Information Retrieval
【Information Retrieval】
1、信息检索/获取(Information Retrieval,简称IR) 是从大规模非结构化数据(通常是文本)的集合(通常保存在计算机上)中找出满足用户信息需求的资料(通常是文档)的过程。
2、布尔检索模型
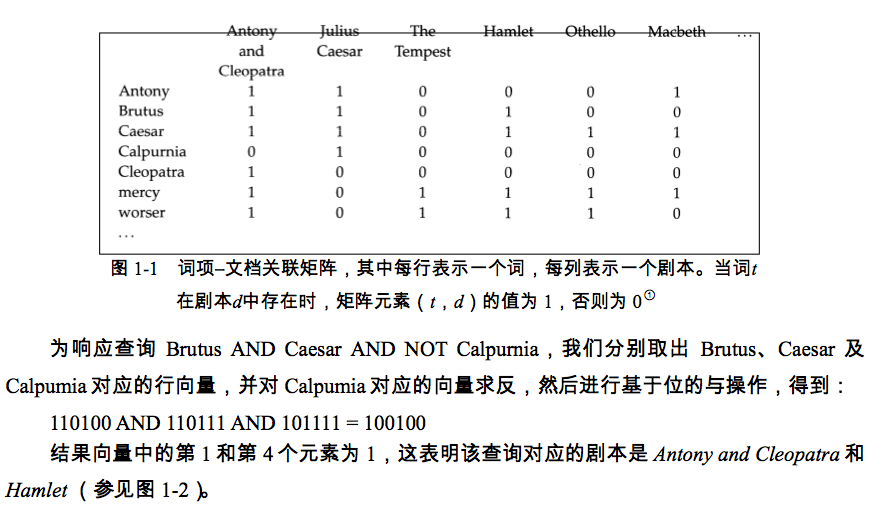
3、文档(document)是信息检索系统的检索对象,它们可以是一条条单独的记录或者是一本书的各章。
4、所有文档组成的文档集(collection),有时也称为语料库(corpus)。
5、检索系统的效果(effectiveness):
1)正确率:返回的结果中真正和信息需求相关的文档所占的百分比。
2)召回率:所有和信息需求真正相关的文档中被检索系统返回的百分比。
6、倒排索引(inverted index),是一个从词项(term,词项的集合也叫 dictionary / vocabulary / lexicon)到倒排记录表(posting list / inverted list)的一张表,所有词的倒排记录表构成全休倒排记录表(postings)。
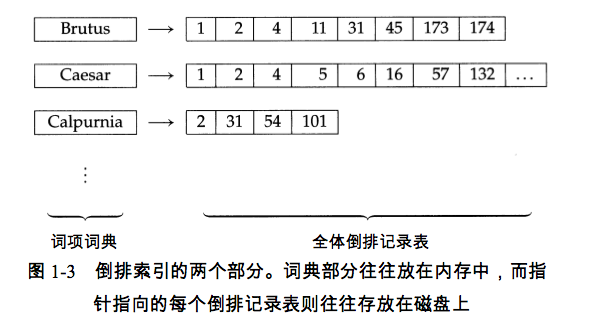
7、建立索引主要步骤:

8、建立倒排索引
给定一个文档集,我们假定每篇文档都有一个唯一的标识符即编号(docID)。在索引构建 过程中,我们可以给每篇新出现的文档赋一个连续的整数编号。在上述的前 3 步处理结束后, 对每篇文档建立索引时的输入就是一个归一化的词条表,也可以看成二元组(词项,文档 ID) 的一个列表(参见图 1-4)。建立索引最核心的步骤是将这个列表按照词项的字母顺序进行排序, 之后我们得到下图中部显示的结果,其中一个词项在同一文档中的多次出现会合并在一起 1, 最后整个结果分成词典和倒排记录表两部分。
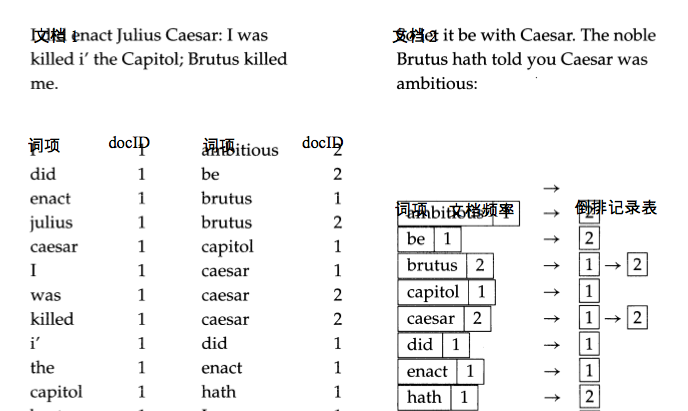

在最终得到的倒排索引中,词典和倒排记录表都有存储开销。前者往往放在内存中,而后 者由于规模大得多,通常放在磁盘上。
9、倒排记录表的存储方式:
1)单链表。
2)变长数组,定长数组链表。
11. 查询优化, 对于下述查询, 一个启发式的想法是, 按照词项的文档频率(也就是倒排记录表的长度)从小到大依次进行处理,如果我们先合并两个最短的倒排记录表,那么所有中间结果的大小都不会超过最短的倒排记录表
Brutus AND Caesar AND Calpurnia
Information Retrieval的更多相关文章
- Information retrieval信息检索
https://en.wikipedia.org/wiki/Information_retrieval 信息检索 (一种信息技术) 信息检索(Information Retrieval)是指信息按一定 ...
- Deep Learning for Information Retrieval
最近关注了一些Deep Learning在Information Retrieval领域的应用,得益于Deep Model在对文本的表达上展现的优势(比如RNN和CNN),我相信在IR的领域引入Dee ...
- Information Retrieval 倒排索引 学习笔记
一,问题描述 在Shakespeare文集(有很多文档Document)中,寻找哪个文档包含了单词“Brutus”和"Caesar",且不包含"Calpurnia&quo ...
- Information Retrieval II
[Information Retrieval II] 搜索引擎分类: 1.目录式搜索引擎. 2.全文搜索引擎. 3.元搜索引擎(Meta-Search Engine). 搜索引擎的4个阶段:下载(cr ...
- Music information retrieval
Music information retrieval - Wikipedia https://en.wikipedia.org/wiki/Music_information_retrieval Mu ...
- Information retrieval (IR class1)
1. 什么是IR? IR与数据库的区别? 答:数据库是检索结构化的数据,例如关系数据库:而信息检索是检索非结构化/半结构化的数据,例如:一系列的文本.信息检索是属于NLP(自然语言处理)里面最实用的一 ...
- IRGAN:A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models
https://arxiv.org/pdf/1705.10513.pdf 论文阅读笔记: https://www.cnblogs.com/liaohuiqiang/p/9694277.html htt ...
- Information retrieval (IR class2)
1. 解析文档一般要分析哪些方面? - 首先分析文档的格式,是docx,html,xml,pdf... - 其次分析文档的语言,是英语,汉语,日语,德语... - 使用的什么字符集,ASCII编码, ...
- information retrieval (CMU 11642)
1. Heap's law. predict the number of new vocabulary. 参考:https://www.youtube.com/watch?v=JDp12gU-vEQ ...
随机推荐
- idea常用实用快捷键
Ctrl+Alt+方向键(左键,右键),返回上次查看的位置.(这个快捷键和window本身快捷键冲突,需要关闭windows 对应快捷键功能,参考博客:https://blog.csdn.net/u0 ...
- phpstudy2017版本的nginx 支持laravel 5.X配置
之前做开发和学习一直用phpstudy的mysql服务,确实很方便,开箱即用.QQ群交流:697028234 现在分享一下最新版本的phpstudy2017 laravel环境配置. 最新版的phps ...
- python try except, 异常处理
http://www.runoob.com/python/python-exceptions.html http://blog.sciencenet.cn/blog-3031432-1059523.h ...
- chaos-engineering 的一些开源工具
Chaos Monkey - A resiliency tool that helps applications tolerate random instance failures. The Simi ...
- 一:线性dp
概念: 动态规划是运筹学的一个分支,是求解决策过程最优化的数学方法. 动态规划是通过拆分问题,定义问题状态和状态之间的关系使得问题能够以递推(或者说分治)的方法去解决. 解决策略: 1)最优化原理:如 ...
- 【转】linux tail命令使用方法详解
原文网址:http://www.111cn.net/sys/linux/46902.htm linux tail命令用途是按照要求将指定的文件的最后部分输出到标准设备,一般是终端,通俗讲来,就是把某个 ...
- mysql索引优化续
(1)索引类型: Btree索引:抽象的可以理解为“排好序的”快速查找结构myisam,innodb中默认使用Btree索引 hash索引:hash索引计算速度非常的快,但数据是随机放置的,无法对范围 ...
- 【转】open-falcon监控windows机器
open-falcon监控windows机器 时间:2016-05-22 15:34:04 来源:眷恋江南 编辑:涛涛 点击:791 A-A+ 最近公司上线了一款新的游戏,用的 ...
- 黄聪:WordPress实现HTML5预加载
WordPress实现HTML5预加载方法很简单,把下面代码: <?php if (is_archive() && ($paged > 1) && ($pa ...
- ffmpeg+nginx+video实现rtsp流转hls流,通过H5查看监控视频
一.FFmpeg下载:http://ffmpeg.zeranoe.com/builds/ 下载并解压FFmpeg文件夹,配置环境变量:在“Path”变量原有变量值内容上加上d:\ffmpeg\bin, ...