大数据【五】Hive(部署;表操作;分区)
一 概述
就像我们所了解的sql一样,Hive也是一种数据仓库,不同的是hive是在hadoop大数据生态圈中所用。这篇博客我主要介绍Hive的简单表运用。
Hive是Hadoop 大数据生态圈中的数据仓库,其提供以表格的方式来组织与管理HDFS上的数据、以类SQL的方式来操作表格里的数据。
Hive的设计目的是能够以类SQL的方式查询存放在HDFS上的大规模数据集,不必开发专门的MapReduce应用。
Hive本质上相当于一个MapReduce和HDFS的翻译终端,用户提交Hive脚本后,Hive运行时环境会将这些脚本翻译成MapReduce和HDFS操作并向集群提交这些操作。
当用户向Hive提交其编写的HiveQL后,首先,Hive运行时环境会将这些脚本翻译成MapReduce和HDFS操作,紧接着,Hive运行时环境使用Hadoop命令行接口向Hadoop集群提交这些MapReduce和HDFS操作,最后,Hadoop集群逐步执行这些MapReduce和HDFS操作,整个过程可概括如下:
(1)用户编写HiveQL并向Hive运行时环境提交该HiveQL。
(2)Hive运行时环境将该HiveQL翻译成MapReduce和HDFS操作。
(3)Hive运行时环境调用Hadoop命令行接口或程序接口,向Hadoop集群提交翻译后的HiveQL。
(4)Hadoop集群执行HiveQL翻译后的MapReduce-APP或HDFS-APP。
由上述执行过程可知,Hive的核心是其运行时环境,该环境能够将类SQL语句编译成MapReduce。
Hive构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询。例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
二 Hive部署
按metastore存储位置的不同,其部署模式分为内嵌模式、本地模式和完全远程模式三种。当使用完全模式时,可以提供很多用户同时访问并操作Hive,并且此模式还提供各类接口(BeeLine,CLI,甚至是Pig),这里我们以内嵌模式为例。
由于使用内嵌模式时,其Hive会使用内置的Derby数据库来存储数据库,此时无须考虑数据库部署连接问题。
1‘ 安装部署
在client机上操作:首先确定存在Hive(如果不存在,同前述博客的mapreduce一样的导入方法)
ls /usr/cstor/

2’ 配置HDFS
先为Hive配置Hadoop安装路径。
待解压完成后,进入Hive的配置文件夹conf目录下,接着将Hive的环境变量模板文件复制成环境变量文件。
cd /usr/cstor/hive/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
在配置文件中加入以下语句:
HADOOP_HOME=/usr/cstor/hadoop
然后在HDFS里新建Hive的存储目录。
在HDFS中新建/tmp 和 /usr/hive/warehouse 两个文件目录,并对同组用户增加写权限。
bin/hadoop fs -mkdir /tmp
bin/hadoop fs -mkdir -p /usr/hive/warehouse
bin/hadoop fs -chmod g+w /tmp
bin/hadoop fs -chmod g+w /usr/hive/warehouse
3‘ 启动Hive
在内嵌模式下,启动Hive指的是启动Hive运行时环境,用户可使用下述命令进入Hive运行时环境。
启动Hive命令行:
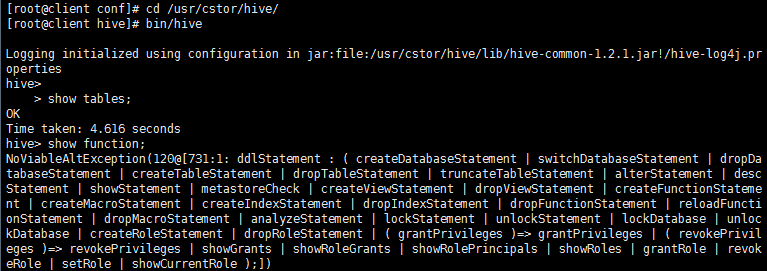
cd /usr/cstor/hive/
bin/hive
或者进入 /usr/cstor/hive/bin/ 然后用命令 ./hive 启动Hive
结果显示会进入hive环境,然后使用 “show tables”, “show function”后验证配置成功。
三 Hive表处理
Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。
Hive中所有的数据都存储在HDFS中,Hive中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
Hive中Table和数据库中 Table在概念上是类似的,每一个Table在Hive中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh是在hive-site.xml中由${hive.metastore.warehouse.dir}指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
1’ 启动Hive(上一步)
2‘ 创建表
默认情况下,新建表的存储格式均为Text类型,字段间默认分隔符为键盘上的Tab键。
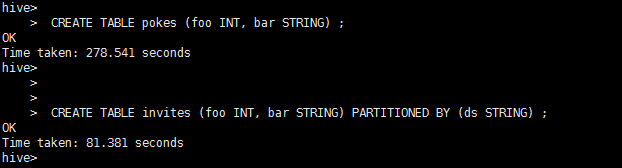
创建一个有两个字段的pokes表,其中第一列名为foo,数据类型为INT,第二列名为bar,类型为STRING。
hive> CREATE TABLE pokes (foo INT, bar STRING) ;
创建一个有两个实体列和一个(虚拟)分区字段的invites表。
hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING) ;
注意:分区字段并不属于invites,当向invites导入数据时,ds字段会用来过滤导入的数据。
3’ 显示表
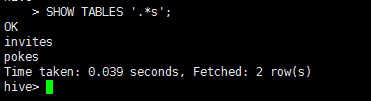
show tables;
或者正则查询 show tables '.*s';
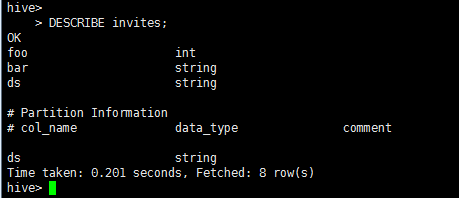
>显示表列
DESCRIBE invites;
4‘ 更改表
修改表events名为3koobecaf (自行创建任意类型events表):
ALTER TABLE events RENAME TO 3koobecaf;
将pokes表新增一列(列名为new_col,类型为INT):
ALTER TABLE pokes ADD COLUMNS (new_col INT);
将invites表新增一列(列名为new_col2,类型为INT),同时增加注释“a comment”:
ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
替换invites表所有列名(数据不动):
ALTER TABLE invites REPLACE COLUMNS (foo INT, bar STRING, baz INT COMMENT 'baz replaces new_col2');
5’ 删除表
删除invites表bar 和 baz 两列:
ALTER TABLE invites REPLACE COLUMNS (foo INT COMMENT 'only keep the first column');
删除pokes表:
DROP TABLE pokes;
四 Hive分区
分区(Partition) 对应于数据库中的 分区(Partition) 列的密集索引,但是 Hive 中 分区(Partition) 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个分区(Partition)对应于表下的一个目录,所有的分区(Partition) 的数据都存储在对应的目录中。 例如:pvs 表中包含 ds 和 ctry 两个分区(Partition),则对应于 ds = 20090801, ctry = US 的HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA。
外部表(External Table) 指向已经在 HDFS 中存在的数据,可以创建分区(Partition)。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
Table 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据的访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
1‘ 启动Hadoop集群(因为Hive依赖于MapReduce)
在主节点进入Hadoop安装目录,启动Hadoop集群。
# cd /usr/cstor/hadoop/sbin
[root@master sbin]# ./start-all.sh
2’ 用命令进入Hive客户端(启动Hive)
进入Hive安装目录,用命令进入Hive客户端。
cd /usr/cstor/hive
bin/hive
3‘ 通过HQL语句进行实验
>进入客户端后,查看Hive数据库,并选择default数据库:
hive> show databases;
>在命令端创建Hive分区表:
hive> create table parthive (createdate string, value string) partitioned by (year string) row format delimited fields terminated by '\t';
>查看新建的表:
hive> show tables;
>给parthive表创建两个分区:
hive> alter table parthive add partition(year='2017');
>查看parthive的表结构:
hive> describe parthive;
>向year=2017分区导入本地数据:
hive> load data local inpath '/root/data/12/parthive.txt' into table parthive partition(year='2017');
根据条件查询year=2017的数据:
hive> select * from parthive t where t.year='2017';
根据条件统计year=2017的数据:
hive> select count(*) from parthive where year='2017';
大数据【五】Hive(部署;表操作;分区)的更多相关文章
- Hive与表操作有关的语句
Hive与表操作有关的语句 1.创建表的语句: Create [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COM ...
- 大数据平台Hive数据迁移至阿里云ODPS平台流程与问题记录
一.背景介绍 最近几天,接到公司的一个将当前大数据平台数据全部迁移到阿里云ODPS平台上的任务.而申请的这个ODPS平台是属于政务内网的,因考虑到安全问题当前的大数据平台与阿里云ODPS的网络是不通的 ...
- 云计算与大数据实验:Hbase shell操作用户表
[实验目的] 1)了解hbase服务 2)学会hbase shell命令操作用户表 [实验原理] HBase是一个分布式的.面向列的开源数据库,它利用Hadoop HDFS作为其文件存储系统,利用Ha ...
- 【大数据】Hive学习笔记
第1章 Hive基本概念 1.1 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表, ...
- 大数据利器Hive
序言:在大数据领域存在一个现象,那就是组件繁多,粗略估计一下轻松超过20种.如果你是初学者,瞬间就会蒙圈,不知道力往哪里使.那么,为什么会出现这种现象呢?在本文的开头笔者就简单的阐述一下这种现象出现的 ...
- 大数据(8) - hive的安装与使用
什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本质是: ...
- 大数据:Hive常用参数调优
1.limit限制调整 一般情况下,Limit语句还是需要执行整个查询语句,然后再返回部分结果. 有一个配置属性可以开启,避免这种情况---对数据源进行抽样 hive.limit.optimize.e ...
- Mysql备份系列(3)--innobackupex备份mysql大数据(全量+增量)操作记录
在日常的linux运维工作中,大数据量备份与还原,始终是个难点.关于mysql的备份和恢复,比较传统的是用mysqldump工具,今天这里推荐另一个备份工具innobackupex.innobacku ...
- 大数据学习——hive的sql练习
1新建一个数据库 create database db3; 2创建一个外部表 --外部表建表语句示例: create external table student_ext(Sno int,Sname ...
- sqoop导oracle数据到hive中并动态分区
静态分区: 在hive中创建表可以使用hql脚本: test.hql USE TEST; CREATE TABLE page_view(viewTime INT, userid BIGINT, pag ...
随机推荐
- 数据库相关 Mysql基本操作
数据库相关 设计三范式: 第一范式: 主要强调原子性 即表的每一列(字段)包含的内容,不能再拆分.如果,某张表的列,还可以细分,则违背了数据库设计的第一范式. 第二范式: 主要强调主键,即:数据库中的 ...
- 继承extends、super、this、方法重写overiding、final、代码块_DAY08
1:Math类的随机数(掌握) 类名调用静态方法. 包:java.lang 类:Math 方法:public static double random(): Java.lang包下的类是不用导包就可 ...
- 解决org.apache.shiro.session.UnknownSessionException: There is no session with id的问题
一.背景 最近在整合了Spring+Shiro+Redis实现tomcat集群session共享的问题之后,发布以后运行以后发现老是会出现:org.apache.shiro.session.Unkno ...
- Redis+Jedis封装工具类
package com.liying.monkey.core.util; import java.io.IOException; import java.util.ArrayList; import ...
- 【跟着开涛学Shiro】(一)Shiro简介
声明:本部分内容均转自于张老师的博客,因为本人很喜欢他的博客,所以一直在学习,转载仅是记录和分享,若也有喜欢的人的话,可以去他的博客首页看:http://jinnianshilongnian.itey ...
- PHP7最高性能优化建议
PHP7已经发布了, 作为PHP10年来最大的版本升级, 最大的性能升级, PHP7在多放的测试中都表现出很明显的性能提升, 然而, 为了让它能发挥出最大的性能, 我还是有几件事想提醒下. PHP7 ...
- Python数据分析之pandas入门
一.pandas库简介 pandas是一个专门用于数据分析的开源Python库,目前很多使用Python分析数据的专业人员都将pandas作为基础工具来使用.pandas是以Numpy作为基础来设计开 ...
- stack堆栈容器、queue队列容器和priority_queue优先队列容器(常用的方法对比与总结)
stack堆栈是一个后进先出的线性表,插入和删除元素都在表的一端进行. stack堆栈的使用方法: 采用push()方法将元素入栈: 采用pop()方法将元素出栈: 采用top()方法访问栈顶元素: ...
- net 反射30分钟速成
概述 什么是反射 Reflection,中文翻译为反射. 这是.Net中获取运行时类型信息的方式,.Net的应用程序由几个部分:‘程序集(Assembly)’.‘模块(Module)’. ...
- 自定义一个可以动态折叠的UITAbleViewCell
看到code 4APP上有一个折叠的UITAbleViewCell,不过是swift的,所以自己尝试做一个简单的可折叠的UITAbleViewCell 主要实现一个可以折叠的UITAbleViewCe ...