Cloudera HUE大数据可视化分析


下载版本
cdh版本 http://archive-primary.cloudera.com/cdh5/cdh/5/
我们下载这个
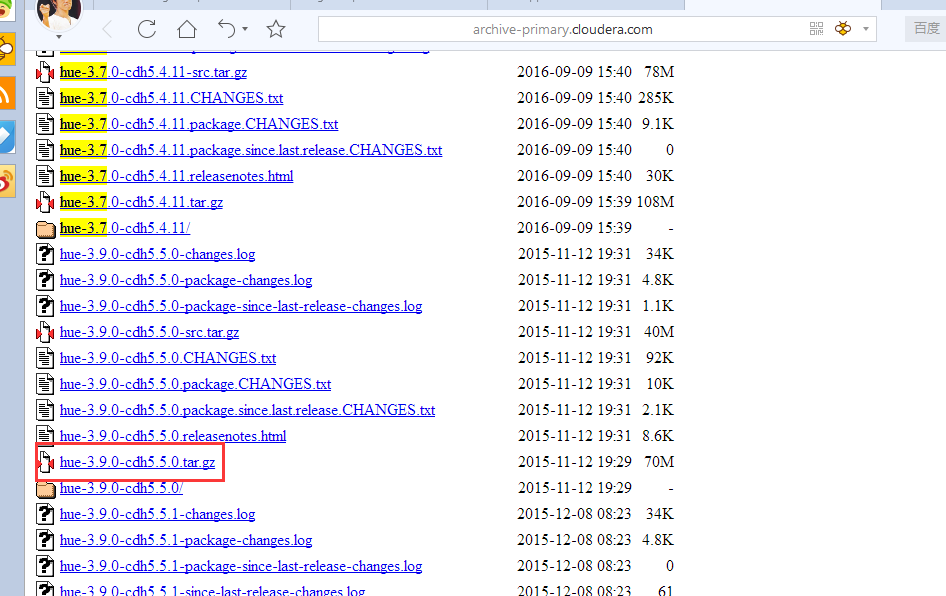
这个是我下载好的

我们解压一下


下载需要的系统包
yum install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi gcc gcc-c++ krb5-devel ibtidy libxml2-devel libxslt-devel openldap-devel python-devel
sqlite-devel openssl-devel mysql-devel gmp-devel

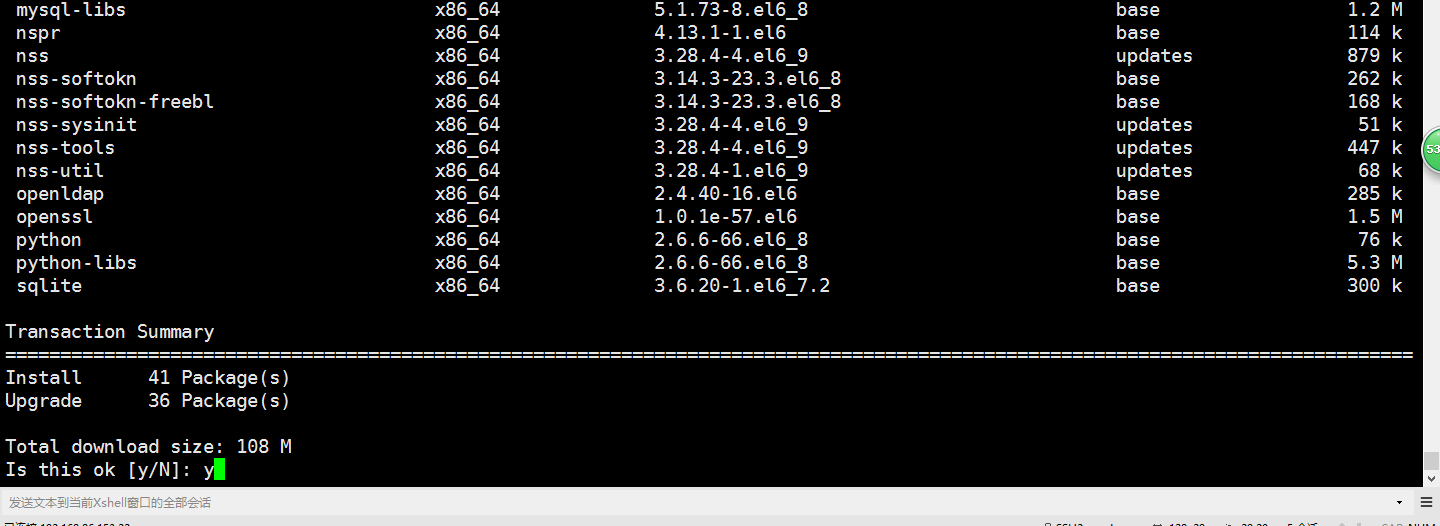

接下来这一步的话可能时间比较久一点起码要三五分钟的,大家耐心等等


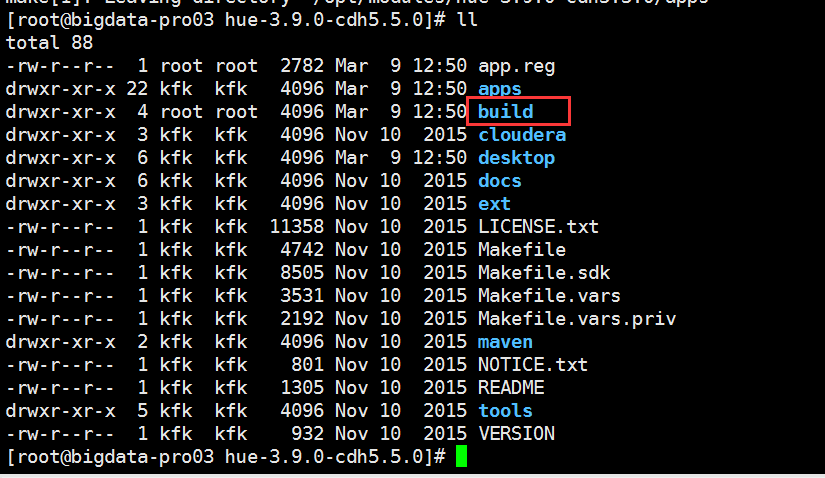
现在我们编译就成功了!!!
我们可以看到生成我们的build目录
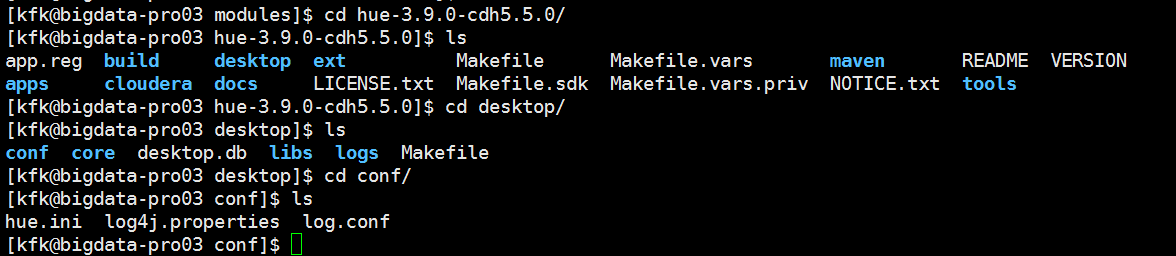
现在我们通过notepad打开这个文件
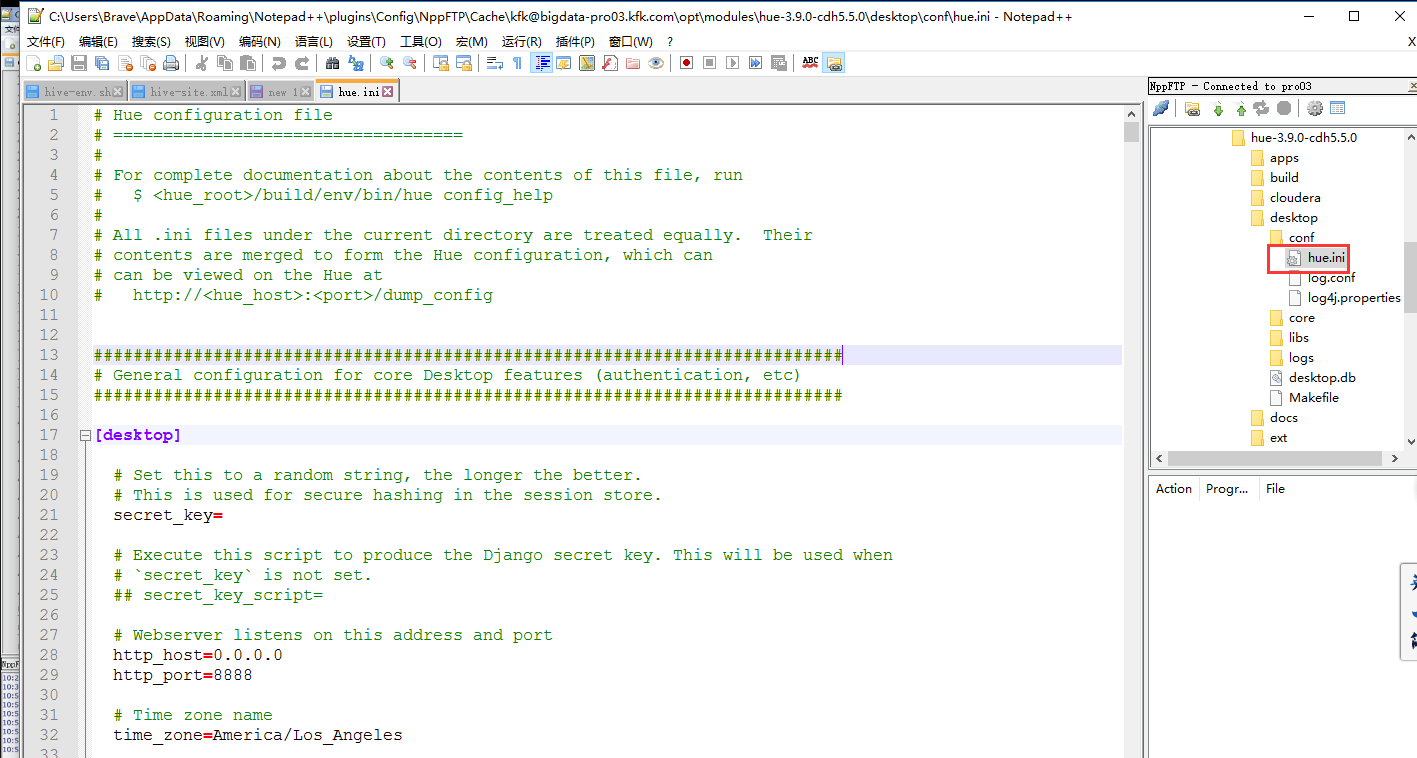
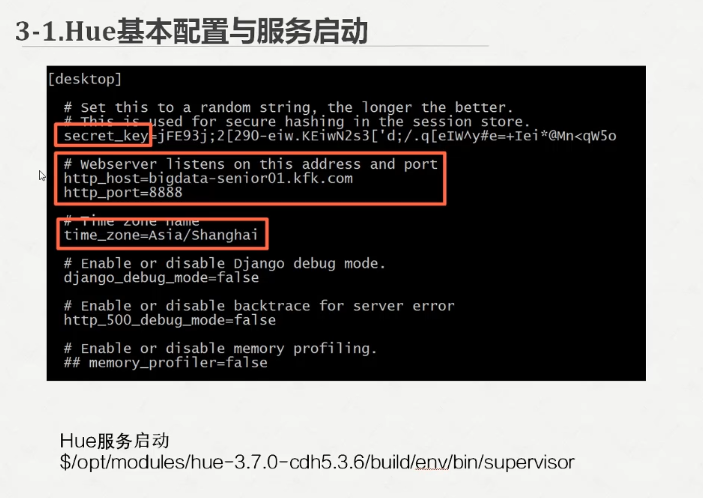
直接把官网的这一串拷贝过来
参考官方说明网址 http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.5.0/manual.html


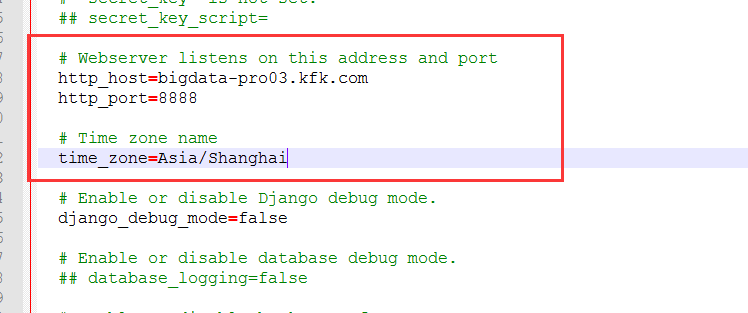
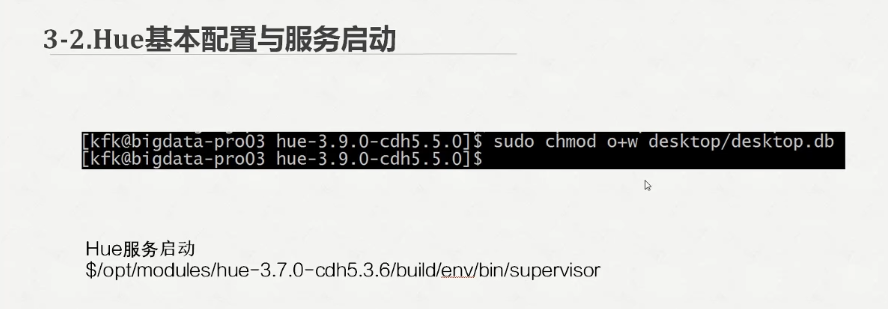

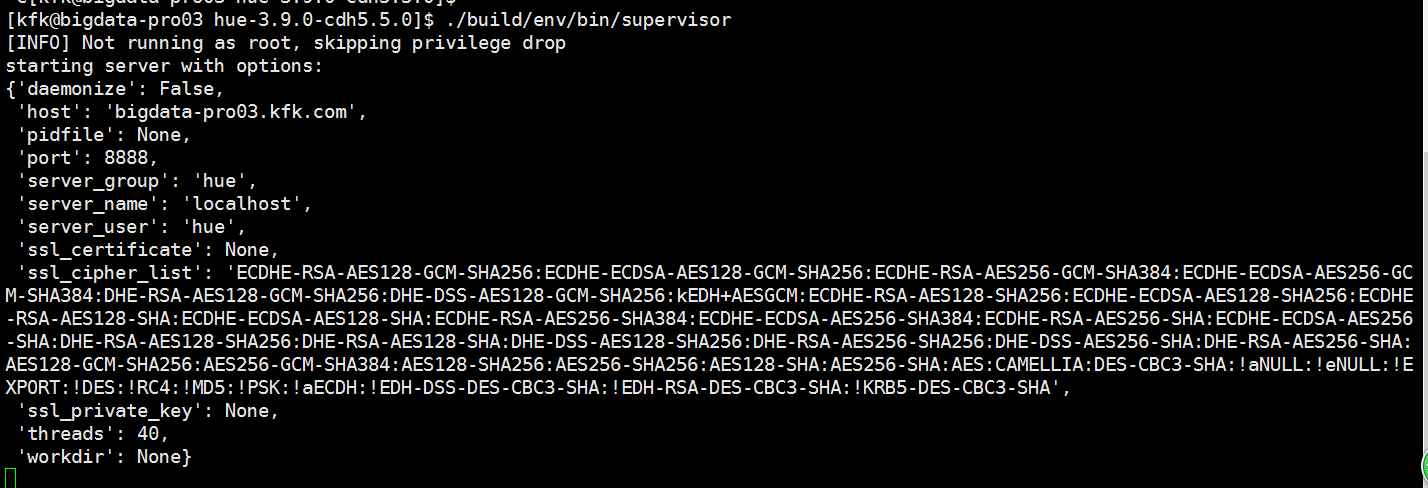
接下来启动服务
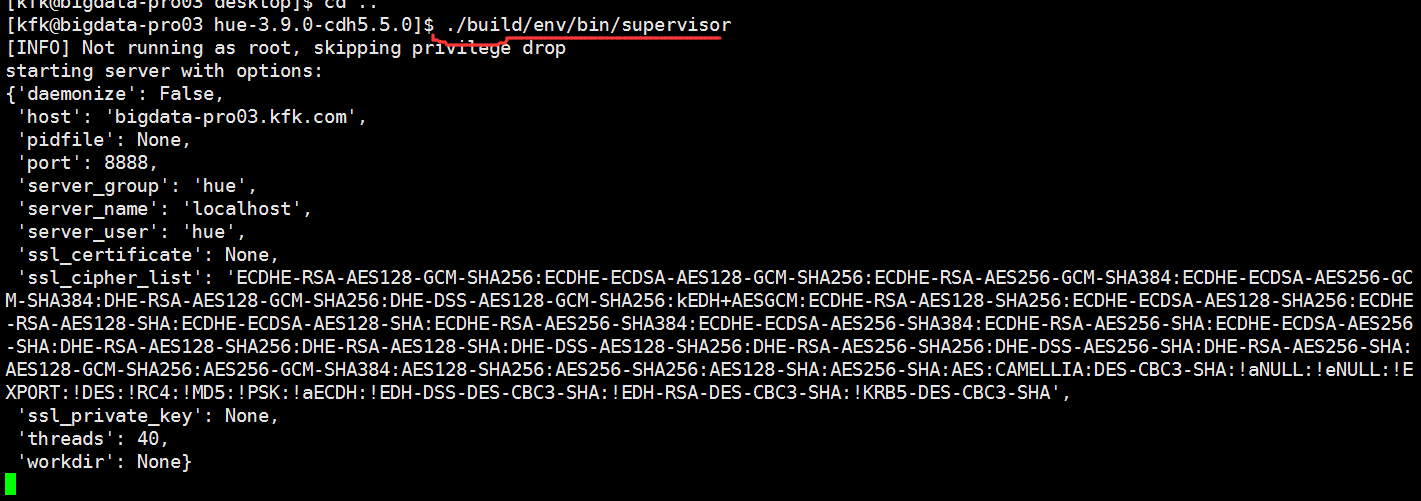
可以看到服务启动起来了,打印了一长串的服务信息,我们不管他
http://bigdata-pro03.kfk.com:8888
登录这个地址看看这个可视化界面

注意我圈出来的,大家首次登录的话一定要仔细阅读里面的内容
我这里就用 用户名:kfk 密码:kfk
点击创建用户
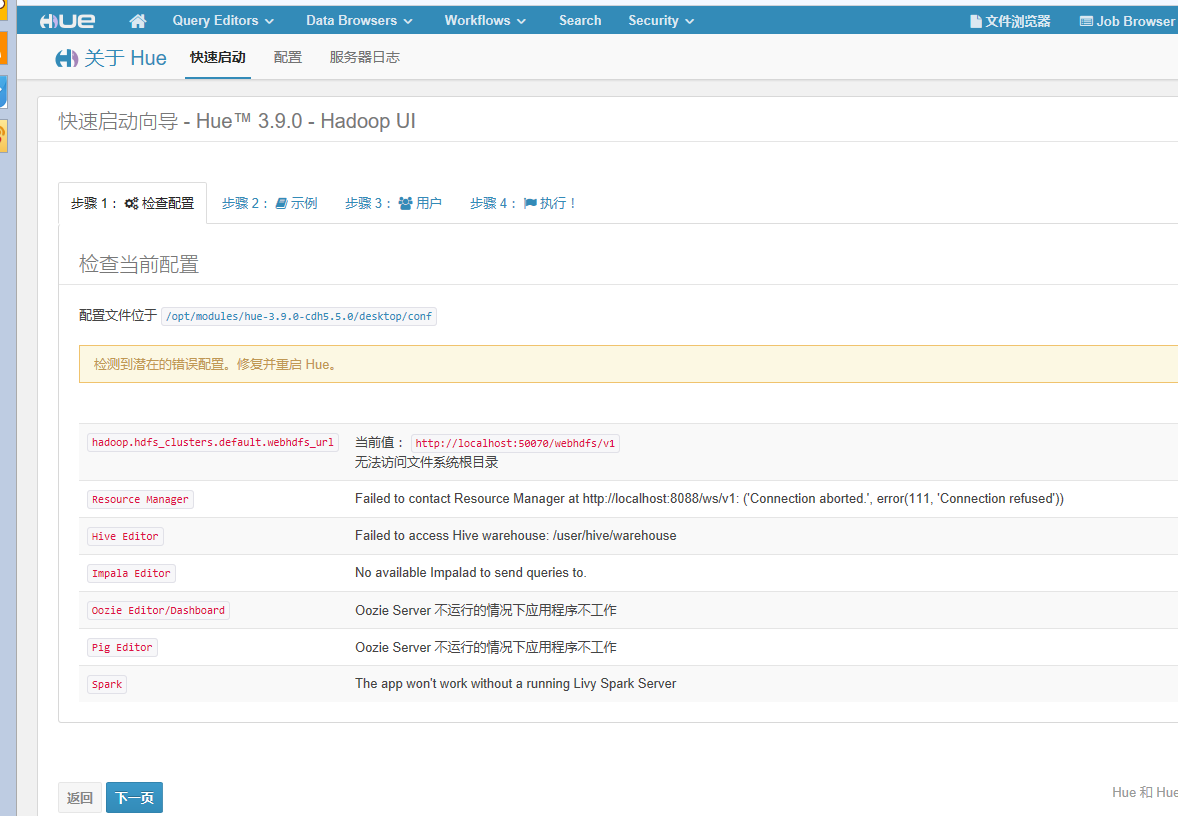
相应的界面我们就进来了

回到hue.ini文件
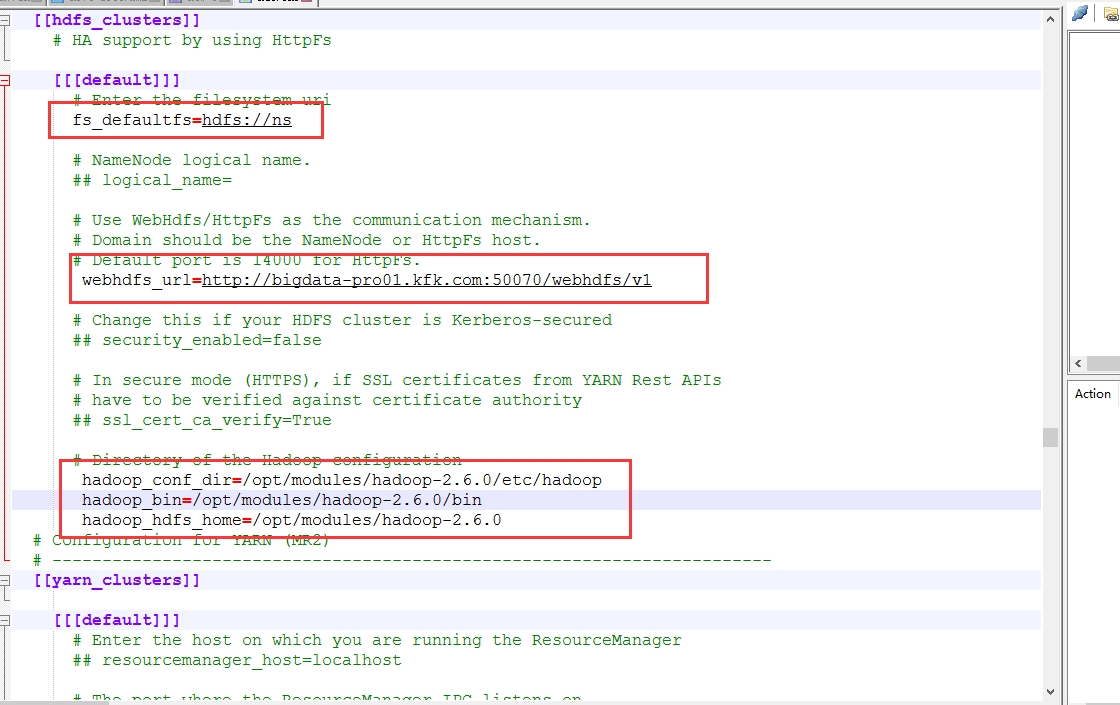
在hadoop的hdfs-site.xml上添加

<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
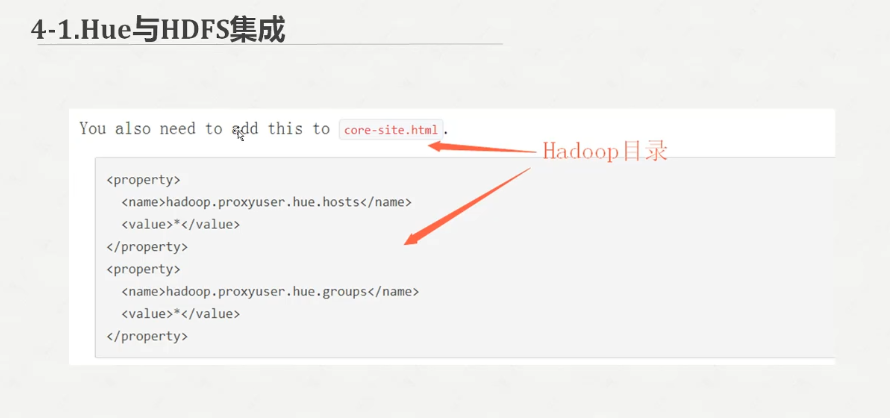
在hadoop的core-site.xml下面加上
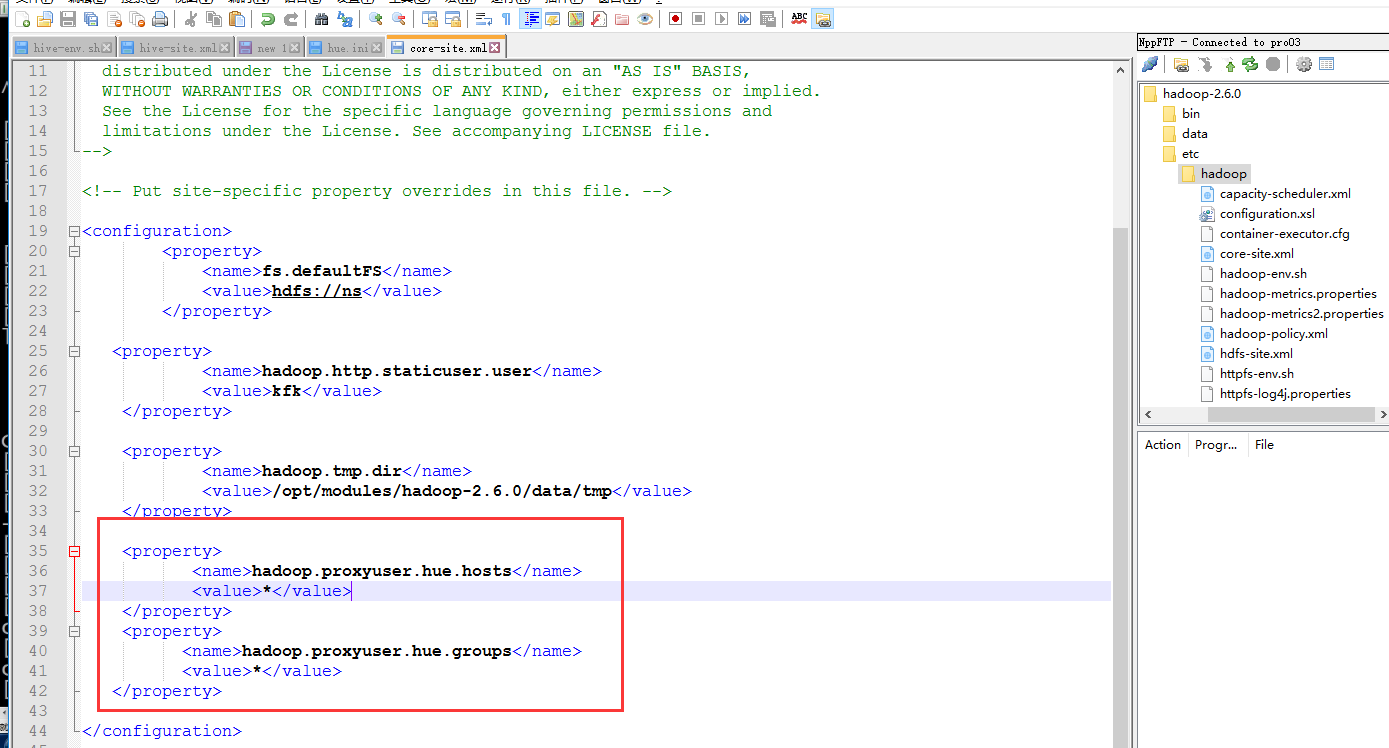
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property> <property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
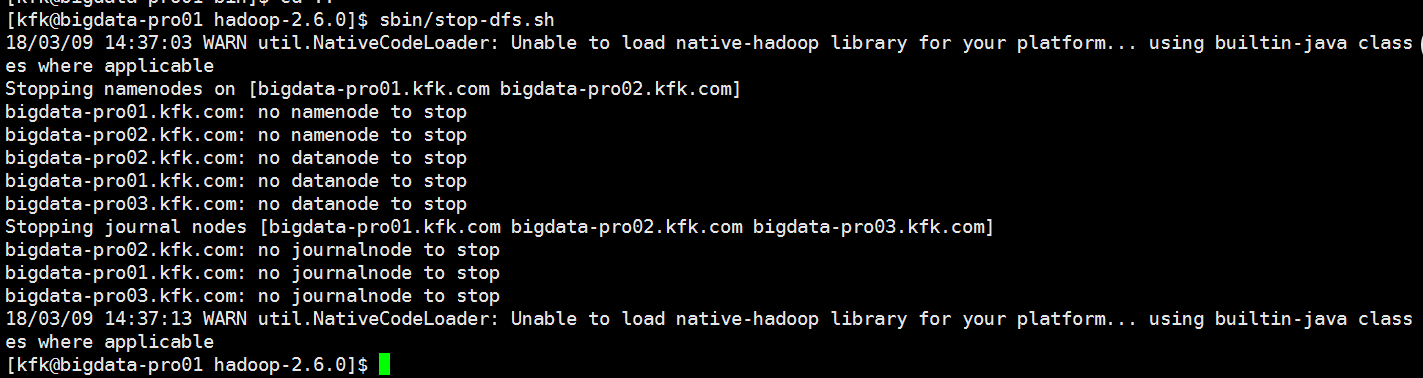
配置完了之后就把配置文件分发到节点1 和节点2上去

分发完之后我们重启一下服务
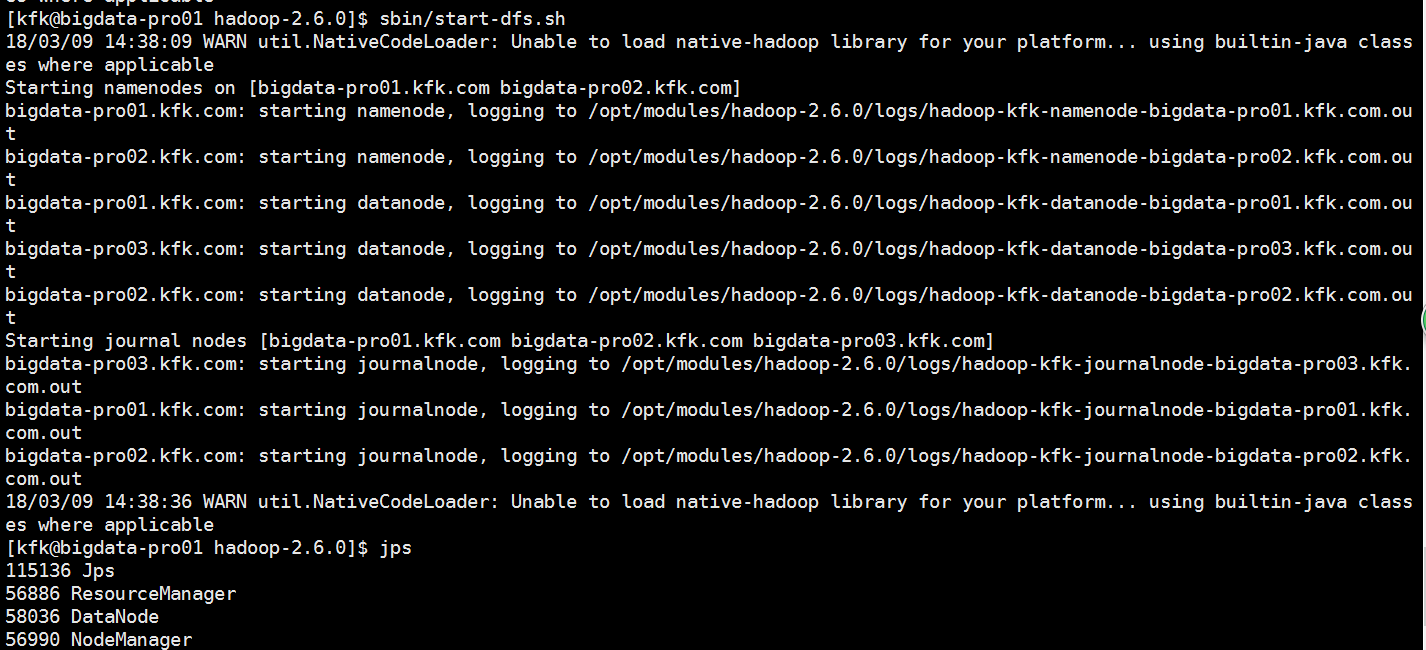
把hue也启动一下

再次进入可视化界面


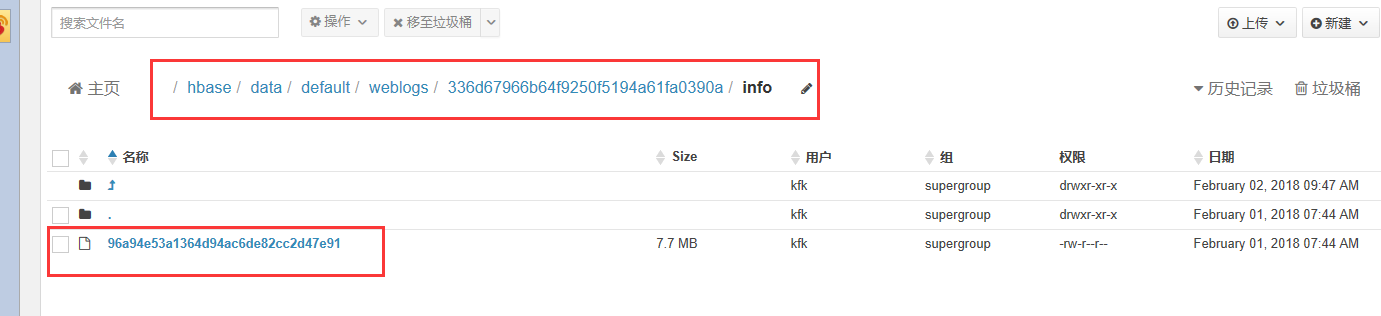
可以看到我的hdfs目录了
可以进来点开这些数据

我们首先查看yarn-site.xml

我们配置hue.ini

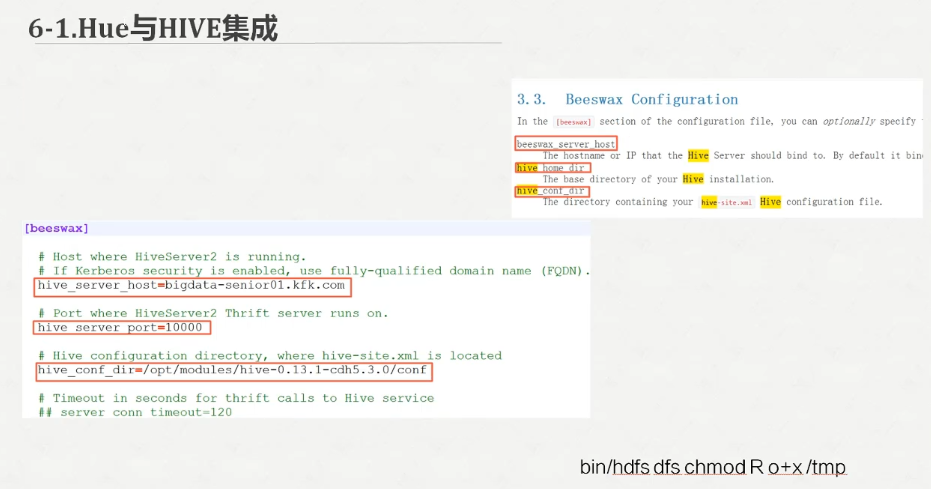
我们继续配置hue.ini

先启动hivesever2

启动一下hue
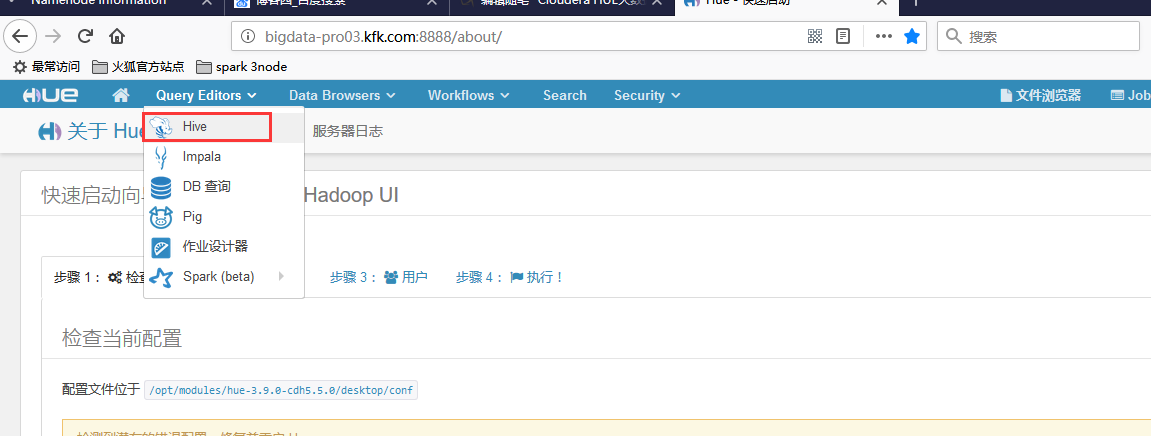
可以看到hive里面我们之前创建的表

我们试图执行一下查询语句,结果报错了
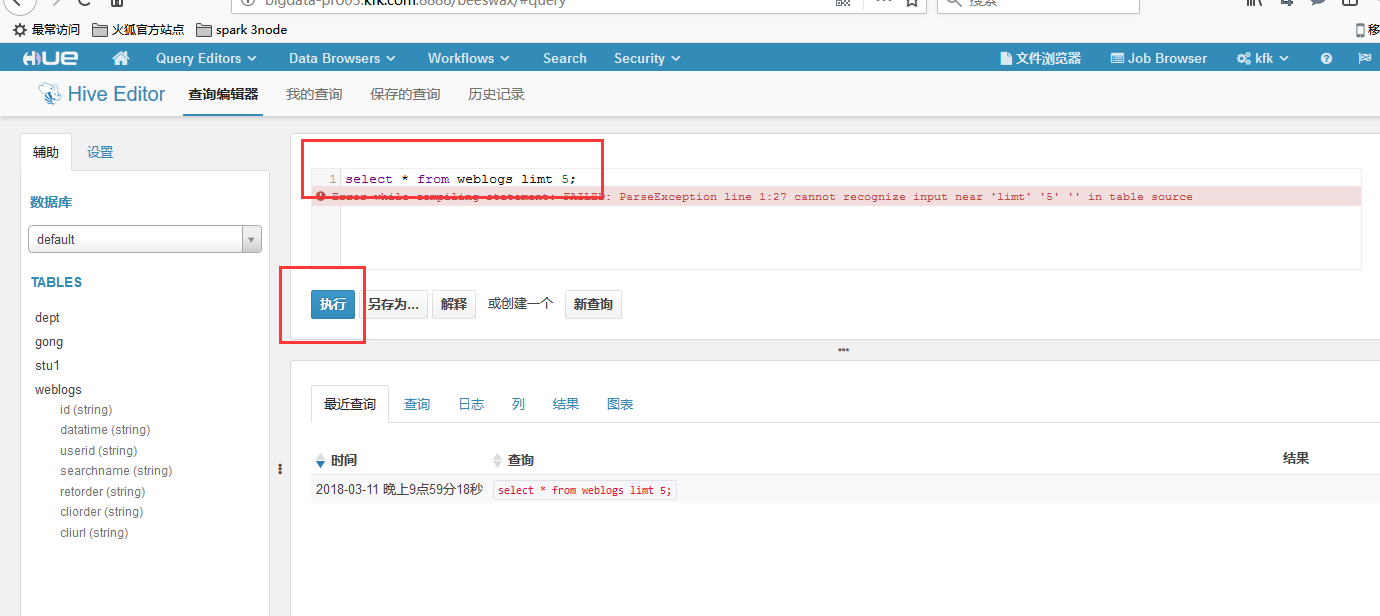
在xshell里面看到报错的信息
[kfk@bigdata-pro03 hive-0.13.-cdh5.3.0]$ bin/hiveserver2
Starting HiveServer2
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
NoViableAltException(@[:: ( ( KW_AS )? alias= Identifier )?])
at org.antlr.runtime.DFA.noViableAlt(DFA.java:)
at org.antlr.runtime.DFA.predict(DFA.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser_FromClauseParser.tableSource(HiveParser_FromClauseParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser_FromClauseParser.fromSource(HiveParser_FromClauseParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser_FromClauseParser.joinSource(HiveParser_FromClauseParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser_FromClauseParser.fromClause(HiveParser_FromClauseParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.fromClause(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.singleSelectStatement(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.selectStatement(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.regularBody(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.queryStatementExpressionBody(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.queryStatementExpression(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.execStatement(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:)
at org.apache.hive.service.cli.operation.SQLOperation.prepare(SQLOperation.java:)
at org.apache.hive.service.cli.operation.SQLOperation.run(SQLOperation.java:)
at org.apache.hive.service.cli.session.HiveSessionImpl.runOperationWithLogCapture(HiveSessionImpl.java:)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementInternal(HiveSessionImpl.java:)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementAsync(HiveSessionImpl.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:)
at org.apache.hive.service.cli.session.HiveSessionProxy.access$(HiveSessionProxy.java:)
at org.apache.hive.service.cli.session.HiveSessionProxy$.run(HiveSessionProxy.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.hive.shims.HadoopShimsSecure.doAs(HadoopShimsSecure.java:)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:)
at com.sun.proxy.$Proxy16.executeStatementAsync(Unknown Source)
at org.apache.hive.service.cli.CLIService.executeStatementAsync(CLIService.java:)
at org.apache.hive.service.cli.thrift.ThriftCLIService.ExecuteStatement(ThriftCLIService.java:)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
FAILED: ParseException line : cannot recognize input near 'limt' '' '<EOF>' in table source
OK
OK
NoViableAltException(@[:: ( ( KW_AS )? alias= Identifier )?])
at org.antlr.runtime.DFA.noViableAlt(DFA.java:)
at org.antlr.runtime.DFA.predict(DFA.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser_FromClauseParser.tableSource(HiveParser_FromClauseParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser_FromClauseParser.fromSource(HiveParser_FromClauseParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser_FromClauseParser.joinSource(HiveParser_FromClauseParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser_FromClauseParser.fromClause(HiveParser_FromClauseParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.fromClause(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.singleSelectStatement(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.selectStatement(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.regularBody(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.queryStatementExpressionBody(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.queryStatementExpression(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.execStatement(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:)
at org.apache.hive.service.cli.operation.SQLOperation.prepare(SQLOperation.java:)
at org.apache.hive.service.cli.operation.SQLOperation.run(SQLOperation.java:)
at org.apache.hive.service.cli.session.HiveSessionImpl.runOperationWithLogCapture(HiveSessionImpl.java:)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementInternal(HiveSessionImpl.java:)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementAsync(HiveSessionImpl.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:)
at org.apache.hive.service.cli.session.HiveSessionProxy.access$(HiveSessionProxy.java:)
at org.apache.hive.service.cli.session.HiveSessionProxy$.run(HiveSessionProxy.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.hive.shims.HadoopShimsSecure.doAs(HadoopShimsSecure.java:)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:)
at com.sun.proxy.$Proxy16.executeStatementAsync(Unknown Source)
at org.apache.hive.service.cli.CLIService.executeStatementAsync(CLIService.java:)
at org.apache.hive.service.cli.thrift.ThriftCLIService.ExecuteStatement(ThriftCLIService.java:)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:)
at org.apache.hive.service.cli.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
FAILED: ParseException line : cannot recognize input near 'limt' '' '<EOF>' in table source
OK
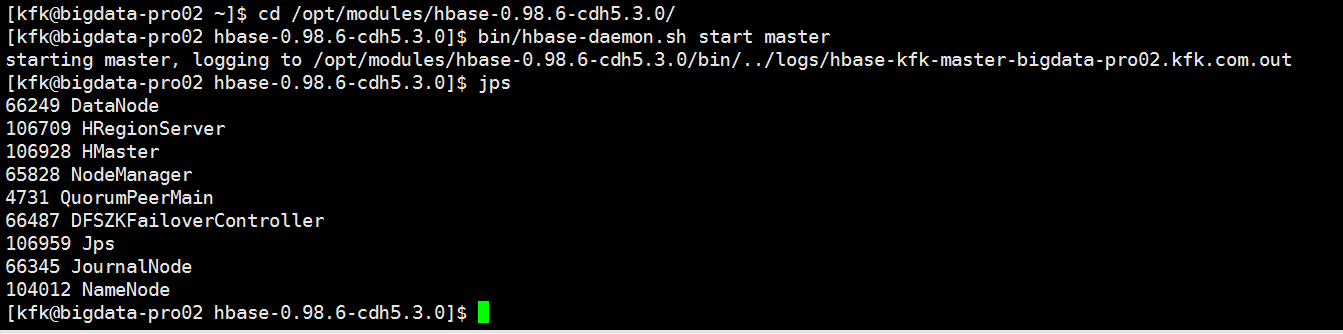
是因为我们的hbase没有启动的原因
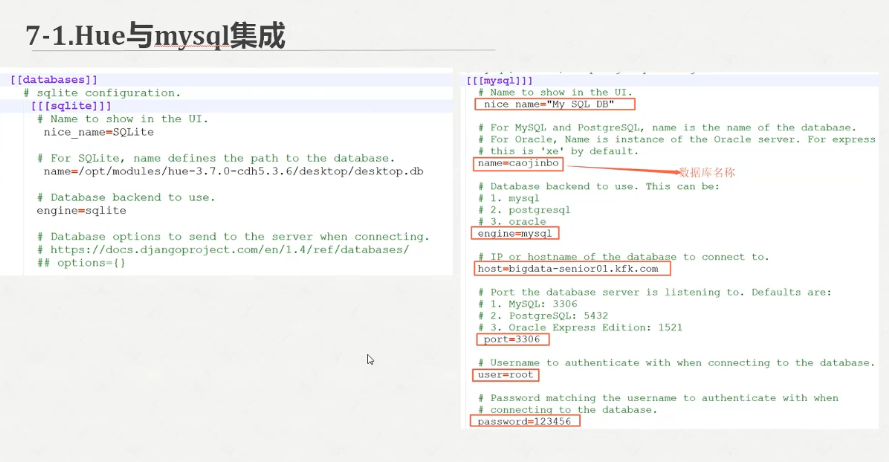
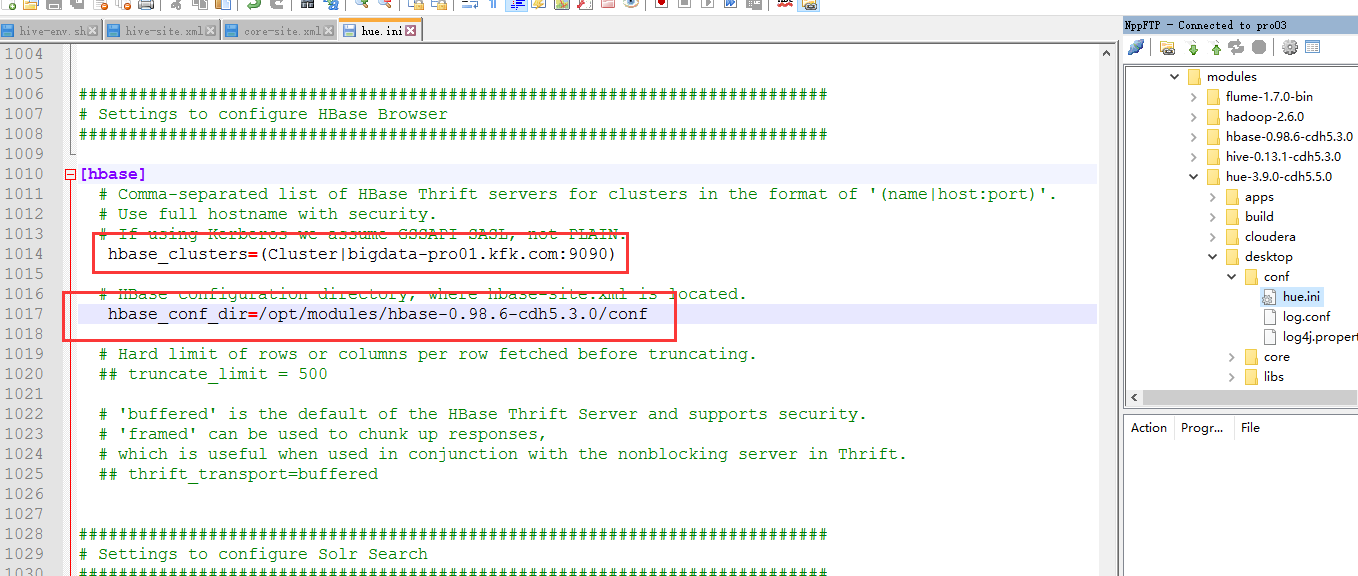
配置hue.ini
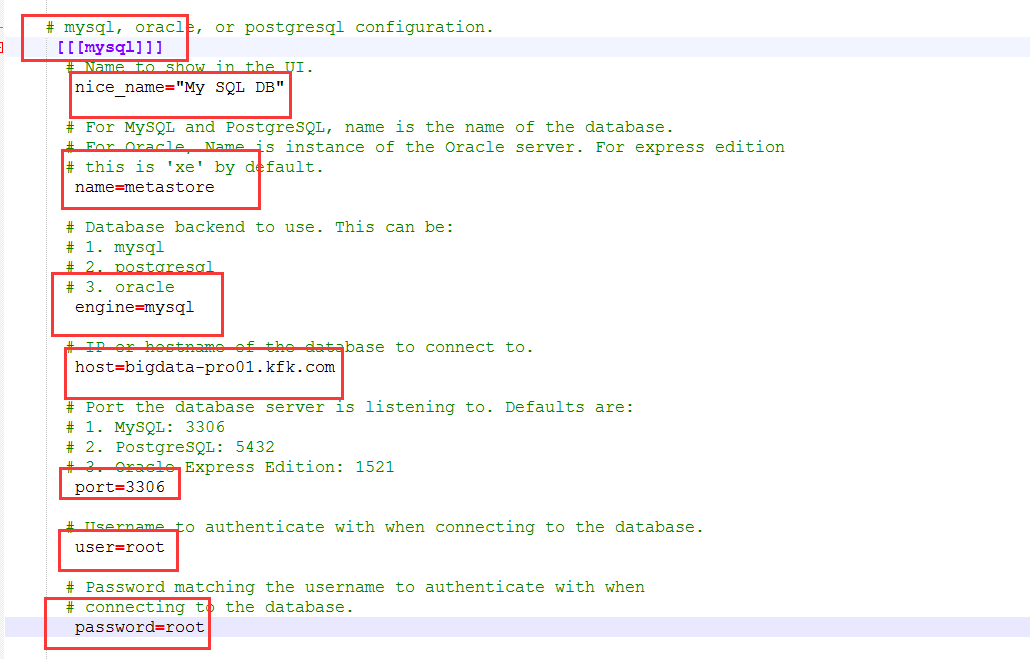
重启一下hue
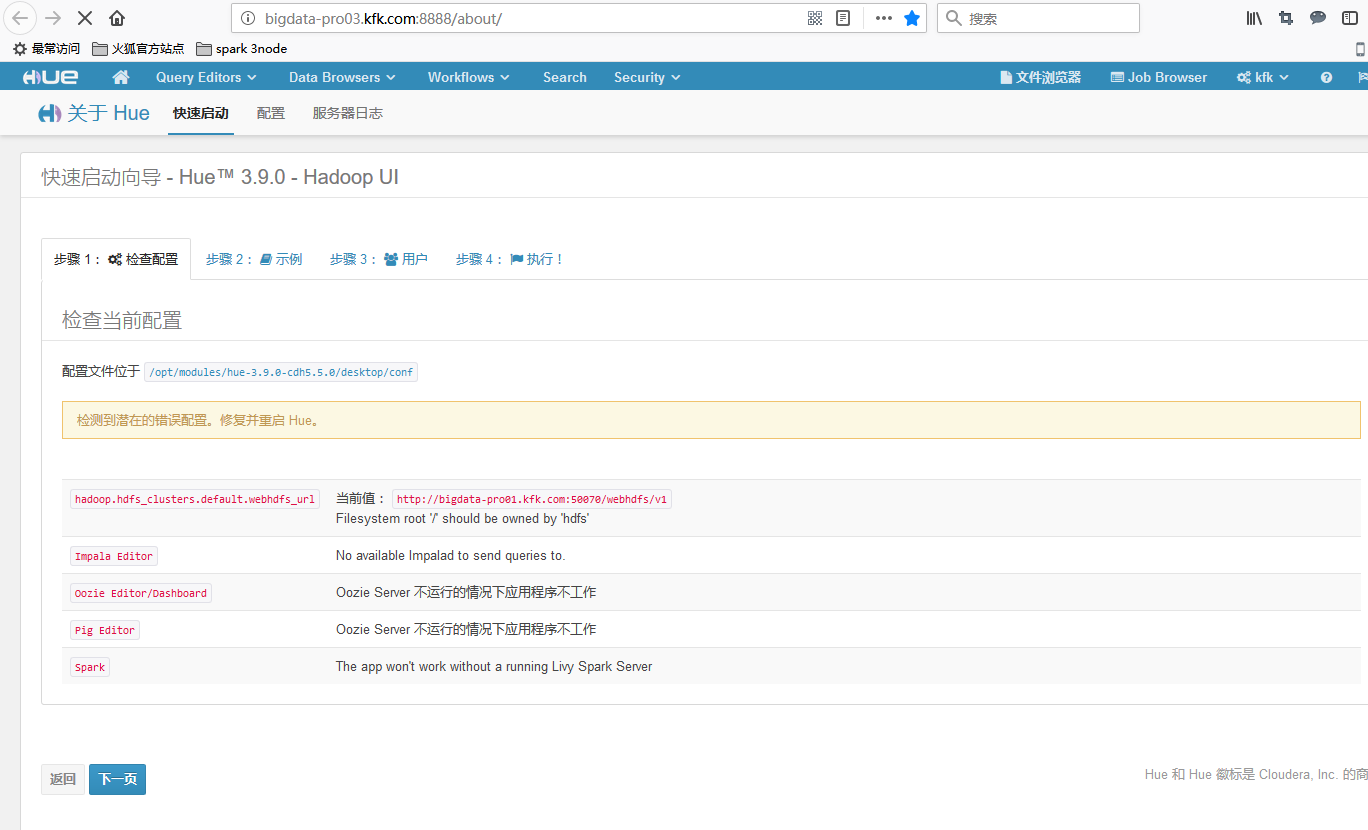
我们重新打开可视化界面

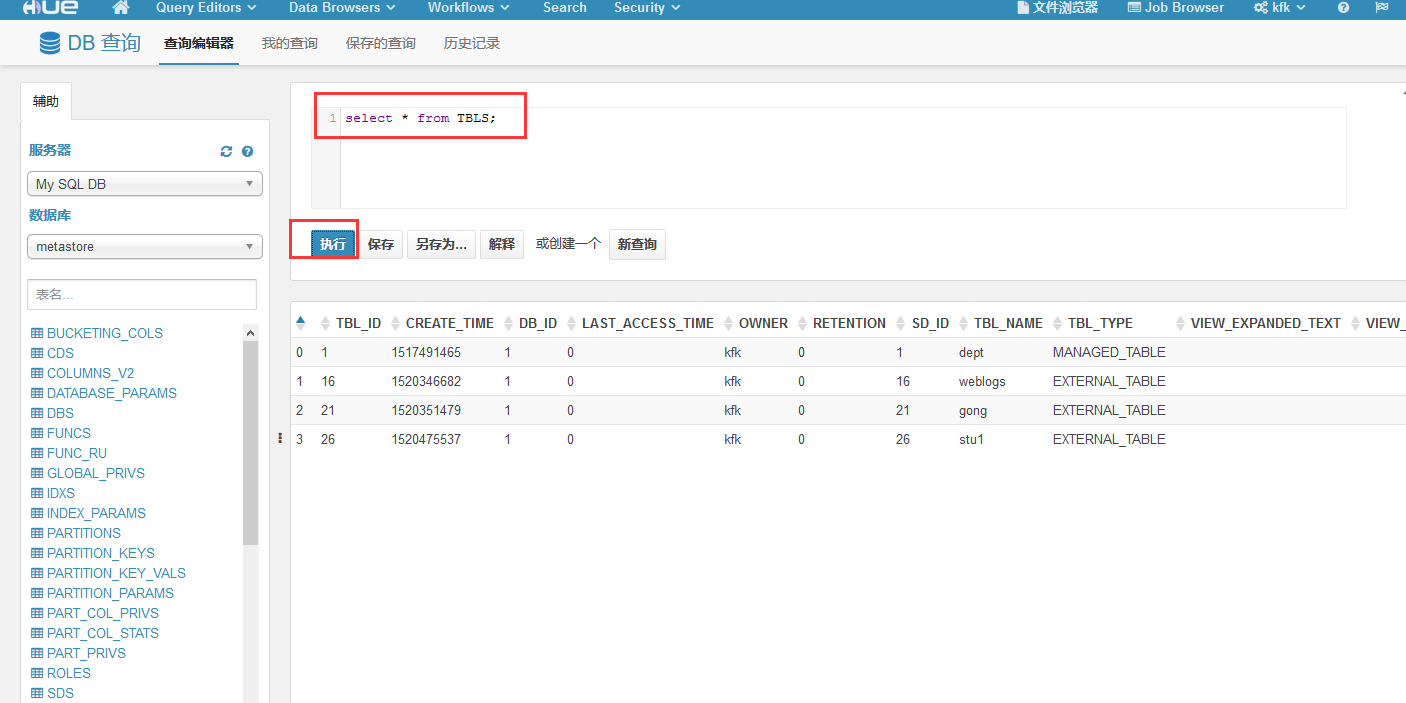
执行一下查询语句

启动hbase
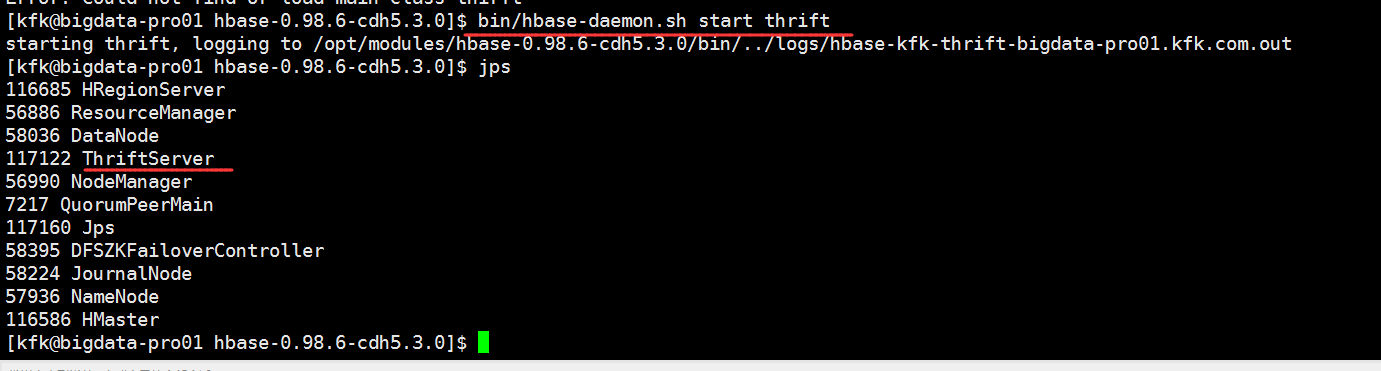
由于hue3.9版本的兼容性问题,下面我们改用hue3.7版本,配置跟3.9一样的。
但是我这里的环境问题,用3.7的版本没办法打开可视化界面,我估计是我的hive hbase的版本太低的原因了,我还是只能用回3.9版本的,还请大家谅解,建议hbase hive都用1.0以上的版本吧
如果大家遇到这个问题,hive命令行没有显示日志的话可以参考一下方法
Cloudera HUE大数据可视化分析的更多相关文章
- 新闻实时分析系统Hive与HBase集成进行数据分析 Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 基于 HTML5 WebGL 与 GIS 的智慧机场大数据可视化分析
前言:大数据,人工智能,工业物联网,5G 已经或者正在潜移默化地改变着我们的生活.在信息技术快速发展的时代,谁能抓住数据的核心,利用有效的方法对数据做数据挖掘和数据分析,从数据中发现趋势,谁就能做到精 ...
- 基于 HTML5 WebGL 与 GIS 的智慧机场大数据可视化分析【转载】
前言:大数据,人工智能,工业物联网,5G 已经或者正在潜移默化地改变着我们的生活.在信息技术快速发展的时代,谁能抓住数据的核心,利用有效的方法对数据做数据挖掘和数据分析,从数据中发现趋势,谁就能做到精 ...
- PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品,产品设计严格遵循国际数据挖掘标准CRISP-DM(跨行业数据挖掘过程标准),具备完备的数据准备、模型构建、模型评估、模型管理、海量数据处理和高纬数据可视化分析能力。
http://www.meritdata.com.cn/article/90 PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品, ...
- HTML5大数据可视化效果(二)可交互地铁线路图
前言 最近特别忙,承蒙大伙关照,3D机房的项目一个接着一个,领了一帮小弟,搞搞传帮带,乌飞兔走,转眼已经菊黄蟹肥……有个小弟很不错,勤奋好学,很快就把API都摸透了,自己折腾着做了个HTML5的魔都的 ...
- 高速基于echarts的大数据可视化
[Author]: kwu 高速基于echarts的大数据可视化,echarts纯粹的js实现的图表工具.高速开发的过程例如以下: 1.引入echarts的依赖js库 <script type= ...
- 在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析
在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析 低成本的Blob存储是一个强大的.通用的Hadoop兼容Azure存储解决方式无缝集成HDInsight.通过Hadoop分布式 ...
随机推荐
- css重难点笔记
只有定位(static除外)的盒子才有z-index,即对静态定位,文档流和浮动设置z-index,都是无效的. 一个盒子如果未给宽度,那么被浮动,绝对定位,display:inline-block之 ...
- 我发起了一个 .Net 开源 数据库 项目 SqlNet
大家好 , 我发起了一个 .Net 开源 数据库 项目 SqlNet . 项目计划 是 用 C# 写一个 关系数据库 . 可以先参考我之前写的 2 篇文章 : 谈谈数据库原理 https://w ...
- 在单文件组件中,引入安装模块里的css的2种方式:script中引入、style中引入
在单文件组件中,引入安装模块里的css的2种方式:script中引入.style中引入 1.script中引入 <script> import 'bulma/css/bulma.css' ...
- c#多线程与委托(转)
一:线程在.net中提供了两种启动线程的方式,一种是不带参数的启动方式,另一种是带参数的启动的方式.不带参数的启动方式 如果启动参数时无需其它额外的信息,可以使用ThreadStart来实例化Thre ...
- LOJ 2743(洛谷 4365) 「九省联考 2018」秘密袭击——整体DP+插值思想
题目:https://loj.ac/problem/2473 https://www.luogu.org/problemnew/show/P4365 参考:https://blog.csdn.net/ ...
- itertools.groupby()/itertools.compress() 笔记
关于itertools.groupby() itertools.groupby()就是将相邻的并且相同的键值划分为同一组,相似功能可以看https://docs.python.org/3/librar ...
- pyhanlp 中文词性标注与分词简介
pyhanlp 中文词性标注与分词简介 pyhanlp实现的分词器有很多,同时pyhanlp获取hanlp中分词器也有两种方式 第一种是直接从封装好的hanlp类中获取,这种获取方式一共可以获取五种分 ...
- java.lang.IllegalArgumentException: URLDecoder: Illegal hex characters in escape (%) pattern - For input string: " 0"
value = URLDecoder.decode(request.getParameter(paraName), "UTF-8"); 前端用了 encodeURI 来编码参数,后 ...
- Selenium Python FirefoxWebDriver处理打开保存对话框
代码如下(网上示例): #profile = webdriver.FirefoxProfile(r"C:\Users\Skyyj\AppData\Roaming\Mozilla\Firef ...
- ribbon的注解使用报错--No instances available for [IP]
使用RestTemplate类调用其他系统的url的时候,加上ribbon的注解@LoadBalanced上这个注解之后访问,就报错了. 报错如下: 因为这里你不能直接访问地址,需要把地址改成你所调用 ...