基于sklearn的metrics库的常用有监督模型评估指标学习
一、分类评估指标
- 准确率(最直白的指标)
缺点:受采样影响极大,比如100个样本中有99个为正例,所以即使模型很无脑地预测全部样本为正例,依然有99%的正确率
适用范围:二分类(准确率);二分类、多分类(平均准确率)from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
accuracy_score(y_true, y_pred)
0.5
accuracy_score(y_true, y_pred, normalize=False)
2from sklearn.metrics import balanced_accuracy_score
y_true = [0, 1, 0, 0, 1, 0]
y_pred = [0, 1, 0, 0, 0, 1]
balanced_accuracy_score(y_true, y_pred)
0.625 - 混淆矩阵
适用范围:所有分类模型,包括二分类、多分类
介绍:实质是一张交叉表,纵轴为真实值,横轴为预测值
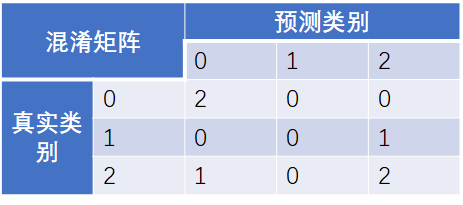
API介绍:Example1:多分类任务,类别已经转换为整数类型,分别为0,1,2三个类别
from sklearn.metrics import confusion_matrix
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
confusion_matrix(y_true, y_pred)
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])可以推导出混淆矩阵如下所示
Example2:多分类任务,类别没有转换为整型数值,而是作为字符串直接传入
from sklearn.metrics import confusion_matrix
y_true = ["cat", "ant", "cat", "cat", "ant", "bird"]
y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"]
confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"])
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])证明该API可以直接传入类别型字符串,混淆矩阵如下所示

Example3:二分类任务
from sklearn.metrics import confusion_matrix confusion_matrix([0, 1, 0, 1], [1, 1, 1, 0])
array([[0, 2],
[1, 1]], dtype=int64) tn, fp, fn, tp = confusion_matrix([0, 1, 0, 1], [1, 1, 1, 0]).ravel()
(tn, fp, fn, tp)
(0, 2, 1, 1)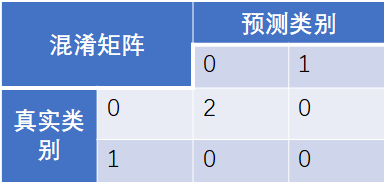
此处“1”为正例,“0”为反例 Roc曲线及auc值
适用范围:二分类
介绍:roc曲线为二维平面的一条曲线,横坐标为fpr,纵坐标为tpr,auc(area under the curve)顾名思义,即为曲线与横轴围成的曲线下的面积
API:
sklearn中有三个关于roc计算相关的接口,分别为metrics.roc_auc_score()
metrics.roc_curve()
metrics.auc()1)直接计算auc的值
from sklearn import metrics
import numpy as np
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
metrics.roc_auc_score(y_true, y_scores)
0.752)先计算fpr,tpr以及threshold(阈值),再通过fpr和tpr求auc
from sklearn import metrics
import numpy as np y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, threshold = metrics.roc_curve(y_true, y_scores)
(fpr, tpr, threshold)
(array([0. , 0.5, 0.5, 1. ]),
array([0.5, 0.5, 1. , 1. ]),
array([0.8 , 0.4 , 0.35, 0.1 ]))
metrics.auc(fpr, tpr)
0.75注意接口接收的参数为类别的真实标签以及模型输出的概率(得分)值,而非模型预测的标签(标签需要通过概率+阈值来得到)
- PR曲线及F1-score
PR曲线为二维平面曲线,横轴为Recall(召回率),纵轴为Precision(精确率),F1-score为recall和precision的调和平均数
适用范围:二分类
API:
sklearn中有五个常用的与PR相关的接口metrics.precision_recall_curve()
metrics.precision_recall_fscore_support()
metrics.precision_score()
metrics.recall_score()
metrics.fbeta_score()1)计算pr曲线
接口接收两个参数,其一为样本的真实值,另一个为样本的预测概率(得分),示例如下:import numpy as np
from sklearn.metrics import precision_recall_curve y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
precision, recall, thresholds = precision_recall_curve(y_true, y_scores)
precision, recall, thresholds
(array([0.66666667, 0.5 , 1. , 1. ]),
array([1. , 0.5, 0.5, 0. ]),
array([0.35, 0.4 , 0.8 ]))2)计算当预测值已经通过阈值转化为类别后的具体某一阈值下的PR及F-score值
from sklearn import metrics #该函数可直接求出precision、recall和f-score
precision,recall,fbeta_score,support = metrics.precision_recall_fscore_support()
#以下三个函数可分别求出precision、recall和f-score
precision = metrics.precision_score()
recall = metrics.recall_score()
f-score = metrics.fbeta_score()
- ks曲线及ks值
适用范围:二分类
ks曲线的横坐标为阈值的分位数,纵坐标分别为tpr,fpr,ks值(tpr-fpr),所以可用2中与ROC相关的接口计算得出 - kappa系数、汉明损失、铰链损失、杰卡德相关系数
适用范围:多分类metrics.cohen_kappa_score()
metrics.hamming_loss()
metrics.hinge_loss()
metrics.jaccard_score()
metrics.log_loss() - 马修斯相关系数(MCC)
适用范围:二分类from sklearn.metrics import matthews_corrcoef y_true = [+1, +1, +1, -1]
y_pred = [+1, -1, +1, +1]
matthews_corrcoef(y_true, y_pred)
-0.33333333
二、回归评估指标
- R2
- MSE
- MAE
睡了。。。明天再修改
基于sklearn的metrics库的常用有监督模型评估指标学习的更多相关文章
- Python机器学习笔记:常用评估指标的用法
在机器学习中,性能指标(Metrics)是衡量一个模型好坏的关键,通过衡量模型输出y_predict和y_true之间的某种“距离”得出的. 对学习器的泛化性能进行评估,不仅需要有效可行的试验估计方法 ...
- Spark ML机器学习库评估指标示例
本文主要对 Spark ML库下模型评估指标的讲解,以下代码均以Jupyter Notebook进行讲解,Spark版本为2.4.5.模型评估指标位于包org.apache.spark.ml.eval ...
- 数据挖掘入门系列教程(九)之基于sklearn的SVM使用
目录 介绍 基于SVM对MINIST数据集进行分类 使用SVM SVM分析垃圾邮件 加载数据集 分词 构建词云 构建数据集 进行训练 交叉验证 炼丹术 总结 参考 介绍 在上一篇博客:数据挖掘入门系列 ...
- 基于sklearn和keras的数据切分与交叉验证
在训练深度学习模型的时候,通常将数据集切分为训练集和验证集.Keras提供了两种评估模型性能的方法: 使用自动切分的验证集 使用手动切分的验证集 一.自动切分 在Keras中,可以从数据集中切分出一部 ...
- 基于sklearn的分类器实战
已迁移到我新博客,阅读体验更佳基于sklearn的分类器实战 完整代码实现见github:click me 一.实验说明 1.1 任务描述 1.2 数据说明 一共有十个数据集,数据集中的数据属性有全部 ...
- 机器学习--PCA算法代码实现(基于Sklearn的PCA代码实现)
一.基于Sklearn的PCA代码实现 import numpy as np import matplotlib.pyplot as plt from sklearn import datasets ...
- Element没更新了?Element没更新,基于El的扩展库更新
think-vuele 基于Vue和ElementUI框架进行整合二次开发的一个框架.提供一些elementUI没有的或当时没有的控件.优化了或简化了便于2B软件开发的一些控件 demo:http:/ ...
- 基于Qt的第三方库和控件
====================== 基于Qt的第三方库和控件 ====================== libQxt -------- http://dev.libqxt.o ...
- Boost正则表达式库regex常用search和match示例 - 编程语言 - 开发者第2241727个问答
Boost正则表达式库regex常用search和match示例 - 编程语言 - 开发者第2241727个问答 Boost正则表达式库regex常用search和match示例 发表回复 Boo ...
随机推荐
- 吴裕雄--天生自然 R语言开发学习:使用键盘、带分隔符的文本文件输入数据
R可从键盘.文本文件.Microsoft Excel和Access.流行的统计软件.特殊格 式的文件.多种关系型数据库管理系统.专业数据库.网站和在线服务中导入数据. 使用键盘了.有两种常见的方式:用 ...
- UFT参数化
1.Resources-Record and Run Settings 2.打开程序进行录制操作 3.对Fly from和Fly to进行参数化 4.选中点击 5.输入名称,点击OK 6.在Data加 ...
- MySQL5.7.x安装教程(tar.gz)
博主本人平和谦逊,热爱学习,读者阅读过程中发现错误的地方,请帮忙指出,感激不尽 二.MySQL安装(tar.gz) 1.系统环境设置 1.1清空系统mysql 安装mysql之前需要将系统自带的my ...
- smtp 邮件传输协议 qq版实现
qq: telnet smtp.qq.com 587 (qq邮箱说明:http://service.mail.qq.com/cgi-bin/help?subtype=1&&id=28& ...
- MAYA卸载/完美解决安装失败/如何彻底卸载清除干净MAYA各种残留注册表和文件的方法
在卸载MAYA重装MAYA时发现安装失败,提示是已安装或安装失败.这是因为上一次卸载后没有清理干净,系统会误认为已经安装过了.有的同学是新装的系统也会出现安装失败的情况,这是因为C++ 或者.NET的 ...
- devexpress设置选中行
版本2009.3 gvTagInfo.FocusedRowHandle = k; ; //有效 gvTagInfo.FocusedRowHandle = k; //这种 ...
- UML 类图介绍
UML 类图介绍 一. UML 简介 UML ( Unified Modeling Language )即统一建模语言,是 OMG ( Object Management Group )发表的图标式软 ...
- mysql中事务的并发问题与隔离级别
回归一下事务的四大特性ACID 1.原子性(Atomicity) 事务开始后所有操作,要么全部做完,要么全部不做.事务是一个不可分割的整体.事务在执行过程中出错,会回滚到事务开始之前的状态,以此来保证 ...
- TensorFlow_Faster_RCNN中demo.py的运行(CPU Only)
GitHub项目地址,https://github.com/endernewton/tf-faster-rcnnTensorflow Faster RCNN for Object Detection. ...
- 从赴美IPO绝迹 看那些烧成泡沫的互联网企业
曾经,赴美上市是很多中国企业的终极梦想.然而在当下,随着中概股在美国股市股价的不断走低.中国赴美上市企业私有化速度的加快,大众才发现,原来美国股市并不是那么好混的.但不管怎样,赴美上市始终是一种荣耀. ...