Java入门系列之线程池ThreadPoolExecutor原理分析思考(十五)
前言
关于线程池原理分析请参看《http://objcoding.com/2019/04/25/threadpool-running/》,建议对原理不太了解的童鞋先看下此文然后再来看本文,这里通过对原理的学习我谈谈对线程池的理解,若有错误之处,还望批评指正。
线程池思考
线程池我们可认为是准备好执行应用程序级任务的预先实例化的备用线程集合,线程池通过同时运行多个任务来提高性能,同时防止线程创建过程中的时间和内存开销,例如,一个Web服务器在启动时实例化线程池,这样当客户端请求进入时,它就不会花时间创建线程,与为每个任务都创建线程相比,线程池通过避免一次无限创建线程来避免资源(处理器,内核,内存等)用尽,创建一定数量的线程后,通常将多余的任务放在等待队列中,直到有线程可用于新任务。下面我们通过一个简单的例子来概括线程池原理,如下:
public static void main(String[] args) {
ArrayBlockingQueue<Runnable> arrayBlockingQueue = new ArrayBlockingQueue<>(5);
ThreadPoolExecutor poolExecutor =
new ThreadPoolExecutor(2,
5, Long.MAX_VALUE, TimeUnit.NANOSECONDS, arrayBlockingQueue);
for (int i = 0; i < 11; i++) {
try {
poolExecutor.execute(new Task());
} catch (RejectedExecutionException ex) {
System.out.println("拒绝任务 = " + (i + 1));
}
printStatus(i + 1, poolExecutor);
}
}
static void printStatus(int taskSubmitted, ThreadPoolExecutor e) {
StringBuilder s = new StringBuilder();
s.append("工作池大小 = ")
.append(e.getPoolSize())
.append(", 核心池大小 = ")
.append(e.getCorePoolSize())
.append(", 队列大小 = ")
.append(e.getQueue().size())
.append(", 队列剩余容量 = ")
.append(e.getQueue().remainingCapacity())
.append(", 最大池大小 = ")
.append(e.getMaximumPoolSize())
.append(", 提交任务数 = ")
.append(taskSubmitted);
System.out.println(s.toString());
}
static class Task implements Runnable {
@Override
public void run() {
while (true) {
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
break;
}
}
}
}

如上例子很好的阐述了线程池基本原理,我们声明一个有界队列(容量为5),实例化线程池的核心池大小为2,最大池大小为10,创建线程没有自定义实现,默认通过线程池工厂创建,拒绝策略为默认,提交11个任务。在启动线程池时,默认情况下它将以无线程启动,当我们提交第一个任务时,将产生第一个工作线程,并将任务移交给该线程,只要当前工作线程数小于配置的核心池大小,即使某些先前创建的核心线程可能处于空闲状态,也会为每个新提交的任务生成一个新的工作线程(注意:当工作线程池大小未超过核心池大小时以创建的Worker中的第一个任务执行即firstTask,而绕过了阻塞队列),若超过核心池大小会将任务放入阻塞队列,一旦阻塞队列满后将重新创建线程任务,若任务超过最大线程池大小将执行拒绝策略。当阻塞队列为无界队列(如LinkedBlockingQueue),很显然设置的最大池大小将无效。我们再来阐述下,当工作线程数达到核心池大小时,若此时提交的任务越来越多,线程池的具体表现行为是什么呢?
1、只要有任何空闲的核心线程(先前创建的工作线程,但已经完成分配的任务),它们将接管提交的新任务并执行。
2、如果没有可用的空闲核心线程,则每个提交的新任务都将进入已定义的工作队列中,直到有一个核心线程可以处理它为止。如果工作队列已满,但仍然没有足够的空闲核心线程来处理任务,那么线程池将恢复而创建新的工作线程,新任务将由它们来执行。 一旦工作线程数达到最大池大小,线程池将再次停止创建新的工作线程,并且在此之后提交的所有任务都将被拒绝。
由上述2我们知道,一旦达到核心线程大小就会进入阻塞队列(阻塞队列未满),我们可认为这是一种执行阻塞队列优先的机制,那我们是不是可以思考一个问题:何不创建非核心线程来扩展线程池大小而不是进入阻塞队列,当达到最大池大小时才进入阻塞队列进行排队,这种方式和默认实现方式在效率和性能上是不是可能会更好呢? 但是从另外一个层面来讲,既然不想很快进入阻塞队列,那么何不将指定的核心池大小进行扩展大一些呢?我们知道线程数越多那么将导致明显的数据争用问题,也就是说在非峰值系统中的线程数会很多,所以在峰值系统中通过创建非核心线程理论上是不是能够比默认立即进入阻塞队列具有支撑规模化的任务更加具有性能上的优势呢?那么我们怎样才能修改默认操作呢?我们首先来看看在执行任务时的操作
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
}
第一步得到当前工作线程数若小于核心池大小,那么将创建基于核心池的线程然后执行任务,这一点我们没毛病,第二步若工作线程大小超过核心池大小,若当前线程正处于运行状态且将其任务放到阻塞队列中,若失败进行第三步创建非核心池线程,通过源码分析得知,若核心池中线程即使有空闲线程也会创建线程执行任务,那么我们是不是可以得到核心池中是否有空闲的线程呢,若有然后才尝试使其进入阻塞队列,所以我们需要重写阻塞队列中的offer方法,添加一个是否有空闲核心池的线程,让其接待任务。所以我们继承上述有界阻塞队列,如下:
public class CustomArrayBlockingQueue<E> extends ArrayBlockingQueue {
private final AtomicInteger idleThreadCount = new AtomicInteger();
public CustomArrayBlockingQueue(int capacity) {
super(capacity);
}
@Override
public boolean offer(Object o) {
return idleThreadCount.get() > 0 && super.offer(o);
}
}
但是不幸的是,通过对线程池源码的分析,我们并不能够得到空闲的核心池的线程,但是我们可以跟踪核心池中的空闲线程,在获取任务方法中如下:
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
} try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
如上截取获取任务的核心,若工作线程大小大于核心池大小时,默认情况下会进入阻塞队列此时通过pool获取阻塞队列中的任务,若工作线程大小小于核心池大小时,此时会调用take方法获从阻塞队列中获取可用的任务,此时说明当前核心池线程处于空闲状态,如果队列中没有任务,则线程将在此调用时会阻塞,直到有可用的任务为止,因此核心池线程仍然处于空闲状态,所以我们增加上述计数器,否则,调用方法返回,此时该线程不再处于空闲状态,我们可以减少计数器,重写take方法,如下:
@Override
public Object take() throws InterruptedException {
idleThreadCount.incrementAndGet();
Object take = super.take();
idleThreadCount.decrementAndGet();
return take;
}
接下来我们再来考虑timed为true的情况,在这种情况下,线程将使用poll方法,很显然,进入poll方法的任何线程当前都处于空闲状态,因此我们可以在工作队列中重写此方法的实现,以在开始时增加计数器,然后,我们可以调用实际的poll方法,这可能导致以下两种情况之,如果队列中没有任务,则线程将等待此调用以提供所提供的超时,然后返回null。到此时,线程将超时,并将很快从池中退出,从而将空闲线程数减少1,因此我们可以在此时减少计数器,否则由方法调用返回,因此该线程不再处于空闲状态,此时我们也可以减少计数器。
@Override
public Object poll(long timeout, TimeUnit unit) throws InterruptedException {
idleThreadCount.incrementAndGet();
Object poll = super.poll(timeout, unit);
idleThreadCount.decrementAndGet();
return poll;
}
通过上述我们对offer、pool、take方法的重写,使得在没有基于核心池的空闲线程进行扩展非核心线程,还未结束,若达到了最大池大小,此时我们需要将其添加到阻塞队列中排队,所以最终使用我们自定义的阻塞队列,并使用自定义的拒绝策略,如下:
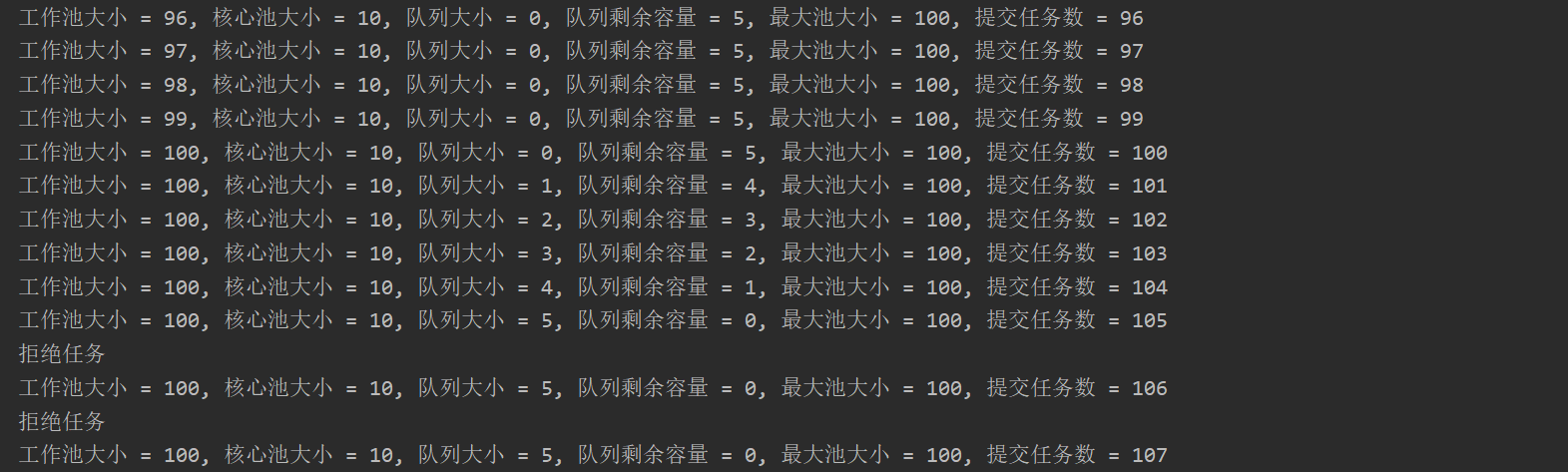
CustomArrayBlockingQueue<Runnable> arrayBlockingQueue = new CustomArrayBlockingQueue<>(5); ThreadPoolExecutor poolExecutor =
new ThreadPoolExecutor(10,
100, Long.MAX_VALUE, TimeUnit.NANOSECONDS, arrayBlockingQueue
, Executors.defaultThreadFactory(), (r, executor) -> {
if (!executor.getQueue().add(r)) {
System.out.println("拒绝任务");
}
}); for (int i = 0; i < 150; i++) {
try {
poolExecutor.execute(new Task());
} catch (RejectedExecutionException ex) {
System.out.println("拒绝任务 = " + (i + 1));
}
printStatus(i + 1, poolExecutor);
}
上述我们实现自定义的拒绝策略,将拒绝的任务放入到阻塞队列中,若阻塞队列已满而不能再接收新的任务,我们将调用默认的拒绝策略或者是其他处理程序,所以在将任务添加到阻塞队列中即调用add方法时,我们还需要重写add方法,如下:
@Override
public boolean add(Object o) {
return super.offer(o);
}
总结
以上详细内容只是针对线程池的默认实现而引发的思考,通过如上方式是否能够对于规模化的任务处理起来在性能上有一定改善呢?可能也有思虑不周全的地方,暂且分析于此。
Java入门系列之线程池ThreadPoolExecutor原理分析思考(十五)的更多相关文章
- Java 线程池(ThreadPoolExecutor)原理分析与使用
在我们的开发中"池"的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 使用线程池的好处 1.降低资源消耗 可以重复利用 ...
- Java线程池(ThreadPoolExecutor)原理分析与使用
在我们的开发中"池"的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 使用线程池的好处 1.降低资源消耗 可以重复利用 ...
- Java并发包中线程池ThreadPoolExecutor原理探究
一.线程池简介 线程池的使用主要是解决两个问题:①当执行大量异步任务的时候线程池能够提供更好的性能,在不使用线程池时候,每当需要执行异步任务的时候直接new一个线程来运行的话,线程的创建和销毁都是需要 ...
- Java 线程池(ThreadPoolExecutor)原理分析与实际运用
在我们的开发中"池"的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 有关java线程技术文章还可以推荐阅读:< ...
- Java入门系列之集合HashMap源码分析(十四)
前言 我们知道在Java 8中对于HashMap引入了红黑树从而提高操作性能,由于在上一节我们已经通过图解方式分析了红黑树原理,所以在接下来我们将更多精力投入到解析原理而不是算法本身,HashMap在 ...
- Java多线程系列--“JUC线程池”02之 线程池原理(一)
概要 在上一章"Java多线程系列--“JUC线程池”01之 线程池架构"中,我们了解了线程池的架构.线程池的实现类是ThreadPoolExecutor类.本章,我们通过分析Th ...
- Java多线程系列--“JUC线程池”03之 线程池原理(二)
概要 在前面一章"Java多线程系列--“JUC线程池”02之 线程池原理(一)"中介绍了线程池的数据结构,本章会通过分析线程池的源码,对线程池进行说明.内容包括:线程池示例参考代 ...
- Java多线程系列--“JUC线程池”04之 线程池原理(三)
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3509960.html 本章介绍线程池的生命周期.在"Java多线程系列--“基础篇”01之 基 ...
- Java多线程系列--“JUC线程池”05之 线程池原理(四)
概要 本章介绍线程池的拒绝策略.内容包括:拒绝策略介绍拒绝策略对比和示例 转载请注明出处:http://www.cnblogs.com/skywang12345/p/3512947.html 拒绝策略 ...
随机推荐
- JavaScript 模式》读书笔记(3)— 字面量和构造函数2
上一篇啊,我们聊了聊字面量对象和自定义构造函数.这一篇,我们继续,来聊聊new和数组字面量. 三.强制使用new的模式 要知道,构造函数,只是一个普通的函数,只不过它却是以new的方式调用.如果在调用 ...
- Django路由层与视图层、pycharm虚拟环境
一. Django路由层 路由层即对应项目文件下的urls.py文件.实际上每个APP中也可以有自己的urls.py路由层.templates文件夹及static文件夹.Django支持这么做,也为实 ...
- vscode 配置c++记录
c_cpp_properties.json { "configurations": [ { "name": "MinGW", "i ...
- link与@import区别整理,一个表格带你了解
网上有许多link和@import的文章,不过大多比较零散,个人觉得一个表格的话看起来能够直观的表达. 于是制作了如下表格: 关于权重这个存在着一些争议,这次碰巧看到了一篇的博客很好的解释了这个问题, ...
- [POJ1190]生日蛋糕<DFS>
题目链接:http://poj.org/problem?id=1190 题看上去确实很复杂 涉及到半径面积这些,其实看着真的很头疼 但是除去这些就是剪枝优化的dfs算法 #include<cst ...
- centos7 编译安装mysql5.7
mysql源码可以到官网下载 安装依赖包 yum -y install gcc gcc-c++ ncurses ncurses-devel bison libgcrypt perl make cmak ...
- coderforces Gym 100803A/Aizu 1345/CSU 1536/UVALive 6832 Bit String Reordering(贪心证明缺)
Portal: http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=1345 http://codeforces.com/gym/100 ...
- Web 环境设置
修改最大打开文件数量 ulimit -n 100000 修改创建文件的最大值 #/etc/security/limits.conf * soft nofile 262140 * hard nofile ...
- H - 覆盖的面积(线段树-线段扫描 + 离散化(板题))
给定平面上若干矩形,求出被这些矩形覆盖过至少两次的区域的面积. Input 输入数据的第一行是一个正整数T(1<=T<=100),代表测试数据的数量.每个测试数据的第一行是一个正整数N(1 ...
- linux硬件资源问题排查:cpu负载、内存使用情况、磁盘空间、磁盘IO
在使用过程中之前正常的功能,突然无法使用,性能变慢,通常都是资源消耗问题,资源消耗可以从以下几个方面去排查.对于已经安装硬件资源监控软件(zabbix)的环境,直接使用硬件资源监控软件(zabbix) ...