题解 CF504E 【Misha and LCP on Tree】
PullShit
倍增和树剖的差距!!!
一个 TLE, 一个 luogu 最优解第三!!!
放个对比图(上面倍增,下面轻重链剖分):
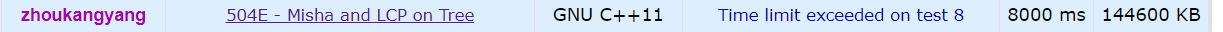

不过这是两只 log 非正解。。。
Solution
\(LCP\), 自然地想到后缀字符串算法和哈希。后缀自动机好像搞不了,用哈希。
正解是把路径拆分成链,不过这里给出一个更自然的 二分 + 哈希。
显然地,我们可以通过统计从根节点到节点 \(i\) 的哈希值 \(f_i\) 和从节点 \(i\) 到根节点 \(g_i\) 来统计路径上的问题。
然后在二分的过程中,判定一个长度 \(k\) 能否成为两个字符串的公共前缀,可以考虑算出 \(k\) 在两个字符串中的哈希值。
这个分为两类讨论,是讨论 \(k\) 是否大于 \(dep_{lca(u, v)} - dep_{u}\)。这个式子比较简单,请读者自己去推。
Code
用倍增的时候卡常的疯狂导致代码丑陋不堪。
#include<bits/stdc++.h>
#define L(i, j, k) for(int i = j, i##E = k; i <= i##E; i++)
#define R(i, j, k) for(int i = j, i##E = k; i >= i##E; i--)
#define ll long long
#define ull unsigned long long
#define db double
#define pii pair<int, int>
#define mkp make_pair
using namespace std;
char buf[1<<26], *p1=buf, *p2=buf, obuf[1<<25], *O=obuf;
#define getchar() (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<26,stdin),p1==p2)?EOF:*p1++)
inline int read() {
int x=0,f=1;char ch=getchar();
while(!isdigit(ch)){if(ch=='-') f=-1;ch=getchar();}
while(isdigit(ch)) x=x*10+(ch^48),ch=getchar();
return x*f;
}
void print(int x) {
if(x>9) print(x/10);
*O++=x%10+'0';
}
const int N = 3e5 + 7;
const int mod = 998244353;
const int G = 917120411;
int Getny(int x) {
int res = 1, y = mod - 2;
for(; y; x = 1ll * x * x % mod, y >>= 1) if(y & 1) res = 1ll * res * x % mod;
return res;
}
int qpow[N], npow[N];
void init(int x) {
qpow[0] = npow[0] = 1;
int iG = Getny(G);
L(i, 1, x) qpow[i] = 1ll * qpow[i - 1] * G % mod, npow[i] = 1ll * npow[i - 1] * iG % mod;
}
int MOD(int x) { if(x >= mod) x -= mod; return x; }
void Mod(int &x) { if(x >= mod) x -= mod; }
void ad(int &x, int y) { x += y; if(x >= mod) x -= mod; }
int n, m, maxto[N], fa[N], id[N], dy[N], heavy[N], siz[N], idtot, dep[N];
int f[N], g[N];
char s[N];
int head[N], edge_id;
struct node {
int to, next;
} e[N << 1];
void add_edge(int u, int v) {
++edge_id, e[edge_id].next = head[u], e[edge_id].to = v, head[u] = edge_id;
}
void dfs1(int x) {
siz[x] = 1;
f[x] = MOD(f[fa[x]] + 1ll * (s[x] - 'a' + 1) * qpow[dep[x]] % mod), g[x] = MOD(1ll * g[fa[x]] * G % mod + s[x] - 'a' + 1);
for(int i = head[x]; i; i = e[i].next) {
int v = e[i].to;
if(v == fa[x]) continue;
fa[v] = x;
dep[v] = dep[x] + 1, dfs1(v), siz[x] += siz[v];
if(siz[v] > siz[heavy[x]]) heavy[x] = v;
}
}
void dfs2(int x) {
id[x] = ++idtot, dy[idtot] = x;
if(siz[x] != 1) {
maxto[heavy[x]] = maxto[x];
dfs2(heavy[x]);
}
for(int i = head[x]; i; i = e[i].next) {
int v = e[i].to;
if(v == fa[x] || v == heavy[x]) continue;
maxto[v] = v, dfs2(v);
}
}
int up(int x, int k) {
int todep = dep[x] - k;
while(dep[maxto[x]] > todep) x = fa[maxto[x]];
return dy[id[x] - dep[x] + todep];
}
int lca(int u, int v) {
while(maxto[u] != maxto[v]) {
if(dep[maxto[u]] < dep[maxto[v]]) swap(u, v);
u = fa[maxto[u]];
}
if(dep[u] < dep[v]) swap(u, v);
return v;
}
int u1, v1, lca1, flca1, len1, flen1, P1;
int g1;
int get1(int k) {
if(k < flen1) return MOD(g[u1] + mod - 1ll * g[up(u1, k)] * qpow[k] % mod);
else if(P1 >= 0) return MOD(g1 + 1ll * f[up(v1, len1 - k)] * qpow[P1] % mod);
else return MOD(g1 + 1ll * f[up(v1, len1 - k)] * npow[-P1] % mod);
}
int u2, v2, lca2, flca2, len2, flen2, P2;
int g2;
int get2(int k) {
if(k < flen2) return MOD(g[u2] + mod - 1ll * g[up(u2, k)] * qpow[k] % mod);
else if(P2 >= 0) return MOD(g2 + 1ll * f[up(v2, len2 - k)] * qpow[P2] % mod);
else return MOD(g2 + 1ll * f[up(v2, len2 - k)] * npow[-P2] % mod);
}
int main() {
n = read();
L(i, 1, n) {
char ch = getchar();
while('a' > ch && ch > 'z') ch = getchar();
s[i] = ch;
}
init(n);
L(i, 1, n - 1) {
int u = read(), v = read();
add_edge(u, v), add_edge(v, u);
}
f[0] = 0, dep[0] = -1;
dfs1(1), dfs2(1);
int m = read();
while(m--) {
u1 = read(), v1 = read(), u2 = read(), v2 = read();
lca1 = lca(u1, v1), lca2 = lca(u2, v2);
len1 = dep[u1] + dep[v1] - dep[lca1] * 2 + 1, flen1 = dep[u1] - dep[lca1] + 1, P1 = flen1 - dep[lca1] - 1;
len2 = dep[u2] + dep[v2] - dep[lca2] * 2 + 1, flen2 = dep[u2] - dep[lca2] + 1, P2 = flen2 - dep[lca2] - 1;
g1 = MOD(g[u1] + mod - 1ll * g[fa[lca1]] * qpow[flen1] % mod);
if(P1 >= 0) g1 = MOD(g1 + mod - 1ll * f[lca1] * qpow[P1] % mod);
else g1 = MOD(g1 + mod - 1ll * f[lca1] * npow[-P1] % mod);
g2 = MOD(g[u2] + mod - 1ll * g[fa[lca2]] * qpow[flen2] % mod);
if(P2 >= 0) g2 = MOD(g2 + mod - 1ll * f[lca2] * qpow[P2] % mod);
else g2 = MOD(g2 + mod - 1ll * f[lca2] * npow[-P2] % mod);
int L = 1, R = min(len1, len2), ans = 0;
while(L <= R) {
int mid = (L + R) / 2;
if(get1(mid) == get2(mid)) ans = mid, L = mid + 1;
else R = mid - 1;
}
print(ans), *O++ = '\n';
}
fwrite(obuf,O-obuf,1,stdout);
return 0;
}
题解 CF504E 【Misha and LCP on Tree】的更多相关文章
- CF504E Misha and LCP on Tree 后缀自动机+树链剖分+倍增
求树上两条路径的 LCP (树上每个节点代表一个字符) 总共写+调了6个多小时,终于过了~ 绝对是我写过的最复杂的数据结构了 我们对这棵树进行轻重链剖分,然后把所有的重链分正串,反串插入到广义后缀自动 ...
- CF504E Misha and LCP on Tree(树链剖分+后缀树组)
1A真舒服. 喜闻乐见的树链剖分+SA. 一个初步的想法就是用树链剖分,把两个字符串求出然后hash+二分求lcp...不存在的. 因为考虑到这个字符串是有序的,我们需要把每一条重链对应的字符串和这个 ...
- 树链剖分 + 后缀数组 - E. Misha and LCP on Tree
E. Misha and LCP on Tree Problem's Link Mean: 给出一棵树,每个结点上有一个字母.每个询问给出两个路径,问这两个路径的串的最长公共前缀. analyse: ...
- CF 504E Misha and LCP on Tree——后缀数组+树链剖分
题目:http://codeforces.com/contest/504/problem/E 树链剖分,把重链都接起来,且把每条重链的另一种方向的也都接上,在这个 2*n 的序列上跑后缀数组. 对于询 ...
- CF 504 E —— Misha and LCP on Tree —— 树剖+后缀数组
题目:http://codeforces.com/contest/504/problem/E 快速查询LCP,可以用后缀数组,但树上的字符串不是一个序列: 所以考虑转化成序列—— dfs 序! 普通的 ...
- CF 504E Misha and LCP on Tree(树链剖分+后缀数组)
题目链接:http://codeforces.com/problemset/problem/504/E 题意:给出一棵树,每个结点上有一个字母.每个询问给出两个路径,问这两个路径的串的最长公共前缀. ...
- [LeetCode]题解(python):145-Binary Tree Postorder Traversal
题目来源: https://leetcode.com/problems/binary-tree-postorder-traversal/ 题意分析: 后序遍历一棵树,递归的方法很简单,尝试用非递归的方 ...
- [LeetCode]题解(python):144-Binary Tree Preorder Traversal
题目来源: https://leetcode.com/problems/binary-tree-preorder-traversal/ 题意分析: 前序遍历一棵树,递归的方法很简单.那么非递归的方法呢 ...
- [LeetCode]题解(python):124-Binary Tree Maximum Path Sum
题目来源: https://leetcode.com/problems/binary-tree-maximum-path-sum/ 题意分析: 给定一棵树,找出一个数值最大的路径,起点可以是任意节点或 ...
随机推荐
- linux kernel 的 procfs sysfs 对查问题的帮助
遇到进程卡死,没有gdb 符号表:只能strace 跟踪处理分析 排查过程: 1.ps -aux 查看卡死进程pid 2.strace -T -tt -e trace=all -p 查看卡死进程系统调 ...
- nagle 算法 tcp nodelay 以及 quick ack分析
后面详细分析 先上传 之前总结查看源码后的总结 Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段.所谓"小段",指的是小于MSS尺寸的数据块,所谓"未被确 ...
- redis乐观锁
乐观锁(又名乐观并发控制,Optimistic Concurrency Control,缩写"OCC"),是一种并发控制的方法.它假设多用户并发的事务在处理时不会彼此互相影响,各事 ...
- 03、MyBatis 映射文件
1.XML映射器 2.select Select元素来定义查询操作 Id:唯一标识符 - 用来引用这条语句,需要和接口的方法名一致 parameterType:参数类型 - 可以不传,MyBatis会 ...
- [C/C++] 结构体内存对齐:alignas alignof pack
简述: alignas(x):指定结构体内某个成员的对齐字节数,指定的对齐字节数不能小于它原本的字节数,且为2^n; #pragma pack(x):指定结构体的对齐方式,只能缩小结构体的对齐数,且为 ...
- msfconsle核心命令学习
back 取消当前模块 banner check 检查当前exploit是否对目标有效,并不进行真正的攻击 color 禁用或启用输出是否包含颜色 connect 可以通过connect命令来链接Ne ...
- NO.A.0002——Git简史及安装教程/创建本地仓库/提交项目到本地仓库/误删还原
一.Git简史及同类产品对比: 1.git简史: 同生活中的许多伟大事件一样,Git 诞生于一个极富纷争大举创新的年代.Linux 内核开源项目有着为数众广的参与者.绝大多数的 Linu ...
- 云服务器-Ubuntu更新系统版本-更新Linux内核-服务器安全配置优化-防反弹shell
购入了一台阿里云的ESC服务器,以前都用CentOS感觉Yum不怎么方便,这次选的Ubuntu16.04.7 搭好服务之后做安全检查,发现Ubuntu16.04版本漏洞众多:虽然也没有涉及到16.04 ...
- 二叉堆python实现
二叉堆是一种完全二叉树,我们可以使用列表来方便存储,也就是说,用列表将树的所有节点存储起来. 如下图,是小根堆方式的二叉堆,假设父节点的下标为p,则他的左孩子下标为2P+1,右孩子下标为2P+2 cl ...
- css3系列之@font-face
@font-face 这个属性呢,必须设置在 css的根下,也就是说,不能设置在任何元素里面. @font-face: 参数: font-family: 给这个文字库 起个名字. src: url( ...