【转】深入 ProtoBuf - 简介
之前在网络通信和通用数据交换等应用场景中经常使用的技术是 JSON 或 XML,而在最近的开发中接触到了 Google 的 ProtoBuf。
在查阅相关资料学习 ProtoBuf 以及研读其源码之后,发现其在效率、兼容性等方面非常出色。在以后的项目技术选型中,尤其是网络通信、通用数据交换等场景应该会优先选择 ProtoBuf。
自己在学习 ProtoBuf 的过程中翻译了官方的主要文档,一来当然是在学习 ProtoBuf,二来是培养阅读英文文档的能力,三来是因为 Google 的文档?不存在的!
看完这些文档对 ProtoBuf 应该就有相当程度的了解了。
翻译文档见 [索引]文章索引,导航为翻译 - 技术 - ProtoBuf 官方文档。
但是官方文档更多的是作为查阅和权威参考,并不意味着看完官方文档就能立马理解其原理。
本文以及接下来的几篇文章会对 ProtoBuf 的编码、序列化、反序列化、反射等原理做一些详细介绍,同时也会尽量将这些原理表达的更为通俗易懂。
何为 ProtoBuf
我们先来看看官方文档给出的定义和描述:
protocol buffers 是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
Protocol Buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
简单来讲, ProtoBuf 是结构数据序列化[1] 方法,可简单类比于 XML[2],其具有以下特点:
- 语言无关、平台无关。即 ProtoBuf 支持 Java、C++、Python 等多种语言,支持多个平台
- 高效。即比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单
- 扩展性、兼容性好。你可以更新数据结构,而不影响和破坏原有的旧程序
序列化[1]:将结构数据或对象转换成能够被存储和传输(例如网络传输)的格式,同时应当要保证这个序列化结果在之后(可能在另一个计算环境中)能够被重建回原来的结构数据或对象。
更为详尽的介绍可参阅 维基百科。
类比于 XML[2]:这里主要指在数据通信和数据存储应用场景中序列化方面的类比,但个人认为 XML 作为一种扩展标记语言和 ProtoBuf 还是有着本质区别的。
使用 ProtoBuf
对 ProtoBuf 的基本概念有了一定了解之后,我们来看看具体该如何使用 ProtoBuf。
第一步,创建 .proto 文件,定义数据结构,如下例1所示:
// 例1: 在 xxx.proto 文件中定义 Example1 message
message Example1 {
optional string stringVal = 1;
optional bytes bytesVal = 2;
message EmbeddedMessage {
int32 int32Val = 1;
string stringVal = 2;
}
optional EmbeddedMessage embeddedExample1 = 3;
repeated int32 repeatedInt32Val = 4;
repeated string repeatedStringVal = 5;
}
我们在上例中定义了一个名为 Example1 的 消息,语法很简单,message 关键字后跟上消息名称:
message xxx {
}
之后我们在其中定义了 message 具有的字段,形式为:
message xxx {
// 字段规则:required -> 字段只能也必须出现 1 次
// 字段规则:optional -> 字段可出现 0 次或1次
// 字段规则:repeated -> 字段可出现任意多次(包括 0)
// 类型:int32、int64、sint32、sint64、string、32-bit ....
// 字段编号:0 ~ 536870911(除去 19000 到 19999 之间的数字)
字段规则 类型 名称 = 字段编号;
}
在上例中,我们定义了:
- 类型 string,名为 stringVal 的 optional 可选字段,字段编号为 1,此字段可出现 0 或 1 次
- 类型 bytes,名为 bytesVal 的 optional 可选字段,字段编号为 2,此字段可出现 0 或 1 次
- 类型 EmbeddedMessage(自定义的内嵌 message 类型),名为 embeddedExample1 的 optional 可选字段,字段编号为 3,此字段可出现 0 或 1 次
- 类型 int32,名为 repeatedInt32Val 的 repeated 可重复字段,字段编号为 4,此字段可出现 任意多次(包括 0)
- 类型 string,名为 repeatedStringVal 的 repeated 可重复字段,字段编号为 5,此字段可出现 任意多次(包括 0)
关于 proto2 定义 message 消息的更多语法细节,例如具有支持哪些类型,字段编号分配、import
导入定义,reserved 保留字段等知识请参阅 [翻译] ProtoBuf 官方文档(二)- 语法指引(proto2)。
关于定义时的一些规范请参阅 [翻译] ProtoBuf 官方文档(四)- 规范指引
第二步,protoc 编译 .proto 文件生成读写接口
我们在 .proto 文件中定义了数据结构,这些数据结构是面向开发者和业务程序的,并不面向存储和传输。
当需要把这些数据进行存储或传输时,就需要将这些结构数据进行序列化、反序列化以及读写。那么如何实现呢?不用担心, ProtoBuf 将会为我们提供相应的接口代码。如何提供?答案就是通过 protoc 这个编译器。
可通过如下命令生成相应的接口代码:
// $SRC_DIR: .proto 所在的源目录
// --cpp_out: 生成 c++ 代码
// $DST_DIR: 生成代码的目标目录
// xxx.proto: 要针对哪个 proto 文件生成接口代码
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/xxx.proto
最终生成的代码将提供类似如下的接口:


第三步,调用接口实现序列化、反序列化以及读写
针对第一步中例1定义的 message,我们可以调用第二步中生成的接口,实现测试代码如下:
//
// Created by yue on 18-7-21.
//
#include <iostream>
#include <fstream>
#include <string>
#include "single_length_delimited_all.pb.h"
int main() {
Example1 example1;
example1.set_stringval("hello,world");
example1.set_bytesval("are you ok?");
Example1_EmbeddedMessage *embeddedExample2 = new Example1_EmbeddedMessage();
embeddedExample2->set_int32val(1);
embeddedExample2->set_stringval("embeddedInfo");
example1.set_allocated_embeddedexample1(embeddedExample2);
example1.add_repeatedint32val(2);
example1.add_repeatedint32val(3);
example1.add_repeatedstringval("repeated1");
example1.add_repeatedstringval("repeated2");
std::string filename = "single_length_delimited_all_example1_val_result";
std::fstream output(filename, std::ios::out | std::ios::trunc | std::ios::binary);
if (!example1.SerializeToOstream(&output)) {
std::cerr << "Failed to write example1." << std::endl;
exit(-1);
}
return 0;
}
关于 protoc 的使用以及接口调用的更多信息可参阅 [翻译] ProtoBuf 官方文档(九)- (C++开发)教程
关于例1的完整代码请参阅 源码:protobuf 例1。其中的 single_length_delimited_all.* 为例子相关代码和文件。
因为此系列文章重点在于深入 ProtoBuf 的编码、序列化、反射等原理,关于 ProtoBuf 的语法、使用等只做简单介绍,更为详见的使用教程可参阅我翻译的系列官方文档。
关于 ProtoBuf 的一些思考
官方文档以及网上很多文章提到 ProtoBuf 可类比 XML 或 JSON。
那么 ProtoBuf 是否就等同于 XML 和 JSON 呢,它们是否具有完全相同的应用场景呢?
个人认为如果要将 ProtoBuf、XML、JSON 三者放到一起去比较,应该区分两个维度。一个是数据结构化,一个是数据序列化。这里的数据结构化主要面向开发或业务层面,数据序列化面向通信或存储层面,当然数据序列化也需要“结构”和“格式”,所以这两者之间的区别主要在于面向领域和场景不同,一般要求和侧重点也会有所不同。数据结构化侧重人类可读性甚至有时会强调语义表达能力,而数据序列化侧重效率和压缩。
从这两个维度,我们可以做出下面的一些思考。
XML 作为一种扩展标记语言,JSON 作为源于 JS 的数据格式,都具有数据结构化的能力。
例如 XML 可以衍生出 HTML (虽然 HTML 早于 XML,但从概念上讲,HTML 只是预定义标签的 XML),HTML 的作用是标记和表达万维网中资源的结构,以便浏览器更好的展示万维网资源,同时也要尽可能保证其人类可读以便开发人员进行编辑,这就是面向业务或开发层面的数据结构化。
再如 XML 还可衍生出 RDF/RDFS,进一步表达语义网中资源的关系和语义,同样它强调数据结构化的能力和人类可读。
关于 RDF/RDFS 和语义网的概念可查询相关资料了解,或参阅 2-Answer 系列-本体构建模块(一) 和 3-Answer 系列-本体构建模块(二) ,文中有一些简单介绍。
JSON 也是同理,在很多场合更多的是体现了数据结构化的能力,例如作为交互接口的数据结构的表达。在 MongoDB 中采用 JSON 作为查询语句,也是在发挥其数据结构化的能力。
当然,JSON、XML 同样也可以直接被用来数据序列化,实际上很多时候它们也是这么被使用的,例如直接采用 JSON、XML 进行网络通信传输,此时 JSON、XML 就成了一种序列化格式,它发挥了数据序列化的能力。但是经常这么被使用,不代表这么做就是合理。实际将 JSON、XML 直接作用数据序列化通常并不是最优选择,因为它们在速度、效率、空间上并不是最优。换句话说它们更适合数据结构化而非数据序列化。
扯完 XML 和 JSON,我们来看看 ProtoBuf,同样的 ProtoBuf 也具有数据结构化的能力,其实也就是上面介绍的 message 定义。我们能够在 .proto 文件中,通过 message、import、内嵌 message 等语法来实现数据结构化,但是很容易能够看出,ProtoBuf 在数据结构化方面和 XML、JSON 相差较大,人类可读性较差,不适合上面提到的 XML、JSON 的一些应用场景。
但是如果从数据序列化的角度你会发现 ProtoBuf 有着明显的优势,效率、速度、空间几乎全面占优,看完后面的 ProtoBuf 编码的文章,你更会了解 ProtoBuf 是如何极尽所能的压榨每一寸空间和性能,而其中的编码原理正是 ProtoBuf 的关键所在,message 的表达能力并不是 ProtoBuf 最关键的重点。所以可以看出 ProtoBuf 重点侧重于数据序列化 而非 数据结构化。
最终对这些个人思考做一些小小的总结:
- XML、JSON、ProtoBuf 都具有数据结构化和数据序列化的能力
- XML、JSON 更注重数据结构化,关注人类可读性和语义表达能力。ProtoBuf 更注重数据序列化,关注效率、空间、速度,人类可读性差,语义表达能力不足(为保证极致的效率,会舍弃一部分元信息)
- ProtoBuf 的应用场景更为明确,XML、JSON 的应用场景更为丰富。
作者:404_89_117_101
链接:https://www.jianshu.com/p/a24c88c0526a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
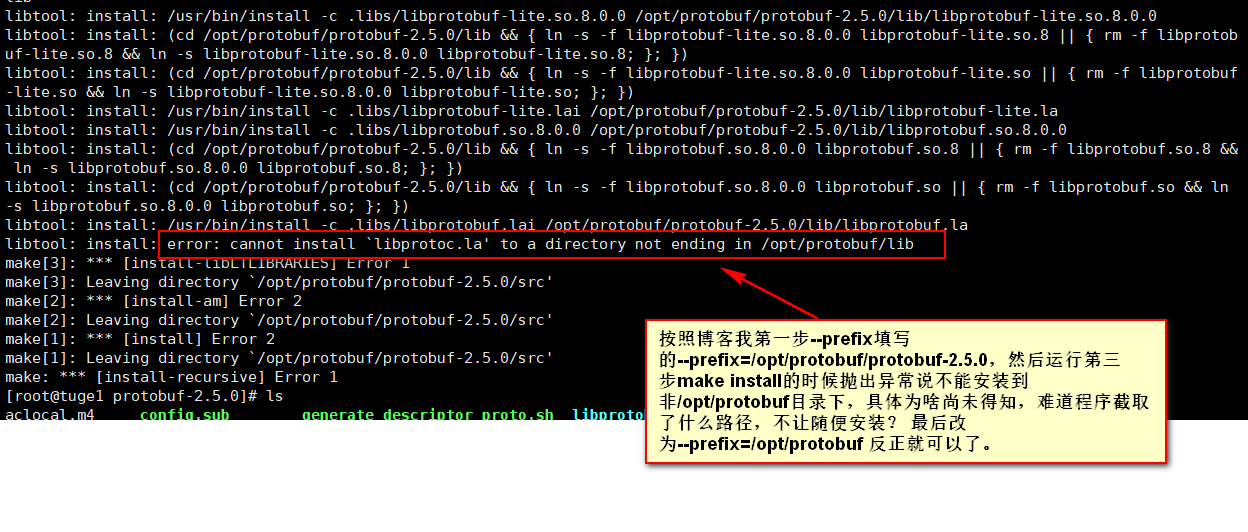
2.安装完毕后使用protoc --version查看版本号,提示 -bash: protoc: command not found。
这个的原因是你没刷新配置造成的,使用source /etc/profile 刷新下再执行就OK了。
【转】深入 ProtoBuf - 简介的更多相关文章
- Protobuf(一)——Protobuf简介
Protobuf简介 什么是 Google Protocol Buffer? 假如您在网上搜索,应该会得到类似这样的文字介绍: Google Protocol Buffer( 简称 Proto ...
- protobuf简介和使用
1.Protocol Buffers简介 Protocol Buffers (ProtocolBuffer/ protobuf )是Google公司开发的一种数据描述语言,类似于XML能够将结构化数据 ...
- 消息中间件NetMQ结合Protobuf简介
概述 对于稍微熟悉这两个优秀的项目来说,每个内容单独介绍都不为过,本文只是简介并探讨如何将两部分内容合并起来,使其在某些场景下更适合.更高效. NetMQ:ZeroMQ的.Net版本,ZeroMQ简单 ...
- protobuf简介
#1,简介 把某种数据结构的信息,以某种格式保存起来: 主要用于数据存储,传输协议格式. #2,优点 性能好 反观XML的缺点:解析的开销惊人,不适用于事件性能敏感的场合:为了有较好的可读性,引入一些 ...
- Google 的开源技术protobuf 简介与例子
本文来自CSDN博客:http://blog.csdn.NET/program_think/archive/2009/05/31/4229773.aspx 今天来介绍一下"Protocol ...
- [转]Google 的开源技术protobuf 简介与例子
本文来自CSDN博客:http://blog.csdn.NET/program_think/archive/2009/05/31/4229773.aspx 今天来介绍一下“Protocol Buffe ...
- Protobuf 简介及简单应用
Protobuf 是 protocol buffers 的缩写. 根据官网的说法, protocol buffers 与平台无关, 与语言无关, 实现数据序列化的一种手段. 正如名字一样, proto ...
- google protobuf安装与使用
google protobuf是一个灵活的.高效的用于序列化数据的协议.相比较XML和JSON格式,protobuf更小.更快.更便捷.google protobuf是跨语言的,并且自带了一个编译器( ...
- Google 开源技术protobuf
http://blog.csdn.net/hguisu/article/details/20721109#0-tsina-1-1601-397232819ff9a47a7b7e80a40613cfe1 ...
随机推荐
- Twitter类社交平台 用比例建立新的“好坏”与社会焦点
用比例建立新的"好坏"与社会焦点" title="Twitter类社交平台 用比例建立新的"好坏"与社会焦点"> 互联网全面 ...
- ServletContext+ServletConfig内容
ServletConfig { ① //读取web.xml配置信息 ServletConfig config = this.getServletConfig(); //读取类名称 config.get ...
- myecplise上将工程部署到应用下时,经常出现 An internal error occurred during: "Add Deployment". java.lang.NullPointEx
myecplise上将工程部署到应用下时,经常出现 An internal error occurred during: "Add Deployment". java.lang.N ...
- 学习日记:Python爬虫-1
这几天在b站看小甲鱼的python3教程,照着写了个有道翻译的程序 代码中字典data中的内容,用浏览器审查元素,先随便输一个要翻译的,找到跳出来的post的那个网址,看formdata就行了 返回的 ...
- CSS过渡、动画及变形的基本属性与运用
[逆战班] 动画可以让一个元素具有动态的效果,这个过程是使元素从一种样式变成另一个样式的过程.我们可以通过设置关键帧的方法来控制动画在某个时间节点的运动方式.通常设置多个节点来实现复杂的动画效果.0% ...
- ZYNQ自定义AXI总线IP应用——PWM实现呼吸灯效果
一.前言 在实时性要求较高的场合中,CPU软件执行的方式显然不能满足需求,这时需要硬件逻辑实现部分功能.要想使自定义IP核被CPU访问,就必须带有总线接口.ZYNQ采用AXI BUS实现PS和PL之间 ...
- git上传命令步骤
1.登陆github后,进入Github首页,点击New repository新建一个项目 2. 填写相应信息后点击create repository即可 Repository name: 仓库名称( ...
- springboot配置文件读取pom文件信息
解决的问题 springboot(当然别的也可以)多环境切换需要该配置文件,打包时不够方便. 解决: 配置文件能读取pom文件中的配置,根据命令选择不同配置注入springboot的配置文件中 pom ...
- opencv +数字识别
现在很多场景需要使用的数字识别,比如银行卡识别,以及车牌识别等,在AI领域有很多图像识别算法,大多是居于opencv 或者谷歌开源的tesseract 识别. 由于公司业务需要,需要开发一个客户端程序 ...
- java线程组
1 简介 一个线程集合.是为了更方便地管理线程.父子结构的,一个线程组可以集成其他线程组,同时也可以拥有其他子线程组. 从结构上看,线程组是一个树形结构,每个线程都隶属于一个线程组,线程组又有父线程组 ...