K-means聚类分析
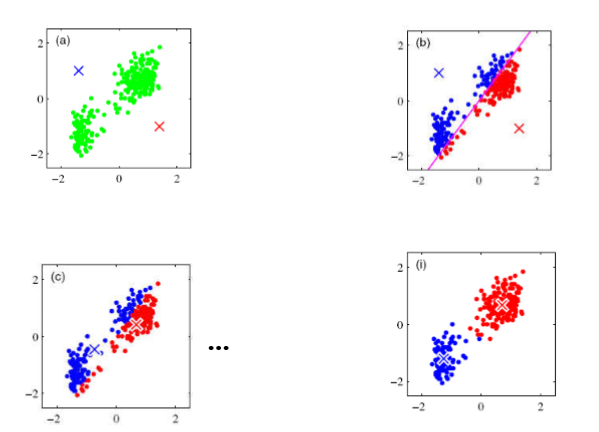
一、原理
- 先确定簇的个数,K
- 假设每个簇都有一个中心点 centroid
- 将每个样本点划分到距离它最近的中心点所属的簇中
选择K个点做为初始的中心点
while()
{
将所有点分配个K个中心点形成K个簇
重新计算每个簇的中心点
if(簇的中心点不再改变)
break;
}
- 目标函数:定义为每个样本与其簇中心点的距离的 平方和(theSum of Squared Error, SSE)
– μk 表示簇Ck 的中心点(或其它能代表Ck的点)
– 若xn被划分到簇Ck则rnk=1,否则rnk= 0
• 目标:找到簇的中心点μk及簇的划分rnk使得目标 函数SSE最小

- 初始中心点通常是随机选取的(收敛后得到的是局部最优解)
不同的中心点会对聚类结果产生不同的影响:
1、
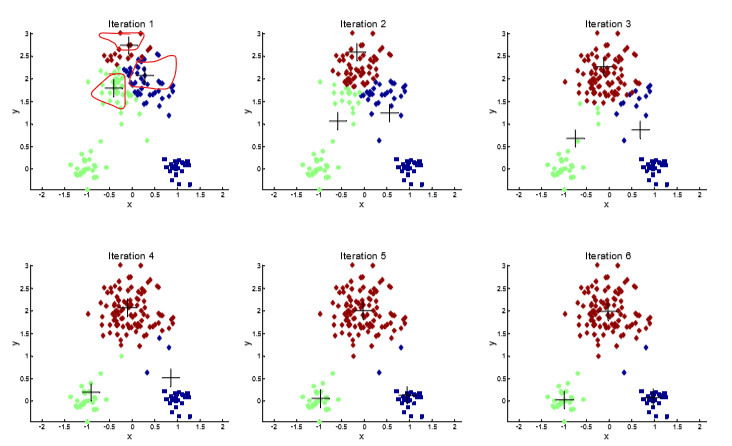
2、
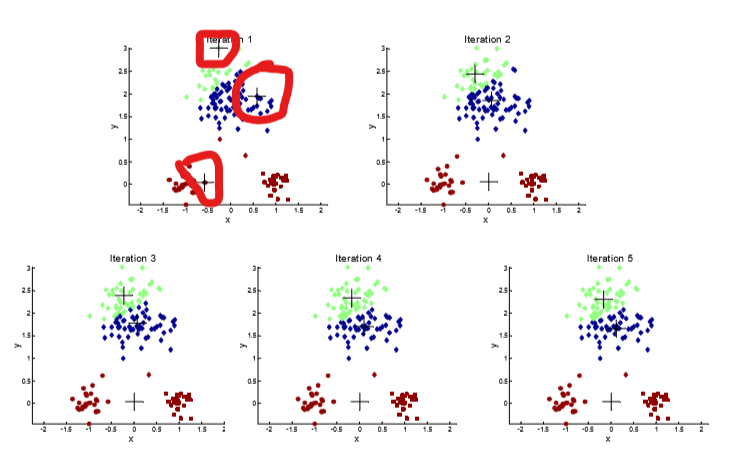
此时你一定会有疑问:如何选取"较好的"初始中心点?
- 凭经验选取代表点
- 将全部数据随机分成c类,计算每类重心座位初始点
- 用“密度”法选择代表点
- 将样本随机排序后使用前c个点作为代表点
- 从(c-1)聚类划分问题的解中产生c聚类划分问题的代表点
结论:若对数据不够了解,可以直接选择2和4方法
- 需要预先确定K
Q:如何选取K
SSE一般随着K的增大而减小
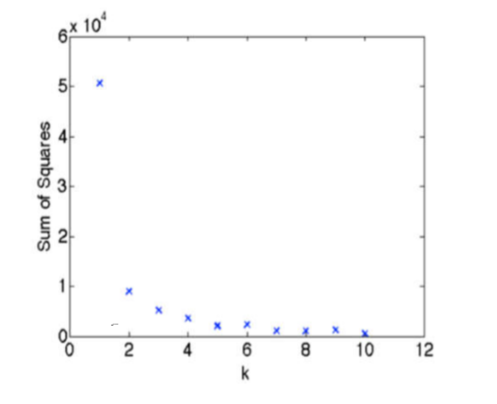
A:emmm你多尝试几次吧,看看哪个合适。斜率改变最大的点比如k=2
总结:
简单的来说,K-means就是假设有K个簇,然后通过上面找初始点的方法,找到K个初始点,将所有的数据分为K个簇,然后一直迭代,在所有的簇里面找到找到簇的中心点μk及簇的划分rnk使得目标函数SSE最小或者中心点不变之后,迭代完成。成功把数据分为K类。
预告:下一篇博文讲K-means代码实现
K-means聚类分析的更多相关文章
- SPSS聚类分析:K均值聚类分析
SPSS聚类分析:K均值聚类分析 一.概念:(分析-分类-K均值聚类) 1.此过程使用可以处理大量个案的算法,根据选定的特征尝试对相对均一的个案组进行标识.不过,该算法要求您指定聚类的个数.如果知道, ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- R 语言实战-Part 5-1笔记
R 语言实战(第二版) part 5-1 技能拓展 ----------第19章 使用ggplot2进行高级绘图------------------------- #R的四种图形系统: #①base: ...
- Python使用RMF聚类分析客户价值
投资机构或电商企业等积累的客户交易数据繁杂.需要根据用户的以往消费记录分析出不同用户群体的特征与价值,再针对不同群体提供不同的营销策略. 用户分析指标 根据美国数据库营销研究所Arthur Hughe ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- SPSS与聚类分析
1.进行K均值聚类分析时需要线标准化处理,抛弃量纲差异,比如说数值型变量有的以千记有的以百分数记.2.层次聚类就是先把每个样本都看成一个独立的类:聚类特征(Clustering Feature, CF ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- numpy.ones_like(a, dtype=None, order='K', subok=True)返回和原矩阵一样形状的1矩阵
Return an array of ones with the same shape and type as a given array. Parameters: a : array_like Th ...
- R数据挖掘 第一篇:聚类分析(划分)
聚类是把一个数据集划分成多个子集的过程,每一个子集称作一个簇(Cluster),聚类使得簇内的对象具有很高的相似性,但与其他簇中的对象很不相似,由聚类分析产生的簇的集合称作一个聚类.在相同的数据集上, ...
随机推荐
- IoTClientTool自动升级更新
IoTClientTool是什么 IoTClientTool是什么,IoTClientTool是IoTClient开源组件的可视化操的作实现.方便对plc设备和ModBusRtu.BACnet.串口等 ...
- SSM整合案例:图书管理系统
目录 SSM整合案例:图书管理系统 1.搭建数据库环境 2.基本环境搭建 2.1.新建一个Maven项目,起名为:ssmbuild,添加web的支持 2.2.导入pom的相关依赖 2.3.Maven静 ...
- mac下xampp访问php显示403错误
错误描述 New xampp security concept: Access Forbidden Error 403 错误分析和解决 403就是我们访问的时候,被安全策略拒绝了,解决方法 找到文件 ...
- LeetCode--LinkedList--203. Remove Linked List Elements(Easy)
203. Remove Linked List Elements(Easy) 题目地址https://leetcode.com/problems/remove-linked-list-elements ...
- Linux内核驱动学习(八)GPIO驱动模拟输出PWM
文章目录 前言 原理图 IO模拟输出PWM 设备树 驱动端 调试信息 实验结果 附录 前言 上一篇的学习中介绍了如何在用户空间直接操作GPIO,并写了一个脚本可以产生PWM.本篇的学习会将写一个驱动操 ...
- nexus 启用ldap认证
使用自己搭建的openldap 使用用户中心的openldap 修改完后,重启服务 # cd /opt/sonarqube-6.7.3/bin/linux-x86-64/ && ./s ...
- vue学习-第三个DEMO(计算属性和监视) v-model基础用法
<div id="demo"> 姓:<input type="text" placeholder="First Name" ...
- 3.7 Go指针
1. Go指针 每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置. Go 语言中使用&作符放在变量前面对变量进行“取地址”操作. 1.指针默认值nil 2.通过&(取地值 ...
- element-ui的el-table和el-form嵌套使用表单校验
表格中嵌套使用表单验证 表格是el-table自动获取的后台数据,每行都有el-input的验证,这样一个rules的规则就不能匹配到每一行,所以要是用动态的prop和rules规则 需求如下,要对告 ...
- 从无到有Springboot整合Spring-data-jpa实现简单应用
本文介绍Springboot整合Spring-data-jpa实现简单应用 Spring-data-jpa是什么?这不由得我们思考一番,其实通俗来说Spring-data-jpa默认使用hiberna ...