", "name": "\\u5927\\u5218"}' chardet.detect(json.dumps(dictStr))
# {'confidence': 1.0, 'encoding': 'ascii'} print json.dumps(dictStr, ensure_ascii=False)
# {"city": "北京", "name": "大刘"} chardet.detect(json.dumps(dictStr, ensure_ascii=False))
# {'confidence': 0.99, 'encoding': 'utf-8'}
chardet是一个非常优秀的编码识别模块,可通过pip安装
3. json.dump()
将Python内置类型序列化为json对象后写入文件
# json_dump.pyimport json
listStr = [{"city": "北京"}, {"name": "大刘"}]
json.dump(listStr, open("listStr.json","w"), ensure_ascii=False)
dictStr = {"city": "北京", "name": "大刘"}
json.dump(dictStr, open("dictStr.json","w"), ensure_ascii=False)
. json.load()
读取文件中json形式的字符串元素 转化成python类型
# json_load.pyimport json
strList = json.load(open("listStr.json"))
print strList
# [{u'city': u'\u5317\u4eac'}, {u'name': u'\u5927\u5218'}]
strDict = json.load(open("dictStr.json"))
print strDict
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u5218'}
JsonPath
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML。
下载地址:https://pypi.python.org/pypi/jsonpath
安装方法:点击
Download URL链接下载jsonpath,解压之后执行python setup.py install
JsonPath与XPath语法对比:
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。
| XPath | JSONPath | 描述 |
|---|---|---|
/ |
$ |
根节点 |
. |
@ |
现行节点 |
/ |
.or[] |
取子节点 |
.. |
n/a | 取父节点,Jsonpath未支持 |
// |
.. |
就是不管位置,选择所有符合条件的条件 |
* |
* |
匹配所有元素节点 |
@ |
n/a | 根据属性访问,Json不支持,因为Json是个Key-value递归结构,不需要。 |
[] |
[] |
迭代器标示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] |
支持迭代器中做多选。 |
[] |
?() |
支持过滤操作. |
| n/a | () |
支持表达式计算 |
() |
n/a | 分组,JsonPath不支持 |
获取拉钩网站json数据
我们以拉勾网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市。
# jsonpath_lagou.pyimport requests
# json解析库,对应到lxml
import json
# json的解析语法,对应到xpath
import jsonpath url = "http://www.lagou.com/lbs/getAllCitySearchLabels.json"
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} response = requests.get(url=url,headers=headers)
# 取出json文件里的内容,返回的格式是字符串
html = response.text
# 把json形式的字符串转换成python形式的Unicode字符串
unicodestr = json.loads(html) # Python形式的列表
city_list = jsonpath.jsonpath(unicodestr, "$..name") # dumps()默认中文为ascii编码格式,ensure_ascii默认为Ture
# 禁用ascii编码格式,返回的Unicode字符串,方便使用
array = json.dumps(city_list, ensure_ascii=False) with open("lagoucity.json", "w",encoding='utf-8') as f:
f.write(array)
注意事项:
json.loads() 是把 Json格式字符串解码转换成Python对象,如果在json.loads的时候出错,要注意被解码的Json字符的编码。
如果传入的字符串的编码不是UTF-8的话,需要指定字符编码的参数 encoding
dataDict = json.loads(jsonStrGBK);
dataJsonStr是JSON字符串,假设其编码本身是非UTF-8的话而是GBK 的,那么上述代码会导致出错,改为对应的:
dataDict = json.loads(jsonStrGBK, encoding="GBK");
如果 dataJsonStr通过encoding指定了合适的编码,但是其中又包含了其他编码的字符,则需要先去将dataJsonStr转换为Unicode,然后再指定编码格式调用json.loads()
``` python
dataJsonStrUni = dataJsonStr.decode("GB2312"); dataDict = json.loads(dataJsonStrUni, encoding="GB2312");
##字符串编码转换
这是中国程序员最苦逼的地方,什么乱码之类的几乎都是由汉字引起的。
其实编码问题很好搞定,只要记住一点:
####任何平台的任何编码 都能和 Unicode 互相转换
UTF-8 与 GBK 互相转换,那就先把UTF-8转换成Unicode,再从Unicode转换成GBK,反之同理。
# 这是一个 UTF- 编码的字符串
utf8Str = "你好地球" # . 将 UTF- 编码的字符串 转换成 Unicode 编码
unicodeStr = utf8Str.decode("UTF-8") # . 再将 Unicode 编码格式字符串 转换成 GBK 编码
gbkData = unicodeStr.encode("GBK") # . 再将 GBK 编码格式字符串 转化成 Unicode
unicodeStr = gbkData.decode("gbk") # . 再将 Unicode 编码格式字符串转换成 UTF-
utf8Str = unicodeStr.encode("UTF-8")
decode的作用是将其他编码的字符串转换成 Unicode 编码
encode的作用是将 Unicode 编码转换成其他编码的字符串
一句话:UTF-8是对Unicode字符集进行编码的一种编码方式
爬取知乎网站
from bs4 import BeautifulSoup
import requests
import time def captcha(captcha_data):
with open("captcha.jpg", "wb") as f:
f.write(captcha_data)
text = input("请输入验证码:")
# 返回用户输入的验证码
return text def zhihuLogin():
# 构建一个Session对象,可以保存页面Cookie
sess = requests.Session() # 请求报头
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 首先获取登录页面,找到需要POST的数据(_xsrf),同时会记录当前网页的Cookie值
html = sess.get("https://www.zhihu.com/#signin", headers = headers).text
# 调用lxml解析库
bs = BeautifulSoup(html, "lxml") # _xsrf 作用是防止CSRF攻击(跨站请求伪造),通常叫跨域攻击,是一种利用网站对用户的一种信任机制来做坏事
# 跨域攻击通常通过伪装成网站信任的用户的请求(利用Cookie),盗取用户信息、欺骗web服务器
# 所以网站会通过设置一个隐藏字段来存放这个MD5字符串,这个字符串用来校验用户Cookie和服务器Session的一种方式 # 找到name属性值为 _xsrf 的input标签,再取出value 的值
_xsrf = bs.find("input", attrs={"name":"_xsrf"}).get("value") # 根据UNIX时间戳,匹配出验证码的URL地址
captcha_url = "https://www.zhihu.com/captcha.gif?r=%d&type=login" % (time.time() * 1000)
# 发送图片的请求,获取图片数据流,
captcha_data = sess.get(captcha_url, headers = headers).content
# 获取验证码里的文字,需要手动输入
text = captcha(captcha_data) data = {
"_xsrf" : _xsrf,
"email" : "123636274@qq.com",
"password" : "ALARMCHIME",
"captcha" : text
} # 发送登录需要的POST数据,获取登录后的Cookie(保存在sess里)
response = sess.post("https://www.zhihu.com/login/email", data = data, headers = headers)
#print response.text # 用已有登录状态的Cookie发送请求,获取目标页面源码
response = sess.get("https://www.zhihu.com/people/maozhaojun/activities", headers = headers)
with open("my.html", "w") as f:
f.write(response.text.encode("utf-8")) if __name__ == "__main__":
zhihuLogin()
9.json和jsonpath的更多相关文章
- Json与JsonPath
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,因为它良好的可读性与易于机器进行解析和生成等特性,在当前的数据整理和收集中得到了广泛的应用. JSON和XM ...
- 爬虫数据提取之JSON与JsonPATH
数据提取之JSON与JsonPATH JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适 ...
- 数据提取之JSON与JsonPATH
数据提取之JSON与JsonPATH JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适 ...
- 【python接口自动化】- 使用json及jsonpath转换和提取数据
前言 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式.它可以让人们很容易的进行阅读和编写,同时也方便了机器进行解析和生成,适用于进行数据交互的场景,比如 ...
- python 数据提取之JSON与JsonPATH
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与 ...
- Json与jsonpath再认识与初识
一.json格式的数据 1.认识 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于 ...
- Python爬虫开发【第1篇】【Json与JsonPath】
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与 ...
- 七、数据提取之JSON与JsonPATH
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与 ...
- python--爬虫之JSON于JsonPath
JSON json的引入 在python中json作为一个内建库不需要额外安装,只需要使用import json执行引入 json模块的功能 在python中json模块提供了四个功能:dumps.d ...
随机推荐
- python面向对象的三大特征
1.封装: 封装就是对类和对象的成员访问进行限制,设定可以访问的方式和不可以访问的方式. 分类: 私有化的封装:当前类/对象种可以使用,类/对象外和子类/对象都不可以用 受保护的封装:当前类/对象和子 ...
- 如何让网站在百度有LOGO展示
什么叫没有了网站logo?准确来说应该是网站索引logo,这个logo确实网站很好的一个展示窗口,我以长沙seo关键词为例,我给大家举例! 我输入长沙SEO,出来的百度索引图,原本所有我标红的框子里都 ...
- 03. pt-config-diff
pt-config-diff h=192.168.100.101,P=3306,u=admin,p=admin h=192.168.100.102,P=3306,u=admin,p=admin pt- ...
- Java 使用 jacob 将 word 文档转换为 pdf 文件
网上查询了许许多多的博客,说利用 poi.iText.Jsoup.jdoctopdf.使用 jodconverter 来调用 openOffice 的服务来转换等等,我尝试了很多种,但要么显示不完全, ...
- Eclipse的下载及安装
Eclipse的下载地址: https://www.eclipse.org/downloads/ 下载完成后,双击安装包即可安装 选择 Eclipse IDE for Java EE Decelope ...
- Spring 系列教程之默认标签的解析
Spring 系列教程之默认标签的解析 之前提到过 Spring 中的标签包括默认标签和自定义标签两种,而两种标签的用法以及解析方式存在着很大的不同,本章节重点带领读者详细分析默认标签的解析过程. 默 ...
- SQL注入漏洞总结
目录: 一.SQL注入漏洞介绍 二.修复建议 三.通用姿势 四.具体实例 五.各种绕过 一.SQL注入漏洞介绍: SQL注入攻击包括通过输入数据从客户端插入或“注入”SQL查询到应用程序.一个成功的S ...
- css字符串转换为类map对象及反转
存储对象为啥是类map(即:{key:val,...}格式),因为Map对象的val为字符时,无法存储 '('.')' 左右括号,我也很无奈╮(╯▽╰)╭ 解析脚本: <!DOCTYPE htm ...
- js--延时消失的菜单--(笔记)
html:有4个li,li下分别有一个span <script> window.onload=function(){ var aLi=document.getElementsBy ...
- GO介绍,环境的配置和安装 简单使用
1. 介绍与安装 Golang 是什么 Go 亦称为 Golang(按照 Rob Pike 说法,语言叫做 Go,Golang 只是官方网站的网址),是由谷歌开发的一个开源的编译型的静态语言. Gol ...