最通俗易懂的 Redis 架构模式详解

前言
话说有一名意大利程序员,在 2004 年到 2006 年间主要做嵌入式工作,之后接触了 Web,2007 年和朋友共同创建了一个网站,并为了解决这个网站的负载问题(为了避免 MySQL 的低性能),于是亲自定做一个数据库,并于 2009 年开发完成,这个就是 Redis。这个意大利程序员就是 Salvatore Sanfilippo 江湖人称 Redis 之父,大家更习惯称呼他 Antirez。

Redis 技术越来越火爆,其超高的性能,简洁轻量的设计,易上手,分布式架构的支持,在缓存等领域出色的表现造就了它现在的地位。
官方的 Benchmark 数据:测试完成了 50 个并发执行 10W 个请求。设置和获取的值是一个 256 字节字符串。
结果:读的速度是 110000次/s,写的速度是 81000次/s。
为了满足开发市场需求,Redis 支持单机、主从、哨兵、集群多种架构模式,本文带大家详细讲解这几种架构模式的区别。
单机模式
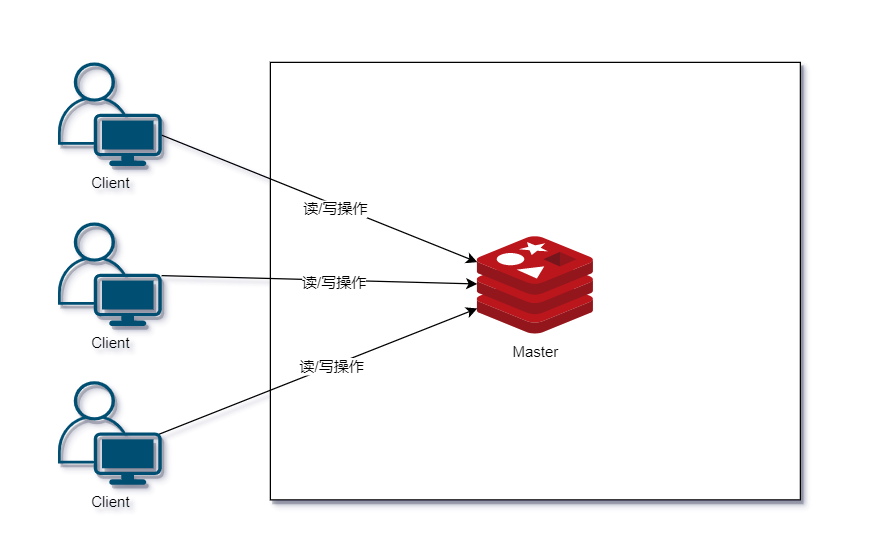
单机模式顾名思义就是安装一个 Redis,启动起来,业务调用即可。例如一些简单的应用,并非必须保证高可用的情况下可以使用该模式。
优点
- 部署简单;
- 成本低,无备用节点;
- 高性能,单机不需要同步数据,数据天然一致性。
缺点
- 可靠性保证不是很好,单节点有宕机的风险。
- 单机高性能受限于 CPU 的处理能力,Redis 是单线程的。
单机 Redis 能够承载的 QPS(每秒查询速率)大概在几万左右。取决于业务操作的复杂性,Lua 脚本复杂性就极高。假如是简单的 key value 查询那性能就会很高。
假设上千万、上亿用户同时访问 Redis,QPS 达到 10 万+。这些请求过来,单机 Redis 直接就挂了。系统的瓶颈就出现在 Redis 单机问题上,此时我们可以通过主从复制解决该问题,实现系统的高并发。
主从复制
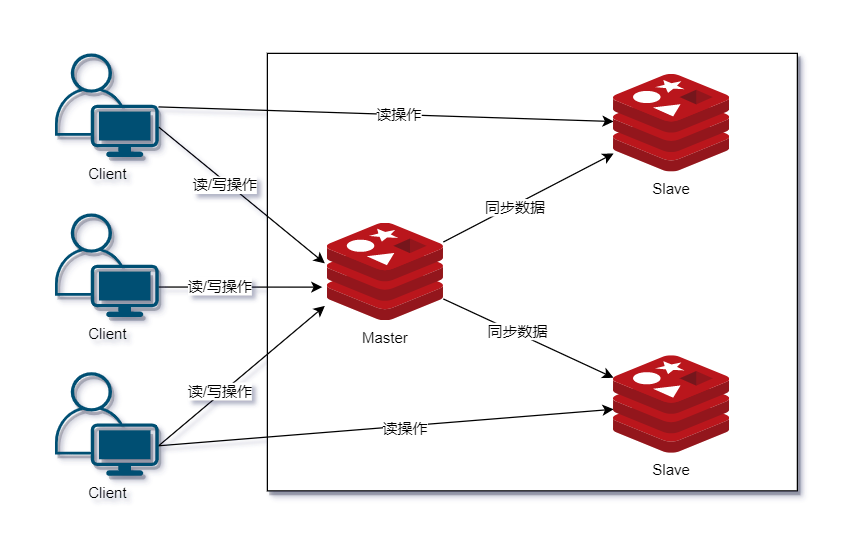
Redis 的复制(Replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(Master),而通过复制创建出来的复制品则为从服务器(Slave)。 只要主从服务器之间的网络连接正常,主服务器就会将写入自己的数据同步更新给从服务器,从而保证主从服务器的数据相同。
数据的复制是单向的,只能由主节点到从节点,简单理解就是从节点只支持读操作,不允许写操作。主要是读高并发的场景下用主从架构。主从模式需要考虑的问题是:当 Master 节点宕机,需要选举产生一个新的 Master 节点,从而保证服务的高可用性。
优点
- Master/Slave 角色方便水平扩展,QPS 增加,增加 Slave 即可;
- 降低 Master 读压力,转交给 Slave 节点;
- 主节点宕机,从节点作为主节点的备份可以随时顶上继续提供服务;
缺点
- 可靠性保证不是很好,主节点故障便无法提供写入服务;
- 没有解决主节点写的压力;
- 数据冗余(为了高并发、高可用和高性能,一般是允许有冗余存在的);
- 一旦主节点宕机,从节点晋升成主节点,需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预;
- 主节点的写能力受到单机的限制;
- 主节点的存储能力受到单机的限制。
哨兵模式
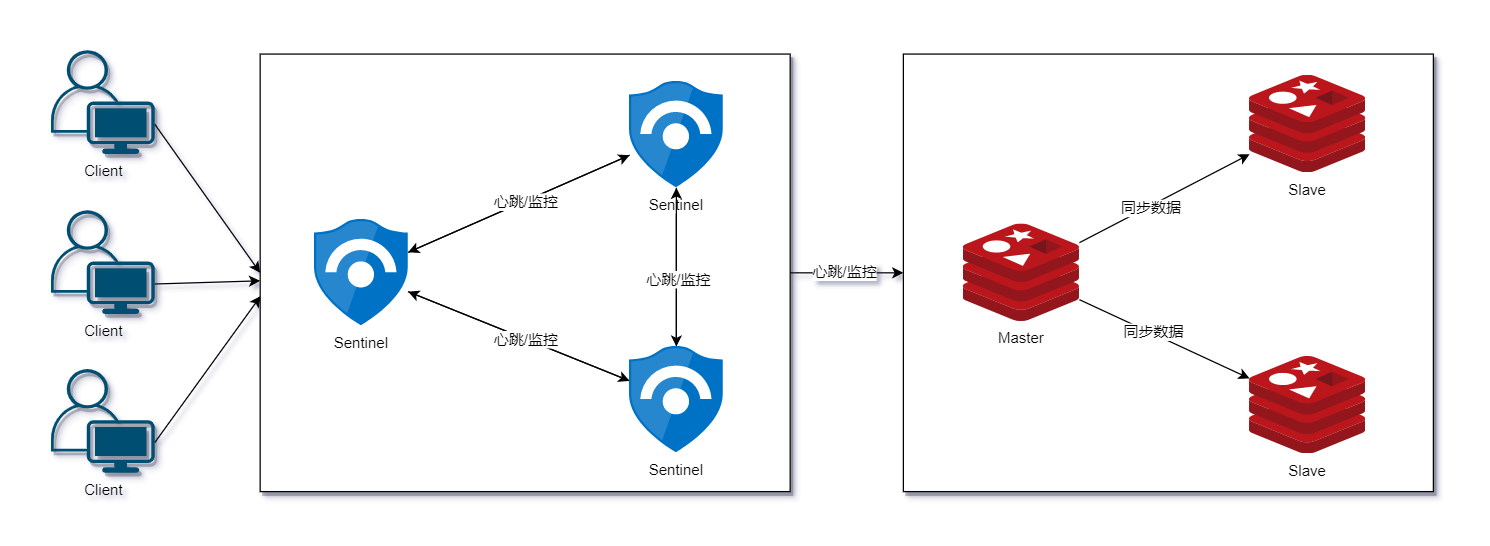
主从模式中,当主节点宕机之后,从节点是可以作为主节点顶上来继续提供服务,但是需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预。
于是,在 Redis 2.8 版本开始,引入了哨兵(Sentinel)这个概念,在主从复制的基础上,哨兵实现了自动化故障恢复。如上图所示,哨兵模式由两部分组成,哨兵节点和数据节点:
- 哨兵节点:哨兵节点是特殊的 Redis 节点,不存储数据;
- 数据节点:主节点和从节点都是数据节点。
Redis Sentinel 是分布式系统中监控 Redis 主从服务器,并提供主服务器下线时自动故障转移功能的模式。其中三个特性为:
- 监控(Monitoring):Sentinel 会不断地检查你的主服务器和从服务器是否运作正常;
- 提醒(Notification):当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知;
- 自动故障迁移(Automatic failover):当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
接下来我们了解一些 Sentinel 中的关键名词,然后系统讲解下哨兵模式的工作原理。
定时任务
Sentinel 内部有 3 个定时任务,分别是:
- 每 1 秒每个 Sentinel 对其他 Sentinel 和 Redis 节点执行
PING操作(监控),这是一个心跳检测,是失败判定的依据。 - 每 2 秒每个 Sentinel 通过 Master 节点的 channel 交换信息(Publish/Subscribe);
- 每 10 秒每个 Sentinel 会对 Master 和 Slave 执行
INFO命令,这个任务主要达到两个目的:- 发现 Slave 节点;
- 确认主从关系。
主观下线
所谓主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断,即单个 Sentinel 认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。
主观下线就是说如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返回一个错误, 那么 Sentinel 会将这个服务器标记为主观下线(SDOWN)。
客观下线
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断,并且通过命令互相交流之后,得出的服务器下线判断,然后开启 failover。
只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线(ODOWN)。只有当 Master 被认定为客观下线时,才会发生故障迁移。
仲裁
仲裁指的是配置文件中的 quorum 选项。某个 Sentinel 先将 Master 节点标记为主观下线,然后会将这个判定通过 sentinel is-master-down-by-addr 命令询问其他 Sentinel 节点是否也同样认为该 addr 的 Master 节点要做主观下线。最后当达成这一共识的 Sentinel 个数达到前面说的 quorum 设置的值时,该 Master 节点会被认定为客观下线并进行故障转移。
quorum 的值一般设置为 Sentinel 个数的二分之一加 1,例如 3 个 Sentinel 就设置为 2。
哨兵模式工作原理
- 每个 Sentinel 以每秒一次的频率向它所知的 Master,Slave 以及其他 Sentinel 节点发送一个
PING命令; - 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过配置文件
own-after-milliseconds选项所指定的值,则这个实例会被 Sentinel 标记为主观下线; - 如果一个 Master 被标记为主观下线,那么正在监视这个 Master 的所有 Sentinel 要以每秒一次的频率确认 Master 是否真的进入主观下线状态;
- 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认 Master 的确进入了主观下线状态,则 Master 会被标记为客观下线;
- 如果 Master 处于 ODOWN 状态,则投票自动选出新的主节点。将剩余的从节点指向新的主节点继续进行数据复制;
- 在正常情况下,每个 Sentinel 会以每 10 秒一次的频率向它已知的所有 Master,Slave 发送
INFO命令;当 Master 被 Sentinel 标记为客观下线时,Sentinel 向已下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次; - 若没有足够数量的 Sentinel 同意 Master 已经下线,Master 的客观下线状态就会被移除。若 Master 重新向 Sentinel 的 PING 命令返回有效回复,Master 的主观下线状态就会被移除。
优点
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都有;
- 主从可以自动切换,系统更健壮,可用性更高;
- Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
缺点
主从切换需要时间,会丢失数据;
还是没有解决主节点写的压力;
主节点的写能力,存储能力受到单机的限制;
动态扩容困难复杂,对于集群,容量达到上限时在线扩容会变得很复杂。
集群模式
假设上千万、上亿用户同时访问 Redis,QPS 达到 10 万+。这些请求过来,单机 Redis 直接就挂了。系统的瓶颈就出现在 Redis 单机问题上,此时我们可以通过主从复制解决该问题,实现系统的高并发。
主从模式中,当主节点宕机之后,从节点是可以作为主节点顶上来继续提供服务,但是需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预。于是,在 Redis 2.8 版本开始,引入了哨兵(Sentinel)这个概念,在主从复制的基础上,哨兵实现了自动化故障恢复。
哨兵模式中,单个节点的写能力,存储能力受到单机的限制,动态扩容困难复杂。于是,Redis 3.0 版本正式推出 Redis Cluster 集群模式,有效地解决了 Redis 分布式方面的需求。Redis Cluster 集群模式具有高可用、可扩展性、分布式、容错等特性。

Redis Cluster 采用无中心结构,每个节点都可以保存数据和整个集群状态,每个节点都和其他所有节点连接。Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点。
如上图所示,该集群中包含 6 个 Redis 节点,3 主 3 从,分别为 M1,M2,M3,S1,S2,S3。除了主从 Redis 节点之间进行数据复制外,所有 Redis 节点之间采用 Gossip 协议进行通信,交换维护节点元数据信息。
总结下来就是:读请求分配给 Slave 节点,写请求分配给 Master,数据同步从 Master 到 Slave 节点。
分片
单机、主从、哨兵的模式数据都是存储在一个节点上,其他节点进行数据的复制。而单个节点存储是存在上限的,集群模式就是把数据进行分片存储,当一个分片数据达到上限的时候,还可以分成多个分片。
Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:HASH_SLOT = CRC16(key) & 16384。每一个节点负责维护一部分槽以及槽所映射的键值数据。
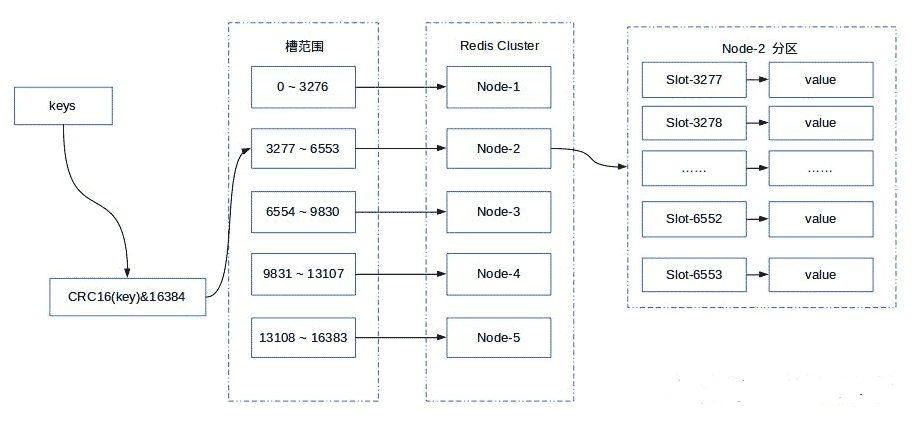
Redis Cluster 提供了灵活的节点扩容和缩容方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容也可以下线部分节点进行缩容。可以说,槽是 Redis Cluster 管理数据的基本单位,集群伸缩就是槽和数据在节点之间的移动。
简单的理解就是:扩容或缩容以后,槽需要重新分配,数据也需要重新迁移,但是服务不需要下线。
假如,这里有 3 个节点的集群环境如下:
- 节点 A 哈希槽范围为 0 ~ 5500;
- 节点 B 哈希槽范围为 5501 ~ 11000;
- 节点 C 哈希槽范围为 11001 ~ 16383。
此时,我们如果要存储数据,按照 Redis Cluster 哈希槽的算法,假设结果是: CRC16(key) & 16384 = 6782。 那么就会把这个key 的存储分配到 B 节点。此时连接 A、B、C 任何一个节点获取 key,都会这样计算,最终通过 B 节点获取数据。
假如这时我们新增一个节点 D,Redis Cluster 会从各个节点中拿取一部分 Slot 到 D 上,比如会变成这样:
- 节点 A 哈希槽范围为 1266 ~ 5500;
- 节点 B 哈希槽范围为 6827 ~ 11000;
- 节点 C 哈希槽范围为 12288 ~ 16383;
- 节点 D 哈希槽范围为 0 ~ 1265,5501 ~ 6826,11001 ~ 12287
这种特性允许在集群中轻松地添加和删除节点。同样的如果我想删除节点 D,只需要将节点 D 的哈希槽移动到其他节点,当节点是空时,便可完全将它从集群中移除。
主从模式
Redis Cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点复制主节点数据备份,当这个主节点挂掉后,就会通过这个主节点的从节点选取一个来充当主节点,从而保证集群的高可用。
回到刚才的例子中,集群有 A、B、C 三个主节点,如果这 3 个节点都没有对应的从节点,如果 B 挂掉了,则集群将无法继续,因为我们不再有办法为 5501 ~ 11000 范围内的哈希槽提供服务。
所以我们在创建集群的时候,一定要为每个主节点都添加对应的从节点。比如,集群包含主节点 A、B、C,以及从节点 A1、B1、C1,那么即使 B 挂掉系统也可以继续正确工作。
因为 B1 节点属于 B 节点的子节点,所以 Redis 集群将会选择 B1 节点作为新的主节点,集群将会继续正确地提供服务。当 B 重新开启后,它就会变成 B1 的从节点。但是请注意,如果节点 B 和 B1 同时挂掉,Redis Cluster 就无法继续正确地提供服务了。
优点
- 无中心架构;
- 可扩展性,数据按照 Slot 存储分布在多个节点,节点间数据共享,节点可动态添加或删除,可动态调整数据分布;
- 高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本。
- 实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的角色提升。
缺点
- 数据通过异步复制,无法保证数据强一致性;
- 集群环境搭建复杂,不过基于 Docker 的搭建方案会相对简单。
总结
随着互联网的飞速发展,我们享受着技术带来的便利,同时也给从业者带来了如何保证项目高并发、低延时的技术挑战。Redis 以其超高的性能,简洁轻量的设计,易上手,分布式架构的支持,在缓存等领域出色的表现等,得到了业界广泛的关注和应用,在当今高性能架构中,也发挥着越来越重要的作用。甚至可以说,Redis 已经成为 IT 互联网大型系统的标配,熟练掌握 Redis 成为开发、运维人员的必备技能。
如果不深挖底层,仅仅只是从使用的角度出发,Redis 的学习成本将会非常低。如果作为一个很好的中间件去研究的话,还是有很多值得学习和借鉴的地方。以上几种模式,每种都有各自的优缺点,在实际场景中要根据业务特点去选择合适的模式使用。
参考资料
- https://redis.io/topics/replication
- https://redis.io/topics/sentinel
- https://redis.io/topics/cluster-tutorial
- https://redis.io/topics/cluster-spec
本文采用 知识共享「署名-非商业性使用-禁止演绎 4.0 国际」许可协议。
最通俗易懂的 Redis 架构模式详解的更多相关文章
- 【Redis】Redis学习(四) Redis Sentinel模式详解
主从模式的弊端就是不具备高可用性,当master挂掉以后,Redis将不能再对外提供写入操作,因此sentinel应运而生. Redis Sentinel是Redis官方提供的集群管理工具,主要有三大 ...
- 【Redis】Redis学习(三) Redis 主从模式详解
不管任何程序,只运行一个实例都是不可靠的,一旦因为网络原因导致所在机器不可达,或者所在服务器挂掉,那么这个程序将不能对外提供服务了,Redis也是一样的.不过Redis的主从并不是解决这个问题的,一些 ...
- 【Redis】Redis学习(五) Redis cluster模式详解
一般情况下,使用主从模式加Sentinal监控就可以满足基本需求了,但是当数据量过大一个主机放不下的时候,就需要对数据进行分区,将key按照一定的规则进行计算,并将key对应的value分配到指定的R ...
- redis入门到精通系列(九):redis哨兵模式详解
(一)哨兵概述 前面我们讲了redis的主从复制,为了实现高可用,会选择一台服务器作为master,多台服务器作为slave.现在有这样一种情况,master宕机了,这时系统会选择一台slave作为m ...
- Dubbo架构设计详解-转
Dubbo架构设计详解 2013-09-03 21:26:59 Yanjun Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解 ...
- Redis 配置文件 redis.conf 项目详解
Redis.conf 配置文件详解 # [Redis](http://yijiebuyi.com/category/redis.html) 配置文件 # 当配置中需要配置内存大小时,可以使用 1k, ...
- [转]Redis内部数据结构详解-sds
本文是<Redis内部数据结构详解>系列的第二篇,讲述Redis中使用最多的一个基础数据结构:sds. 不管在哪门编程语言当中,字符串都几乎是使用最多的数据结构.sds正是在Redis中被 ...
- [CB]Intel 2018架构日详解:新CPU&新GPU齐公布 牙膏时代有望明年结束
Intel 2018架构日详解:新CPU&新GPU齐公布 牙膏时代有望明年结束 北京时间12月12日晚,Intel在圣克拉拉举办了架构日活动.在五个小时的演讲中,Intel揭开了2021年CP ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
随机推荐
- Qt数据库 QSqlTableModel实例操作(转)
本文介绍的是Qt数据库 QSqlTableModel实例操作,详细操作请先来看内容.与上篇内容衔接着,不顾本文也有关于上篇内容的链接. Qt数据库 QSqlTableModel实例操作是本文所介绍的内 ...
- Python编写的桌面图形界面程序实现更新检测和下载安装
在Python中我们有很多种方案来编写桌面图形用户界面程序,譬如内置的 Tkinter .强大的 PyQt5 和 PySide2 ,还有 wxPython .借助这些或内置或第三方的模块,我们可以轻松 ...
- Docker 搭建 RabbitMQ
Docker RabbitMQ RabbitMQ 安装非常繁琐,使用 Docker 快速搭建一个 RabbitMQ 开发环境 步骤 拉取镜像 docker pull rabbitmq 启动容器 端口会 ...
- 语言模型 Language Model (LM)
定义 什么是语言模型,通俗的讲就是从语法上判断一句话是否通顺.即判断如下的概率成立: \[p(\text{今天是周末})>p(\text{周末是今天}) \] 链式法则(chain rule) ...
- XCTF-WEB-高手进阶区-NaNNaNaNNaN-Batman-笔记
上来直接百度先搜下Batman -_-|| 不存在的传令兵么 本身是下载下来了一个文件web100 打开发现是如下内容 可以看出这个是个脚本语言,因此尝试修改后缀为html,发现是一个OK框 现在是想 ...
- C#LeetCode刷题之#119-杨辉三角 II(Pascal‘s Triangle II)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3690 访问. 给定一个非负索引 k,其中 k ≤ 33,返回杨辉 ...
- JavaScript 手写setTimeout
let setTimeout = (sec, num) => { // 初始当前时间 const now = new Date().getTime() let flag = true let c ...
- IDEA 非常重要的一些设置项 → 一连串的问题差点让我重新用回 Eclipse !
开心一刻 建筑行业内,我看过的最凶残笑话(IT行业内好一致!) 上联:一天晚上两个甲方三更半夜四处催图只好周五加班到周六早上七点画好八点传完九点上床睡觉十分痛苦 下联:十点才过九分甲方八个短信七个电话 ...
- Homekit_人体感应器
前置需求: 苹果手机一台 Homekit人体感应一台 USB供电线一根 这款产品内置人体红外感应器,使用圆环设计,增大了其接触面积,使感应变得更加灵敏,重量轻,方便将其粘贴到墙上,同时支持二次开发,如 ...
- golang 工厂模式
目录 前言 1.介绍 2.分析 1.优点 2.缺点 3.模式扩展 4.适用环境 5.模式结构 类图 时序图 demo 跳转 前言 不做文字的搬运工,多做灵感性记录 这是平时学习总结的地方,用做知识库 ...