sentinel流量控制和熔断降级执行流程之源码分析
前言:
sentinel是阿里针对服务流量控制、熔断降级的框架,如何使用官方都有很详细的文档,下载它的源码包 里面对各大主流框都做了适配按理,本系列文章目的 主要通过源码分析sentinel流量控制和熔断降级的流程
提前准备好sentinel控制台 如有下载源码启动sentinel dashboard模块
本文演示的项目通过引入spring-cloud-starter-alibaba-sentinel包来实现接入sentinel功能
入门案例
下面举一个最简单的案例埋点来引出流控入口
public String getOrderInfo(String orderNo) {
ContextUtil.enter("getOrderInfo", "application-a");
Entry entry = null;
try {
// name:资源名 EntryType 流量类型为入口还是出口,系统规则只针对入口流量, batchCount:当前请求流量, args:参数
entry = SphU.entry("getOrderInfo", EntryType.IN, 1, orderNo);
getUserInfo();
} catch (BlockException e) {
e.printStackTrace();
} finally {
entry.exit();
}
return "orderInfo = " + orderNo;
}
public String getUserInfo() {
Entry entry = null;
try {
entry = SphU.entry("getUserInfo", EntryType.OUT, 1);
} catch (BlockException e) {
e.printStackTrace();
} finally {
entry.exit();
}
return "userInfo";
}
public static Entry entry(String name, EntryType trafficType, int batchCount, Object... args) throws BlockException
也可以通过注解的方式引入,执行方法时SentinelResourceAspect会做拦截进行流控处理,当然什么都不配也是可以的,因为引入spring-cloud-starter-alibaba-sentinel包spring mvc和spring webflux做了适配,自动会对每一个请求做埋点
@GetMapping("getOrderInfo")
@SentinelResource(value = "/getOrderInfo", entryType = EntryType.IN)
public String getOrderInfo(@RequestParam("orderNo") String orderNo) {
return "orderInfo = " + orderNo;
}
ContextUtil.enter("getOrderInfo", "application-a") 来表示调用链的入口,可以暂时理解为上下文,一般不做声明 后面会默认创建
第一个参数为context-name,区分不同的调用链入口,默认常量值sentinel_default_context,
第二参数为调用来源,这个参数可以细分从不同应用来源发出的请求,授权规则白名单和黑名单会根据该参数做限制,
然后通过SphU.entry()埋点进入,下面说下这个方法几个参数的含义
- name:当前资源名
- trafficType:流量类型 分别为入口流量和出口流量。入口流量和出口流量执行过程都是差不多,只是入口流量会多了一个系统规则拦截,像是上面案例从订单服务调用getUserInfo,getUserInfo是去调用用户服务,它的流量方式是出去的,压力都在用户服务那边,不用考虑当前服务器的压力,所以标为出口流量
- batchCount:当前流量数量,一般默认为1
- args:参数,后面做热点参数规则时用到
BlockException:当某一规则不通过时会抛出对应异常
SphU.entry(xxx) 需要与 entry.exit() 方法成对出现,匹配调用,如有嵌套像上面,需先退出getUserInfo的entry在退出getOrderInfo的entry
打开打控制台,此时应该是空白的,sentinel控制台是懒加载模式,需要调用一下相关资源接口就可以看到
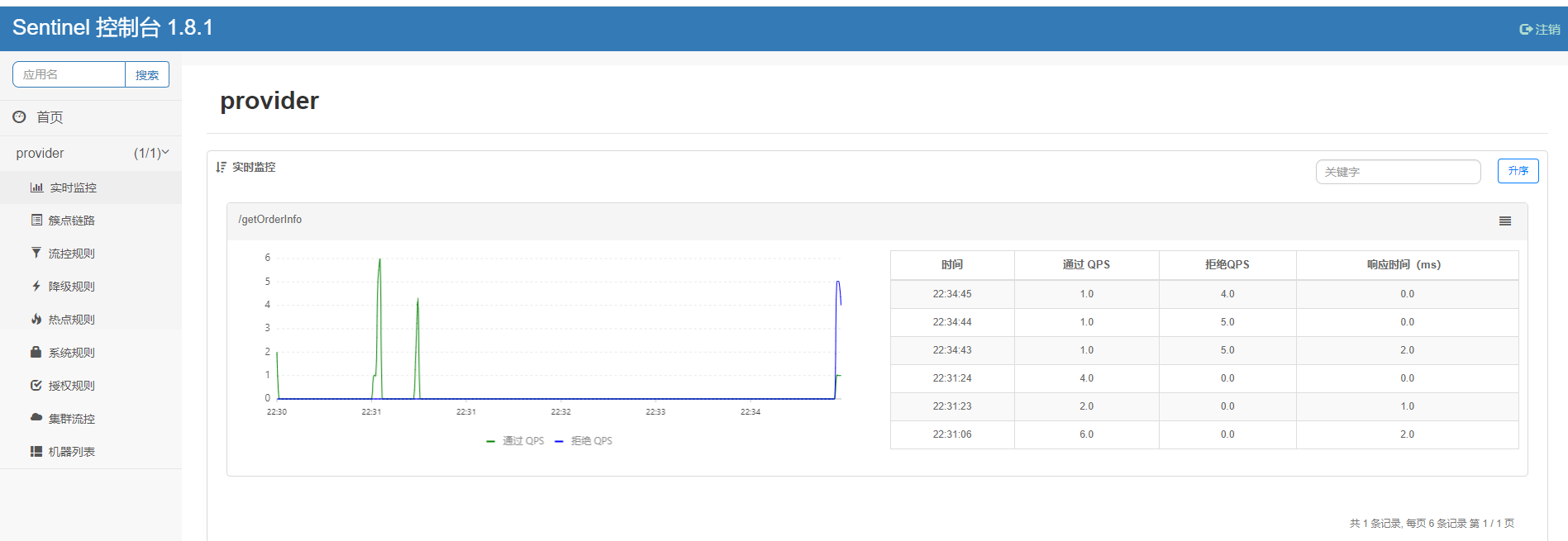
可以看到sentinel规则配置主要有流控规则,降级规则,热点规则,系统规则,授权规则,先简单介绍下规则作用,其它配置也很简单 一目了然,后面通过结合源码来深入分析
- 流控规则:针对资源流量控制
- 热点规则:针对资源的热点参数做流量控制
- 降级规则:针对资源的调度情况来做降级处理
- 系统规则:针对当前服务做全局流量控制
- 授权规则:对访问资源的特定应用做授权处理
我们随着SphU.entry()入口来走进源码
SphU.entry(xxx)执行过程源码分析
流控规则执行前的准备
public static Entry entry(String name, EntryType trafficType, int batchCount, Object... args)
throws BlockException {
return Env.sph.entry(name, trafficType, batchCount, args);
} public Entry entry(String name, EntryType type, int count, Object... args) throws BlockException {
// 将资源名称和流量类型进行包装
StringResourceWrapper resource = new StringResourceWrapper(name, type);
return entry(resource, count, args);
} private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args)
throws BlockException {
// 这里返回当前线程持有的context
Context context = ContextUtil.getContext();
if (context instanceof NullContext) {
return new CtEntry(resourceWrapper, null, context);
}
if (context == null) {
// 为空创建一个默认
context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
} // 全局开关 不进行规则检查
if (!Constants.ON) {
return new CtEntry(resourceWrapper, null, context);
}
// 添加一个规则检查调用链
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
// 创建一个流量入口,将context curEntry进行指定
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
// 开始规则检查
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) {
// 发生流控异常进行退出
e.exit(count, args);
// 将异常向上抛
throw e1;
} catch (Throwable e1) {
// This should not happen, unless there are errors existing in Sentinel internal.
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}
可以看到准备过程主要做了五件事
- 将资源名称和流量类型进行包装
- 从当前线程得到context,如果之前没有创建context,则这里会创建一个context-name为sentinel_default_name、original为""的context
- 添加一个规则检查调用链,根据我们配置的规则一层一层进行检查,只要在某一个规则未通过就提前结束抛出该规则对应的异常
- 创建一个流量入口entry,它用来保存本次调用的信息,将context的curEntry进行指定
- 开始执行规则检查调用链
context创建过程
来看下context的创建过程,因为里面还涉及到一个非常重要的类Node,它的作用是统计资源的调用信息,如QPS、rt等信息
protected static Context trueEnter(String name, String origin) {
// 从当前线程上下文中拿
Context context = contextHolder.get();
if (context == null) {
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
// 获取context-name对应的DefaultNode
DefaultNode node = localCacheNameMap.get(name);
if (node == null) {
// 限制2000,也就是最多申明2000不同名称的上下文
if (localCacheNameMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
LOCK.lock();
try {
// 防止并发,再次检查
node = contextNameNodeMap.get(name);
if (node == null) {
if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
// 创建EntranceNode
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
// Add entrance node.
Constants.ROOT.addChild(node);
Map<String, DefaultNode> newMap = new HashMap<>(contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
}
} finally {
LOCK.unlock();
}
}
}
context = new Context(node, name);
context.setOrigin(origin);
contextHolder.set(context);
}
return context;
}
Node之间的树形结构
在创建context会先创建DefaultNode 实际是它的父类EntranceNode,context可以相同context-name反复申明创建,但是DefaultNode同一context-name只会创建一次,DefaultNode包含了一个链路所有的资源,每一个资源对应一个ClusterNode,ClusterNode再根据来源细分为StatisticNode,它们之间的关系就是一个树形结构 如下:
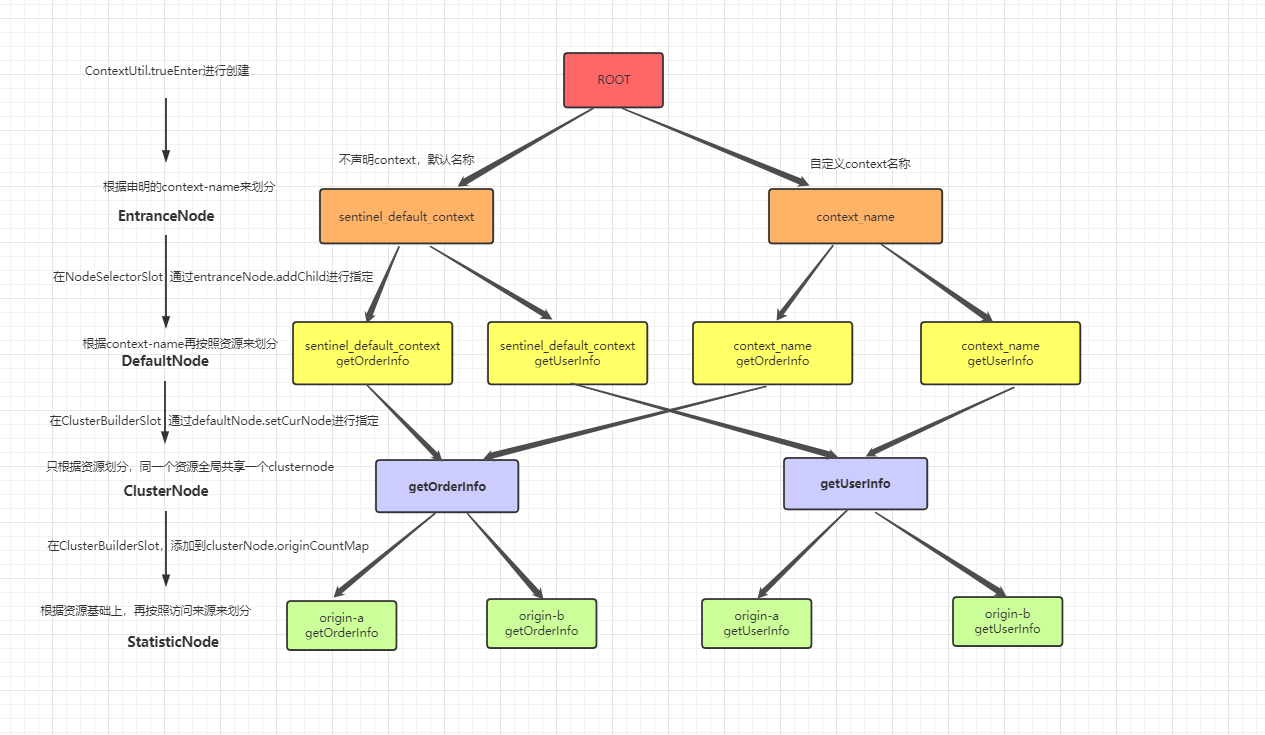
EntranceNode:根据context-name来创建,就算同一个context-name多次创建context,entranceNode也只会创建一次, 用来统计该链路上所有的资源信息
DefaultNode:根据context-name + resource-name创建,用来统计某链路上的资源信息
ClusterNode:根据resource-name来创建,用来统计资源信息
StatisticsNode:根据origin-name+resource-name来创建,针对请求来源统计该来源的资源信息,上面几个node都是它的子类,基于它的数据做汇总
读者一定要搞清楚这几个node之间的关系和作用,下面重点来看StatisticsNode,它用来完成信息统计 以供后续的限流规则使用, 它只统计了两个维度数据,qps和线程数
Node中滑动窗口实现
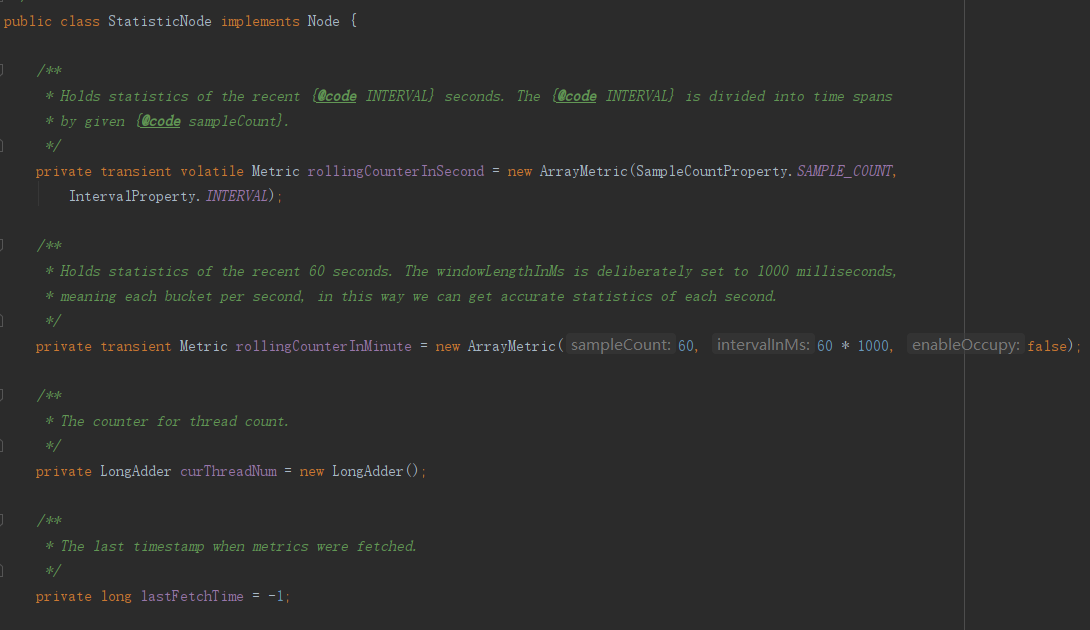
线程数统计很简单,通过LongAdder来完成,比较简单不过叙述,qps采用滑动窗口算法完成,但它跟普通的滑动窗口算法不太一样,它的数据结构是固定,可以重复利用 减少了内存消耗,可以看到默认创建了两个时间维度的窗口,分别以秒(细分为2个子窗口 500ms为间隔)和分钟(细分为60个子窗口 1s为间隔)

ArrayMetric 的内部是一个 LeapArray,分钟维度使用由子类 BucketLeapArray 实现,秒维度由OccpiableBucketLeapArray实现,我们先来看BucketLeapArray ,OccpiableBucketLeapArray会在后面具体使用到时候再进行额外讲解
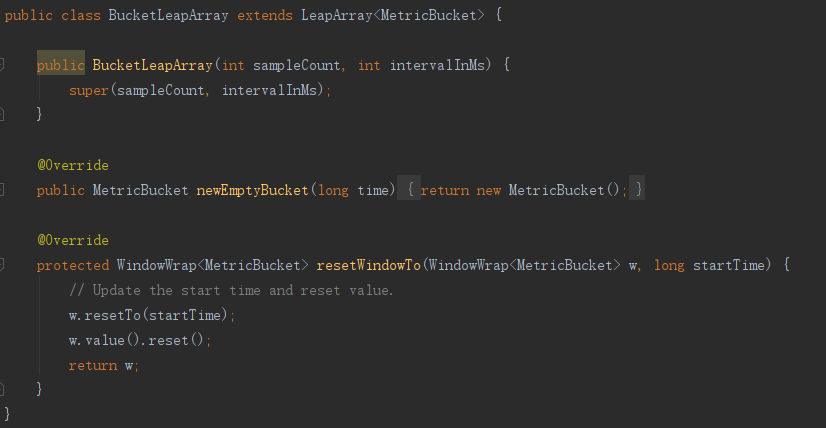
BucketLeapArray比较简单,内部就实现了LeapArray两个钩子方法,newEmptyBucket创建空桶, MetricBuket它窗口用来统计数据的类,里面是一个数组LongAdder 依次存放qps、rt等信息
resetWindoTo 重置窗口数据,再跟到LeapArray类中
public abstract class LeapArray<T> {
// 每个窗口长度(占用时间)
protected int windowLengthInMs;
// 滑动窗口的个数
protected int sampleCount;
// 全部窗口的总间隔时间 (毫秒)
protected int intervalInMs;
// 全部窗口的总间隔时间 (秒)
private double intervalInSecond;
// 存储窗口的数组,length = sampleCount
protected final AtomicReferenceArray<WindowWrap<T>> array;
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
// 根据时间计算索引
int idx = calculateTimeIdx(timeMillis);
// 根据时间计算窗口开始时间
long windowStart = calculateWindowStart(timeMillis);
/*
* 从array中获取窗口
*
* (1) array中不存在,创建一个窗口 并cas加入其中
* (2) array中窗口开始的时间=当前当前窗口开始时间,说明当前窗口刚不久已经创建过
* (3) array中窗口开始的时间<当前获取的时间,表示old窗口已过期,重置窗口数据并返回
*/
while (true) {
WindowWrap<T> old = array.get(idx);
if (old == null) {
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
if (array.compareAndSet(idx, null, window)) {
return window;
} else {
Thread.yield();
}
} else if (windowStart == old.windowStart()) {
return old;
} else if (windowStart > old.windowStart()) {
if (updateLock.tryLock()) {
try {
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
Thread.yield();
}
} else if (windowStart < old.windowStart()) {
// Should not go through here, as the provided time is already behind.
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}
// 获取窗口数据
public T getWindowValue(long timeMillis) {
if (timeMillis < 0) {
return null;
}
// 根据时间计算索引
int idx = calculateTimeIdx(timeMillis);
WindowWrap<T> bucket = array.get(idx);
if (bucket == null || !bucket.isTimeInWindow(timeMillis)) {
return null;
}
return bucket.value();
}
}
LeapArray主要两个方法,currentWindow(long timeMillis),根据当前时间获取当前窗口,getWindowValue(long timeMillis),根据当前时间获取当前窗口的值
这里跟一般的滑动窗口算法不太一样,一般的滑动窗口算法 窗口的大小不是固定 可以实时扩容,但这里它的大小在初始化就决定好了,当第一分钟中的60个窗口已经全部被创建,后续时间进来获取窗口会不断进行覆盖
sentinel规则调用链
我们再回到Sphu.entry()方法中来,里面还有个sentinel规则调用链的构建,针对当前资源的调度信息进行规则校验
ProcessorSlot<Object> chain = this.lookProcessChain(resourceWrapper);
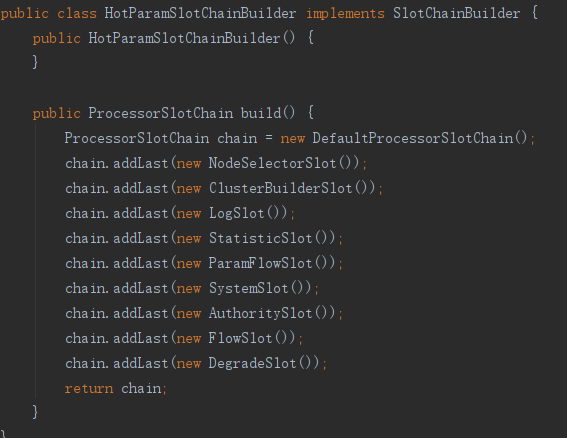
构建后会形成一个这样的调用链
NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
进入规则调用链,跟着顺序一个一个来看
chain.entry(context, resourceWrapper, null, count, prioritized, args)
NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
NodeSelectorSlot:用来创建DefaultNode,前面讲解node已经提到过
NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
ClusterBuilderSlot: 用来创建ClusterBuilderSlot
NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
LogSlot:发生BlockException异常,记录日志
NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
StatisticSlot:这个类就非常重要了,它用来进行数据统计,它先向后继续传递,等后续slot全部执行后再执行统计
public class StatisticSlot extends AbstractLinkedProcessorSlot<DefaultNode> {
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
try {
// 向后传递
fireEntry(context, resourceWrapper, node, count, prioritized, args);
// 对DefaultNode添加线程数和qps
node.increaseThreadNum();
node.addPassRequest(count);
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (PriorityWaitException ex) {
xxx
} catch (BlockException e) {
xxx
throw e;
} catch (Throwable e) {
context.getCurEntry().setError(e);
throw e;
}
}
}
NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
ParamFlowSlot:校验热点参数规则
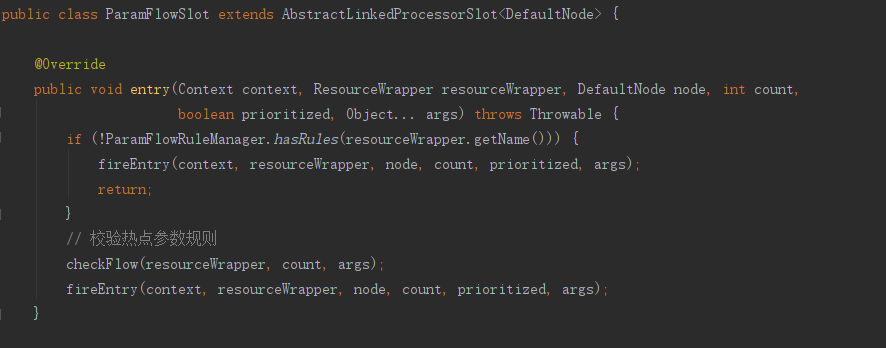
NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
SystemSlot:系统规则校验,只对入站流量做校验,汇总当前入站所有的资源信息然后进行校验


NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
AuthoritySlot:授权规则校验,对调用方进行白名单或黑名单限制

NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
FlowSlot:校验流控规则,具体有四种规则,由TrafficShapingController的实现类完成,里面实现比较复杂,在下一章节会进行详解
NodeSelectorSlot >>> ClusterBuilderSlot >>> LogSlot >>> StatisticSlot >>> ParamFlowSlot >>> SystemSlot >>> AuthoritySlot >>> FlowSlot >>> DegradeSlot
DegradeSlot:校验熔断降级规则,分别有三种策略:慢比例调用、异常比例、异常数,降级规则校验跟之前规则校验流程不太一样,它是直接对资源进行校验,内部通过CircuitBreaker(断路器)来实现,慢比例调用由ResponseTimeCircuitBreaker实现,
异常比例、异常数由ExceptionCircuitBreaker实现
public class DegradeSlot extends AbstractLinkedProcessorSlot<DefaultNode> {
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
performChecking(context, resourceWrapper);
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
void performChecking(Context context, ResourceWrapper r) throws BlockException {
List<CircuitBreaker> circuitBreakers = DegradeRuleManager.getCircuitBreakers(r.getName());
if (circuitBreakers == null || circuitBreakers.isEmpty()) {
return;
}
for (CircuitBreaker cb : circuitBreakers) {
// 尝试通过
if (!cb.tryPass(context)) {
throw new DegradeException(cb.getRule().getLimitApp(), cb.getRule());
}
}
}
}
断路器有三种状态,CLOSE:正常通行,HALF_OPEN:允许探测通行,OPEN:拒绝通行,这里解释下为啥会有HALF_OPEN状态出现,比如我们对同一个资源设置了两个降级规则 R1:熔断时间为100ms,R2:熔断时间为200ms,当R1已到恢复点 此时R2还未恢复,
R1状态会从OPEN变为HALF_OPEN,R1本次校验通过,由于R2还未恢复 R2校验不通过,本次资源请求依然是不通过的,但如果R1、R2都已恢复 正常通行,在entry.exit()会将状态设置为CLOSE后续请求正常通行,这就是HALF_OPEN出现的目的
/**************************************AbstractCircuitBreaker**************************************/
public boolean tryPass(Context context) {
// 正常通行
if (currentState.get() == State.CLOSED) {
return true;
}
// 尝试通行
if (currentState.get() == State.OPEN) {
// For half-open state we allow a request for probing.
return retryTimeoutArrived() && fromOpenToHalfOpen(context);
}
return false;
} protected boolean fromOpenToHalfOpen(Context context) {
// 尝试将状态从OPEN设置为HALF_OPEN
if (currentState.compareAndSet(State.OPEN, State.HALF_OPEN)) {
// 状态变化通知
notifyObservers(State.OPEN, State.HALF_OPEN, null);
Entry entry = context.getCurEntry();
// 在entry添加一个exitHandler entry.exit()时会调用
entry.whenTerminate(new BiConsumer<Context, Entry>() {
@Override
public void accept(Context context, Entry entry) {
// 如果有发生异常,重新将状态设置为OPEN 请求不同通过
if (entry.getBlockError() != null) {
currentState.compareAndSet(State.HALF_OPEN, State.OPEN);
notifyObservers(State.HALF_OPEN, State.OPEN, 1.0d);
}
}
});
// 此时状态已设置为HALF_OPEN正常通行
return true;
}
return false;
} /**************************************CtEntry**************************************/
private void callExitHandlersAndCleanUp(Context ctx) {
if (exitHandlers != null && !exitHandlers.isEmpty()) {
for (BiConsumer<Context, Entry> handler : this.exitHandlers) {
try {
handler.accept(ctx, this);
} catch (Exception e) {
RecordLog.warn("Error occurred when invoking entry exit handler, current entry: "
+ resourceWrapper.getName(), e);
}
}
exitHandlers = null;
}
}
上面只看到了状态从OPEN变为HALF_OPEN,HALF_OPEN变为OPEN,但没有看到状态如何从HALF_OPEN变为CLOSE的,它的变化过程是在正常执行完请求后,entry.exit()会调用DegradeSlot.exit()方法来改变状态
/**************************************DegradeSlot**************************************/
public void exit(Context context, ResourceWrapper r, int count, Object... args) {
Entry curEntry = context.getCurEntry();
if (curEntry.getBlockError() != null) {
fireExit(context, r, count, args);
return;
}
List<CircuitBreaker> circuitBreakers = DegradeRuleManager.getCircuitBreakers(r.getName());
if (circuitBreakers == null || circuitBreakers.isEmpty()) {
fireExit(context, r, count, args);
return;
} if (curEntry.getBlockError() == null) {
// passed request
for (CircuitBreaker circuitBreaker : circuitBreakers) {
circuitBreaker.onRequestComplete(context);
}
} fireExit(context, r, count, args);
} /**************************************ExceptionCircuitBreaker**************************************/
public void onRequestComplete(Context context) {
Entry entry = context.getCurEntry();
if (entry == null) {
return;
}
Throwable error = entry.getError();
SimpleErrorCounter counter = stat.currentWindow().value();
if (error != null) {
// 发生异常 添加异常数
counter.getErrorCount().add(1);
}
counter.getTotalCount().add(1); handleStateChangeWhenThresholdExceeded(error);
} private void handleStateChangeWhenThresholdExceeded(Throwable error) {
if (currentState.get() == State.OPEN) {
return;
} if (currentState.get() == State.HALF_OPEN) {
// In detecting request
if (error == null) {
// 未发生异常 HALF_OPEN >>> CLOSE
fromHalfOpenToClose();
} else {
// 发生异常 HALF_OPEN >>> OPEN
fromHalfOpenToOpen(1.0d);
}
return;
}
// 代表此时状态为CLOSE
List<SimpleErrorCounter> counters = stat.values();
long errCount = 0;
long totalCount = 0;
for (SimpleErrorCounter counter : counters) {
errCount += counter.errorCount.sum();
totalCount += counter.totalCount.sum();
}
if (totalCount < minRequestAmount) {
return;
}
// 当前异常数
double curCount = errCount;
if (strategy == DEGRADE_GRADE_EXCEPTION_RATIO) {
// 算出当前的异常比例
curCount = errCount * 1.0d / totalCount;
}
// 判断当前异常数或异常比例是否达到设定的阀值
if (curCount > threshold) {
// 超出设定 将状态设置为OPEN
transformToOpen(curCount);
}
}
到此整个规则调用的流程我们都大致过了一遍,除了FlowSlot和DegradeSlot比较复杂,其它的规则校验源码都不算难,读者自行了解
sentinel流量控制和熔断降级执行流程之源码分析的更多相关文章
- storm启动过程之源码分析
TopologyMaster: 处理拓扑的一些基本信息和工作,比如更新心跳信息,拓扑指标信息更新等 NimbusServer: ** * * NimbusServer work flow: 1. ...
- 4.Sentinel源码分析— Sentinel是如何做到降级的?
各位中秋节快乐啊,我觉得在这个月圆之夜有必要写一篇源码解析,以表示我内心的高兴~ Sentinel源码解析系列: 1.Sentinel源码分析-FlowRuleManager加载规则做了什么? 2. ...
- 3. Sentinel源码分析— QPS流量控制是如何实现的?
Sentinel源码解析系列: 1.Sentinel源码分析-FlowRuleManager加载规则做了什么? 2. Sentinel源码分析-Sentinel是如何进行流量统计的? 上回我们用基于并 ...
- 探索drf执行流程之APIView源码分析
Django REST framework 简介 现在新一代web应用都开始采用前后端分离的方式来进行,淘汰了以前的服务器端渲染的方式.而实现前后端分离是通过Django REST framework ...
- SpringCloudAlibaba分布式流量控制组件Sentinel实战与源码分析(上)
概述 定义 Sentinel官网地址 https://sentinelguard.io/zh-cn/index.html 最新版本v1.8.4 Sentinel官网文档地址 https://senti ...
- 2. Sentinel源码分析—Sentinel是如何进行流量统计的?
这一篇我还是继续上一篇没有讲完的内容,先上一个例子: private static final int threadCount = 100; public static void main(Strin ...
- 5.Sentinel源码分析—Sentinel如何实现自适应限流?
Sentinel源码解析系列: 1.Sentinel源码分析-FlowRuleManager加载规则做了什么? 2. Sentinel源码分析-Sentinel是如何进行流量统计的? 3. Senti ...
- 6.Sentinel源码分析—Sentinel是如何动态加载配置限流的?
Sentinel源码解析系列: 1.Sentinel源码分析-FlowRuleManager加载规则做了什么? 2. Sentinel源码分析-Sentinel是如何进行流量统计的? 3. Senti ...
- 7.Sentinel源码分析—Sentinel是怎么和控制台通信的?
这里会介绍: Sentinel会使用多线程的方式实现一个类Reactor的IO模型 Sentinel会使用心跳检测来观察控制台是否正常 Sentinel源码解析系列: 1.Sentinel源码分析-F ...
随机推荐
- 2021升级版微服务教程4—Nacos 服务注册和发现
2021升级版SpringCloud教程从入门到实战精通「H版&alibaba&链路追踪&日志&事务&锁」 默认文件1610014380163 教程全目录「含视 ...
- zabbix v3.0安装部署【转】
关于zabbix及相关服务软件版本: Linux:oracle linux 6.5 nginx:1.9.15 MySQL:5.5.49 PHP:5.5.35 一.安装nginx: 安装依赖包: yum ...
- node.js中使用http-proxy-middleware请求转发给其它服务器
var express = require('express');var proxy = require('http-proxy-middleware'); var app = express(); ...
- 【MyBatis】MyBatis 多表操作
MyBatis 多表操作 文章源码 一对一查询 需求:查询所有账户信息,关联查询下单用户信息. 注意:因为一个账户信息只能供某个用户使用,所以从查询账户信息出发关联查询用户信息为一对一查询.如果从用户 ...
- LeetCode117 每个节点的右向指针 II
给定一个二叉树 struct TreeLinkNode { TreeLinkNode *left; TreeLinkNode *right; TreeLinkNode *next; } 填充它的每个 ...
- 两万字长文总结,梳理 Java 入门进阶那些事
大家好,我是程序员小跃,一名在职场已经写了6年程序的老程序员,从一开始的菊厂 Android 开发到现在某游戏公司的Java后端架构,对Java还是相对了解的挺多. 大概是半年前吧,在知乎上有个知友私 ...
- webpack知识点整理
作用域 es6里模块化的写法 会存在的问题,变量.方法名字雷同,外部文件调用的时候出现问题 如 a.js里 var a='susan' b.js里 var a='jack' 问题解决方案,添加包裹 a ...
- CWE 4.3:强化你的数据自我保护能力
摘要:如何通过软件自动的检查法规中涉及的数据保护, 新版的CWE 4.3 给出了一个解决途径. 1. 按照惯例,先说故事 用12月初在深圳参加的"全球C++及系统软件技术大会"里C ...
- postgresql-12编译安装
1 准备环境 修改yum源 mkdir -p /etc/yum.bak mv /etc/yum.repos.d/* /etc/yum.bak/ &&\ curl -o /etc/yum ...
- python7、8章
目录 第七章 用户输入和while循环 7.1 函数input()的工作原理 7.1.1 编写清晰的程序 7.1.2 使用int()来获取数值输入 分析: 结果: 7.1.3 求模运算符 7.1.4 ...