【PSMA】Progressive Sample Mining and Representation Learning for One-Shot Re-ID
导言
文章提出了一种新的三元组损失 HSoften-Triplet-Loss,在处理one-shot Re-ID任务中的噪声伪标签样本方面非常强大。文章还提出了一种伪标签采样过程,确保了在保持高可靠性的同时为训练图像形成正对和负对的可行性。与此同时,文章采用对抗学习网络,为训练集提供更多具有相同ID的样本,从而增加了训练集的多样性。 实验表明,文章框架在Market-1501(mAP 42.7%)和DukeMTMC-Reid数据集(mAP 40.3%)取得了最先进的Re-ID性能。
引用
@article{DBLP:journals/pr/LiXSLZ21,
author = {Hui Li and
Jimin Xiao and
Mingjie Sun and
Eng Gee Lim and
Yao Zhao},
title = {Progressive sample mining and representation learning for one-shot
person re-identification},
journal = {Pattern Recognit.},
volume = {110},
pages = {107614},
year = {2021}
}
相关链接
paper:https://www.sciencedirect.com/science/article/pii/S0031320320304179?via%3Dihub
code:https://github.com/detectiveli/PSMA
下方↓公众号后台回复“PSMA”,即可获得论文电子资源。

主要挑战
- how to design loss functions for Re-ID training with pseudo labelled samples;
- how to select unlabelled samples for pseudo label;
- how to overcome the overfitting problem due to lack of data
主要的贡献和创新点

Fig. 1. Example of pseudo labelled person sampling and training with new losses. The upper part is the third iteration step, where we choose 2 similar images with the same pseudo ID. After one more training iteration, in the lower part, we aim to choose one more image with pseudo label for each person, but ignore the wrong sample for ID 2.
We identify the necessity of triplet loss in image-based one-shot Re-ID, where the use of noisy pseudo labels for training is inevitable. Considering the nature of pseudo labels, we introduce an HSoften-Triplet-Loss to soften the negative influence of incorrect pseudo label. Meanwhile, a new batch formation rule is designed by taking different nature of labelled samples and pseudo labelled samples into account.
We propose a pseudo label sampling mechanism for one-shot Re-ID task, which is based on the relative sample distance to the feature center of each labelled sample. Our sampling mechanism ensures the feasibility of forming a positive pair and a negative pair of samples for each class label, which paves the way for the utilization of the HSoften-Triplet-Loss.
We achieve the state-of-the-art mAP score of 42.7% on Market1501 and 40.3% on DukeMTMC-Reid, 16.5 and 11.8 higher than EUG [7] respectively.
创新点
- triplet loss
- HSoften-Triplet-Loss
- new batch formation rule
- pseudo label sampling mechanism
提出的方法
总体框架与算法
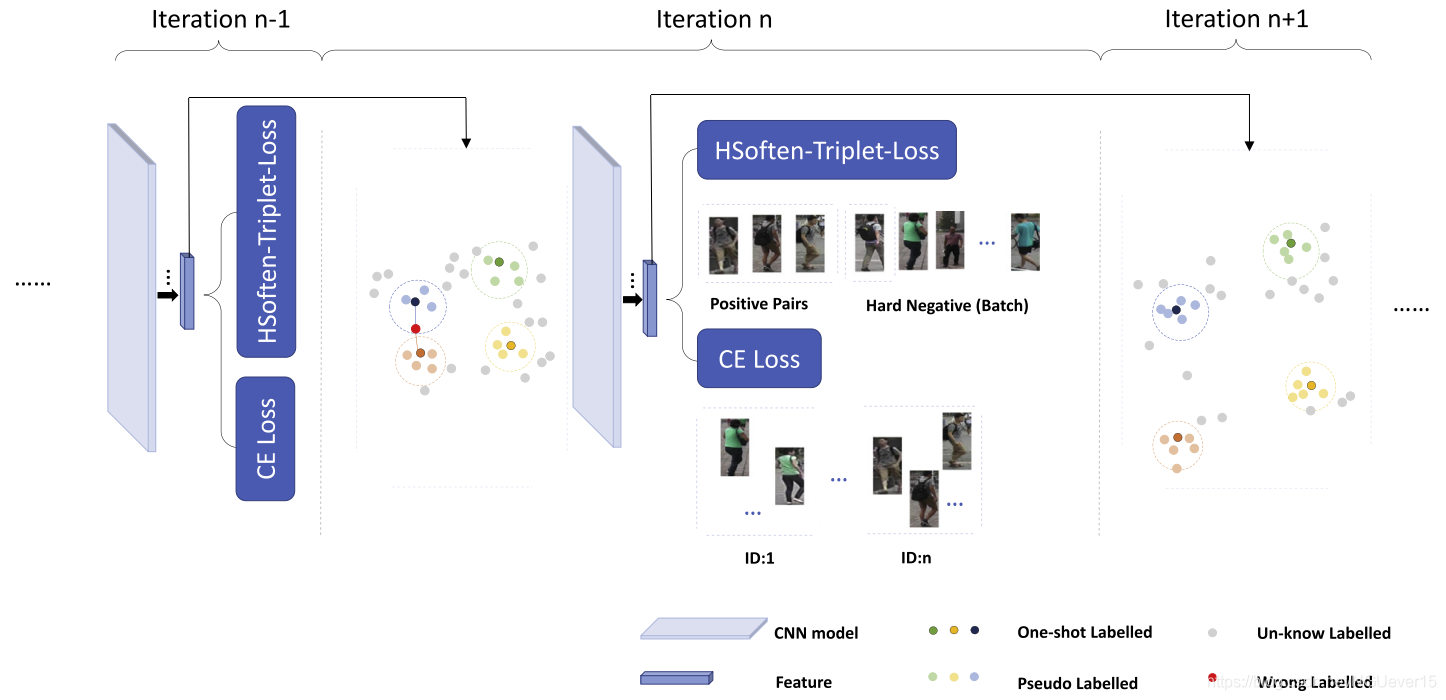
Fig. 2. Overview of our method. Our training process takes several iterations. Each iteration has two main steps: 1) Add pseudo labelled images for each labelled image.2) Train the model with both CE loss and HSoft-triplet loss. After each iteration, the model should be more discriminative for feature representation and more reliable to generate the next similarity matrix. This is demonstrated by the fact that image features of the same person are clustered in a more compact manner, and features of different person move apart. The new similarity matrix is used to sample more pseudo labelled images for the next iteration training. Best viewed in color.
Vanilla pseudo label sampling (PLS)
Our pseudo label sampling (PLS) process maintains distance ranking for each class label individually, whist EUG only maintains one overall distance ranking for all the class labels. Therefore, the PLS process in EUG cannot ensure the feasibility of forming a positive pair and a negative pair samples for each class label because for some classes there might be only one labelled sample for one class label. Thus, in EUG, it is not compatible to adopt a triplet loss or a contrast loss.
PLS with adversarial learning
In our framework, we also apply the adversarial learning into the one-shot Re-ID task. To be more specific, we use the CycleGAN [33] as a data augmentation tool to generate images of different cameras, and adapt the enhanced dataset to our PLS framework.
The total CycleGAN loss will be:
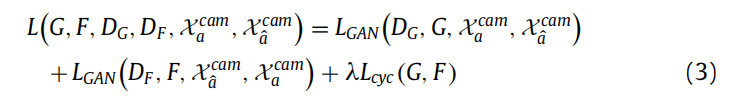
With the enhanced dataset, we update our PLS process in three aspects: (1) we make full use of the entire enhanced dataset as the training set. (2) more labelled images are available during the initial training process. (3) instead of using the one-shot image feature as sample mining reference, we use the feature centre of that
person under different cameras.
Training losses
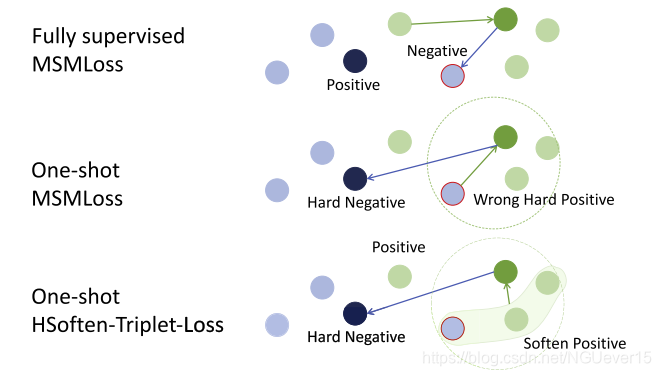
Fig. 3. The comparison of different losses.1) In fully-supervised learning, MSMLoss is perfect to distinct the positive and negative samples. 2) In one-shot learning, an incorrect hard positive sample causes strong miss. 3) In one-shot learning, soften hard positive can avoid the fatal impact of the incorrect hard positive sample by averaging the features. Best viewed in color.
The softmax loss is formulated as:
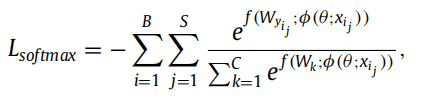
The MSMLoss [24] is formulated as:
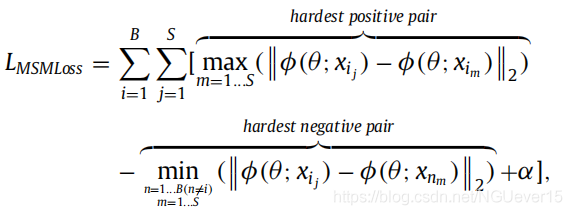
we design a soft version of hard positive sample feature representation:
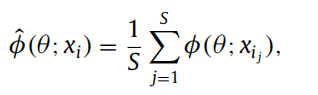
The final HSoften-Triplet-Loss is:

The overall loss is the combination of both softmax, and our HSoften-Triplet-Loss with parameter λ.
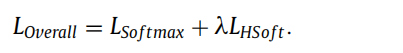
实验与结果
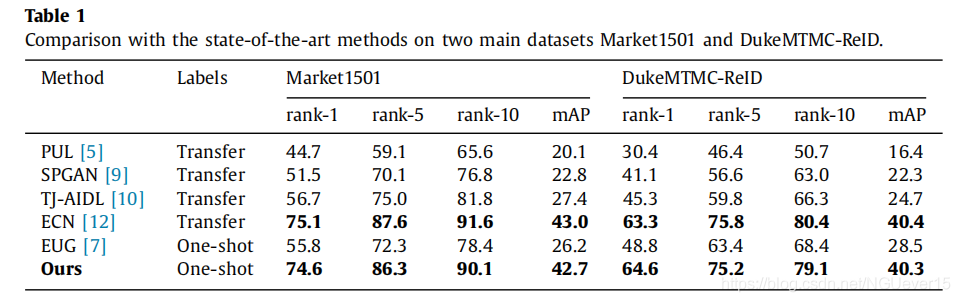
As can observed from Table 1, among the methods in the lower group (one-shot learning), our model achieves a new state-of-the-art performance on both Market1501 (mAP of 42.7%) and DukeMTMC-ReID (mAP of 40.3%). Compared with the previous state-of-the-art method EUG [7], our method improves the accuracy of mAP by 16.5 on Market1501, and by 11.8 on DukeMTMC-ReID, which shows the robustness of our method on different testing datasets. In terms of the comparison in the second group, our method also achieves competitive results. On both dataset, our method virtually achieves the same accuracy as the best performing method in the upper group (transfer learning), while our method needs much fewer labels for training, which demonstrates the data efficiency of our method.
Ablation study on components:
- a) Effect of different network structures
- b) Ablation study on the number of generated samples
- c) Ablation study on the weight parameter λ
- d) Visualization of the feature distribution
结论
In this paper, we design a new triplet loss HSoften-Triplet-Loss, which is robust when dealing with the noisy pseudo labelled samples for the one-shot person Re-ID task. To provide compatible input data for the triplet loss, we also propose a pseudo label sampling process, that ensures the feasibility of forming a positive pair and a negative pair for the training images while maintaining high reliability. Extensive experimental results prove that using our new triplet loss leads to much better performance than simply using the softmax loss in existing one-shot person Re-ID methods, as well as conventional triplet loss without a softening mechanism. Besides, we further adopt an adversarial learning network to provide more samples with the same ID for the training set, which increases the diversity of the training set.
We believe our proposed HSoften-Triplet-Loss can be widely used for other identification tasks, where the noisy pseudo labels are involved, for examples, person Re-ID, face recognition with limited and/or weakly annotated labels. In the future work, we plan to study a more sophisticated distance metric to mine pseudo labelled images, and we also plan to deploy our new triplet loss in the one-shot face recognition task.
【PSMA】Progressive Sample Mining and Representation Learning for One-Shot Re-ID的更多相关文章
- 【CV】CVPR2015_A Discriminative CNN Video Representation for Event Detection
A Discriminative CNN Video Representation for Event Detection Note here: it's a learning note on the ...
- 【转载】Sqlserver在创建表的时候如何定义自增量Id
在Sqlserver创建表的过程中,有时候需要为表指定一个自增量Id,其实Sqlserver和Mysql等数据库都支持设置自增量Id字段,允许设置自增量Id的标识种子和标识自增量,标识种子代表初始自增 ...
- 【翻译】停止学习框架(Stop Learning Frameworks)
原文地址:https://sizovs.net/2018/12/17/stop-learning-frameworks/.翻译的比较生硬,大家凑合看吧. 我们作为程序员,对技术要时刻保持着激情,每天都 ...
- 深度强化学习介绍 【PPT】 Human-level control through deep reinforcement learning (DQN)
这个是平时在实验室讲reinforcement learning 的时候用到PPT, 交期末作业.汇报都是一直用的这个,觉得比较不错,保存一下,也为分享,最早该PPT源于师弟汇报所做.
- 【论文 PPT】 【转】Human-level control through deep reinforcement learning(DQN)
最近在学习强化学习的东西,在网上发现了一个关于DQN讲解的PPT,感觉很是不错,这里做下记录,具体出处不详. ============================================= ...
- 【转】The most comprehensive Data Science learning plan for 2017
I joined Analytics Vidhya as an intern last summer. I had no clue what was in store for me. I had be ...
- 【解决】Linux Tomcat启动慢--Creation of SecureRandom instance for session ID generation using [SHA1PRNG] took [236,325] milliseconds
一.背景 今天部署项目到tomcat,执行./startup.sh命令之后,访问项目迟迟加载不出来,查看日志又没报错(其实是我粗心了,当时tomcat日志还没打印完),一开始怀疑是阿里云主机出现问题, ...
- 【转载】 迁移学习简介(tranfer learning)
原文地址: https://blog.csdn.net/qq_33414271/article/details/78756366 土豆洋芋山药蛋 --------------------------- ...
- 【转】iis解决应用程序池**提供服务的进程意外终止进程ID是**。进程退出代码是'0x80'
转自:http://blog.sina.com.cn/s/blog_56a68d5501013xdd.html 我们公司旗下的红黑互联会遇到这种问题 事件类型: 警告事件来源: W3SVC事件种类: ...
随机推荐
- MarkDown及Typora文本编辑器
文章介绍主要介绍MarkDown语法和与之能够配套使用的文本编辑器Typora的下载使用 1. MarkDown简介 MarkDown是一种纯文本标记语言,其书写与txt.word文档类似: 所有网站 ...
- P5691 [NOI2001]方程的解数
题意描述 方程的解数 求方程 \(\sum_{i=1}^{n}k_ix_i^{p_i}=0(x_i\in [1,m])\) 的解的个数. 算法分析 远古 NOI 的题目就是水 类似于这道题. 做过这道 ...
- Linux开机启动顺序启动顺序及配置开机启动
Linux:开机启动顺序启动顺序及配置开机启动 开机启动顺序 1.加载内核 2.启动 init(/etc/inittab) pid=1 3.系统初始化 /etc/rc.d/rc.sysinit 4.运 ...
- 最新阿里Java后端开发面试题100道(P6-P7)
面试题 1.什么是字节码?采用字节码的好处是什么?2. Oracle JDK 和 OpenJDK 的对比?3.Arrays.sort 和 Collections.sort 实现原理和区别4.wait ...
- Redux学习day1
01.React介绍 Redux是一个用来管理管理数据状态和UI状态的JavaScript应用工具.随着JavaScript单页应用(SPA)开发日趋复杂,JavaScript需要管理比任何时候都要多 ...
- angularJS 小记
刚刚接触angularJS,网上学习了一遍菜鸟教程(http://www.runoob.com/angularjs/angularjs-tutorial.html),做了些基础知识的笔记. Angul ...
- 数字取证autopsy——性能优化(二)
介绍: 在开始使用autopsy之前,我们先对autopsy进行性能优化.如果还没有安装autopsy,请点击连接https://github.com/sleuthkit/autopsy/releas ...
- waitpid()系统调用学习
waitpid()的头文件 #include <sys/types.h> #include <sys/wait.h> pid_t waitpid(pid_t pid,int ...
- 【JVM第四篇--运行时数据区】堆
写在前面的话:本文是在观看尚硅谷JVM教程后,整理的学习笔记.其观看地址如下:尚硅谷2020最新版宋红康JVM教程 一.堆的概述 JVM的运行时数据区如下: 一个Java程序运行起来对应着一个进程(操 ...
- 加解密 C语言实现
1.加密的基本原理 加密分为对称加密和非对称加密,对称加密就是加密方和解密放用同一个密钥. 加密是分组加密,即将明文数据分成多个密钥大小的块,依次和密钥运算,输出密文. padding,由于加密需要分 ...