Elasticsearch、Solr、Lucene、Hermes区别
Elasticsearch简介
Elasticsearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错(did-you-mean)等搜索建议功能。
英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
Github使用Elasticsearch检索1300亿行的代码。
但是Elasticsearch不仅用于大型企业,它还让像DataDog以及Klout这样的创业公司将最初的想法变成可扩展的解决方案。Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据 。
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Solr简介
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
Lucene简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene是一个全文检索引擎的架构。那什么是全文搜索引擎?
全文搜索引擎是名副其实的搜索引擎,国外具代表性的有Google、Fast/AllTheWeb、AltaVista、Inktomi、Teoma、WiseNut等,国内著名的有百度(Baidu)。它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户,因此他们是真正的搜索引擎。
从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据库中调用,如上面提到的7家引擎;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如Lycos引擎。
Elasticsearch和Solr比较
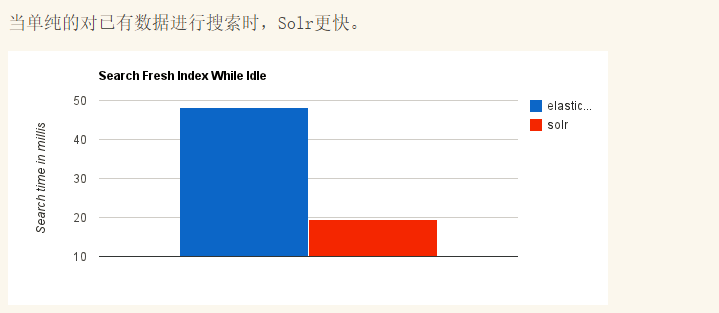
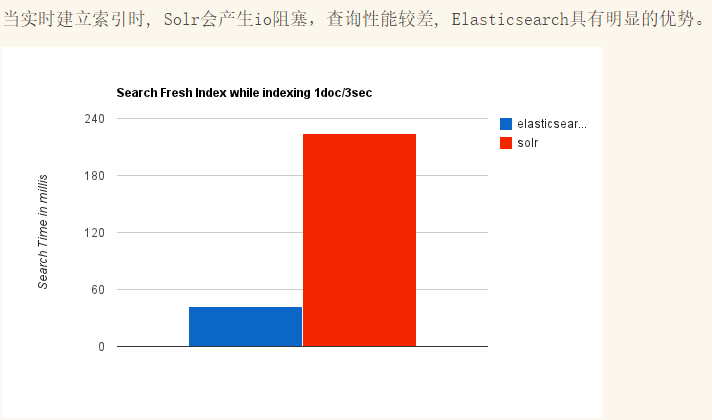


ElasticSearch vs Solr 总结
(1)es基本是开箱即用,非常简单。Solr安装略微复杂一丢丢,可关注(solr6.6教程-基础环境搭建(一))
(2)Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
(3)Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
(4)Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
(5)Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
(6)Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
Hermes
在整理solr和es资料的时候意外发现了一篇文章Hermes与开源的Solr、ElasticSearch的不同,中提到了hermes和他们两者的对比,于是摘抄了下面的部分文字,由于首次见到没有什么了解,今摘抄下了给广大读者有兴趣的朋友吧1
Solr\ES :偏重于为小规模的数据提供全文检索服务;Hermes:则更倾向于为大规模的数据仓库提供索引支持,为大规模数据仓库提供即席分析的解决方案,并降低数据仓库的成本,Hermes数据量更“大”。
Solr、ES的使用特点如下:
1. 源自搜索引擎,侧重搜索与全文检索。
2. 数据规模从几百万到千万不等,数据量过亿的集群特别少。
Hermes:的使用特点如下:
1. 一个基于大索引技术的海量数据实时检索分析平台。侧重数据分析。
2. 数据规模从几亿到万亿不等。最小的表也是千万级别。在腾讯17 台TS5机器,就可以处理每天450亿的数据(每条数据1kb左右),数据可以保存一个月之久。
转:https://www.cnblogs.com/blueskyli/p/8326229.html
Elasticsearch、Solr、Lucene、Hermes区别的更多相关文章
- 全文索引Elasticsearch,Solr,Lucene
最近项目组安排了一个任务,项目中用到了全文搜索,基于全文搜索 Solr,但是该 Solr 搜索云项目不稳定,经常查询不出来数据,需要手动全量同步,而且是其他团队在维护,依赖性太强,导致 Solr 服务 ...
- ElasticSearch vs Lucene多维度分析对比
ElasticSearch vs Lucene的关系,简单一句话就是,成品与半成品的关系. (1)Lucene专注于搜索底层的建设,而ElasticSearch专注于企业应用. (2)Luncen ...
- Solr和Lucene的区别?
1.Lucene 是工具包 是jar包 2.Solr是索引引擎服务 War 3.Solr是基于Lucene(底层是由Lucene写的) 4.上面二个软件都是Apache公司由java写的 5.Luc ...
- Solr与Lucene的区别
Lucene是一个优秀的开源搜索库,Solr是在Lucene上封装的完善的搜索引擎.通俗地说,如果Solr是汽车,那么Lucene就是发动机,没有发动机,汽车就没法运转,但对于用户来说只可开车,不能开 ...
- ElasticSearch:Lucene和ElasticSearch
Lucene的概念: 关于索引 索引(index)和搜索(搜索),在lucene以及es里面索引是一个动作,即插入动作,包括创建索引以及为索引添加文档:所有则是针对索引(添加)的文档按照评分规则进行查 ...
- SOLR+LUCENE错误
java.lang.NoClassDefFoundError: org/apache/lucene/analysis/synonym/SynonymFilter 该错误发生在自定义SOLR服务器时,原 ...
- elasticsearch(lucene)索引数据过程
倒排索引存储-分段存储(lucene的功能)在lucene中:lucene index包含了若干个segment在elasticsearch中:index包含了若干主从shard,shard包干了若干 ...
- elasticsearch term match multi_match区别
转自:http://www.cnblogs.com/yjf512/p/4897294.html match 最简单的一个match例子: 查询和"我的宝马多少马力"这个查询语句匹配 ...
- ElasticSearch match, match_phrase, term区别
1.term结构化字段查询,匹配一个值,且输入的值不会被分词器分词. 比如查询条件是: { "query":{ "term":{ "foo" ...
随机推荐
- Java IO(十七)FIleReader 和 FileWriter
Java IO(十七)FIleReader 和 FileWriter 一.介绍 FIleReader 和 FileWriter 是读写字符文件的便利类,分别继承于 InputStreamReader ...
- Java IO(二)File
Java IO(二)File 一.概述 在 Java 中,File 类是 java.io 包中唯一代表磁盘文件本身的对象,也就是说,如果希望在程序中操作文件和目录,则都可以通过 File 类来完成.F ...
- Codeforces Round #635 (Div. 2)部分(A~E)题解
虽然打的是div1,但最后半小时完全处于挂机状态,不会做1C,只有个 \(O(n^3)\) 的想法,水了水论坛,甚至看了一下div2的AB,所以干脆顺便写个div2的题解吧,内容看上去还丰富一些(X) ...
- 前端HTML div标签的用法 盒子模型
盒子模型 边框 border -外边距 margin- 内容与边框距离padding[会撑大div边框]- 宽width-高height. div的奇特玩法 1.把div弄成圆形 [css设置bord ...
- JUC : 并发编程工具类的使用
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.JUC是什么 1.JUC定义 JUC,即java.util.concurrent 在并发编程中使用的 ...
- Java实现 LeetCode 659 分割数组为连续子序列 (哈希)
659. 分割数组为连续子序列 输入一个按升序排序的整数数组(可能包含重复数字),你需要将它们分割成几个子序列,其中每个子序列至少包含三个连续整数.返回你是否能做出这样的分割? 示例 1: 输入: [ ...
- Java实现第十届蓝桥杯最大降雨量
试题 E: 最大降雨量 本题总分:15 分 [问题描述] 由于沙之国长年干旱,法师小明准备施展自己的一个神秘法术来求雨. 这个法术需要用到他手中的 49 张法术符,上面分别写着 1 至 49 这 49 ...
- Java实现第九届蓝桥杯分数
分数 题目描述 1/1 + 1/2 + 1/4 + 1/8 + 1/16 + - 每项是前一项的一半,如果一共有20项, 求这个和是多少,结果用分数表示出来. 类似: 3/2 当然,这只是加了前2项而 ...
- Python中map和reduce函数
①从参数方面来讲: map()函数: map()包含两个参数,第一个是参数是一个函数,第二个是序列(列表或元组).其中,函数(即map的第一个参数位置的函数)可以接收一个或多个参数. reduce() ...
- 00-04.kaliLinux-手动配置IP地址
在KaliLinux中手动配置网卡 用vim打开网卡的配置文件,配置各个网卡信息 root@kali:~# cd /etc/network root@kali:/etc/network# ------ ...