数据分析_numpy_基础2
数据分析_numpy_基础2
sqrt 开方
arr = np.arange(10)
arr # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.sqrt(arr)
###############
array([0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])
exp e的幂次方
e的幂次方,e是一个常数为2.71828
arr = np.arange(10)
np.exp(arr)
###############
array([1.00000000e+00, 2.71828183e+00, 7.38905610e+00, 2.00855369e+01,
5.45981500e+01, 1.48413159e+02, 4.03428793e+02, 1.09663316e+03,
2.98095799e+03, 8.10308393e+03])
maximum 取最大
# 取最大
a = np.random.randn(8)
b = np.random.randn(8)
print(a)
print(b)
np.maximum(a,b)
###############
[ 0.85228538 1.97016707 0.42150124 -0.36300513 -1.14605012 0.56155395
0.25129545 -0.379637 ]
[-0.69127043 1.49033843 -0.71327372 -1.40685882 -1.38443997 0.09179302
-0.19740235 -1.01923785]
array([ 0.85228538, 1.97016707, 0.42150124, -0.36300513, -1.14605012,
0.56155395, 0.25129545, -0.379637 ])
modf 分离小数和整数部分
arr = np.random.randn(7)*5
print(arr)
np.modf(arr)
###############
[ 0.82479112 -9.04717881 5.80702178 5.63267183 0.05189789 -7.89850539
4.11234958]
(array([ 0.82479112, -0.04717881, 0.80702178, 0.63267183, 0.05189789,
-0.89850539, 0.11234958]), array([ 0., -9., 5., 5., 0., -7., 4.]))
#生成1000个数据
points = np.arange(-5,5,0.01)
# print(points)
# 转成二维
xs, ys = np.meshgrid(points,points)
xs.shape
print(xs,xs.shape)
print(ys,ys.shape)
z = np.sqrt(xs**2+ys**2)
z
###############
[[-5. -4.99 -4.98 ... 4.97 4.98 4.99]
[-5. -4.99 -4.98 ... 4.97 4.98 4.99]
[-5. -4.99 -4.98 ... 4.97 4.98 4.99]
...
[-5. -4.99 -4.98 ... 4.97 4.98 4.99]
[-5. -4.99 -4.98 ... 4.97 4.98 4.99]
[-5. -4.99 -4.98 ... 4.97 4.98 4.99]] (1000, 1000)
[[-5. -5. -5. ... -5. -5. -5. ]
[-4.99 -4.99 -4.99 ... -4.99 -4.99 -4.99]
[-4.98 -4.98 -4.98 ... -4.98 -4.98 -4.98]
...
[ 4.97 4.97 4.97 ... 4.97 4.97 4.97]
[ 4.98 4.98 4.98 ... 4.98 4.98 4.98]
[ 4.99 4.99 4.99 ... 4.99 4.99 4.99]] (1000, 1000)

where 将条件逻辑表述为数组运算
# 将条件逻辑表述为数组运算
xarr = np.arange(1,6)*0.1+1
yarr = np.arange(1,6)*0.1+2
cond = np.array([1,0,1,1,0])
# 当cond中的值为True时,选取xarr的值,否则从yarr中选取
np.where(cond,xarr,yarr)
###############
array([1.1, 2.2, 1.3, 1.4, 2.5])
假设有一个由随机数据组成的矩阵,你希望将所有正值替换为2,将所有负值替换为-2
arr = np.random.randn(4,4)
print(arr)
print(arr > 0)
np.where(arr>0,2,-2) 结果一样
###############
[[-0.54610079 -1.05767612 -1.01828345 -0.86101887]
[-0.27741771 0.89109665 0.05494077 0.30950575]
[ 0.19986644 0.7114658 0.18654865 0.51397356]
[-1.11511449 -0.22895058 -1.22898344 -1.86394091]]
[[False False False False]
[False True True True]
[ True True True True]
[False False False False]]
[[-2. -2. -2. -2.]
[-2. 2. 2. 2.]
[ 2. 2. 2. 2.]
[-2. -2. -2. -2.]]
数学和统计方方法
可以通过数组上的一一组数学函数对整个数组或某个轴向的数据进行行行统计计算。sum、mean以及标准差std等聚合计算(aggregation,通常叫做约简(reduction))
mean 求平均值
arr.mean(1)是“计算行的平均值”
sum 求和
arr.sum(0)是“计算每列的和”
arr = np.arange(10).reshape(2,5)
print(arr)
print(arr.mean())
print(arr.sum())
###############
[[0 1 2 3 4]
[5 6 7 8 9]]
4.5
45
cumsum 累积和
所有元素的累积和
arr = np.arange(9).reshape(3,3)
# 列加
print(arr.cumsum(axis=0))
# 行加
print(arr.cumsum(axis=1))
# 累加
print(arr.cumsum())
###############
[[ 0 1 2]
[ 3 5 7]
[ 9 12 15]]
[[ 0 1 3]
[ 3 7 12]
[ 6 13 21]]
[ 0 1 3 6 10 15 21 28 36]
Boolean 求和 (arr>0).sum()
统计符合条件的数目
# 用用于布尔型数组的方方法
arr = np.random.randn(100)
(arr>0).sum()
###############
56
Boolean any() 判断array中有True
Boolean all()判断array中是不是全是True
# any用用于测试数组中是否存在一个或多个True,而而all则检查数组中所有值是否都是True, 这两个 方法也能用用于非非布尔型数组,所有非非0元素将会被当做True
bools = np.array([False,True,False,False])
print(bools.any())
print(bools.all())
###############
True
False
sort 排序
顶级方方法np.sort返回的是数组的已排序副本,而就地排序则会修改数组本身
arr = np.random.randn(6)
print(arr)
# 从小到大
arr.sort()
arr
###############
[-1.04718671 1.22510949 -1.6441873 0.95095345 0.71862062 0.17306216]
array([-1.6441873 , -1.04718671, 0.17306216, 0.71862062, 0.95095345,
1.22510949])
sort 多维数组任一轴排序
多维数组可以在任何一个轴向上进行行行排序
顶级方方法np.sort返回的是数组的已排序副本,而就地排序则会修改数组本身
arr = np.random.randn(5,3)
print(arr)
# 从小到大 1 轴
arr.sort(1)
print(arr)
# 从小到大 0 轴
arr.sort(0)
print(arr)
###############
[[ 1.17254835 -0.86920954 -0.07445568]
[ 0.1045885 0.56492704 -0.24095239]
[-0.24405566 0.50114349 0.63202603]
[ 0.81669178 0.74370167 1.56135813]
[ 1.33049254 1.63408223 -1.50942967]]
[[-0.86920954 -0.07445568 1.17254835]
[-0.24095239 0.1045885 0.56492704]
[-0.24405566 0.50114349 0.63202603]
[ 0.74370167 0.81669178 1.56135813]
[-1.50942967 1.33049254 1.63408223]]
[[-1.50942967 -0.07445568 0.56492704]
[-0.86920954 0.1045885 0.63202603]
[-0.24405566 0.50114349 1.17254835]
[-0.24095239 0.81669178 1.56135813]
[ 0.74370167 1.33049254 1.63408223]]
unique 去重
找出数组中的唯一值并返回已排序的结果
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
print(np.unique(names))
ints = np.array([3, 3, 3, 2, 2, 1, 1, 4, 4])
print(np.unique(ints))
###############
['Bob' 'Joe' 'Will']
[1 2 3 4]
in1d 检查a中有没有b
注意: 是in一d 不是L
相当于Python in
用于测试一个数组中的值在另一个数组中的成员资格
返回一个布尔型数组
values = np.array([6, 0, 0, 3, 2, 5, 6])
print(np.in1d(values,[5,6]))
s = '我爱你中国'
print(np.in1d(list(s),['中','国']))
###############
[ True False False False False True True]
[False False False True True]
save 数组保存到文件
load 从文件中读数组
用于数组的文件输入输出
NumPy的内置二进制格式读写
np.save和np.load是读写磁盘数组数据的两个主要函数。默认情况下,数组是以未压缩的原始
二进制格式保存在扩展名为.npy的文文件中的
arr = np.arange(10)
np.save('arr_tmp',arr)
np.load('arr_tmp.npy')
###############
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
savez多个数组输出到文件
# 通过np.savez可以将多个数组保存到一一个未压缩文文件中
np.savez('arr_tmp',arr,arr)
# np.savez('arr_tmp',a=arr,b=arr)
arch = np.load('arr_tmp.npz')
for i in arch:
print(i)
np.savez('arr_tmp',a=arr,b=arr)
arch = np.load('arr_tmp.npz')
for i in arch:
print(i)
for i in arch:
print(arch[i])
###############
arr_0
arr_1
a
b
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
savez_compressed 数组 数据压缩 输出到文件
将数据压缩,可以使用用numpy.savez_compressed
np.savez_compressed('arr_tmp',a=arr,b=arr)
arch = np.load('arr_tmp.npz')
for i in arch:
print(arch[i])
###############
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
dot 矩阵乘法
多维乘多维
x = np.arange(1,7).reshape(3,2)
y = np.arange(1,7).reshape(2,3)
print(x)
print(y)
print(x.dot(y))
x = np.arange(1,5).reshape(2,2)
y = np.arange(1,5).reshape(2,2)
print(x)
print(y)
x.dot(y)
###############
[[1 2]
[3 4]
[5 6]]
[[1 2 3]
[4 5 6]]
[[ 9 12 15]
[19 26 33]
[29 40 51]]
[[1 2]
[3 4]]
[[1 2]
[3 4]]
array([[ 7, 10],
[15, 22]])
# 7 = 1*1 + 2*3
# 10 = 1*2 + 2*4
# 15 = 3*1 + 3*4
# 22 = 3*2 + 4*4
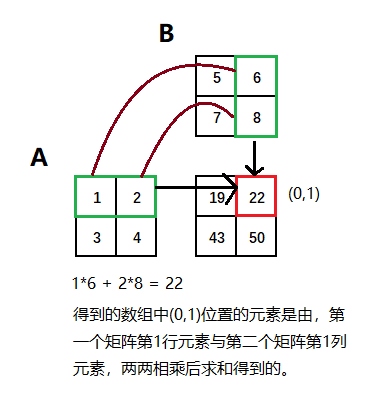
多维乘一维
@符矩阵乘法
# 一个二维数组跟一个大小合适的一维数组的矩阵点积运算之后将会得到一个一维数组
x = np.arange(1,7).reshape(2,3)
print(x)
y = np.array([2,2,2])
print(y)
print(np.dot(x,y))
# 12 = 1*2+2*2+3*2
# @符也可以用用作中缀运算符,进行矩阵乘法
x @ y
###############
[[1 2 3]
[4 5 6]]
[2 2 2]
[12 30]
array([12, 30])
random伪随机数生成
numpy.random函数(部分)
| 函数 | 说明 |
|---|---|
| seed | 确定随机数生成器的种子 |
| permutation | (打乱顺序)返回一个序列的随机排列或返回一个随机排列的范围 |
| shuffle | (打乱顺序)对一个序列就地随机排序 |
| rand | 产生均匀分布的样本值 |
| randint | 从给定上下范围内随机选取整数 |
| randn | 产生正态分布(平均值为零,标准差为1)的样本值 |
| binomial | 产生二项分布的样本值 |
| normal | 产生正态(高斯)分布的样本值 |
| beta | 产生Bate分布的样本值 |
| chisquare | 产生卡方分布的样本值 |
| gamma | 产生Gamma分布的样本值 |
| uniform | 产生[0,1]中均匀分布的样本值 |
numpy.random和py random性能比较
# 用用normal来得到一一个标准正态分布的4×4样本数
samples = np.random.normal(size=(4,4))
print(samples)
from random import normalvariate
N = 1000000
%timeit samples = [normalvariate(0, 1) for _ in range(N)]
%timeit np.random.normal(size=N)
###############
[[ 0.94167052 0.05689129 -2.67972024 0.29580882]
[-0.81439042 -0.19358061 0.45406157 -0.98315377]
[-0.92666199 0.75788726 0.99233796 -0.67953378]
[-0.08530308 0.98250136 -0.21396473 0.23257401]]
893 ms ± 54.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
43.7 ms ± 311 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
# Python内置的random模块则只能一次生生成一个样本值。从上面的测试结果中可以看出,如果 需要产生大量样本值,numpy.random快了不止一个数量量级
示例:随机漫步
draws = np.random.randint(0,2,size=10)
print(draws)
steps = np.where(draws>0,1,-1)
print(steps)
walk = steps.cumsum()
print(walk)
print(walk.min())
print(walk.max())
###############
[0 0 0 1 1 1 1 0 0 0]
[-1 -1 -1 1 1 1 1 -1 -1 -1]
[-1 -2 -3 -2 -1 0 1 0 -1 -2]
-3
1
数据分析_numpy_基础2的更多相关文章
- 数据分析_numpy_基础1
数据分析_numpy_基础1 创建数组 方法 说明 np.array( x ) 将输入数据转化为一个ndarray| np.array( x, dtype ) 将输入数据转化为一个类型为type的nd ...
- 利用Python进行数据分析_Numpy_基础_3
通用函数:快速的元素级数组函数 通用函数,是指对数组中的数据执行元素级运算的函数:接受一个或多个标量值,并产生一个或多个标量值. sqrt 求平方根 np.sqrt(arr) exp 计算各元素指数 ...
- 利用Python进行数据分析_Numpy_基础_2
Numpy数据类型包括: int8.uint8.int16.uint16.int32.uint32.int64.uint64.float16.float32.float64.float128.co ...
- 利用Python进行数据分析_Numpy_基础_1
ndarray:多维数组 ndarray 每个数组元素必须是相同类型,每个数组都有shape和dtype对象. shape 表示数组大小 dtype 表示数组数据类型 array 如何创建一个数组? ...
- 利用Python进行数据分析——Numpy基础:数组和矢量计算
利用Python进行数据分析--Numpy基础:数组和矢量计算 ndarry,一个具有矢量运算和复杂广播能力快速节省空间的多维数组 对整组数据进行快速运算的标准数学函数,无需for-loop 用于读写 ...
- 数据分析——python基础
前言:python数据分析的基础知识,简单总结,主要是为了方便自己写的时候查看(你们可能看不太清楚T^T),发现有用的方法,随时补充,欢迎指正 数据分析专栏: 数据分析--python基础 数据分析- ...
- Python数据分析——numpy基础简介
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:基因学苑 NumPy(Numerical Python的简称)是高性 ...
- Python数据分析(基础)
目录: Python基础: Python基本用法:控制语句.函数.文件读写等 Python基本数据结构:字典.集合等 Numpy:简述 Pandas:简述 一. Python基础: 1.1 文件读取 ...
- python数据分析 Numpy基础 数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
随机推荐
- PHP压缩文件夹 php
$path = PUBLIC_DIR.'/images/'; //待压缩文件夹父目录 $zipPath = PUBLIC_DIR.'/images_zip/'; //压缩文件保存目录 !is_dir( ...
- 使用web写UI, 使用js对接C++项目, 提高开发效率
ppt资源下载地址https://www.slidestalk.com/s/webui_nodejs_cmdlrx
- Python - 字符串格式化详解(%、format)
Python在字符串格式化的两种方式 % format %,关于整数的输出 %o:oct 八进制%d:dec 十进制%x:hex 十六进制 print("整数:%d,%d,%d" ...
- vue 带参数的跳转-完成一个功能之后 之后需要深思,否则还会忘记
我要写详细点,否则下次很容易忘记 写了一个页面,这个页面里面添加了 很多a 标签,跳转都是同一个页面,内容不一样,方法 首先 路由 设定好 routes:[ { path:'/aaa', name:' ...
- 用户HTTP请求过程简单剖析
用户终端(如电脑浏览器)发起某个url请求,如http://www.baidu.com/1.jpg. 1.电脑首先会对www.baidu.com进行解析请求,获得域名对应的服务器IP. 2.电脑对服务 ...
- IOS 项目release版本中关闭NSlog的打印
在-Prefix.pch文件中添加如下代码: #ifdef DEBUG #define NSLog(...) NSLog(__VA_ARGS__) #define debugMethod() NSLo ...
- flask blueprint出现的坑
from flask import Blueprint admin = Blueprint('admin',__name__) def init_bule(app): app.register_blu ...
- linux php 安装libiconv过程与总结
问题:在嵌入式linux 已经安装好的php的情景下,需要安装一个扩展库libiconv 背景:从后台传的数据含有中文(gbk2312)的通过json_encode 显示为null,查阅资料发现jso ...
- created:异步初始化数据都应该放到 created里面
created:异步初始化数据都应该放到 created里面
- 详解如何实现斗鱼、B站等全局悬浮窗直播小窗口
最近业务需求需要我们直播返回或者退出直播间时,开一个小窗口在全局继续直播视频,先看效果图. 调研了一下当下主流直播平台,斗鱼.BiliBili等app,都是用WindowManger做的(这个你可以在 ...