HBase – 探索HFile索引机制
本文由 网易云发布。
作者: 范欣欣
本篇文章仅限内部分享,如需转载,请联系网易获取授权。
01 HFile索引结构解析
HFile中索引结构根据索引层级的不同分为两种:single-level和mutil-level,前者表示单层索引,后者表示多级索引,一般为两级或三级。HFile V1版本中只有single-level一种索引结构,V2版本中引入多级索引。之所以引入多级索引,是因为随着HFile文件越来越大,Data Block越来越多,索引数据也越来越大,已经无法全部加载到内存中(V1版本中一个Region Server的索引数据加载到内存会占用几乎6G空间),多级索引可以只加载部分索引,降低内存使用空间。上一篇文章《HBase-存储文件HFile结构解析》,我们提到Bloom Filter内存使用问题是促使V1版本升级到V2版本的一个原因,再加上这个原因,这两个原因就是V1版本升级到V2版本最重要的两个因素。
V2版本Index Block有两类:Root Index Block和NonRoot Index Block,其中NonRoot Index Block又分为Intermediate Index Block和Leaf Index Block两种。HFile中索引结构类似于一棵树,Root Index Block表示索引数根节点,Intermediate Index Block表示中间节点,Leaf Index block表示叶子节点,叶子节点直接指向实际数据块。
HFile中除了Data Block需要索引之外,上一篇文章提到过Bloom Block也需要索引,索引结构实际上就是采用了single-level结构,文中Bloom Index Block就是一种Root Index Block。
对于Data Block,由于HFile刚开始数据量较小,索引采用single-level结构,只有Root Index一层索引,直接指向数据块。当数据量慢慢变大,Root Index Block满了之后,索引就会变为mutil-level结构,由一层索引变为两层,根节点指向叶子节点,叶子节点指向实际数据块。如果数据量再变大,索引层级就会变为三层。
下面就针对Root index Block和NonRoot index Block两种结构进行解析,因为Root Index Block已经在上面一篇文章中分析过, 此处简单带过,重点介绍NonRoot Index Block结构(InterMediate Index Block和Ieaf Index Block在内存和磁盘中存储格式相同,都为NonRoot Index Block格式)。
02 Root Index Block
Root Index Block表示索引树根节点索引块,可以作为bloom的直接索引,也可以作为data索引的根索引。而且对于single-level 和mutil-level两种索引结构对应的Root Index Block略有不同,本文以mutil-level索引结构为例进行分析(single-level索引结构是mutual-level的一种简化场景),在内存和磁盘中的格式如下图所示:
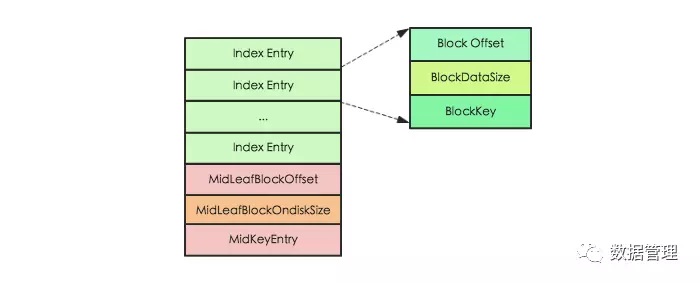
其中Index Entry表示具体的索引对象,每个索引对象由3个字段组成,Block Offset表示索引指向数据块的偏移量,BlockDataSize 表示索引指向数据块在磁盘上的大小,BlockKey表示索引指向数据块中的第一个key。除此之外,还有另外3个字段用来记录MidKey的相关信息,MidKey表示HFile所有Data Block中中间的一个Data Block,用于在对HFile进行split操作时,快速定位HFile的中间位置。需要注意的是single-level索引结构和mutil-level结构相比,就只缺少MidKey这三个字段。
Root Index Block会在HFile解析的时候直接加载到内存中,此处需要注意在Trailer Block中有一个字段为dataIndexCount,就表示此处Index Entry的个数。因为Index Entry并不定长,只有知道Entry的个数才能正确的将所有Index Entry加载到内存。
03 NonRoot Index Block
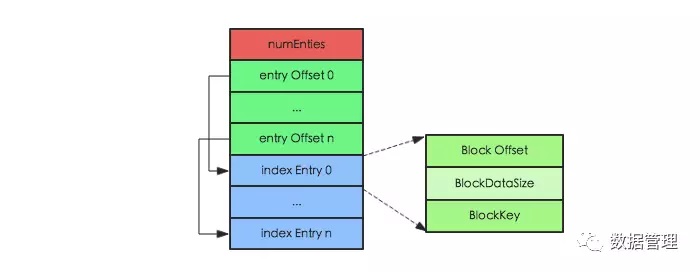
和Root Index Block相同,NonRoot Index Block中最核心的字段也是Index Entry,用于指向叶子节点块或者数据块。不同的是,NonRoot Index Block结构中增加了block块的内部索引entry Offset字段,entry Offset表示index Entry在该block中的相对偏移量(相对于第一个index Entry),用于实现block内的二分查找。所有非根节点索引块,包括Intermediate index block和leaf index block,在其内部定位一个key的具体索引并不是通过遍历实现,而是使用二分查找算法,这样可以更加高效快速地定位到待查找key。
04 HFile数据完整索引流程
了解了HFile中数据索引块的两种结构之后,就来看看如何使用这些索引数据块进行数据的高效检索。整个索引体系类似于MySQL 的B+树结构,但是又有所不同,比B+树简单,并没有复杂的分裂操作。具体见下图所示:
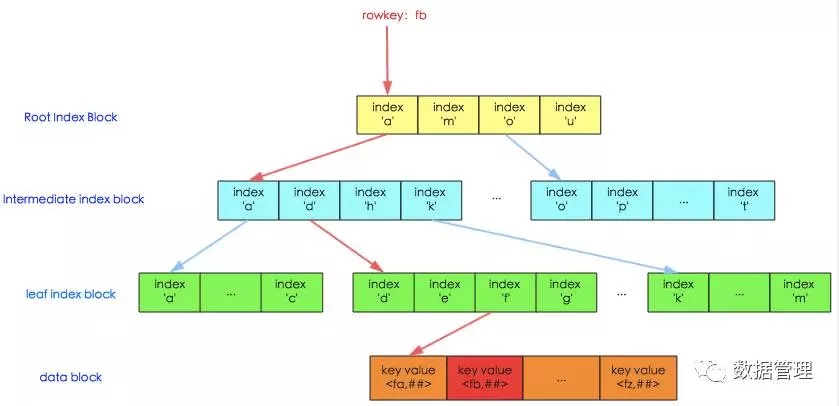
图中上面三层为索引层,在数据量不大的时候只有最上面一层,数据量大了之后开始分裂为多层,最多三层,如图所示。最下面一层为数据层,存储用户的实际keyvalue数据。这个索引树结构类似于InnoSQL的聚集索引,只是HBase并没有辅助索引的概念。
图中红线表示一次查询的索引过程(HBase中相关类为HFileBlockIndex和HFileReaderV2),基本流程可以表示为:
1. 用户输入rowkey为fb,在root index block中通过二分查找定位到fb在’a’和’m’之间,因此需要访问索引’a’指向的中间节点。因为root index block常驻内存,所以这个过程很快;
2. 将索引’a’指向的中间节点索引块加载到内存,然后通过二分查找定位到fb在index ‘d’和’h’之间,接下来访问索引’d’指向的叶子节点;
3. 同理,将索引’d’指向的中间节点索引块加载到内存,一样通过二分查找定位找到fb在index ‘f’和’g’之间,最后需要访问索引’f’指向的数据块节点;
4. 将索引’f’指向的数据块加载到内存,通过遍历的方式找到对应的keyvalue。
上述流程中因为中间节点、叶子节点和数据块都需要加载到内存,所以io次数正常为3次。但是实际上HBase为block提供了缓存机制,可以将频繁使用的block缓存在内存中,可以进一步加快实际读取过程。所以,在HBase中,通常一次随机读请求最多会产生3次io,如果数据量小(只有一层索引),数据已经缓存到了内存,就不会产生io。
05 索引块分裂
上文中已经提到,当数据量少、文件小的时候,只需要一个root index block就可以完成索引,即索引树只有一层。当数据不断写入,文件变大之后,索引数据也会相应变大,索引结构就会由single-level变为mulit-level,期间涉及到索引块的写入和分裂,本节来关注一下数据写入是如何引起索引块分裂的。
如果大家之前看过HBase系列另一篇博文《HBase数据写入之Memstore Flush》,可以知道memstore flush主要分为3个阶段,第一个阶段会讲memstore中的keyvalue数据snapshot,第二阶段再将这部分数据flush的HFile,并生成在临时目录,第三阶段将临时文件移动到指定的ColumnFamily目录下。很显然,第二阶段将keyvalue数据flush到HFile将会是关注的重点(flush相关代码在DefaultStoreFlusher类中)。整个flush阶段又可以分为两阶段:
1. append阶段:memstore中keyvalue首先会写入到HFile中数据块;
2. finalize阶段:修改HFlie中meta元数据块,索引数据块以及Trailer数据块等。
06 Append流程
具体key value数据的append以及finalize过程在HFileWriterV2文件中,其中append流程可以大体表征为:

a. 预检查:检查key的大小是否大于前一个key,如果大于则不符合HBase顺序排列的原理,抛出异常;检查value是否是null,如果为null也抛出异常;
b. block是否写满:检查当前Data Block是否已经写满,如果没有写满就直接写入keyvalue;否则就需要执行数据块落盘以及索引块修改操作;
c. 数据落盘并修改索引:如果DataBlock写满,首先将block块写入流;再生成一个leaf index entry,写入leaf Index block;再检查该leaf index block是否已经写满需要落盘,如果已经写满,就将该leaf index block写入到输出流,并且为索引树根节点root index block新增一个索引,指向叶子节点(second-level index);
d. 生成一个新的block:重新reset输出流,初始化startOffset为-1;
e. 写入keyvalue:将keyvalue以流的方式写入输出流,同时需要写入memstoreTS;除此之外,如果该key是当前block的第一个key,需要赋值给变量firstKeyInBlock。
07 Finalize阶段
memstore中所有keyvalue都经过append阶段输出到HFile后,会执行一次finalize过程,主要更新HFile中meta元数据块、索引数据块以及Trailer数据块,其中对索引数据块的更新是我们关心的重点,此处详细解析,上述append流程中c步骤’数据落盘并修改索引’会使得root index block不断增多,当增大到一定程度之后就需要分裂,分裂示意图如下图所示:
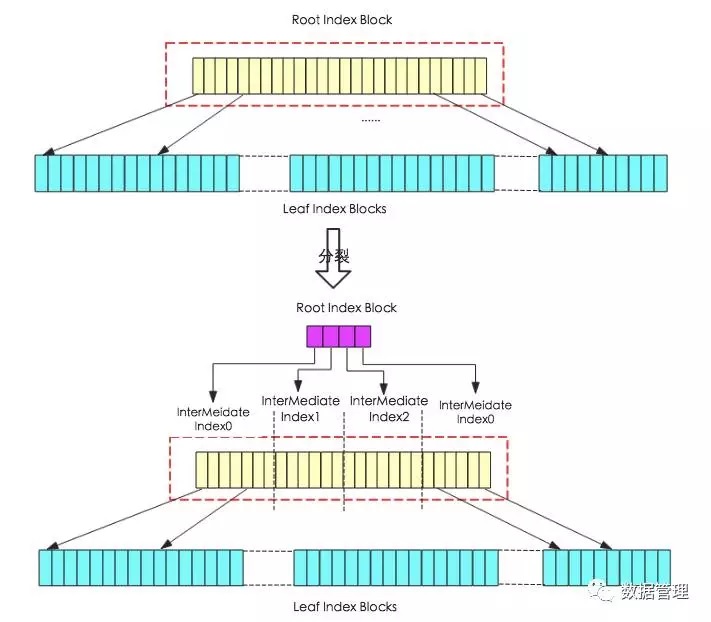
上图所示,分裂前索引结构为second-level结构,图中没有画出Data Blocks,根节点索引指向叶子节点索引块。finalize阶段系统会对Root Index Block进行大小检查,如果大小大于规定的大小就需要进行分裂,图中分裂过程实际上就是将原来的Root Index Block块分割成4块,每块独立形成中间节点InterMediate Index Block,系统再重新生成一个Root Index Block(图中红色部分),分别指向分割形成的4个interMediate Index Block。此时索引结构就变成了third-level结构。
08 总 结
这篇文章是HFile结构解析的第二篇文章,主要集中介绍HFile中的数据索引块。首先分Root Index Block和NonRoot Index Block 两部分对HFile中索引块进行了解析,紧接着基于此介绍了HBase如何使用索引对数据进行检索,最后结合Memstore Flush的相关知识分析了keyvalue数据写入的过程中索引块的分裂过程。希望通过这两篇文章的介绍,能够对HBase中数据存储文件HFile有一个更加全面深入的认识。
网易有数:企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。可点击这里免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/
HBase – 探索HFile索引机制的更多相关文章
- HBase – 存储文件HFile结构解析
本文由 网易云发布. 作者:范欣欣 本篇文章仅限内部分享,如需转载,请联系网易获取授权. HFile是HBase存储数据的文件组织形式,参考BigTable的SSTable和Hadoop的TFile ...
- hbase构建二级索引解决方案
关注公众号:大数据技术派,回复"资料",领取1024G资料. 1 为什么需要二级索引 HBase的一级索引就是rowkey,我们仅仅能通过rowkey进行检索.假设我们相对Hbas ...
- HBase的二级索引,以及phoenix的安装(需再做一次)
一:HBase的二级索引 1.讲解 uid+ts 11111_20161126111111:查询某一uid的某一个时间段内的数据 查询某一时间段内所有用户的数据:按照时间 索引表 rowkey:ts+ ...
- 探索 Java 同步机制[Monitor Object 并发模式在 Java 同步机制中的实现]
探索 Java 同步机制[Monitor Object 并发模式在 Java 同步机制中的实现] https://www.ibm.com/developerworks/cn/java/j-lo-syn ...
- Numpy数组对象的操作-索引机制、切片和迭代方法
前几篇博文我写了数组创建和数据运算,现在我们就来看一下数组对象的操作方法.使用索引和切片的方法选择元素,还有如何数组的迭代方法. 一.索引机制 1.一维数组 In [1]: a = np.arange ...
- 085 HBase的二级索引,以及phoenix的安装(需再做一次)
一:问题由来 1.举例 有A列与B列,分别是年龄与姓名. 如果想通过年龄查询姓名. 正常的检索是通过rowkey进行检索. 根据年龄查询rowkey,然后根据rowkey进行查找姓名. 这样的效率不高 ...
- MongoDB优化,建立索引实例及索引机制原理讲解
MongoDB优化,建立索引实例及索引机制原理讲解 为什么需要索引? 当你抱怨MongoDB集合查询效率低的时候,可能你就需要考虑使用索引了,为了方便后续介绍,先科普下MongoDB里的索引机制(同样 ...
- Hadoop生态圈-phoenix(HBase)的索引配置
Hadoop生态圈-phoenix(HBase)的索引配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 创建索引是为了优化查询,我们可以在phoenix上配置索引方式. 一.修改 ...
- Hadoop生态圈-HBase的HFile创建方式
Hadoop生态圈-HBase的HFile创建方式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 废话不多说,直接上代码,想说的话都在代码的注释里面. 一.环境准备 list cr ...
随机推荐
- Requests抓取火车票数据
1.数据接口 https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes=ADULT&queryDate=2016-08-01&from_ ...
- Spring JDBC Framework详解——批量JDBC操作、ORM映射
转自:https://blog.csdn.net/yuyulover/article/details/5826948 一.spring JDBC 概述 Spring 提供了一个强有力的模板类JdbcT ...
- Nginx rewrite使用
转自: https://www.cnblogs.com/czlun/articles/7010604.html
- class.__subclasses__()
[class.__subclasses__()] Each class keeps a list of weak references to its immediate subclasses. Thi ...
- go_接口
duck typeing 隐式的实现接口的方法就等于实现了接口 main函数 package main import ( "fmt" "learngo/retriever ...
- Intellij IDEA 启动项目ClassNotFoundException
博客原文地址:https://blog.csdn.net/wo541075754/article/details/45640267 使用Intellij IDEA 的过程中,新创建的项目启动时报错: ...
- 轻轻松松 用U盘安装WIN7
详细图解请猛击这里:http://www.docin.com/p-624698990.html一. 制作驱动U盘1. 先下载WIN7原版盒装安装盘镜像先下载软件2. 然后下载UltraISO PE 9 ...
- Spring Boot 、mybatis 、swagger 和 c3p0 整合
文件路径如下 添加依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns=" ...
- A simple way to crack VBA password in Excel file
Unbelivibale, but I found a very simple way that really works! Do the follwoing: 1. Create a new sim ...
- loadrunner12--学习中遇到疑问及解释
1.analysis里面,平均事务响应时间,平均事务响应时间+运行vuser,两个图的数据有区别是什么原因? 答: 请仔细查看以下两张图,其实两张图的数据是没有区别的. 之所以我们认为他们二者的数据有 ...