JQuery Sizzle引擎源代码分析
最近在拜读艾伦在慕课网上写的JQuery课程,感觉在国内对JQuery代码分析透彻的人没几个能比得过艾伦。有没有吹牛?是不是我说大话了?
什么是Sizzle引擎?
我们经常使用JQuery的选择器查询元素,查询的选择器有简单也有复杂:
简单点:“div”、“.navi”、“div.navi”。
复杂点:"div input[type='checkbox']"、"div.navi + .section p"。
Query实现查询时也是优先使用DOM标准查询函数,例如:
document.getElementById()
document.getElementsByTagName()
document.getElementsByClassName()
document.getElementsByName()
高级浏览器还实现了:
querySelector()
querySelectorAll()
由于浏览器版本差异导致的兼容问题,上面的函数并不是所有浏览器都支持。但JQuery得解决这些问题,所以就引入了Sizzle引擎。
JQuery在筛选元素时优先使用浏览器自带的高级查询函数,因为查询效率高。其次才选择使用Sizzle引擎筛选元素。
Sizzle引擎的目的是根据传入的selector选择器筛选出元素集合。执行过程经过词法分析、编译过程。通过词法分析把一个selector字符串分解成结构化的数据以便编译过程使用。编译过程充分利用了Javascript的闭包功能,生成一个函数链,在最终匹配时再去执行这个函数链。
举个例子,一个选择器selector的值为”Aaron input[name=ttt]”,通过词法分析,得到一个结构化数组:
[
{
matches: ["div"],
type: "TAG",
value: "Aaron"
},
{
type: " ",
value: " "
},
{
matches: ["name", "=", "ttt"],
type: "ATTR",
value: "[name=ttt]"
}
]
selector中的input作为一个种子集合seed。意思是Sizzle根据input查询出所有input元素,结果存放到seed集合,编译过程都是在seed集合中查询过滤。
上面说的很粗糙,不便于理解,接下来我们就拿代码来介绍。
通过代码分析原理
申明:下面的代码来源于Aaron在慕课网上的Jquery教程
compile
/**
* 编译过程
*/
function compile(){
var seed = document.querySelectorAll("input"),
selector = "Aaron [name=ttt]",
elementMatchers = [],
match = [
{
matches: ["div"],
type: "TAG",
value: "Aaron"
},
{
type: " ",
value: " "
},
{
matches: ["name", "=", "ttt"],
type: "ATTR",
value: "[name=ttt]"
}
];
elementMatchers.push(matcherFromTokens(match));
//超级匹配器
var cached = matcherFromGroupMatchers(elementMatchers);
var results = cached(seed);
results[0].checked = 'checked';
}
JQuery的compile函数包含了所有的执行过程,由于本篇介绍的重点是编译过程,所以词法分析的过程未包含,这里直接写了match结果,实际JQuery会调用tokenize()函数获取词组。
函数中调用了两个函数:matcherFromTokens()和matcherFromGroupMatchers()。
matcherFromTokens():返回的是一个函数,函数结构如下:
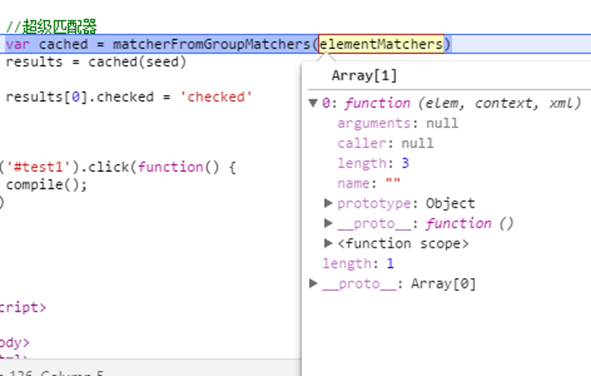
返回函数格式为function(elem, context, xml),并且这个函数返回一个bool值表示elem是否匹配有效。
matcherFromGroupMatchers():函数代码很简单,遍历seed集合,每个元素都调用elementMatcher函数。最终返回一个匹配成功的元素集合。
由于matcherFromGroupMatchers()函数比较简单,所以就先介绍它。
matcherFromGroupMatchers
function matcherFromGroupMatchers(elmentMatchers){
return function(seed){
var results = [];
var matcher, elem;
for(var i = 0; i < seed.length; i++){
var elem = seed[i];
matcher = elmentMatchers[0];
if(matcher(elem)){
results.push(elem);
}
}
return results;
}
}
遍历seed元素,每一个元素都调用matcher函数,返回true则添加到results数组中。
matcherFromTokens
function matcherFromTokens(tokens){
var len = tokens.length,
matcher,
matchers = [];
for(var i = 0; i < len; i++){
if(tokens[i].type === " "){
matchers = [addCombinator(elementMatcher(matchers))];
}else{
matcher = filter[tokens[i].type].apply(null, tokens[i].matches);
matchers.push(matcher);
}
}
return elementMatcher(matchers);
}
整个编译的核心也就在matcherFromTokens函数中,遍历分词tokens数组,分词分两大类,关系型和非关系型。关系型包括:“ ”、“>”、“+”、“~”。 剩下的都是非关系型分词。
每一个非关系型分词都会对应一个matcher:
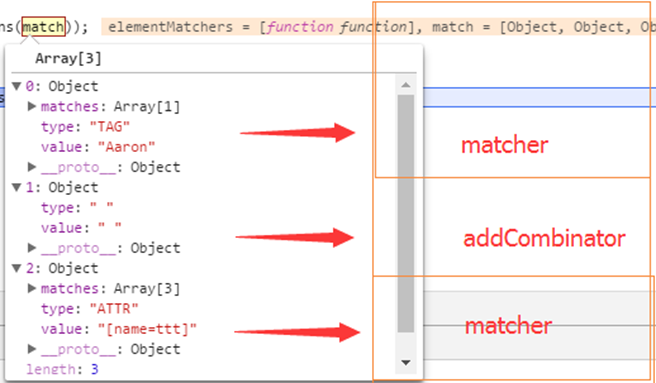
第一个分词类型为TAG,在filter中找到matcher。第二个分词为关系分词,调用addCombinator合并之前的matcher。第三个分词类型为ATTR,在filter中找到matcher。最终matchers的值为:
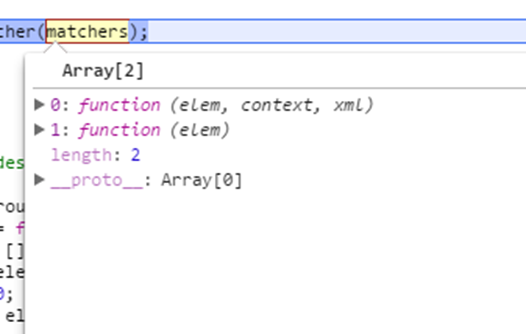
在return的时候又调用了elementMatcher()函数,返回的结果还是一个函数。上面介绍compile函数时看到过返回的函数结构。
matcherFromTokens函数体中有用到addCombinator()和elementMatcher()函数以及filter对象。先看filter:
var filter = {
ATTR: function(name, operator,check){
return function(elem){
var attr = elem.getAttribute(name);
if(operator === "="){
if(attr === check){
return true;
}
}
return false;
}
},
TAG: function(nodeNameSelector){
return function(elem){
return elem.nodeName && elem.nodeName.toLowerCase() === nodeNameSelector;
}
}
}
一目了然,一看就知道filter中的ATTR和TAG对应了match分词组中的type类型,所以filter对应了非关系型分词的matcher函数。
addCombinator
function addCombinator(matcher){
return function(elem, context, xml){
while(elem = elem["parentNode"]){
if(elem.nodeType === 1)
//找到第一个亲密的节点,立马就用终极匹配器判断这个节点是否符合前面的规则
return matcher(elem);
}
}
}
addCombinator对应关系型分词matcher。本例只列举了祖先和子孙关系" "的合并,返回的结果是一个签名为function(elem, contenxt, xml)的函数,函数中elem[“parentNode”]找到文档元素类型的父节点,再调用matcher校验这个父节点是否匹配。
所以关系型matcher函数执行的过程:先通过关系类型找到匹配元素,然后再调用matcher校验匹配结果。
elementMatcher
function elementMatcher(matchers){
return matchers.length > 1 ?
function(elem, context, xml){
var i = matchers.length;
while(i--){
if(!matchers[i](elem, context, xml)){
return false;
}
}
return true;
}:
matchers[0];
}
elementMatcher()函数就是干实事的家伙,它遍历matchers函数数组,执行每个matcher函数,一旦有matchers[i]返回false则整个匹配就失败了。这里需要注意的一点是i--,为什么是反序遍历?因为JQuery Sizzle匹配的原则是从右往左。由于前面的match数组是按照选择器从左往右保存的,所以这里先执行最后面的。
上面所有的代码只是简单模拟了JQuery Sizzle引擎的执行过程,真实的源代码很复杂,估计只有大神些才能领悟透彻。大神,艾伦得算一个。
说到闭包,如果能把JQuery Sizzle代码分析透彻,理解闭包易如反掌。本篇介绍的函数返回值都是函数,而每个返回函数需要的变量都是通过闭包存储起来,在真正执行函数的时候再读取这些变量。
如果本篇内容对大家有帮助,请点击页面右下角的关注。如果觉得不好,也欢迎拍砖。你们的评价就是博主的动力!下篇内容,敬请期待!
JQuery Sizzle引擎源代码分析的更多相关文章
- Sizzle.filter [ 源代码分析 ]
最近的研究已Sizzle选择,对于原理中我们也不得不佩服! Sizzle中间filter办法.主要负责元素表达式过滤块的集合,在内部的方法调用Sizzle.selector.fitler滤波操作的操作 ...
- jquery ui widget 源代码分析
jquery ui 的全部组件都是基于一个简单,可重用的widget. 这个widget是jquery ui的核心部分,有用它能实现一致的API.创建有状态的插件,而无需关心插件的内部转换. $.wi ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 高效查询
为什么Sizzle很高效? 首先,从处理流程上理解,它总是先使用最高效的原生方法来做处理 HTML文档一共有这么四个API: getElementById 上下文只能是HTML文档 浏览器支持情况:I ...
- jQuery中的Sizzle引擎分析
我分析的jQuery版本是1.8.3.Sizzle代码从3669行开始到5358行,将近2000行的代码,这个引擎的版本还是比较旧,最新的版本已经到v2.2.2了,代码已经超过2000行了.并且还有个 ...
- jQuery 2.0.3 源码分析Sizzle引擎解析原理
jQuery 2.0.3 源码分析Sizzle引擎 - 解析原理 声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 先来回答博友的提问: 如何解析 div > p + ...
- [转]JQuery - Sizzle选择器引擎原理分析
原文: https://segmentfault.com/a/1190000003933990 ---------------------------------------------------- ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 词法解析
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 浏览器从下载文档到显示页面的过程是个复杂的过程,这里包含了重绘和重排.各家浏览器引擎的工作原理略有差别,但也有一定规则. 简 ...
- jQuery1.11源码分析(8)-----jQuery调用Sizzle引擎的相关API
之所以把这部分放在这里,是因为这里用到了一些基本API,前一篇介绍过后才能使用. //jQuery通过find方法调用Sizzle引擎 //jQuery通过find方法调用Sizzle引擎 jQuer ...
- jQuery选择器引擎和Sizzle介绍
一.前言 Sizzle原来是jQuery里面的选择器引擎,后来逐渐独立出来,成为一个独立的模块,可以自由地引入到其他类库中.我曾经将其作为YUI3里面的一个module,用起来畅通无阻,没有任何障碍. ...
随机推荐
- Android 获取meta-data中的数据
在 Android 的 Mainfest 清单文件中,Application,Activity,Recriver,Service 的节点中都有这个的存在.很多时候我们可以通过 meta-data 来配 ...
- 微信小程序IDE(微信web开发者工具)安装、破解手册
1.IDE下载 微信web开发者工具,本人是用的windows 10 x64系统,用到以下两个版本的IDE安装工具与一个破解工具包: wechat_web_devtools_0.7.0_x64.exe ...
- PhpStorm和WAMP配置调试参数,问题描述Error. Interpreter is not specified or invalid. Press “Fix” to edit your project configuration.
PhpStorm和WAMP配置调试参数 问题描述: Error. Interpreter is not specified or invalid. Press “Fix” to edit your p ...
- 【从零开始学BPM,Day2】默认表单开发
[课程主题]主题:5天,一起从零开始学习BPM[课程形式]1.为期5天的短任务学习2.每天观看一个视频,视频学习时间自由安排. [第二天课程] Step 1 软件下载:H3 BPM10.0全开放免费下 ...
- RMS去除在线认证
在微软 OS 平台创建打开 RMS 文档如何避免时延 相信我们在企业内部的环境中已经部署了微软最新的OS平台,Windows 7和Windows 2008 R2,在这些OS平台上使用IRM功能时,您有 ...
- 打开程序总是会提示“Enter password to unlock your login keyring” ,如何成功关掉?
p { margin-bottom: 0.1in; line-height: 120% } 一.一开始我是按照网友所说的 : rm -f ~/.gnome2/keyrings/login.keyrin ...
- vim+vundle配置
Linux环境下写代码虽然没有IDE,但通过给vim配置几个插件也足够好用.一般常用的插件主要包括几类,查找文件,查找符号的定义或者声明(函数,变量等)以及自动补全功能.一般流程都是下载需要的工具,然 ...
- 第14章 Linux启动管理(3)_系统修复模式
3. 系统修复模式 3.1 单用户模式 (1)在grub界面中选择第2项,并按"e键"进入编辑.并在"-quiet"后面加入" 1",即&q ...
- [httpserver]如何解析HTTP请求报文
这个http server的实现源代码我放在了我的github上,有兴趣的话可以点击查看哦. 在上一篇文章中,讲述了如何编写一个最简单的server,但该程序只是接受到请求之后马上返回响应,实在不能更 ...
- 2000条你应知的WPF小姿势 基础篇<63-68 Triggers和WPF类逻辑结构>
在正文开始之前需要介绍一个人:Sean Sexton. 来自明尼苏达双城的软件工程师.最为出色的是他维护了两个博客:2,000ThingsYou Should Know About C# 和 2,00 ...