网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
Python
数据抓取框架,速度快,强大,而且使用简单。
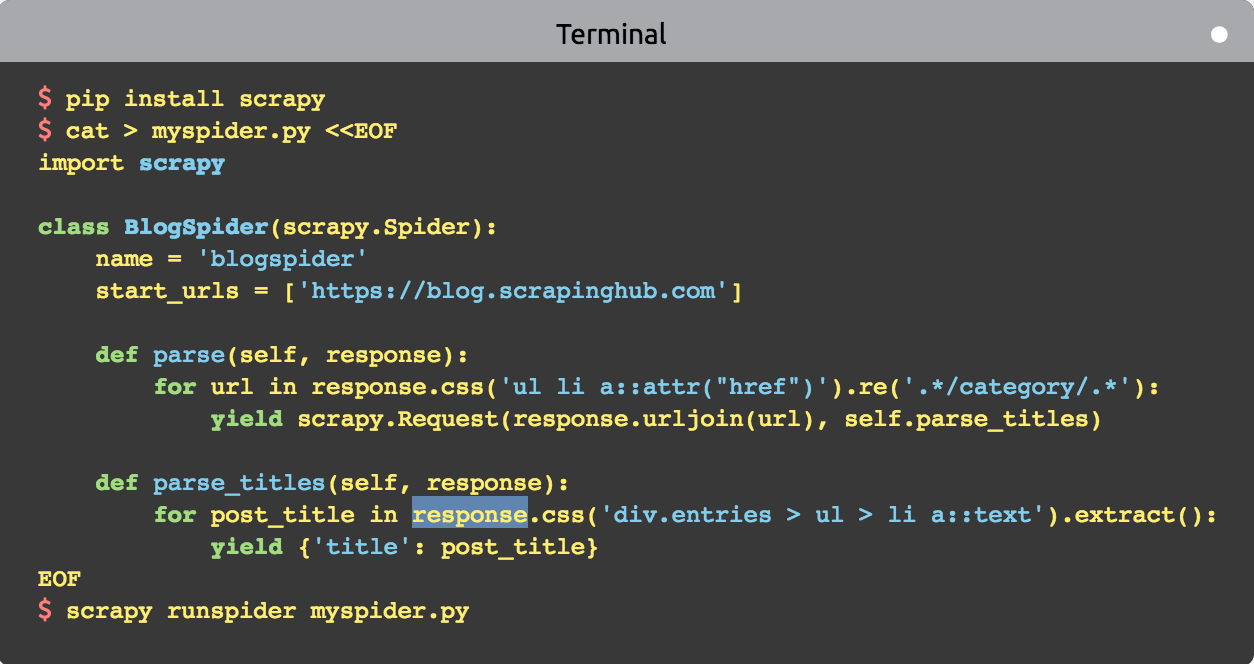
- 当执行scrapy runspider xxx.py命令的时候, Scrapy在项目里查找Spider(蜘蛛
网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务的更多相关文章
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码
这一篇首先从allitebooks.com里抓取书籍列表的书籍信息和每本书对应的ISBN码. 一.分析需求和网站结构 allitebooks.com这个网站的结构很简单,分页+书籍列表+书籍详情页. ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
开始学习网络数据挖掘方面的知识,首先从Beautiful Soup入手(Beautiful Soup是一个Python库,功能是从HTML和XML中解析数据),打算以三篇博文纪录学习Beautiful ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- 30分钟编写一个抓取 Unsplash 图片的 Python爬虫
我一直想用 Python and Selenium 创建一个网页爬虫,但从来没有实现它. 几天前, 我决定尝试一下,这听起来可能是挺复杂的, 然而编写代码从 Unsplash 抓取一些美丽的图片 ...
- 使用scrapy框架来进行抓取的原因
在python爬虫中:使用requests + selenium就可以解决将近90%的爬虫需求,那么scrapy就是解决剩下10%的吗? 这个显然不是这样的,scrapy框架是为了让我们的爬虫更强大. ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- 网络爬虫值scrapy框架基础
简介 Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv.json等文件中. 首先我们安装Scrapy. 其可以应用在数据挖掘,信息处理或存储历史 ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
随机推荐
- 3.Windows Server 2012 R2数据库部署
很多人竟然不会安装数据库....好吧,来个图文教程,其实和windows里面一样安装,和安装2008一样的 先安装3.5:http://www.cnblogs.com/dunitian/p/53487 ...
- 利用bootstrap的carousel.js实现轮播图动画
前期准备: 1.jquery.js. 2.bootstrap的carousel.js. 3.bootstrap.css. 如果大家不知道在哪下载,可以联系小颖,小颖把这些js和css可以发送给你. 一 ...
- 【开源】.net 分布式架构之监控平台
开源地址:http://git.oschina.net/chejiangyi/Dyd.BaseService.Monitor .net 简单监控平台,用于集群的性能监控,应用耗时监控管理,统一日志管理 ...
- 用scikit-learn学习DBSCAN聚类
在DBSCAN密度聚类算法中,我们对DBSCAN聚类算法的原理做了总结,本文就对如何用scikit-learn来学习DBSCAN聚类做一个总结,重点讲述参数的意义和需要调参的参数. 1. scikit ...
- 浅谈 LayoutInflater
浅谈 LayoutInflater 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/View 文中如有纰漏,欢迎大家留言指出. 在 Android 的 ...
- iOS UITableView 与 UITableViewController
很多应用都会在界面中使用某种列表控件:用户可以选中.删除或重新排列列表中的项目.这些控件其实都是UITableView 对象,可以用来显示一组对象,例如,用户地址薄中的一组人名.项目地址. UITab ...
- Python 正则表达式入门(中级篇)
Python 正则表达式入门(中级篇) 初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我们说在这一篇里,我们会介绍子表达式,向前向 ...
- UVa 122 Trees on the level
题目的意思: 输入很多个节点,包括路径和数值,但是不一定这些全部可以构成一棵树,问题就是判断所给的能否构成一棵树,且没有多余. 网上其他大神已经给出了题目意思:比如我一直很喜欢的小白菜又菜的博客 说一 ...
- [原创]java使用JDBC向MySQL数据库批次插入10W条数据测试效率
使用JDBC连接MySQL数据库进行数据插入的时候,特别是大批量数据连续插入(100000),如何提高效率呢?在JDBC编程接口中Statement 有两个方法特别值得注意:通过使用addBatch( ...
- Android中Fragment的两种创建方式
fragment是Activity中用户界面的一个行为或者是一部分.你可以在一个单独的Activity上把多个Fragment组合成为一个多区域的UI,并且可以在多个Activity中再使用.你可以认 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格