二分类问题中混淆矩阵、PR以及AP评估指标
仿照上篇博文对于混淆矩阵、ROC和AUC指标的探讨,本文简要讨论机器学习二分类问题中的混淆矩阵、PR以及AP评估指标;实际上,(ROC,AUC)与(PR,AP)指标对具有某种相似性。
按照循序渐进的原则,依次讨论混淆矩阵、PR和AP:
设定一个机器学习问题情境:给定一些肿瘤患者样本,构建一个分类模型来预测肿瘤是良性还是恶性,显然这是一个二分类问题。
本文中,将良性肿瘤视为正类标签(可能在具体实践中更为关注恶性肿瘤,不过这并不影响技术上的操作)。
当分类模型选定以后,将其在测试数据集上进行评估,分别可以得到以下评估指标:
混淆矩阵
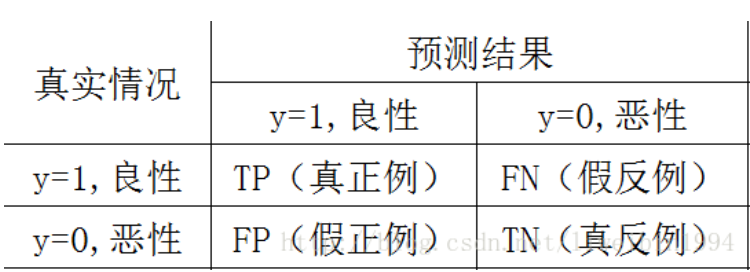
TP表示预测为良性,真实情况是良性的样例数;
FN表示预测为恶性,真实情况是良性的样例数;
FP表示预测为良性,真实情况是恶性的样例数;
TN表示预测为恶性,真实情况是恶性的样例数;
以上四类数据构成混淆矩阵。
PR
在混淆矩阵的基础上,进一步地定义两个指标。
按照下式定义precision(P)指标
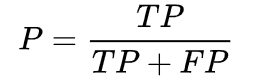
precision表示,预测为正的样本中有多少是真正的正样本;精准率强调对某类样本识别的准确性。
按照下式定义recall(R)指标
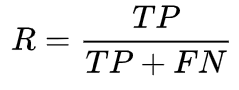
recall表示,样本中的正例有多少被预测正确了;召回率强调对某类样本识别的全面性。
precision,recall分别反映分类器对某一类样本鉴别能力的两个方面;通常,这两个指标呈现互斥关系,即一个指标高了往往会致使另一指标降低。
由上,一个混淆矩阵对应一对(precision,recall)
需要明确的是,P和R是建立在类别明确的预测结果之上的,即分类模型明确地指出待预测样本的类别。
然而,在二分类问题(0,1)中,一般模型最后的输出是一个概率值,表示结果是1的概率。此时需要确定一个阈值,若模型的输出概率超过阈值,则归类为1;若模型的输出概率低于阈值,则归类为0。
不同的阈值会导致分类的结果不同,也就是混淆矩阵有差,P和R也就不同。
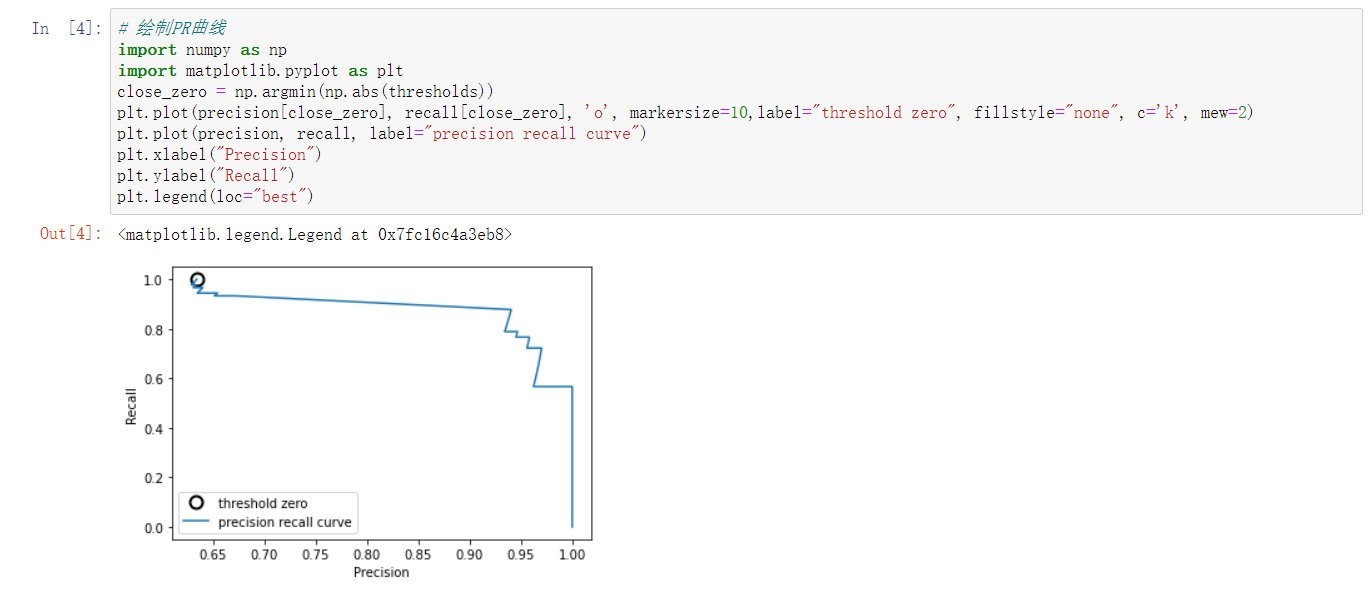
当阈值从0开始慢慢移动到1的过程,就会形成很多对(precision,recall)的值,将它们画在坐标系上,就是所谓的PR曲线了。
AP
得到PR曲线后,就可以计算曲线下方的面积,计算出来的面积就是AP值。
一般而言,AP越大,模型的性能越好。
示例
二分类问题中混淆矩阵、PR以及AP评估指标的更多相关文章
- E. Arson In Berland Forest(思维,找二维阵列中的矩阵,二分)
题:https://codeforces.com/contest/1262/problem/E 分析:预处理出阵列中的矩阵,然后二分答案还原题目的烧火过程,判断是否满足要求 #include<b ...
- 二分类算法的评价指标:准确率、精准率、召回率、混淆矩阵、AUC
评价指标是针对同样的数据,输入不同的算法,或者输入相同的算法但参数不同而给出这个算法或者参数好坏的定量指标. 以下为了方便讲解,都以二分类问题为前提进行介绍,其实多分类问题下这些概念都可以得到推广. ...
- 【分类问题中模型的性能度量(二)】超强整理,超详细解析,一文彻底搞懂ROC、AUC
文章目录 1.背景 2.ROC曲线 2.1 ROC名称溯源(选看) 2.2 ROC曲线的绘制 3.AUC(Area Under ROC Curve) 3.1 AUC来历 3.2 AUC几何意义 3.3 ...
- [机器学习]-分类问题常用评价指标、混淆矩阵及ROC曲线绘制方法
分类问题 分类问题是人工智能领域中最常见的一类问题之一,掌握合适的评价指标,对模型进行恰当的评价,是至关重要的. 同样地,分割问题是像素级别的分类,除了mAcc.mIoU之外,也可以采用分类问题的一些 ...
- 【分类问题中模型的性能度量(一)】错误率、精度、查准率、查全率、F1详细讲解
文章目录 1.错误率与精度 2.查准率.查全率与F1 2.1 查准率.查全率 2.2 P-R曲线(P.R到F1的思维过渡) 2.3 F1度量 2.4 扩展 性能度量是用来衡量模型泛化能力的评价标准,错 ...
- 混淆矩阵(Confusion matrix)的原理及使用(scikit-learn 和 tensorflow)
原理 在机器学习中, 混淆矩阵是一个误差矩阵, 常用来可视化地评估监督学习算法的性能. 混淆矩阵大小为 (n_classes, n_classes) 的方阵, 其中 n_classes 表示类的数量. ...
- scikit-learn机器学习(二)逻辑回归进行二分类(垃圾邮件分类),二分类性能指标,画ROC曲线,计算acc,recall,presicion,f1
数据来自UCI机器学习仓库中的垃圾信息数据集 数据可从http://archive.ics.uci.edu/ml/datasets/sms+spam+collection下载 转成csv载入数据 im ...
- 基于Keras的imdb数据集电影评论情感二分类
IMDB数据集下载速度慢,可以在我的repo库中找到下载,下载后放到~/.keras/datasets/目录下,即可正常运行.)中找到下载,下载后放到~/.keras/datasets/目录下,即可正 ...
- 【sklearn】性能度量指标之ROC曲线(二分类)
原创博文,转载请注明出处! 1.ROC曲线介绍 ROC曲线适用场景 二分类任务中,positive和negtive同样重要时,适合用ROC曲线评价 ROC曲线的意义 TPR的增长是以FPR的增长为代价 ...
随机推荐
- HTTP协议相关知识整理:
http协议简介 超文本传输协议:是一种用于分布式.协作式和超媒体信息系统的应用层协议. 一次请求一次响应之后断开连接(无状态,短连接) 分析http请求信息格式 http工作原理 以下是 HTTP ...
- MATLAB中load和imread的读取方式区别
load是导入文件,一般从mat文件中,读取的是结构体imread是图像处理工具箱的库函数,处理图像比较方便,读取的是矩阵 1.之前将数组或者矩阵保存为一个mat格式的文件,在进行load命令读取时: ...
- JavaScript中的Object类型!
3.4.8 Object 类型 ECMAScript 中的对象其实就是一组数据和功能的集合.对象通过 new 操作符后跟对象类型的名称来创建.开发者可以通过创建 Object 类型的实例来创建自己的对 ...
- 在原生开发中控制HTML5视频!
在原生开发中控制HTML5视频! PC端 视频如何自动播放! 在video标签中添加 autoplay + muted(静音属性!) 温馨提醒: video是一个块级元素! 但是唯一的缺陷就是视频没有 ...
- windows2012-2016亲测安装mysql8.0
先去官网下载点击的MySQL的下载 下载完成后解压 解压完是这个样子 不要手动创建Data文件夹和my.ini文件, cmd命令窗口进入bin目录,如果已经做了环境变量那随意在哪里打开. mysqld ...
- Frame of Reference and Roaring Bitmaps
https://www.elastic.co/cn/blog/frame-of-reference-and-roaring-bitmaps http://roaringbitmap.org/ 2015 ...
- trust an HTTPS connection 安全协议 随机数 运输层安全协议 应用层安全协议 安全证书
小结: 1.HTTPS存在不同于HTTP的默认端口及一个加密/身份验证层(在HTTP与TCP之间) HTTPS(全称:Hyper Text Transfer Protocol over Secure ...
- 【LinuxShell】命令行常用快捷键
Ctrl + A :光标跳到一行命令的开头.一般来说,Home 键有相同的效果: Ctrl + E :光标跳到一行命令的结尾.一般来说,End 键有相同的效果:. Ctrl + U :删除所有在光标左 ...
- 六:SpringBoot-集成Druid连接池,配置监控界面
SpringBoot-集成Druid连接池,配置监控界面 1.Druid连接池 1.1 Druid特点 2.SpringBoot整合Druid 2.1 引入核心依赖 2.2 数据源配置文件 2.3 核 ...
- Docker 之 Jenkins自动化部署
Docker 之 Jenkins自动化部署 Jenkins部署 jenkis 绑定gitlab shell脚本自动化构建Docker镜像 提升maven构建速度 jenkins 无法通过shell脚本 ...