python爬取千库网
url:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/
有水印
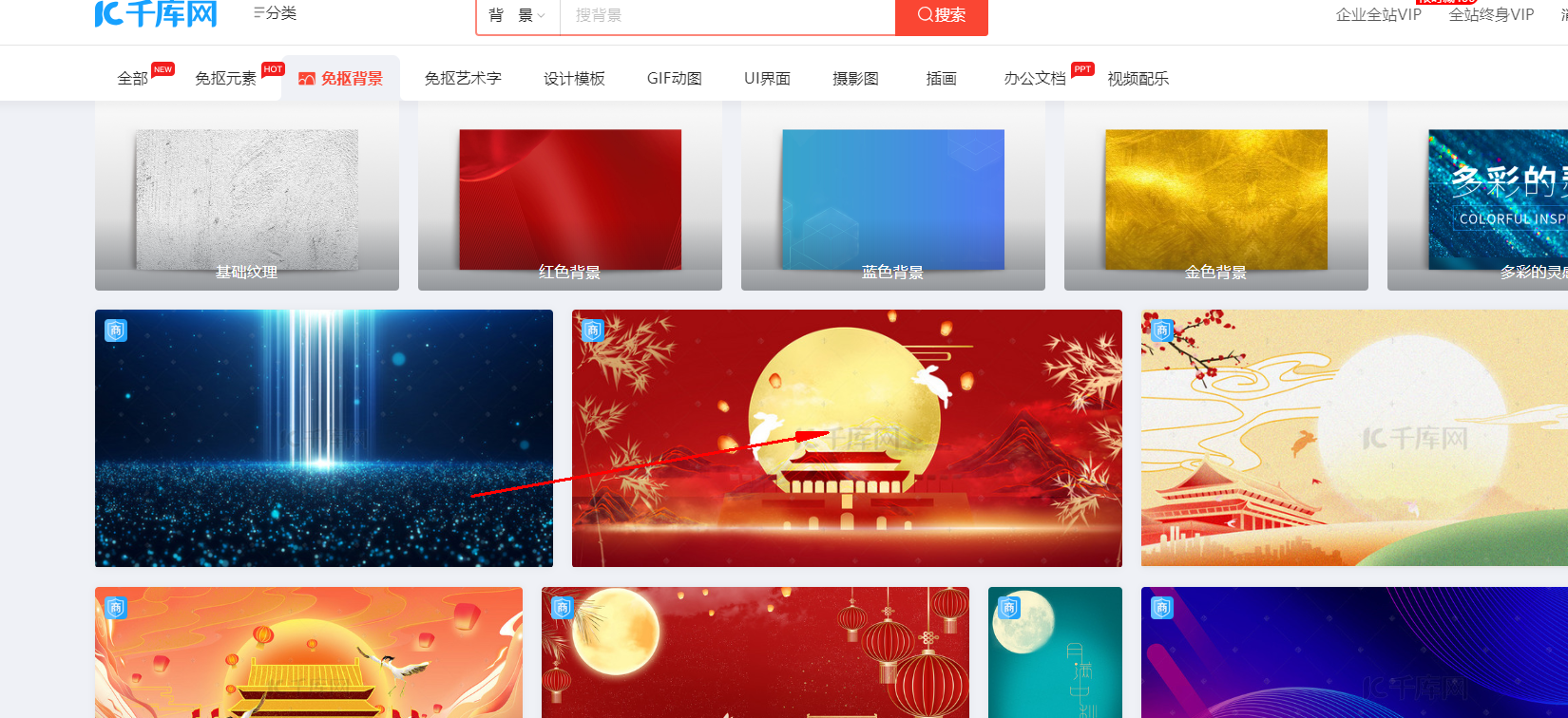
但是点进去就没了
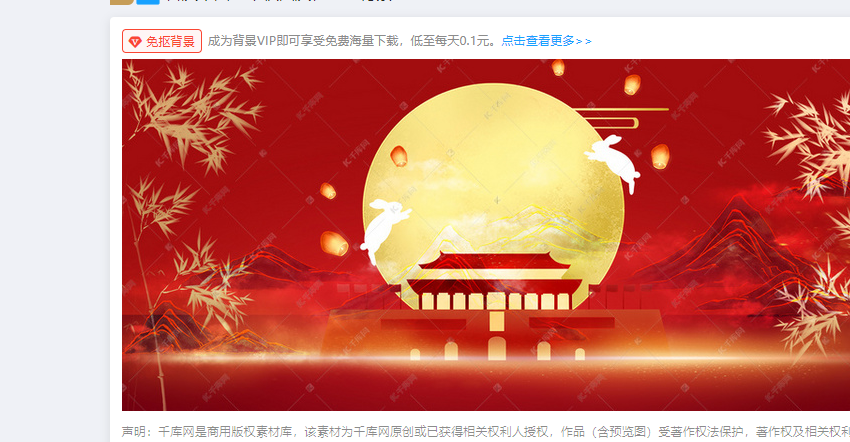
这里先来测试是否有反爬虫
import requestsfrom bs4 import BeautifulSoupimport oshtml = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/')print(html.text)
输出是404,添加个ua头就可以了
可以看到每个图片都在一个div class里面,比如fl marony-item bglist_5993476,是3个class但是最后一个编号不同就不取
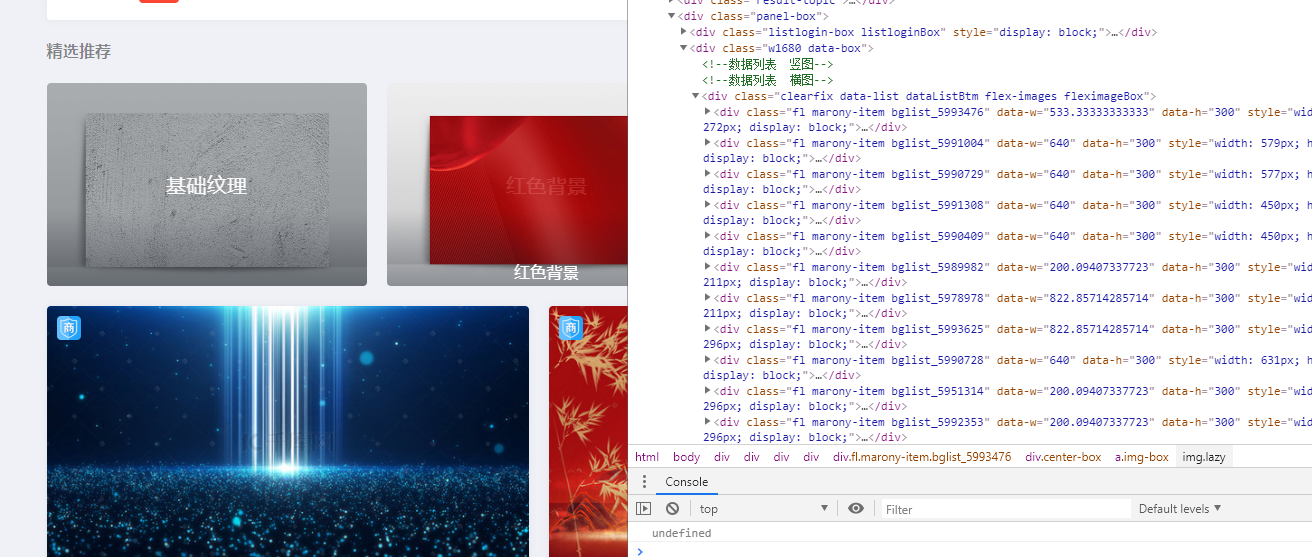
我们就可以获取里面的url
import requestsfrom bs4 import BeautifulSoupimport osheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/',headers=headers)soup = BeautifulSoup(html.text,'lxml')Urlimags = soup.select('div.fl.marony-item div a')for Urlimag in Urlimags:print(Urlimag['href'])
输出结果为
//i588ku.com/ycbeijing/5993476.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5991004.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5990729.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5991308.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5990409.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5989982.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5978978.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5993625.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5990728.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5951314.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5992353.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5993626.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5992302.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5820069.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5804406.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5960482.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5881533.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5986104.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5956726.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5986063.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5978787.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5954475.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5959200.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5973667.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5850381.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5898111.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5924657.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5975496.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5928655.html//i588ku.com/comnew/vip///i588ku.com/ycbeijing/5963925.html//i588ku.com/comnew/vip/
这个/vip是广告,过滤一下
for Urlimag in Urlimags:if 'vip' in Urlimag['href']:continueprint('http:'+Urlimag['href'])
然后用os写入本地
import requestsfrom bs4 import BeautifulSoupimport osheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/',headers=headers)soup = BeautifulSoup(html.text,'lxml')Urlimags = soup.select('div.fl.marony-item div a')for Urlimag in Urlimags:if 'vip' in Urlimag['href']:continue# print('http:'+Urlimag['href'])imgurl = requests.get('http:'+Urlimag['href'],headers=headers)imgsoup = BeautifulSoup(imgurl.text,'lxml')imgdatas = imgsoup.select_one('.img-box img')title = imgdatas['alt']print('无水印:','https:'+imgdatas['src'])if not os.path.exists('千图网图片'):os.mkdir('千图网图片')with open('千图网图片/{}.jpg'.format(title),'wb')as f:f.write(requests.get('https:'+imgdatas['src'],headers=headers).content)
然后我们要下载多页,先看看url规则
第一页:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/
第二页:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-2/
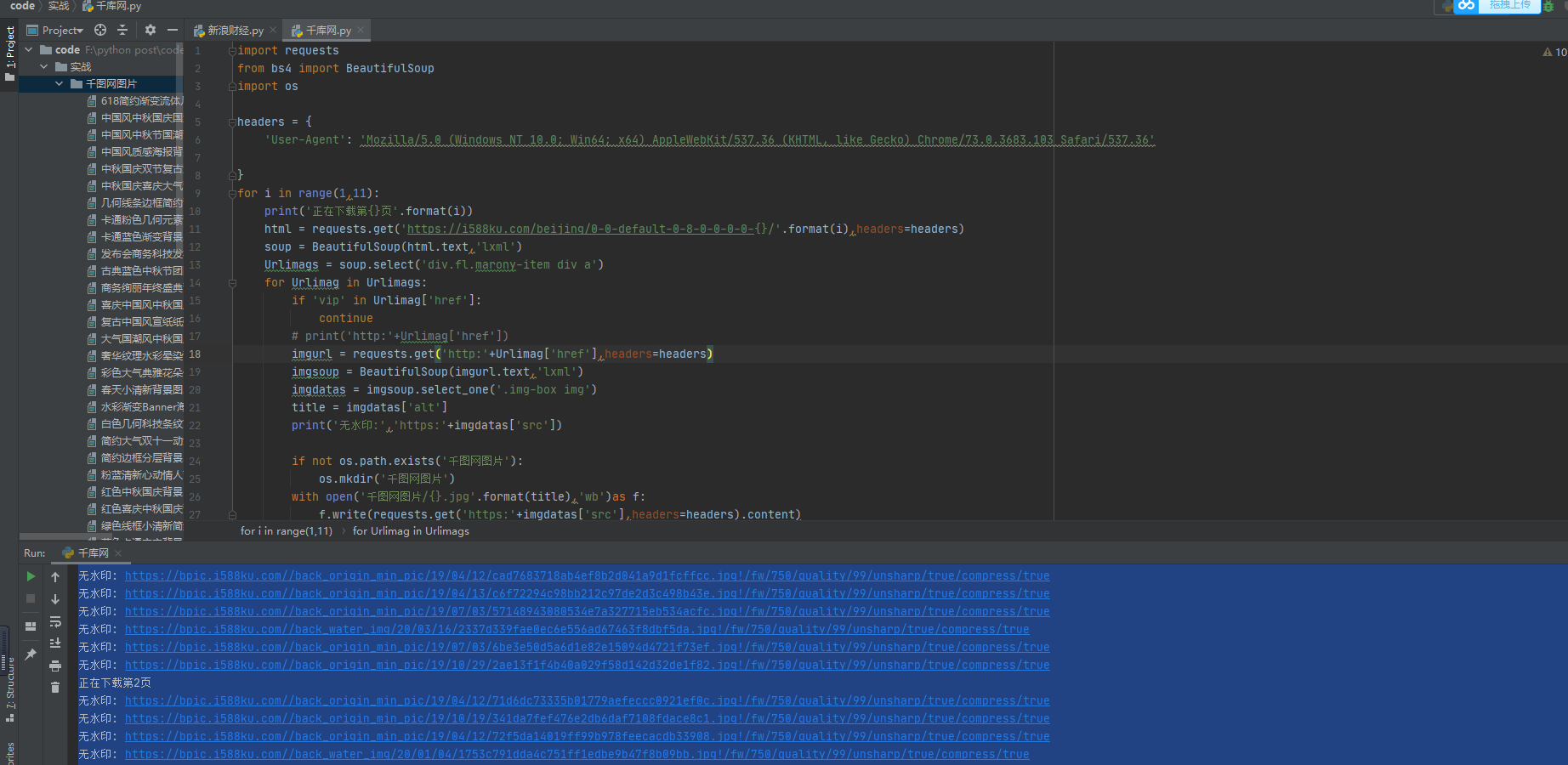
import requestsfrom bs4 import BeautifulSoupimport osheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}for i in range(1,11):print('正在下载第{}页'.format(i))html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-{}/'.format(i),headers=headers)soup = BeautifulSoup(html.text,'lxml')Urlimags = soup.select('div.fl.marony-item div a')for Urlimag in Urlimags:if 'vip' in Urlimag['href']:continue# print('http:'+Urlimag['href'])imgurl = requests.get('http:'+Urlimag['href'],headers=headers)imgsoup = BeautifulSoup(imgurl.text,'lxml')imgdatas = imgsoup.select_one('.img-box img')title = imgdatas['alt']print('无水印:','https:'+imgdatas['src'])if not os.path.exists('千图网图片'):os.mkdir('千图网图片')with open('千图网图片/{}.jpg'.format(title),'wb')as f:f.write(requests.get('https:'+imgdatas['src'],headers=headers).content)
python爬取千库网的更多相关文章
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- python爬取天气后报网
前言 大二下学期的大数据技术导论课上由于需要获取数据进行分析,我决定学习python爬虫来获取数据.由于对于数据需求量相对较大,我最终选择爬取 天气后报网,该网站可以查询到全国各地多年的数据,而且相对 ...
- (python爬取小故事网并写入mysql)
前言: 这是一篇来自整理EVERNOTE的笔记所产生的小博客,实现功能主要为用广度优先算法爬取小故事网,爬满100个链接并写入mysql,虽然CS作为双学位已经修习了三年多了,但不仅理论知识一般,动手 ...
- Python爬取中国票房网所有电影片名和演员名字,爬取齐鲁网大陆所有电视剧名称
爬取CBO中国票房网所有电影片名和演员名字 # -*- coding: utf-8 -*- # 爬取CBO中国票房网所有电影片名 import json import requests import ...
- python爬取斗图网中的 “最新套图”和“最新表情”
1.分析斗图网 斗图网地址:http://www.doutula.com 网站的顶部有这两个部分: 先分析“最新套图” 发现地址栏变成了这个链接,我们在点击第二页 可见,每一页的地址栏只有后面的pag ...
- 适合初学者的Python爬取链家网教程
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TinaLY PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- Python 爬取煎蛋网妹子图片
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-24 10:17:28 # @Author : EnderZhou (z ...
- python爬取中国知网部分论文信息
爬取指定主题的论文,并以相关度排序. #!/usr/bin/python3 # -*- coding: utf-8 -*- import requests import linecache impor ...
- Python爬取17吉他网吉他谱
最近学习吉他,一张一张保存吉他谱太麻烦,写个小程序下载吉他谱. 安装 BeautifulSoup,BeautifulSoup是一个解析HTML的库.pip install BeautifulSoup4 ...
随机推荐
- Javascript模块化编程(一):模块的写法 (转)
Javascript模块化编程(一):模块的写法 原文作者: 阮一峰 日期: 2012年10月26日 随着网站逐渐变成"互联网应用程序",嵌入网页的Javascript代码越来越庞 ...
- springMVC入门(七)------RESTFul风格的支持
简介 RESTful风格(Representational State Transfer),又叫表现层状态转移,是一种开发理念,也是对HTTP协议很好的诠释 主要理念是将互联网中的网页.数据.服务都视 ...
- 七夕节表白3d相册制作(html5+css3)
七夕节表白3d相册制作 涉及知识点 定位 阴影 3d转换 动画 主要思路: 通过定位将所有照片叠在一起,在设置默认的样式以及照片的布局,最后通过设置盒子以及照片的旋转动画来达到效果. 代码如下: &l ...
- 计算机网络-应用层(2)FTP协议
文件传输协议(FTP,File Transfer Protocol)是Internet上使用最广泛的文件传送协议.FTP提供交互式的访问,允许客户指明文件的类型与格式,并允许文件具有存取权限.它屏蔽了 ...
- 牛客网PAT练兵场-数字黑洞
题解:循环即可 题目地址:https://www.nowcoder.com/questionTerminal/2e6a898974064e72ba09d05a60349c9e /** * Copyri ...
- 服务应用突然宕机了?别怕,Dubbo 帮你自动搞定服务隔离!
某日中午,午睡正香的时候,接到系统的报警电话,提示生产某物理机异常宕机了,目前该物理机已恢复,需要重启上面部署的应用. 这时瞬间没有了睡意,登上堡垒机,快速重启了应用,系统恢复正常.本想着继续午睡,但 ...
- python爬虫-爬取豆瓣电影数据
#!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:27# 文件 :spider_05.py# IDE :PyChar ...
- 纯CSS3图片反转
一些简单实用的小技巧,CSS3对图片进行翻转,显示另一面的文字,或者图片效果,那么具体怎样去做呢?一起来看看吧. 在CSS3中,可以使用transform-style: preserve-3d进行3d ...
- vue前端获取env中的常量
process.env.常量名 如:process.env.MIX_APP_URL
- Photon PUN 二 大厅 & 房间
一, 简介 玩过 LOL , dota2, 王者荣耀 等MOBA类的游戏,就很容易理解大厅和房间了. LOL中一个服务器就相当与一个大厅; 什么电一,电二 ,,, 联通一区等 每一个区就相当于一个大厅 ...