flume通过avro对接(汇总数据)
使用场景:
把多台服务器(flume generator)上面的日志汇总到一台或者几台服务器上面(flume collector),然后对接到kafka或者HDFS上

Flume Collector服务端
vim flume-server.properties
# agent1 name
a1.channels = c1
a1.sources = r1
a1.sinks = k1 #set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # other node, slave to master
a1.sources.r1.type = avro
a1.sources.r1.bind = master
a1.sources.r1.port = # set sink to logger
a1.sinks.k1.type = logger a1.sources.r1.channels = c1
a1.sinks.k1.channel=c1
启动:
## Master
/usr/local/flume/bin/flume-ng agent –f flume-server.properties –name a1
Flume Generator客户端
vim flume-client.properties
# a1 name
a1.channels = c1
a1.sources = r1
a1.sinks = k1 #set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = a1.sources.r1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /root/test.log # set sink1
#a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = master
a1.sinks.k1.port = a1.sources.r1.channels = c1
a1.sinks.k1.channel=c1
启动:
分别在slave1和slave2服务器上面启动
/usr/local/flume/bin/flume-ng agent –f flume-client.properties –name a1
启动之后,在slave1和slave2服务器上面分别执行以下操作:
#slave1
echo "wangzai slave1" > /root/test.log #slave2
echo "wangzai slave2" > /root/test.log
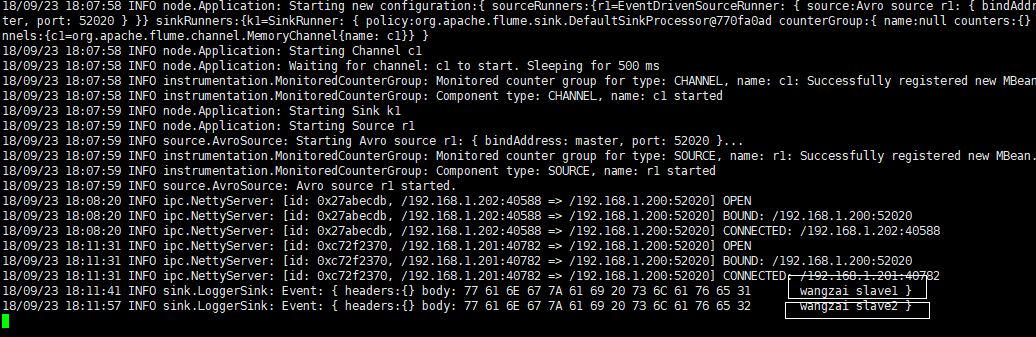
结果:
Master:
flume通过avro对接(汇总数据)的更多相关文章
- 将线上服务器生成的日志信息实时导入kafka,采用agent和collector分层传输,app的数据通过thrift传给agent,agent通过avro sink将数据发给collector,collector将数据汇集后,发送给kafka
记flume部署过程中遇到的问题以及解决方法(持续更新) - CSDN博客 https://blog.csdn.net/lijinqi1987/article/details/77449889 现将调 ...
- Flume+Kafka+Storm+Redis 大数据在线实时分析
1.实时处理框架 即从上面的架构中我们可以看出,其由下面的几部分构成: Flume集群 Kafka集群 Storm集群 从构建实时处理系统的角度出发,我们需要做的是,如何让数据在各个不同的集群系统之间 ...
- SQLSERVER 使用 ROLLUP 汇总数据,实现分组统计,合计,小计
表结构: CREATE TABLE [dbo].[Students]( ,) NOT NULL, ) NULL, [Sex] [int] NOT NULL, ) NULL, ) NULL, , ) N ...
- 一个有趣的SQL Server 层级汇总数据问题
看SQL Server大V宋大侠的博客文章,发现了一个有趣的sql server层级汇总数据问题. 具体的问题如下: parent_id emp_id emp_nam ...
- Flume的Avro Sink和Avro Source研究之一: Avro Source
问题 : Avro Source提供了怎么样RPC服务,是怎么提供的? 问题 1.1 Flume Source是如何启动一个Netty Server来提供RPC服务. 由GitHub上avro-rpc ...
- SQL学习之汇总数据之聚集函数
一. 1.我们经常需要汇总数据而不用把他们实际检索出来,为此SQL提供了专门的函数,以便于分析数据和报表生成,这些函数的功能有: (1)确定表中行数(或者满足单个条件或多个条件或包含某个特定值的行数) ...
- 采用Flume实时采集和处理数据
它已成功安装Flume在...的基础上.本文将总结使用Flume实时采集和处理数据,详细过程,如下面: 第一步,在$FLUME_HOME/conf文件夹下,编写Flume的配置文件,命名为flume_ ...
- MySQL汇总数据
汇总数据 有时,数据本身是不上台面的操作数据表.但在摘要表中的数据.例如 数据的一列的平均值.极大值.至少值等一下. 对于这些频繁使用的数据的处理的概要,MySQL它提供了一个函数来处理. SQL聚集 ...
- 介绍一种非常好用汇总数据的方式GROUPING SETS
介绍 对于任何人而言,用T-SQL语句来写聚会查询都是工作中重要的一环.我们大家也都很熟悉GROUP BY子句来实现聚合表达式,但是如果打算在一个结果集中包含多种不同的汇总结果,可能会比较麻烦.我将举 ...
随机推荐
- thinkjs——moment.js之前后台引入问题
前言: 工作中时常会遇见处理时间格式化问题:简言之就是将存在数据库中的时间戳的数字以“YYYY-MM-DD HH:mm:ss”格式展现出来. 过程: 1.在html文件中,通常是引入moment.js ...
- windows下配置VisualSVN Server服务器
下载安装文件: 服务端安装文件:VisualSVN-Server-1.6.2 客户端安装文件:TortoiseSVN-1.5.5.14361-win32-svn-1.5.4 上面是我使用的版本. 在V ...
- linux的setup命令设置网卡和防火墙等
以前在centos上配置网卡都是纯命令行,今天发现linux原来还有一个setup那么好用的命令,真是相见恨晚,以后防火墙.网卡.其他网络配置.系统配置(开机启动项)都可用他来完成了
- css3-巧用选择器 “:target”
今天(昨天)又发现一个知识盲区 css3的:target标签,之前学习的时候就是一眼扫过,说是认识了,但其实也就记了三分钟,合上书就全忘光了. 直到昨天,遇到一个有意思的题目,用css3新特性做一个类 ...
- CSSOM视图模式(CSSOM View Module)
一.Window视图属性(window对象) 这些属性可以获取住整个浏览器窗体大小.微软则将这些API称为“Screenview 接口” innerWidth 属性和 innerHeight 属性pa ...
- PL/SQL developer 可以连接本地数据库,但是不可以连接远程数据库的解决方法
修改Oracle_home目录下的 network\ADMIN\tnsnames.ora 文件, 在其中增加远程数据库对应的记录,类似下边这样: .2_orcl = (DESCRIPTION = (A ...
- Express框架(http服务器 + 路由)
index.js 使用express框架搭建http服务器,和实现路由功能. var express = require('express'); var app = express(); // 主页输 ...
- Python老王视频习题答案
基础篇2:一切变量都是数据对象的引用sys.getrefcount('test') 查看引用计数变量命名不能以数字开头编码:ascii.unicode.utf-81.阅读str对象的help文档,并解 ...
- 在ListView中嵌套ListView的事件处理
十分感谢此作者,以及作者的作者,让我卡了一星期的问题解决了!!http://blog.csdn.net/hutengfei0701/article/details/8956284谢谢http://my ...
- JS--页面返回/跳转/刷新(转载)
原文: Javascript 返回上一页1. Javascript 返回上一页 history.go(-1), 返回两个页面: history.go(-2); 2. history.back(). 3 ...