9.算法之顺序、二分、hash查找
一.查找/搜索
- 我们现在把注意力转向计算中经常出现的一些问题,即搜索或查找的问题。搜索是在元素集合中查找特定元素的算法过程。搜索通常对于元素是否存在返回 True 或 False。有时它可能返回元素被找到的地方。我们在这里将仅关注成员是否存在这个问题。
- 在 Python 中,有一个非常简单的方法来询问一个元素是否在一个元素列表中。我们使用 in 运算符。
- >>> 15 in [3,5,2,4,1]
- False
- >>> 3 in [3,5,2,4,1]
- True
- >>>
- 这很容易写,一个底层的操作替我们完成这个工作。事实证明,有很多不同的方法来搜索。我们在这里感兴趣的是这些算法如何工作以及它们如何相互比较。
二.顺序查找
- 当数据存储在诸如列表的集合中时,我们说这些数据具有线性或顺序关系。 每个数据元素都存储在相对于其他数据元素的位置。 在 Python 列表中,这些相对位置是单个元素的索引值。由于这些索引值是有序的,我们可以按顺序访问它们。 这个过程产实现的搜索即为顺序查找。
- 顺序查找原理剖析:从列表中的第一个元素开始,我们按照基本的顺序排序,简单地从一个元素移动到另一个元素,直到找到我们正在寻找的元素或遍历完整个列表。如果我们遍历完整个列表,则说明正在搜索的元素不存在。

- 代码实现:该函数需要一个列表和我们正在寻找的元素作为参数,并返回一个是否存在的布尔值。found 布尔变量初始化为 False,如果我们发现列表中的元素,则赋值为 True。
- def sequentialSearch(alist, item):
- pos = 0
- found = False
- while pos < len(alist) and not found:
- if alist[pos] == item:
- found = True
- else:
- pos = pos+1
- return found
- testlist = [1, 2, 32, 8, 17, 19, 42, 13, 0]
- print(sequentialSearch(testlist, 3))
- print(sequentialSearch(testlist, 13))
- 顺序查找分析:为了分析搜索算法,我们可以分析一下上述案例中搜索算法的时间复杂度,即统计为了找到搜索目标耗费的运算步骤。实际上有三种不同的情况可能发生。在最好的情况下,我们在列表的开头找到所需的项,只需要一个比较。在最坏的情况下,我们直到最后的比较才找到项,第 n 个比较。平均情况怎么样?平均来说,我们会在列表的一半找到该项; 也就是说,我们将比较 n/2 项。然而,回想一下,当 n 变大时,系数,无论它们是什么,在我们的近似中变得不重要,因此顺序查找的复杂度是 O(n)
- 有序列表:之前我们列表中的元素是随机放置的,因此在元素之间没有相对顺序。如果元素以某种方式排序,顺序查找会发生什么?我们能够在搜索技术中取得更好的效率吗?
- 设计:假设元素的列表按升序排列。如果我们正在寻找的元素存在此列表中,则目标元素在列表的 n 个位置中存在的概率是相同。我们仍然会有相同数量的比较来找到该元素。然而,如果该元素不存在,则有一些优点。下图展示了这个过程,在列表中寻找元素 50。注意,元素仍然按顺序进行比较直到 54,因为列表是有序的。在这种情况下,算法不必继续查看所有项。它可以立即停止。

- def orderedSequentialSearch(alist, item):
- pos = 0
- found = False
- stop = False
- while pos < len(alist) and not found and not stop:
- if alist[pos] == item:
- found = True
- else:
- if alist[pos] > item:
- stop = True
- else:
- pos = pos+1
- return found
- testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
- print(orderedSequentialSearch(testlist, 3))
- print(orderedSequentialSearch(testlist, 13))
该排序模式在最好的情况下,我们通过只查看一项会发现该项不在列表中。 平均来说,我们将只了解 n/2 项就知道。然而,这种复杂度仍然是 O(n)。 但是在我们没有找到目标元素的情况下,才通过对列表排序来改进顺序查找。
三. 二分查找:
- 有序列表对于我们的实现搜索是很有用的。在顺序查找中,当我们与第一个元素进行比较时,如果第一个元素不是我们要查找的,则最多还有 n-1 个元素需要进行比较。 二分查找则是从中间元素开始,而不是按顺序查找列表。 如果该元素是我们正在寻找的元素,我们就完成了查找。 如果它不是,我们可以使用列表的有序性质来消除剩余元素的一半。如果我们正在查找的元素大于中间元素,就可以消除中间元素以及比中间元素小的一半元素。如果该元素在列表中,肯定在大的那半部分。然后我们可以用大的半部分重复该过程,继续从中间元素开始,将其与我们正在寻找的内容进行比较。下图展示了该算法如何快速找到值 54 。

- def binarySearch(alist, item):
- first = 0
- last = len(alist)-1
- found = False
- while first<=last and not found:
- midpoint = (first + last)//2
- if alist[midpoint] == item:
- found = True
- else:
- if item < alist[midpoint]:
- last = midpoint-1
- else:
- first = midpoint+1
- return found
- testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
- print(binarySearch(testlist, 3))
- print(binarySearch(testlist, 13))
- 二分查找分析:为了分析二分查找算法,我们需要记住,每个比较消除了大约一半的剩余元素。该算法检查整个列表的最大比较数是多少?如果我们从 n 项开始,大约 n/2 项将在第一次比较后留下。第二次比较后,会有约 n/4。 然后 n/8,n/16,等等。 我们可以拆分列表多少次?
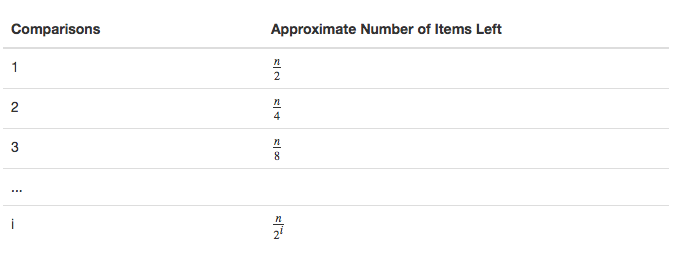
当我们切分列表足够多次时,我们最终得到只有一个元素的列表。 要么是我们正在寻找的元素,要么不是。达到这一点所需的比较数是 i,当 n / i^2=1时。 求解 i 得出 i = logn。 最大比较数相对于列表中的项是对数的。 因此,二分查找是 O(log n)。
Hash 查找。None 。下图展示了大小 m = 11 的哈希表。换句话说,在表中有 m 个槽,命名为 0 到 10。
54,26,93,17,77 和 31 的集合,hash 函数将接收集合中的任何元素,并在槽名范围内(0和 m-1之间)返回一个整数。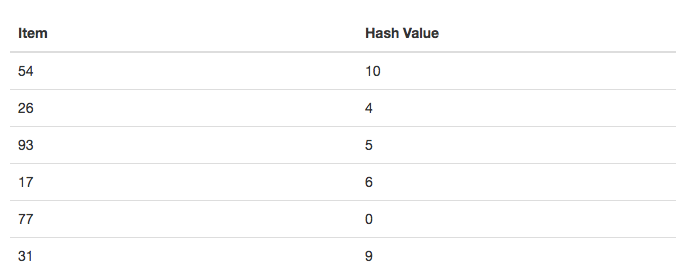
λ=项数/表大小, 在这个例子中,λ = 6/11 。
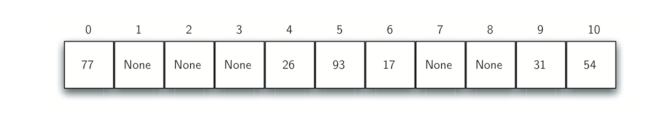
- 结论:当我们要搜索一个元素时,我们只需使用哈希函数来计算该元素的槽名称,然后检查哈希表以查看它是否存在。该搜索操作是 O(1)。
- 注意:只有每个元素映射到哈希表中的位置是唯一的,这种技术才会起作用。 例如,元素77是我们集合中的某一个元素,则它的哈希值为0(77%11 == 0)。 那么如果集合中还有一个元素是44,则44的hash值也是 0,我们会有一个问题。根据hash函数,两个或更多元素将需要在同一槽中。这种现象被称为碰撞(它也可以被称为“冲突”)。显然,冲突使散列技术产生了问题。我们将在后面详细讨论。
- 其他计算hash值的方法:
- 分组求和法:如果我们的元素是电话号码 436-555-4601,我们将取出数字,并将它们分成2位数(43,65,55,46,01)。43 + 65 + 55 + 46 + 01,我们得到 210。我们假设哈希表有 11 个槽,那么我们需要除以 11 。在这种情况下,210%11 为 1,因此电话号码 436-555-4601 放置到槽 1 。
- 平方取中法:我们首先对该元素进行平方,然后提取一部分数字结果。例如,如果元素是 44,我们将首先计算 44^2 = 1,936 。通过提取中间两个数字 93 ,我们得到 93%11=5,因此元素44放置到槽5.
- 注意:还可以思考一些其他方法来计算集合中元素的哈希值。重要的是要记住,哈希函数必须是高效的,以便它不会成为存储和搜索过程的主要部分。如果哈希函数太复杂,则计算槽名称的程序要比之前所述的简单地进行基本的顺序或二分搜索更耗时。 这将打破哈希的目的。
- 冲突解决:如果有两个元素通过调用hash函数返回两个同样的槽名,我们就必须有一种方法可以使得这两个元素可以散落在hash表的不同槽中!
- 解决方案:解决冲突的一种方法是查找哈希表,尝试查找到另一个空槽以保存导致冲突的元素。一个简单的方法是从原始哈希值位置开始,然后以顺序方式移动槽,直到遇到第一个空槽。这种冲突解决过程被称为开放寻址,因为它试图在哈希表中找到下一个空槽或地址。通过系统的依次访问每个槽。当我们尝试将 44 放入槽 0 时,发生冲突。在线性探测下,我们逐个顺序观察,直到找到位置。在这种情况下,我们找到槽 1。再次,55 应该在槽 0 中,但是必须放置在槽 2 中,因为它是下一个开放位置。值 20 散列到槽 9 。由于槽 9 已满,我们进行线性探测。我们访问槽10,0,1和 2,最后在位置 3 找到一个空槽。
原图
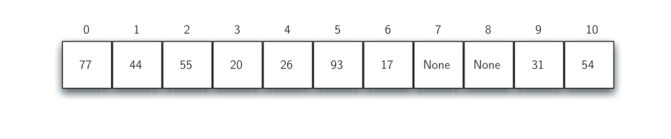 现图
现图
一旦我们使用开放寻址建立了哈希表,我们就必须使用相同的方法来搜索项。假设我们想查找项 93 。当我们计算哈希值时,我们得到 5 。查看槽 5 得到 93,返回 True。如果我们正在寻找 20, 现在哈希值为 9,而槽 9 当前项为 31 。我们不能简单地返回 False,因为我们知道可能存在冲突。我们现在被迫做一个顺序搜索,从位置 10 开始寻找,直到我们找到项 20 或我们找到一个空槽。
- 代码实现
- 实现 map 抽象数据类型:最有用的 Python 集合之一是字典。回想一下,字典是一种关联数据类型,你可以在其中存储键-值对。该键用于查找关联的值。我们经常将这个想法称为 map。map 抽象数据类型定义如下:
- Map() 创建一个新的 map 。它返回一个空的 map 集合。
- put(key,val) 向 map 中添加一个新的键值对。如果键已经在 map 中,那么用新值替换旧值。
- get(key) 给定一个键,返回存储在 map 中的值或 None。
- del 使用
del map[key]形式的语句从 map 中删除键值对。 - len() 返回存储在 map 中的键值对的数量。
- in 返回 True 对于
key in map语句,如果给定的键在 map 中,否则为False。
- 我们使用两个列表来创建一个实现 Map 抽象数据类型的HashTable 类。一个名为 slots的列表将保存键项,一个称 data 的并行列表将保存数据值。当我们查找一个键时,data 列表中的相应位置将保存相关的数据值。我们将使用前面提出的想法将键列表视为哈希表。注意,哈希表的初始大小已经被选择为 11。尽管这是任意的,但是重要的是,大小是质数,使得冲突解决算法可以尽可能高效。
- class HashTable:
- def __init__(self):
- self.size = 11
- self.slots = [None] * self.size
- self.data = [None] * self.size
- hash 函数实现简单的余数方法。冲突解决技术是 加1 rehash 函数的线性探测。 put 函数假定最终将有一个空槽,除非 key 已经存在于 self.slots 中。 它计算原始哈希值,如果该槽不为空,则迭代 rehash 函数,直到出现空槽。如果非空槽已经包含 key,则旧数据值将替换为新数据值。
- def put(self,key,data):
- hashvalue = self.hashfunction(key,len(self.slots))
- if self.slots[hashvalue] == None:
- self.slots[hashvalue] = key
- self.data[hashvalue] = data
- else:
- if self.slots[hashvalue] == key:
- self.data[hashvalue] = data #replace
- else:
- nextslot = self.rehash(hashvalue,len(self.slots))
- while self.slots[nextslot] != None and \
- self.slots[nextslot] != key:
- nextslot = self.rehash(nextslot,len(self.slots))
- if self.slots[nextslot] == None:
- self.slots[nextslot]=key
- self.data[nextslot]=data
- else:
- self.data[nextslot] = data #replace
- def hashfunction(self,key,size):
- return key%size
- def rehash(self,oldhash,size):
- return (oldhash+1)%size
- 同样,get 函数从计算初始哈希值开始。如果值不在初始槽中,则 rehash 用于定位下一个可能的位置。注意,第 15 行保证搜索将通过检查以确保我们没有返回到初始槽来终止。如果发生这种情况,我们已用尽所有可能的槽,并且项不存在。HashTable 类提供了附加的字典功能。我们重载 __getitem__ 和__setitem__ 方法以允许使用 [] 访问。 这意味着一旦创建了HashTable,索引操作符将可用。
- def get(self,key):
- startslot = self.hashfunction(key,len(self.slots))
- data = None
- stop = False
- found = False
- position = startslot
- while self.slots[position] != None and \
- not found and not stop:
- if self.slots[position] == key:
- found = True
- data = self.data[position]
- else:
- position=self.rehash(position,len(self.slots))
- if position == startslot:
- stop = True
- return data
- def __getitem__(self,key):
- return self.get(key)
- def __setitem__(self,key,data):
- self.put(key,data)
- 下面展示了 HashTable 类的操作。首先,我们将创建一个哈希表并存储一些带有整数键和字符串数据值的项。
- >>> H=HashTable()
- >>> H[54]="cat"
- >>> H[26]="dog"
- >>> H[93]="lion"
- >>> H[17]="tiger"
- >>> H[77]="bird"
- >>> H[31]="cow"
- >>> H[44]="goat"
- >>> H[55]="pig"
- >>> H[20]="chicken"
- >>> H.slots
- [77, 44, 55, 20, 26, 93, 17, None, None, 31, 54]
- >>> H.data
- ['bird', 'goat', 'pig', 'chicken', 'dog', 'lion',
- 'tiger', None, None, 'cow', 'cat']
- 接下来,我们将访问和修改哈希表中的一些项。注意,正替换键 20 的值。
- >>> H[20]
- 'chicken'
- >>> H[17]
- 'tiger'
- >>> H[20]='duck'
- >>> H[20]
- 'duck'
- >>> H.data
- ['bird', 'goat', 'pig', 'duck', 'dog', 'lion',
- 'tiger', None, None, 'cow', 'cat']
- >> print(H[99])
- None
9.算法之顺序、二分、hash查找的更多相关文章
- 算法之顺序、二分、hash查找
算法之顺序.二分.hash查找 一.查找/搜索 - 我们现在把注意力转向计算中经常出现的一些问题,即搜索或查找的问题.搜索是在元素集合中查找特定元素的算法过程.搜索通常对于元素是否存在返回 Tru ...
- 查找算法(顺序查找、二分法查找、二叉树查找、hash查找)
查找功能是数据处理的一个基本功能.数据查找并不复杂,但是如何实现数据又快又好地查找呢?前人在实践中积累的一些方法,值得我们好好学些一下.我们假定查找的数据唯一存在,数组中没有重复的数据存在. (1)顺 ...
- C语言查找算法之顺序查找、二分查找(折半查找)
C语言查找算法之顺序查找.二分查找(折半查找),最近考试要用到,网上也有很多例子,我觉得还是自己写的看得懂一些. 顺序查找 /*顺序查找 顺序查找是在一个已知无(或有序)序队列中找出与给定关键字相同的 ...
- 查找算法----二分查找与hash查找
二分查找 有序列表对于我们的实现搜索是很有用的.在顺序查找中,当我们与第一个元素进行比较时,如果第一个元素不是我们要查找的,则最多还有 n-1 个元素需要进行比较. 二分查找则是从中间元素开始,而不是 ...
- Java中的查找算法之顺序查找(Sequential Search)
Java中的查找算法之顺序查找(Sequential Search) 神话丿小王子的博客主页 a) 原理:顺序查找就是按顺序从头到尾依次往下查找,找到数据,则提前结束查找,找不到便一直查找下去,直到数 ...
- 二分查找和hash查找
转载:http://blog.csdn.net/feixiaoxing/article/details/6844723 无论是数据库,还是普通的ERP系统,查找功能数据处理的一个基本功能.数据查找并不 ...
- javascript数据结构与算法---检索算法(顺序查找、最大最小值、自组织查询)
javascript数据结构与算法---检索算法(顺序查找.最大最小值.自组织查询) 一.顺序查找法 /* * 顺序查找法 * * 顺序查找法只要从列表的第一个元素开始循环,然后逐个与要查找的数据进行 ...
- Python 迭代器&生成器,装饰器,递归,算法基础:二分查找、二维数组转换,正则表达式,作业:计算器开发
本节大纲 迭代器&生成器 装饰器 基本装饰器 多参数装饰器 递归 算法基础:二分查找.二维数组转换 正则表达式 常用模块学习 作业:计算器开发 实现加减乘除及拓号优先级解析 用户输入 1 - ...
- 查找算法(6)--Block search--分块查找
1. 分块查找 (1)说明分块查找又称索引顺序查找,它是顺序查找的一种改进方法. (2)算法思想:将n个数据元素"按块有序"划分为m块(m ≤ n).每一块中的结点不必有序,但块与 ...
随机推荐
- CAlayer一
// // ViewController.m // Layer // // Created by City--Online on 15/4/9. // Copyright (c) 2015年 City ...
- ASP.NET MVC加载用户控件后并获取其内控件值或赋值
有网友看了这篇<ASP.NET MVC加载ASCX之后,并为之赋值>http://www.cnblogs.com/insus/p/3643254.html 之后,问及Insus.NET,不 ...
- windows下nodejs监听80端口
windows下nodejs监听80端口时提示端口被占用报错,解决方案如下: 1.cmd---netstat -ano查看是什么程序占用了80端口: 2.控制面板--管理工具--服务--停止 SQL ...
- ExtJs 中Viewport的介绍与使用
ExtJs 中Viewport的介绍与使用 VeiwPort 代表整个浏览器显示区域,该对象渲染到页面的body 区域,并会随着浏览器显示区域的大小自动改变,一个页面中只能有一个ViewPort 实例 ...
- [日常] Go语言圣经--复数,布尔值,字符串习题
go语言圣经-复数 1.我们把形如a+bi(a,b均为实数)的数称为复数,其中a称为实部,b称为虚部,i称为虚数单位.两种精度的复数类型:complex64和complex128,分别对应float3 ...
- CentOs 7.3下ELK日志分析系统搭建
系统环境 为了安装时不出错,建议选择这两者选择一样的版本,本文全部选择5.3版本. System: Centos release 7.3 Java: openjdk version "1.8 ...
- Spring Boot使用layui的字体图标时无法正常显示 解决办法
在html文件使用字体图标并且预览时正常,但是启动工程后显示不正常,浏览器调试界面显示字体文件无法decode: Failed to decode downloaded font: xxxxx 如图所 ...
- Java JDBC MySQL
一.驱动 下载地址:https://dev.mysql.com/downloads/connector/j/ 二.数据库连接配置 jdbc:mysql://address:port/database? ...
- JAVA—集合框架
ref:https://blog.csdn.net/u012961566/article/details/76915755 https://blog.csdn.net/u011240877/artic ...
- 【学习笔记】--- 老男孩学Python,day4 编码,数据类型,字符串方法
今日主要内容 1. 编码 1. 最早的计算机编码是ASCII. 美国人创建的. 包含了英文字母(大写字母, 小写字母). 数字, 标点等特殊字符!@#$% 128个码位 2**7 在此基础上加了一位 ...