kubernetes flannel pod CrashLoopBackoff解决
背景
某环境客户部署了一个kubernetes集群,发现flannel的pod一直重启,始终处于CrashLoopBackOff状态。

排查
对于始终CrashLoopBackOff的pod,一般是应用本身的问题,需要查看具体pod的日志,通过
kubectl logs -f --tail -n kube-system flannel-xxx显示,“pod cidr not assigned”,然后flannel退出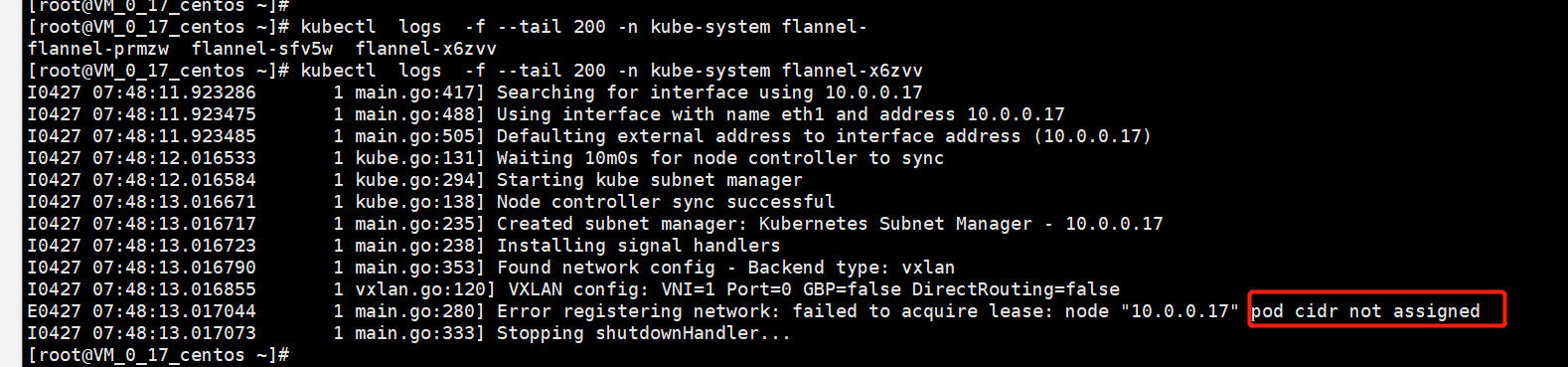
检查日志显示的节点10.0.0.17的cidr,发现确实为空,而正常的环境却是正常的。


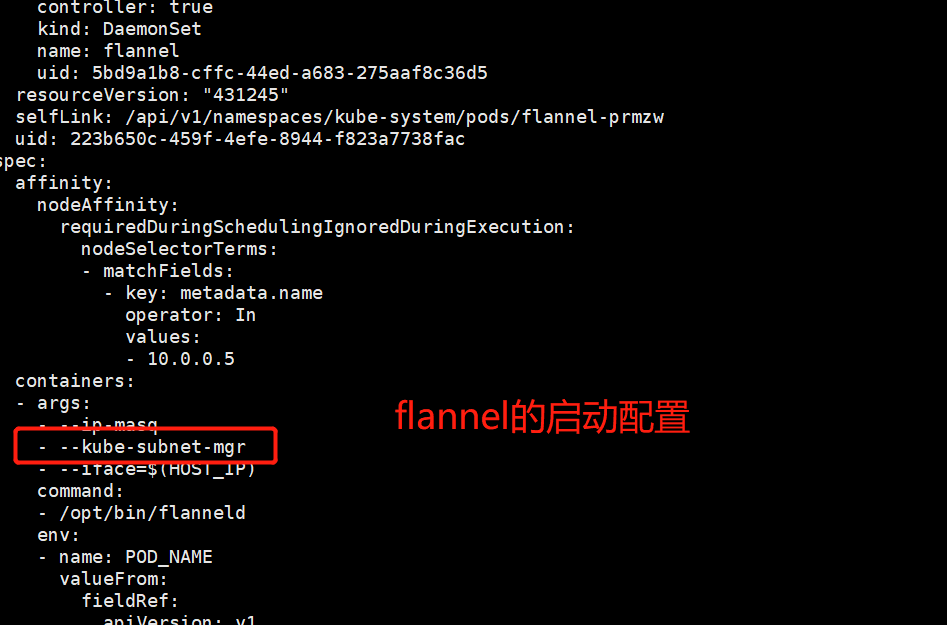
- 检查flannel的启动参数,发现为
--kube-subnet-mgr,–kube-subnet-mgr代表其使用kube类型的subnet-manager。该类型有别于使用etcd的local-subnet-mgr类型,使用kube类型后,flannel上各Node的IP子网分配均基于K8S Node的spec.podCIDR属性—"contact the Kubernetes API for subnet assignment instead of etcd.",而在第2步,我们已经发现节点的podcidr为空。
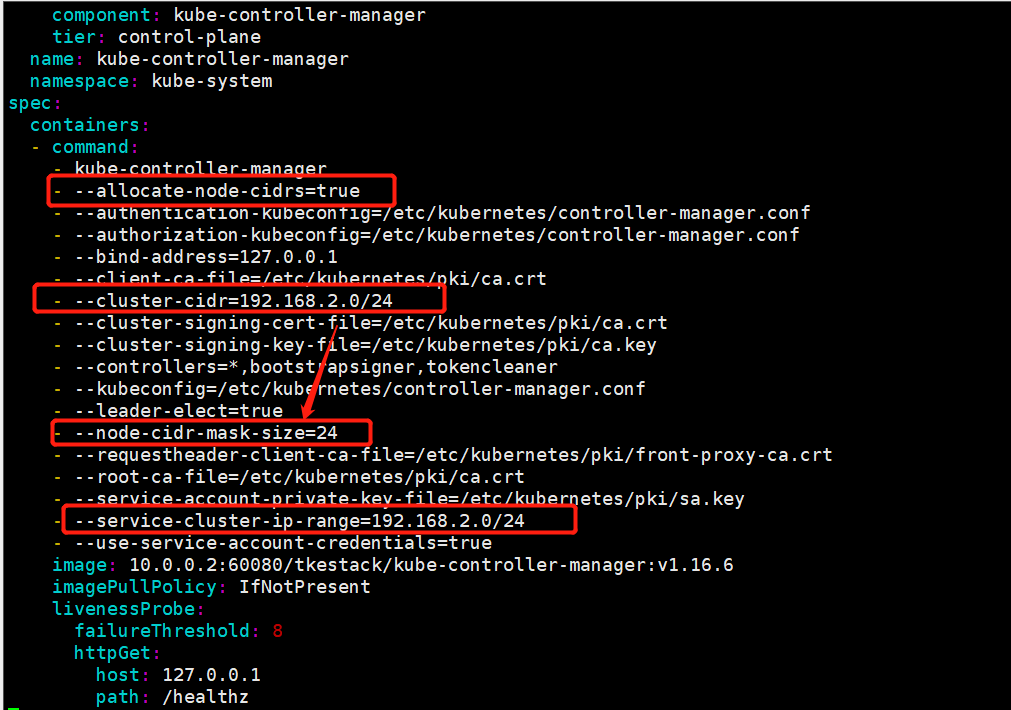
- node节点分配podCIDR,需要kube-controller-manager开启
allocate-node-cidrs为true,它和cluster-cidr参数共同使用的时候,controller-manager会为所有的Node资源分配容器IP段, 并将结果写入到PodCIDR字段.检查环境kube-controller-manager的配置文件,发现问题所在。如下图,环境设置了cluster-cidr为192.168.2.0/24,同时设置了node-cidr-mask-size为24,node-cidr-mask-size参数,用来表示kubernetes管理集群中节点的cidr掩码长度,默认是24位,需要从cluster-cidr里面分配地址段,而设置的cluster-cidr显然无法满足这个掩码要求,导致kube-controller-manager为节点分配地址失败。
后记
综上,可以修改node-cidr-mask-size参数为24以上的数解决node没法分配podcidr问题,但是同时发现环境部署使用的kubernetes自动化工具分配集群的service-cluster-ip-range也是从cluster-cidr里面取一段,分配不满足竟然使用了和cluster-cidr一样的地址,造成网段冲突。最终,让客户重新规划了网段,修改cluster-cidr掩码从24位改为16位,后续flannel均启动正常。
kubernetes flannel pod CrashLoopBackoff解决的更多相关文章
- kubernetes删除pod一直处于terminating状态的解决方法
kubernetes删除pod一直处理 Terminating状态 # kubectl get po -n mon NAME READY STATUS RESTARTS AGE alertmanage ...
- Kubernetes之Pod使用
一.什么是Podkubernetes中的一切都可以理解为是一种资源对象,pod,rc,service,都可以理解是 一种资源对象.pod的组成示意图如下,由一个叫”pause“的根容器,加上一个或多个 ...
- centos下kubernetes+flannel部署(旧)
更合理的部署方式参见<Centos下Kubernetes+Flannel部署(新)> 一.准备工作 1. 三台centos主机 k8s(即kubernetes,下同)master: 10. ...
- Kubernetes探索学习004--深入Kubernetes的Pod
深入研究学习Pod 首先需要认识到Pod才是Kubernetes项目中最小的编排单位原子单位,凡是涉及到调度,网络,存储层面的,基本上都是Pod级别的!官方是用这样的语言来描述的: A Pod is ...
- kubernetes之pod健康检查
目录 kubernetes之pod健康检查 1.概述和分类 2.LivenessProbe探针(存活性探测) 3.ReadinessProbe探针(就绪型探测) 4.探针的实现方式 4.1.ExecA ...
- Kubernetes基石-pod容器
引用三个问题来叙述Kubernetes的pod容器 1.为什么不直接在一个Docker容器中运行所有的应用进程. 2.为什么pod这种容器中要同时运行多个Docker容器(可以只有一个) 3.为什么k ...
- Kubernetes服务pod的健康检测liveness和readiness详解
Kubernetes服务pod的健康检测liveness和readiness详解 接下来给大家讲解下在K8S上,我们如果对我们的业务服务进行健康检测. Health Check.restartPoli ...
- kubernetes调度pod运行于master节点上
应用背景: 使用kubeadm部署的kubernetes集群,其master节点默认拒绝将pod调度运行于其上的,加点官方的术语就是:master默认被赋予了一个或者多个“污点(taints)”,“污 ...
- kubernetes concepts -- Pod Overview
This page provides an overview of Pod, the smallest deployable object in the Kubernetes object model ...
随机推荐
- docker-数据管理(3)
Docker 容器中管理数据主要有两种方式: 数据卷(Data volumes) 数据卷容器(Data volumes containers 数据卷是一个可供一个或者多个容器使用的特殊目录,它绕过UF ...
- 截取nginx日志
截取nginx日志 sed -n '/24\/Feb\/2017:11:00:00/,/24\/Feb\/2017:12:00:00/p' yunying_api.wanglibao.com.acce ...
- bibernate中inverse和cascade用法
一口一口吃掉Hibernate(八)--Hibernate中inverse的用法 [转自 http://blog.csdn.net/xiaoxian8023 ] 一.Inverse是hibernate ...
- Linux下实现文件共享配置[samba]
Linux下实现文件共享配置[samba] 第一步:安装samba软件 1.命令:rpm –q samba #查询是否已安装sambayum install samba #使用yum源安装samba, ...
- 【COCOS2DX-LUA 脚本开发之四】使用tolua++编译pk创建自定义类
此篇基本[COCOS2DX(2.X)_LUA开发之三]在LUA中使用自定义精灵(LUA脚本与自创建类之间的访问)及LUA基础讲解 在Lua第三篇中介绍了,如何在cocos2dx中使用Lua创建自定义类 ...
- .html文件转换成.txt
@ 思路 @-@ 简要 根据尖括号将文件分隔成字符串,建立一套判断字符串是否为标签的标准,若不为标签则为文本内容,存入结果文件中: @-@ 详述 0. 建立两个哈希表: 哈希表1 unordere ...
- js世家委托详解
事件原理 通过div0.addElementListener来调用:用法:div0.addElementListener(事件类型,事件回调函数,是否捕获时执行){}.1.事件类型(type):必须是 ...
- [LOJ2865] P4899 [IOI2018] werewolf 狼人
P4899 [IOI2018] werewolf 狼人 LOJ#2865.「IOI2018」狼人,第一次AC交互题 kruskal 重构树+主席树 其实知道重构树的算法的话,难度就主要在主席树上 习惯 ...
- 一只简单的网络爬虫(基于linux C/C++)————socket相关及HTTP
socket相关 建立连接 网络通信中少不了socket,该爬虫没有使用现成的一些库,而是自己封装了socket的相关操作,因为爬虫属于客户端,建立套接字和发起连接都封装在build_connect中 ...
- socket编程之时间回射服务器
使用到的函数: // 返回值:读到的字节数,若已到文件尾,返回0:若出错,返回-1 ssize_t read(int fd, void *buf, size_t nbytes); // 返回值:若成功 ...