MapReduce之WritableComparable排序
@
排序概述
- 排序是MapReduce框架中最重要的操作之一。
- Map Task和ReduceTask均会默认对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
- 黑默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
- 对于
MapTask,它会将处理的结果暂时放到一个缓冲区中,当缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次排序,并将这些有序数据写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行一次合并,以将这些文件合并成一个大的有序文件。 - 对于
ReduceTask,它从每个MapTak上远程拷贝相应的数据文件,如果文件大小超过一定阑值,则放到磁盘上,否则放到内存中。如果磁盘上文件数目达到一定阈值,则进行一次合并以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。 - 排序器:排序器影响的是排序的速度(效率,对什么排序?),QuickSorter
- 比较器:比较器影响的是排序的结果(按照什么规则排序)
获取Mapper输出的key的比较器(源码)
public RawComparator getOutputKeyComparator() {
// 从配置中获取mapreduce.job.output.key.comparator.class的值,必须是RawComparator类型,如果没有配置,默认为null
Class<? extends RawComparator> theClass = getClass(JobContext.KEY_COMPARATOR, null, RawComparator.class);
// 一旦用户配置了此参数,实例化一个用户自定义的比较器实例
if (theClass != null){
return ReflectionUtils.newInstance(theClass, this);
}
//用户没有配置,判断Mapper输出的key的类型是否是WritableComparable的子类,如果不是,就抛异常,如果是,系统会自动为我们提供一个key的比较器
return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class), this);
}
案例实操(区内排序)
需求
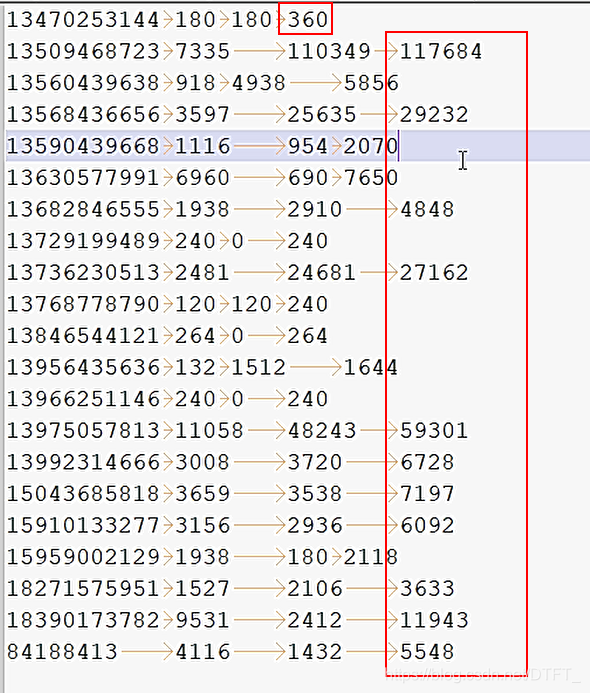
对每个手机号按照上行流量和下行流量的总和进行内部排序。
思考
因为Map Task和ReduceTask均会默认对数据按照key进行排序,所以需要把流量总和设置为Key,手机号等其他内容设置为value
FlowBeanMapper.java
public class FlowBeanMapper extends Mapper<LongWritable, Text, LongWritable, Text>{
private LongWritable out_key=new LongWritable();
private Text out_value=new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
//封装总流量为key
out_key.set(Long.parseLong(words[3]));//切分后,流量和的下标为3
//封装其他内容为value
out_value.set(words[0]+"\t"+words[1]+"\t"+words[2]);
context.write(out_key, out_value);
}
}
FlowBeanReducer.java
public class FlowBeanReducer extends Reducer<LongWritable, Text, Text, LongWritable>{
@Override
protected void reduce(LongWritable key, Iterable<Text> values,
Reducer<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value, key);
}
}
}
FlowBeanDriver.java
public class FlowBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("E:\\mroutput\\flowbean");
Path outputPath=new Path("e:/mroutput/flowbeanSort1");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(FlowBeanMapper.class);
job.setReducerClass(FlowBeanReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
//由于Mapper和Reducer输出的Key-value类型不一致(maper输出类型是long-text,而reducer是text-value)
//所以需要额外设定
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 默认升序排,可以设置使用自定义的比较器
//job.setSortComparatorClass(DecreasingComparator.class);
// ③运行Job
job.waitForCompletion(true);
}
}
运行结果(默认升序排)
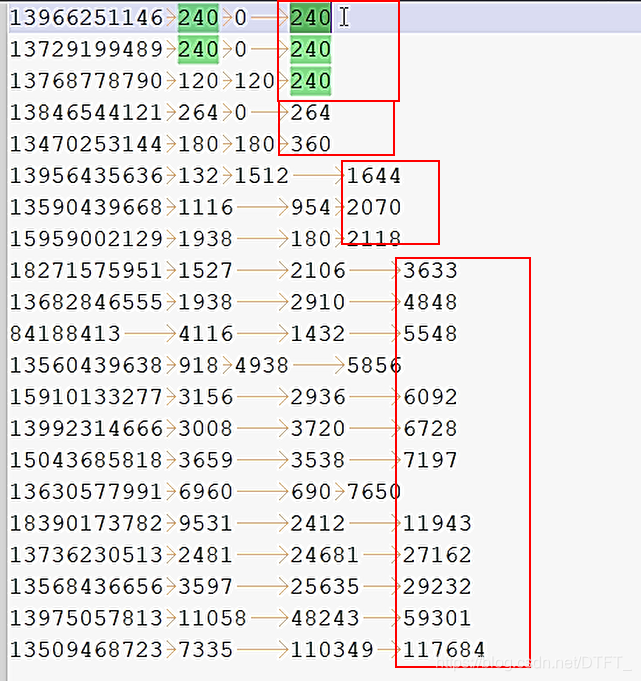
自定义排序器,使用降序
方法一:自定义类,这个类必须是
RawComparator类型,通过设置mapreduce.job.output.key.comparator.class自定义的类的类型。
自定义类时,可以继承WriableComparator类,也可以实现RawCompartor
调用方法时,先调用RawCompartor. compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2),再调用RawCompartor.compare()方法二:定义Mapper输出的key,让key实现
WritableComparable,实现CompareTo()
MyDescComparator.java
public class MyDescComparator extends WritableComparator{
@Override
public int compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2) {
long thisValue = readLong(b1, s1);
long thatValue = readLong(b2, s2);
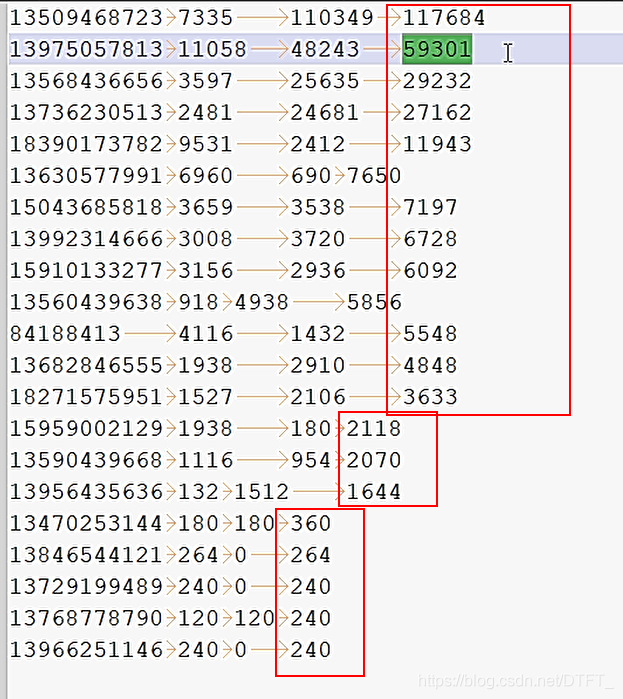
//这里把第一个-1改成1,把第二个1改成-1,就是降序排
return (thisValue<thatValue ? 1 : (thisValue==thatValue ? 0 : -1));
}
}
运行结果
MapReduce之WritableComparable排序的更多相关文章
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop学习笔记: MapReduce二次排序
本文给出一个实现MapReduce二次排序的例子 package SortTest; import java.io.DataInput; import java.io.DataOutput; impo ...
- (转)MapReduce二次排序
一.概述 MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的.在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求 ...
- 详细讲解MapReduce二次排序过程
我在15年处理大数据的时候还都是使用MapReduce, 随着时间的推移, 计算工具的发展, 内存越来越便宜, 计算方式也有了极大的改变. 到现在再做大数据开发的好多同学都是直接使用spark, hi ...
- mapreduce数据处理——统计排序
接上篇https://www.cnblogs.com/sengzhao666/p/11850849.html 2.数据处理: ·统计最受欢迎的视频/文章的Top10访问次数 (id) ·按照地市统计最 ...
- mapreduce 实现数子排序
设计思路: 使用mapreduce的默认排序,按照key值进行排序的,如果key为封装int的IntWritable类型,那么MapReduce按照数字大小对key排序,如果key为封装为String ...
- MapReduce二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
随机推荐
- 真的可以,用C语言实现面向对象编程OOP
ID:技术让梦想更伟大 作者:李肖遥 解释区分一下C语言和OOP 我们经常说C语言是面向过程的,而C++是面向对象的,然而何为面向对象,什么又是面向过程呢?不管怎么样,我们最原始的目标只有一个就是实现 ...
- 修改CentOS7登录欢迎界面信息
vi /etc/issue 添加自己喜欢的内容,保存即可. 特殊字符的含义: \d 本地端时间的日期: \l 显示第几个终端机接口: \m 显示硬件的等级 (i386/i486/i586/i686.. ...
- 【PyMuPDF和pdf2image】Python将PDF转成图片
前言: 在最近的测试中遇到一个与PDF相关的测试需求,其中有一个过程是将PDF转换成图片,然后对图片进行测试. 粗略的试了好几种方式,其中语言尝试了Python和Java,总体而言所找到的Python ...
- python中pymysql executemany 批量插入数据
import pymysqlimport timedb = pymysql.connect("IP","username","password&quo ...
- System.Timers.Timer(定时器)
1.System.Timers命名空间下的Timer类.System.Timers.Timer类:定义一个System.Timers.Timer对象,然后绑定Elapsed事件,通过Start()方法 ...
- mui点击蒙版点击蒙版让其不自动关闭
var mask = mui.createMask(callback);//callback为用户点击蒙版时自动执行的回调: mask.show();//显示遮罩 mask.close();//关闭遮 ...
- YAML 语言教程与使用案例
YAML语言教程与使用案例,如何编与读懂写YAML文件. YAML概要 YAML 是 “YAML Ain’t a Markup Language”(YAML 不是一种标记语言)的递归缩写.在开发的这种 ...
- java 基本语法(十九)Optional类的使用
java.util.Optional类1.理解:为了解决java中的空指针问题而生!Optional<T> 类(java.util.Optional) 是一个容器类,它可以保存类型T的值, ...
- (五)学习了解OrchardCore笔记——灵魂中间件ModularTenantContainerMiddleware的第一行②模块的功能部分
在(三)的时候已经说到模块集合用ForEachAsync的扩展方法分配多个任务,把每个modules的ManifestInfo分析出来的功能加入ConcurrentDictionary.我们先看看这个 ...
- 为什么大家都在用Fiddler?
在我们做接口测试的时候,经常需要验证发送的消息是否正确,或者在出现问题的时候,查看手机客户端发送给server端的包内容是否正确,就需要用到抓包工具.常用的抓包工具有fiddler.wireshark ...