Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
![]()
前言
在我们在爬取手机APP上面的数据的时候,都会借助Fidder来爬取。今天就教大家如何爬取手机APP上面的数据。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:1097524789
环境配置
1、Fidder的安装和配置
下载Fidder软件地址:https://www.telerik.com/download/fiddler
然后就是傻瓜式的安装,安装步骤很简单。在安装完成后,打开软件,进行如下设置:
默认的8888端口
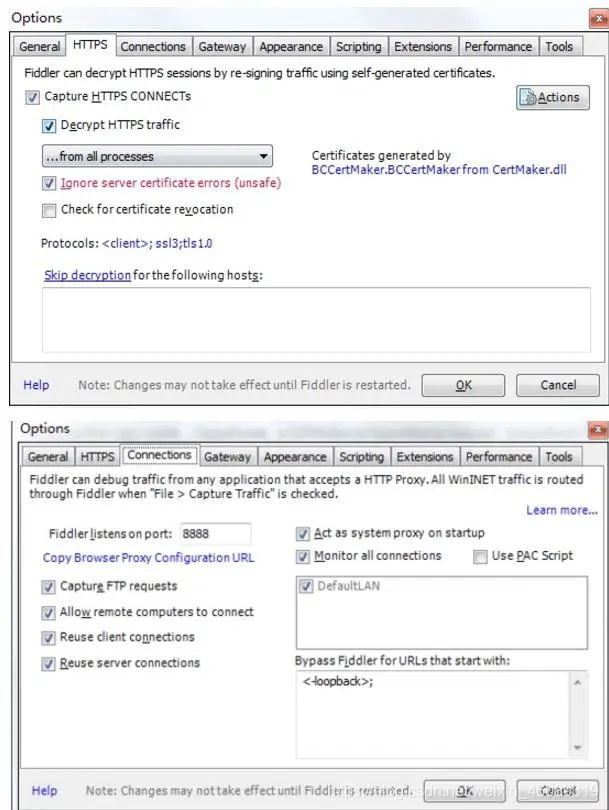
![]()
2、手机的配置
首先打开cmd,输入ipconfig查看IP地址,记录下这个IP地址:
![]()
想要使用FIdder进行手机抓包,要让手机和PC处在同一个内网中,方法就是连接同一个无线网络。然后打开手机,进入Wi-FI设置修改代理为手动代理,再把上面的IP地址和8888端口号输入进去:
![]()
然后打开浏览器,输入http://127.0.0.1:8888,会看到如下界面,点击FidderRoot certificate下载证书:
![]()
下载好之后如果出现无法安装的情况,可以进入设置进行手动安装证书,我的安装步骤是“设置->系统安全->从SD卡安装”,不同的手机安装步骤不同,不过也差不多吧。
3、抓包测试
在完成上面的步骤之后,我们先进行一下抓包测试,打开手机的浏览器,然后打开百度的网页,可以看到出现了对应的包,这样就可以进行之后的抓取了。
![]()
抓取步骤
这次使用的APP是王者荣耀盒子,打开APP,点击英雄,可以看到第一个英雄-上官婉儿,然后点进去。
![]()
然后在Fidder中可以找到如下这个包:
![]()
然后在右侧可以看到如下信息:
![]()
把这些信息复制一下,然后解码一下就可以看到如下数据了,包括英雄名字、英雄图片、英雄技能等信息:
![]()
但是在推荐装备的信息里,只有装备的id值,却没有装备的名字,那我们要怎么获得这些装备的名字呢?还是同样的办法,点击查看所有装备,然后抓包,找到对应的包,再进行爬取。在获得所有的装备和对应的id后,可以再爬取所有的英雄名称,然后就可以制作我们自己的英雄攻略了==
运行结果如下:
![]()
完整代码
![]()
Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢的更多相关文章
- ORM取数据很简单!是吗?
简介 几乎任何系统都以某种方式与外部数据存储一起运行.大多数情况下,外部数据存储是一个关系数据库,并且在实现时通常将数据提取任务委托给某些 ORM. 尽管 ORM 包含很多 routine 代码,但是 ...
- 轻松搞定Ajax(分享下自己封装ajax函数,其实Ajax使用很简单,难是难在你得到数据后来怎样去使用这些数据)
hey,guys!今天我们一起讨论下ajax吧!此文只适合有一定ajax基础,但还是模糊状态的同志,当然高手也可以略过~~~ 一.概念 Ajax(Asynchronous Javascript + X ...
- POI导出大量数据的简单解决方案(附源码)-Java-POI导出大量数据,导出Excel文件,压缩ZIP(转载自iteye.com)
说明:我的电脑 2.0CPU 2G内存 能够十秒钟导出 20W 条数据 ,12.8M的excel内容压缩后2.68M 我们知道在POI导出Excel时,数据量大了,很容易导致内存溢出.由于Excel ...
- webmagic 二次开发爬虫 爬取网站图片
webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫. webmagic介绍 编写一个简单的爬虫 webmagic的使用文档:http://w ...
- Python爬虫入门教程 47-100 mitmproxy安装与安卓模拟器的配合使用-手机APP爬虫部分
1. 准备下载软件 介绍一款爬虫辅助工具mitmproxy ,mitmproxy 就是用于MITM的proxy,MITM中间人攻击.说白了就是服务器和客户机中间通讯多增加了一层.跟Fiddler和Ch ...
- UWP开发:APP之间的数据交互(以微信为例)
目录 说明 UWP应用唤醒方式 跟微信APP交互数据 APP之间交互数据的前提 说明 我们经常看到,在手机上不需要退到桌面,APP之间就可以相互切换,并且可以传递数据.比如我在使用知乎APP的时候,需 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python获取动态网站上面的动态加载的数据(初级)
我们在处理一些网站数据的时候,有时候我们需要的数据很多都是动态加载的,而不都是静态的,以下以一个实例来介绍简单的获取动态数据,首先申明本人小白,还在学习python中,这个方法还是比较笨拙的,但是对于 ...
随机推荐
- 1-GPIO
GPIO的配置: GPIO库函数编程: void LED_init(void)//LED初始化 { GPIO_InitTypeDef GPIO_InitStructure;//定义一个结构体变量 RC ...
- 二、python 中五种常用的数据类型
一.字符串 单引号定义: str1 = 'hello' 双引号定义: str1 = "hello" 三引号定义:""" 人生苦短, 我用python! ...
- Scala 面向对象(四):import
1 Scala引入包基本介绍 Scala引入包也是使用import, 基本的原理和机制和Java一样,但是Scala中的import功能更加强大,也更灵活. 因为Scala语言源自于Java,所以ja ...
- JVM 专题九:运行时数据区(四)本地方法栈
1. 本地方法栈 2. 什么是本地方法栈? Java虚拟机栈用于管理Java方法的调用,而本地方法栈用于管理本地方法的调用 本地方法栈,也是线程私有的. 允许被实现成固定或者是可动态拓展的内存大小 ...
- selenium:selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
可用链接: 1.http://blog.csdn.net/heatdeath/article/details/71136174 2.https://www.cnblogs.com/yousuosiys ...
- unity-疑难杂症(一)
1.使用odin插件序列化,当出现预制体有引用类型的关联, 拖到scene就没关联时,可右键预制体--Reimport解决. 2.类似问题1,脚本组件关联AudioMixer,拖到scene没有关联, ...
- Java应用服务器之tomcat部署
一.相关术语简介 首先我们来了解下tomcat是什么,tomcat是apache软件基金会中的一个项目,由apache.Sun 和其他一些公司及个人共同开发而成.主要作用是提供servlet和jsp类 ...
- Java匿名对象介绍
Java匿名对象介绍 什么是匿名对象? 顾名思义就是没有变量名的对象,即创建对象时,只有创建对象的语句,却没有把对象地址值赋值给某个变量. 匿名对象命名格式:以Scanner类举例 new Scann ...
- 设计模式:fly weight模式
目的:通过共享实例的方式来避免重复的对象被new出来,节约系统资源 别名:享元模式 例子: class Char //共享的类,轻量级 { char c; public: Char(char c) { ...
- WPF 有缩放时显示线条的问题
公司项目已经开发好几年了,用的WPF开发的,期间遇到好多问题,都是些小细节.很久没有写博客了,以后有时间还是需要写写博客啊!作为分享也好.记录也好,利人利己嘛. 今天主要说一下显示线条的问题,因为我们 ...