Django中的ORM
Django中ORM的使用。
一、安装python连接mysql的模块:MySQL-python
sudo pip install MySQL-python
安装完成后在python-shell中测试:
>>> import MySQLdb
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Library/Python/2.7/site-packages/MySQLdb/__init__.py", line 19, in <module>
import _mysql
ImportError: dlopen(/Library/Python/2.7/site-packages/_mysql.so, 2): Library not loaded: /usr/local/mysql/lib/libmysql.18.dylib
Referenced from: /Library/Python/2.7/site-packages/_mysql.so
Reason: image not found
出现错误,解决办法:
sudo ln -s /usr/local/mysql/lib/libmysqlclient.18.dylib /usr/lib/libmysqlclient.18.dylib sudo ln -s /usr/local/mysql/lib /usr/local/mysql/lib/mysql
执行以上命令时会提示:operation not permitted,即使使用sudo也没有权限。
这是因为在MAC OS10.11中采用了System Integrity Protection (SIP)保护技术,使得/usr/、/System/、/bin/、/sbin/以及系统默认安装的应用都收到SIP的保护。
因此需要暂时解除SIP的保护。
重启系统-按住command+R进入恢复模式-实用工具-终端,在终端中输入:
csrutil disable
这样 SIP 保护就关闭了。然后正常启动系统, 卸载之前安装的MySQL-python,重新安装。
sudo pip uninstall MySQL-python sudo pip install MySQL-python
然后执行以上ln即可执行成功,然后倒入模块测试成功。
>>> import MySQLdb
>>>
出于安全考虑,安装成功后再将SIP保护打开:同样进入恢复模式-终端中输入:
csrutil enable
二、ORM模型使用
1、禁止显示调试信息,找不到页面后,只返回404。
DEBUG = True ALLOWED_HOSTS = [*] #允许任何主机访问
2、在settings的INSTALL_APPS中注册创建的app
3、在settings的DATABASES中定义数据库引擎、数据库名字。定义数据库之前,必须先创建该库。(此处将数据库修改为mysql)
DATABASES = {
'default': {
#'ENGINE': 'django.db.backends.sqlite3',
#'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
'ENGINE': 'django.db.backends.mysql',
'NAME':'authors',
'HOST':'',
'PORT':'',
'USER':'root',
'PASSWORD':''
}
}
4、在models中创建数据库类。
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
def __unicode__(self):
return self.name class Author(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=40)
email = models.EmailField()
def __unicode__(self):
return '<%s %s>' %(self.first_name,self.last_name) class Book(models.Model):
name = models.CharField(max_length=100)
authors = models.ManyToManyField(Author) #关联Author表,在后台添加book时,会有author和publisher的选项。
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
def __unicode__(self):
return self.name
这里创建了三个表。书籍有书名和出版日期。它有一个或多个作者(和作者是多对多的关联关系[many-to-many]),只有一个出版商(和出版商是一对多的关联关系[one-to-many],也被称作外键[foreign key])。
5、生成数据库。
同步数据库(根据上面的数据库类生成SQL语句):
localhost:apps ahaii$ sudo python manage.py makemigrations
Migrations for 'test1':
0002_auto_20160729_0237.py:
- Create model Author
- Create model Book
- Create model Publisher
- Add field publisher to book
生成数据库:
localhost:apps ahaii$ sudo python manage.py migrate
Operations to perform:
Apply all migrations: admin, test1, contenttypes, auth, sessions
Running migrations:
Rendering model states... DONE
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying sessions.0001_initial... OK
Applying test1.0001_initial... OK
Applying test1.0002_auto_20160729_0237... OK
数据库创建成功,此时可以进入数据库中查询:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| authors |
| mysql |
| performance_schema |
+--------------------+
4 rows in set (0.01 sec)
已经创建了authors数据库。
mysql> show tables;
+----------------------------+
| Tables_in_authors |
+----------------------------+
| auth_group |
| auth_group_permissions |
| auth_permission |
| auth_user |
| auth_user_groups |
| auth_user_user_permissions |
| django_admin_log |
| django_content_type |
| django_migrations |
| django_session |
| test1_author |
| test1_book |
| test1_book_authors |
| test1_publisher |
| test1_userinfo |
+----------------------------+
15 rows in set (0.00 sec)
已经创建了author、book、publisher三张表和book_authors关联表。
6、创建后台超级管理用户
localhost:apps ahaii$ sudo python manage.py createsuperuser
Username (leave blank to use 'root'): ahaii
Email address:
Password:
Password (again):
Superuser created successfully.
7、通过后台admin管理数据库
在admin文件中添加数据库项目
import models admin.site.register(models.Author)
admin.site.register(models.Publisher)
admin.site.register(models.Book)
到此,就可以通过后台admin来管理数据库了。
运行django,然后访问lcoalhost:8000/admin,输入创建的超级管理用户,登陆即可。显示效果如下:
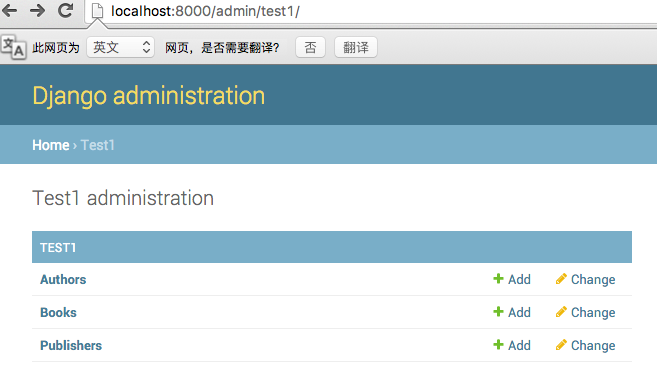
若需要将Auhors、Books和Publisher显示为中文,则需要在定义数据库类的时候添加:
class Meta:
verbose_name_plural='中文'
上面models文件修改为:
#!_*_ coding:utf-8 _*_
from __future__ import unicode_literals from django.db import models class Author(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=40)
email = models.EmailField()
def __unicode__(self):
return '<%s %s>' %(self.first_name,self.last_name)
class Meta:
verbose_name_plural='作者' class Book(models.Model):
name = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
def __unicode__(self):
return self.name
class Meta:
verbose_name_plural='书籍名称'
添加后效果如下:
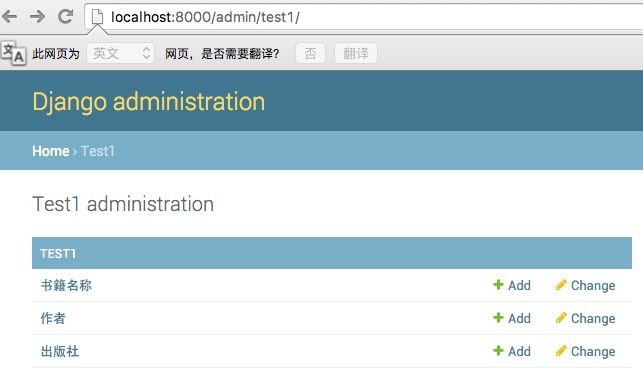
三、博客实例
1、生成一个新的app
sudo django-admin startapp blog
2、注册app
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'test1',
'blog'
]
3、创建model
class Blog(models.Model):
name = models.CharField(max_length=100)
tagline = models.TextField() def __unicode__(self):
return self.name class Author(models.Model):
name = models.CharField(max_length=50)
email = models.EmailField() def __unicode__(self):
return self.name class Entry(models.Model):
blog = models.ForeignKey(Blog)
headline = models.CharField(max_length=255)
body_text = models.TextField()
pub_date = models.DateField()
mod_date = models.DateField()
authors = models.ManyToManyField(Author)
n_comments = models.IntegerField()
n_pingbacks = models.IntegerField()
rating = models.IntegerField() def __unicode__(self):
return self.headline
4、同步数据库
sudo python manage.py makemigrations blog sudo python manage.py migrate
同步数据库时可能出现的错误:
localhost:apps ahaii$ sudo python manage.py migrate
Operations to perform:
Apply all migrations: test1, sessions, admin, auth, blog, contenttypes
Running migrations:
No migrations to apply.
解决办法:
将 django_migrations表中对应app名字的一条记录删掉,然后重新同步数据库就可以了。
5、在admin后台中注册blog
from django.contrib import admin # Register your models here.
import models admin.site.register(models.Author)
admin.site.register(models.Blog)
admin.site.register(models.Entry)
这样,admin中就有该app了
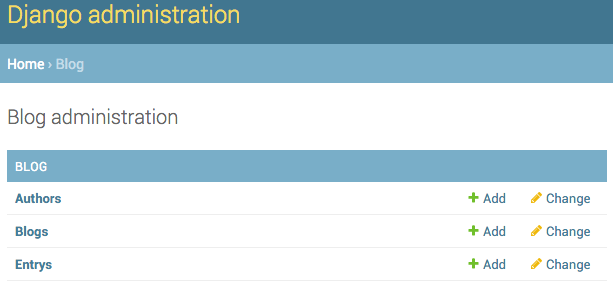
------------------------------------------------
以下转自django官方文档
获取对象¶
通过模型中的管理器构造一个查询集,来从你的数据库中获取对象。
查询集表示从数据库中取出来的对象的集合。它可以含有零个、一个或者多个过滤器。过滤器基于所给的参数限制查询的结果。 从SQL 的角度,查询集和SELECT 语句等价,过滤器是像WHERE 和LIMIT 一样的限制子句。
你可以从模型的管理器那里取得查询集。每个模型都至少有一个管理器,它默认命名为objects。通过模型类来直接访问它,像这样:
>>> Blog.objects
<django.db.models.manager.Manager object at ...>
>>> b = Blog(name='Foo', tagline='Bar')
>>> b.objects
Traceback:
...
AttributeError: "Manager isn't accessible via Blog instances."
注
管理器只可以通过模型的类访问,而不可以通过模型的实例访问,目的是为了强制区分“表级别”的操作和“记录级别”的操作。
对于一个模型来说,管理器是查询集的主要来源。例如,Blog.objects.all() 返回包含数据库中所有Blog 对象的一个查询集。
使用过滤器获取特定对象¶
all() 方法返回了一个包含数据库表中所有记录查询集。但在通常情况下,你往往想要获取的是完整数据集的一个子集。
要创建这样一个子集,你需要在原始的的查询集上增加一些过滤条件。两个最普遍的途径是:
查询参数(上面函数定义中的**kwargs)需要满足特定的格式,下面字段查询一节中会提到。
举个例子,要获取年份为2006的所有文章的查询集,可以使用filter()方法:
Entry.objects.filter(pub_date__year=2006)
利用默认的管理器,它相当于:
Entry.objects.all().filter(pub_date__year=2006)
链式过滤¶
查询集的筛选结果本身还是查询集,所以可以将筛选语句链接在一起。像这样:
>>> Entry.objects.filter(
... headline__startswith='What'
... ).exclude(
... pub_date__gte=datetime.date.today()
... ).filter(
... pub_date__gte=datetime(2005, 1, 30)
... )
这个例子最开始获取数据库中所有对象的一个查询集,之后增加一个过滤器,然后又增加一个排除,再之后又是另外一个过滤器。最后的结果仍然是一个查询集,它包含标题以”What“开头、发布日期在2005年1月30日至当天之间的所有记录。
过滤后的查询集是独立的¶
每次你筛选一个查询集,得到的都是全新的另一个查询集,它和之前的查询集之间没有任何绑定关系。每次筛选都会创建一个独立的查询集,它可以被存储及反复使用。
例如:
>>> q1 = Entry.objects.filter(headline__startswith="What")
>>> q2 = q1.exclude(pub_date__gte=datetime.date.today())
>>> q3 = q1.filter(pub_date__gte=datetime.date.today())
这三个查询集都是独立的。第一个是一个基础的查询集,包含所有标题以“What”开头的记录。第二个查询集是第一个的子集,它增加另外一个限制条件,排除pub_date 为今天和将来的记录。第三个查询集同样是第一个的子集,它增加另外一个限制条件,只选择pub_date 为今天或将来的记录。原始的查询集(q1)不会受到筛选过程的影响。
查询集是惰性执行的¶
查询集 是惰性执行的 —— 创建查询集不会带来任何数据库的访问。你可以将过滤器保持一整天,直到查询集 需要求值时,Django 才会真正运行这个查询。看下这个例子:
>>> q = Entry.objects.filter(headline__startswith="What")
>>> q = q.filter(pub_date__lte=datetime.date.today())
>>> q = q.exclude(body_text__icontains="food")
>>> print(q)
虽然它看上去有三次数据库访问,但事实上只有在最后一行(print(q))时才访问一次数据库。一般来说,只有在“请求”查询集 的结果时才会到数据库中去获取它们。当你确实需要结果时,查询集 通过访问数据库来求值。 关于求值发生的准确时间,参见何时计算查询集。
通过get 获取一个单一的对象¶
filter() 始终给你一个查询集,即使只有一个对象满足查询条件 —— 这种情况下,查询集将只包含一个元素。
如果你知道只有一个对象满足你的查询,你可以使用管理器的get() 方法,它直接返回该对象:
>>> one_entry = Entry.objects.get(pk=1)
可以对get() 使用任何查询表达式,和filter() 一样 —— 同样请查看下文的字段查询。
注意,使用get() 和使用filter() 的切片[0] 有一点区别。如果没有结果满足查询,get() 将引发一个DoesNotExist异常。这个异常是正在查询的模型类的一个属性 —— 所以在上面的代码中,如果没有主键为1 的Entry 对象,Django 将引发一个Entry.DoesNotExist。
类似地,如果有多条记录满足get() 的查询条件,Django 也将报错。这种情况将引发MultipleObjectsReturned,它同样是模型类自身的一个属性。
其它查询集方法¶
大多数情况下,需要从数据库中查找对象时,你会使用all()、 get()、filter() 和exclude()。 然而,这只是冰山一角;查询集 方法的完整列表,请参见查询集API 参考。
限制查询集¶
可以使用Python 的切片语法来限制查询集记录的数目 。它等同于SQL 的LIMIT 和OFFSET 子句。
例如,下面的语句返回前面5 个对象(LIMIT 5):
>>> Entry.objects.all()[:5]
下面这条语句返回第6 至第10 个对象(OFFSET 5 LIMIT 5):
>>> Entry.objects.all()[5:10]
不支持负的索引(例如Entry.objects.all()[-1])。
通常,查询集 的切片返回一个新的查询集 —— 它不会执行查询。有一个例外,是如果你使用Python 切片语法中"step"参数。例如,下面的语句将返回前10 个对象中每隔2个对象,它将真实执行查询:
>>> Entry.objects.all()[:10:2]
若要获取一个单一的对象而不是一个列表(例如,SELECT foo FROM bar LIMIT 1),可以简单地使用一个索引而不是切片。例如,下面的语句返回数据库中根据标题排序后的第一条Entry:
>>> Entry.objects.order_by('headline')[0]
它大体等同于:
>>> Entry.objects.order_by('headline')[0:1].get()
然而请注意,如果没有对象满足给定的条件,第一条语句将引发IndexError而第二条语句将引发DoesNotExist。 更多细节参见get()。
字段查询¶
字段查询是指如何指定SQL WHERE 子句的内容。它们通过查询集方法filter()、exclude() 和 get() 的关键字参数指定。
查询的关键字参数的基本形式是field__lookuptype=value。(中间是两个下划线)。例如:
>>> Entry.objects.filter(pub_date__lte='2006-01-01')
翻译成SQL(大体)是:
SELECT * FROM blog_entry WHERE pub_date <= '2006-01-01';
这是如何实现的
Python 定义的函数可以接收任意的键/值对参数,这些名称和参数可以在运行时求值。更多信息,参见Python 官方文档中的关键字参数。
查询条件中指定的字段必须是模型字段的名称。但有一个例外,对于ForeignKey你可以使用字段名加上_id 后缀。在这种情况下,该参数的值应该是外键的原始值。例如:
>>> Entry.objects.filter(blog_id=4)
如果你传递的是一个不合法的参数,查询函数将引发 TypeError。
这些数据库API 支持大约二十多种查询的类型;在字段查询参考 中可以找到完整的参考。为了让你尝尝鲜,下面是一些你可能用到的常见查询:
- exact
-
“精确”匹配。例如:
>>> Entry.objects.get(headline__exact="Man bites dog")
将生成下面的SQL:
SELECT ... WHERE headline = 'Man bites dog';
如果你没有提供查询类型 —— 即如果你的关键字参数不包含双下划线 —— 默认假定查询类型是exact。
例如,下面的两条语句相等:
>>> Blog.objects.get(id__exact=14) # Explicit form
>>> Blog.objects.get(id=14) # __exact is implied这是为了方便,因为exact 查询是最常见的情况。
- iexact
-
大小写不敏感的匹配。所以,查询:
>>> Blog.objects.get(name__iexact="beatles blog")
将匹配标题为"Beatles Blog"、"beatles blog" 甚至"BeAtlES blOG" 的Blog。
- contains
-
大小写敏感的包含关系测试。例如:
Entry.objects.get(headline__contains='Lennon')
大体可以翻译成下面的SQL:
SELECT ... WHERE headline LIKE '%Lennon%';
注意,这将匹配'Today Lennon honored' 但不能匹配'today lennon honored'。
还有一个大小写不敏感的版本,icontains。
- startswith, endswith
- 分别表示以XXX开头和以XXX结尾。当然还有大小写不敏感的版本,叫做istartswith 和 iendswith。
同样,这里只是表面。完整的参考可以在字段查询参考中找到。
跨关联关系的查询¶
Django 提供一种强大而又直观的方式来“处理”查询中的关联关系,它在后台自动帮你处理JOIN。 若要跨越关联关系,只需使用关联的模型字段的名称,并使用双下划线分隔,直至你想要的字段:
下面这个例子获取所有Blog 的name 为'Beatles Blog' 的Entry 对象:
>>> Entry.objects.filter(blog__name='Beatles Blog')
这种跨越可以是任意的深度。
它还可以反向工作。若要引用一个“反向”的关系,只需要使用该模型的小写的名称。
下面的示例获取所有的Blog 对象,它们至少有一个Entry 的headline 包含'Lennon':
>>> Blog.objects.filter(entry__headline__contains='Lennon')
如果你在多个关联关系直接过滤而且其中某个中介模型没有满足过滤条件的值,Django 将把它当做一个空的(所有的值都为NULL)但是合法的对象。这意味着不会有错误引发。例如,在下面的过滤器中:
Blog.objects.filter(entry__authors__name='Lennon')
(如果有一个相关联的Author 模型),如果Entry 中没有找到对应的author,那么它将当作其没有name,而不会因为没有author 引发一个错误。通常,这就是你想要的。唯一可能让你困惑的是当你使用isnull 的时候。因此:
Blog.objects.filter(entry__authors__name__isnull=True)
返回的Blog 对象包括author __name 为空的Blog对象,以及author__name不为空但author__name关联的entry__author 为空的对象。如果你不需要后者,你可以这样写:
Blog.objects.filter(entry__authors__isnull=False,
entry__authors__name__isnull=True)
跨越多值的关联关系¶
当你基于ManyToManyField 或反向的ForeignKey 来过滤一个对象时,有两种不同种类的过滤器。考虑Blog/Entry 关联关系(Blog 和 Entry 是一对多的关系)。我们可能想找出headline为“Lennon” 或publish为'2008'年的Entry。或者我们可能想查询包headline为“Lennon” 的Entry以及published为'2008'的Entry。因为实际上有和单个Blog 相关联的多个Entry,所以这两个查询在某些场景下都是有可能并有意义的。
ManyToManyField 有类似的情况。例如,如果Entry 有一个ManyToManyField 叫做 tags,我们可能想找到tag 叫做“music” 和“bands” 的Entry,或者我们想找一个tag 名为“music” 且状态为“public”的Entry。
对于这两种情况,Django 有种一致的方法来处理filter() 调用。一个filter() 调用中的所有参数会同时应用以过滤出满足所有要求的记录。接下来的filter() 调用进一步限制对象集,但是对于多值关系,它们应用到与主模型关联的对象,而不是应用到前一个filter() 调用选择出来的对象。
这些听起来可能有点混乱,所以希望展示一个例子使它变得更清晰。选择所有包含同时满足两个条件的entry的blog,这两个条件是headline 包含Lennon 和发表时间是2008 (同一个entry 满足两个条件),我们的代码是:
Blog.objects.filter(entry__headline__contains='Lennon',
entry__pub_date__year=2008)
从所有的blog模型实例中选择满足以下条件的blog实例:blog的enrty的headline属性值是“Lennon”,或者entry的发表时间是2008(两个条件至少满足一个,也可以同时满足),我们的代码是:
Blog.objects.filter(entry__headline__contains='Lennon').filter(
entry__pub_date__year=2008)
假如只有一个blog 对象同时含有两种entries,其中一种headline 包含“Lennon”而另外一种发表时间是2008,但是没有发表在2008年且headline 包含“Lennon” 的entries。第一个查询不会返回任何blog,第二个查询将会返回一个blog。
在第二个例子中, 第一个filter 限定查询集中的blog 与headline 包含“Lennon” 的entry 关联。第二个filter 又 限定查询集中的blog ,这些blog关联的entry 的发表时间是2008。(译者注:难点在如何理解further这个词!)第二个filter 过滤出来的entry 与第一个filter 过滤出来的entry 可能相同也可能不同。每个filter 语句过滤的是Blog,而不是Entry。
注
跨越多值关系的filter() 查询的行为,与exclude() 实现的不同。单个exclude() 调用中的条件不必引用同一个记录。
例如,下面的查询排除headline 中包含“Lennon”的Entry和在2008 年发布的Entry:
Blog.objects.exclude(
entry__headline__contains='Lennon',
entry__pub_date__year=2008,
)
然而,这与使用filter() 的行为不同,它不是排除同时满足两个条件的Entry。为了实现这点,即选择的Blog中不包含在2008年发布且healine 中带有“Lennon” 的Entry,你需要编写两个查询:
Blog.objects.exclude(
entry=Entry.objects.filter(
headline__contains='Lennon',
pub_date__year=2008,
),
)
Filter 可以引用模型的字段¶
到目前为止给出的示例中,我们构造过将模型字段与常量进行比较的filter。但是,如果你想将模型的一个字段与同一个模型的另外一个字段进行比较该怎么办?
Django 提供F 表达式 来允许这样的比较。F() 返回的实例用作查询内部对模型字段的引用。这些引用可以用于查询的filter 中来比较相同模型实例上不同字段之间值的比较。
例如,为了查找comments 数目多于pingbacks 的Entry,我们将构造一个F() 对象来引用pingback 数目,并在查询中使用该F() 对象:
>>> from django.db.models import F
>>> Entry.objects.filter(n_comments__gt=F('n_pingbacks'))
Django 支持对F() 对象使用加法、减法、乘法、除法、取模以及幂计算等算术操作,两个操作数可以都是常数和其它F()对象。为了查找comments 数目比pingbacks 两倍还要多的Entry,我们将查询修改为:
>>> Entry.objects.filter(n_comments__gt=F('n_pingbacks') * 2)
添加 ** 操作符。
为了查询rating 比pingback 和comment 数目总和要小的Entry,我们将这样查询:
>>> Entry.objects.filter(rating__lt=F('n_comments') + F('n_pingbacks'))
你还可以在F() 对象中使用双下划线标记来跨越关联关系。带有双下划线的F() 对象将引入任何需要的join 操作以访问关联的对象。例如,如要获取author 的名字与blog 名字相同的Entry,我们可以这样查询:
>>> Entry.objects.filter(authors__name=F('blog__name'))
对于date 和date/time 字段,你可以给它们加上或减去一个timedelta 对象。下面的例子将返回发布超过3天后被修改的所有Entry:
>>> from datetime import timedelta
>>> Entry.objects.filter(mod_date__gt=F('pub_date') + timedelta(days=3))
F() 对象支持.bitand() 和.bitor() 两种位操作,例如:
>>> F('somefield').bitand(16)
查询的快捷方式pk¶
为了方便,Django 提供一个查询快捷方式pk ,它表示“primary key” 的意思。
在Blog 模型示例中,主键是id 字段,所以下面三条语句是等同的:
>>> Blog.objects.get(id__exact=14) # Explicit form
>>> Blog.objects.get(id=14) # __exact is implied
>>> Blog.objects.get(pk=14) # pk implies id__exact
pk 的使用不仅限于__exact 查询 —— 任何查询类型都可以与pk 结合来完成一个模型上对主键的查询:
# Get blogs entries with id 1, 4 and 7
>>> Blog.objects.filter(pk__in=[1,4,7]) # Get all blog entries with id > 14
>>> Blog.objects.filter(pk__gt=14)
pk查询在join 中也可以工作。例如,下面三个语句是等同的:
>>> Entry.objects.filter(blog__id__exact=3) # Explicit form
>>> Entry.objects.filter(blog__id=3) # __exact is implied
>>> Entry.objects.filter(blog__pk=3) # __pk implies __id__exact
转义LIKE 语句中的百分号和下划线¶
与LIKE SQL 语句等同的字段查询(iexact、 contains、icontains、startswith、 istartswith、endswith 和iendswith)将自动转义在LIKE 语句中使用的两个特殊的字符 —— 百分号和下划线。(在LIKE 语句中,百分号通配符表示多个字符,下划线通配符表示单个字符)。
这意味着语句将很直观,不会显得太抽象。例如,要获取包含一个百分号的所有的Entry,只需要像其它任何字符一样使用百分号:
>>> Entry.objects.filter(headline__contains='%') #包含%符号
Django 会帮你转义;生成的SQL 看上去会是这样:
SELECT ... WHERE headline LIKE '%\%%';
对于下划线是同样的道理。百分号和下划线都会透明地帮你处理。
缓存和查询集¶
每个查询集都包含一个缓存来最小化对数据库的访问。理解它是如何工作的将让你编写最高效的代码。
在一个新创建的查询集中,缓存为空。首次对查询集进行求值 —— 同时发生数据库查询 ——Django 将保存查询的结果到查询集的缓存中并返回明确请求的结果(例如,如果正在迭代查询集,则返回下一个结果)。接下来对该查询集 的求值将重用缓存的结果。
请牢记这个缓存行为,因为对查询集使用不当的话,它会坑你的。例如,下面的语句创建两个查询集,对它们求值,然后扔掉它们:
>>> print([e.headline for e in Entry.objects.all()])
>>> print([e.pub_date for e in Entry.objects.all()])
这意味着相同的数据库查询将执行两次,显然倍增了你的数据库负载。同时,还有可能两个结果列表并不包含相同的数据库记录,因为在两次请求期间有可能有Entry被添加进来或删除掉。
为了避免这个问题,只需保存查询集并重新使用它:
>>> queryset = Entry.objects.all()
>>> print([p.headline for p in queryset]) # Evaluate the query set.
>>> print([p.pub_date for p in queryset]) # Re-use the cache from the evaluation.
何时查询集不会被缓存¶
查询集不会永远缓存它们的结果。当只对查询集的部分进行求值时会检查缓存, 但是如果这个部分不在缓存中,那么接下来查询返回的记录都将不会被缓存。特别地,这意味着使用切片或索引来限制查询集将不会填充缓存。
例如,重复获取查询集对象中一个特定的索引将每次都查询数据库:
>>> queryset = Entry.objects.all()
>>> print queryset[5] # Queries the database
>>> print queryset[5] # Queries the database again
然而,如果已经对全部查询集求值过,则将检查缓存:
>>> queryset = Entry.objects.all()
>>> [entry for entry in queryset] # Queries the database
>>> print queryset[5] # Uses cache
>>> print queryset[5] # Uses cache
下面是一些其它例子,它们会使得全部的查询集被求值并填充到缓存中:
>>> [entry for entry in queryset]
>>> bool(queryset)
>>> entry in queryset
>>> list(queryset)
注
简单地打印查询集不会填充缓存。因为__repr__() 调用只返回全部查询集的一个切片。
使用Q 对象进行复杂的查询¶
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
Q 对象 (django.db.models.Q) 对象用于封装一组关键字参数。这些关键字参数就是上文“字段查询” 中所提及的那些。
例如,下面的Q 对象封装一个LIKE 查询:
from django.db.models import Q
Q(question__startswith='What')
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
例如,下面的语句产生一个Q 对象,表示两个"question__startswith" 查询的“OR” :
Q(question__startswith='Who') | Q(question__startswith='What')
它等同于下面的SQL WHERE 子句:
WHERE question LIKE 'Who%' OR question LIKE 'What%'
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
Q(question__startswith='Who') | ~Q(pub_date__year=2005)
每个接受关键字参数的查询函数(例如filter()、exclude()、get())都可以传递一个或多个Q 对象作为位置(不带名的)参数。如果一个查询函数有多个Q 对象参数,这些参数的逻辑关系为“AND"。例如:
Poll.objects.get(
Q(question__startswith='Who'),
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))
)
... 大体上可以翻译成这个SQL:
SELECT * from polls WHERE question LIKE 'Who%'
AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06')
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
Poll.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
question__startswith='Who')
... 是一个合法的查询,等同于前面的例子;但是:
# INVALID QUERY
Poll.objects.get(
question__startswith='Who',
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)))
... 是不合法的。
另见
Django 单元测试中的OR 查询示例演示了几种Q 的用法。
比较对象¶
为了比较两个模型实例,只需要使用标准的Python 比较操作符,即双等于符号:==。在后台,它会比较两个模型主键的值。
利用上面的Entry 示例,下面两个语句是等同的:
>>> some_entry == other_entry
>>> some_entry.id == other_entry.id
如果模型的主键不叫id,也没有问题。比较将始终使用主键,无论它叫什么。例如,如果模型的主键字段叫做name,下面的两条语句是等同的:
>>> some_obj == other_obj
>>> some_obj.name == other_obj.name
删除对象¶
删除方法,为了方便,就取名为delete()。这个方法将立即删除对象且没有返回值。例如:
e.delete()
你还可以批量删除对象。每个查询集 都有一个delete() 方法,它将删除该查询集中的所有成员。
例如,下面的语句删除pub_date 为2005 的所有Entry 对象:
Entry.objects.filter(pub_date__year=2005).delete()
记住,这将尽可能地使用纯SQL 执行,所以这个过程中不需要调用每个对象实例的delete()方法。如果你给模型类提供了一个自定义的delete() 方法并希望确保它被调用,你需要手工删除该模型的实例(例如,迭代查询集并调用每个对象的delete())而不能使用查询集的批量delete() 方法。
当Django 删除一个对象时,它默认使用SQL ON DELETE CASCADE 约束 —— 换句话讲,任何有外键指向要删除对象的对象将一起删除。例如:
b = Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
这种级联的行为可以通过的ForeignKey 的on_delete 参数自定义。
注意,delete() 是唯一没有在管理器 上暴露出来的查询集方法。这是一个安全机制来防止你意外地请求Entry.objects.delete(),而删除所有 的条目。如果你确实想删除所有的对象,你必须明确地请求一个完全的查询集:
Entry.objects.all().delete()
拷贝模型实例¶
虽然没有内建的方法用于拷贝模型实例,但还是很容易创建一个新的实例并让它的所有字段都拷贝过来。最简单的方法是,只需要将pk 设置为None。利用我们的Blog 示例:
blog = Blog(name='My blog', tagline='Blogging is easy')
blog.save() # blog.pk == 1 blog.pk = None
blog.save() # blog.pk == 2
如果你用继承,那么会复杂一些。考虑下面Blog 的子类:
class ThemeBlog(Blog):
theme = models.CharField(max_length=200) django_blog = ThemeBlog(name='Django', tagline='Django is easy', theme='python')
django_blog.save() # django_blog.pk == 3
由于继承的工作方式,你必须设置pk 和 id 都为None:
django_blog.pk = None
django_blog.id = None
django_blog.save() # django_blog.pk == 4
这个过程不会拷贝关联的对象。如果你想拷贝关联关系,你必须编写一些更多的代码。在我们的例子中,Entry 有一个到Author 的多对多字段:
entry = Entry.objects.all()[0] # some previous entry
old_authors = entry.authors.all()
entry.pk = None
entry.save()
entry.authors = old_authors # saves new many2many relations
一次更新多个对象¶
有时你想为一个查询集中所有对象的某个字段都设置一个特定的值。这时你可以使用update() 方法。例如:
# Update all the headlines with pub_date in 2007.
Entry.objects.filter(pub_date__year=2007).update(headline='Everything is the same')
你只可以对非关联字段和ForeignKey 字段使用这个方法。若要更新一个非关联字段,只需提供一个新的常数值。若要更新ForeignKey 字段,需设置新的值为你想指向的新的模型实例。例如:
>>> b = Blog.objects.get(pk=1) # Change every Entry so that it belongs to this Blog.
>>> Entry.objects.all().update(blog=b)
update() 方法会立即执行并返回查询匹配的行数(如果有些行已经具有新的值,返回的行数可能和被更新的行数不相等)。更新查询集 唯一的限制是它只能访问一个数据库表,也就是模型的主表。你可以根据关联的字段过滤,但是你只能更新模型主表中的列。例如:
>>> b = Blog.objects.get(pk=1) # Update all the headlines belonging to this Blog.
>>> Entry.objects.select_related().filter(blog=b).update(headline='Everything is the same')
要注意update() 方法会直接转换成一个SQL 语句。它是一个批量的直接更新操作。它不会运行模型的save() 方法,或者发出pre_save 或 post_save信号(调用save()方法产生)或者查看auto_now 字段选项。如果你想保存查询集中的每个条目并确保每个实例的save() 方法都被调用,你不需要使用任何特殊的函数来处理。只需要迭代它们并调用save():
for item in my_queryset:
item.save()
对update 的调用也可以使用F 表达式 来根据模型中的一个字段更新另外一个字段。这对于在当前值的基础上加上一个值特别有用。例如,增加Blog 中每个Entry 的pingback 个数:
>>> Entry.objects.all().update(n_pingbacks=F('n_pingbacks') + 1)
然而,与filter 和exclude 子句中的F() 对象不同,在update 中你不可以使用F() 对象引入join —— 你只可以引用正在更新的模型的字段。如果你尝试使用F() 对象引入一个join,将引发一个FieldError:
# THIS WILL RAISE A FieldError
>>> Entry.objects.update(headline=F('blog__name'))
关联的对象¶
当你在一个模型中定义一个关联关系时(例如,ForeignKey、 OneToOneField 或ManyToManyField),该模型的实例将带有一个方便的API 来访问关联的对象。
利用本页顶部的模型,一个Entry 对象e 可以通过blog 属性e.blog 获取关联的Blog 对象。
(在幕后,这个功能是通过Python 的描述器实现的。这应该不会对你有什么真正的影响,但是这里我们指出它以满足你的好奇)。
Django 还会创建API 用于访问关联关系的另一头 —— 从关联的模型访问定义关联关系的模型。例如,Blog 对象b 可以通过entry_set 属性 b.entry_set.all()访问与它关联的所有Entry 对象。
这一节中的所有示例都将使用本页顶部定义的Blog、 Author 和Entry 模型。
一对多关系¶
前向查询¶
如果一个模型具有ForeignKey,那么该模型的实例将可以通过属性访问关联的(外部)对象。
例如:
>>> e = Entry.objects.get(id=2)
>>> e.blog # Returns the related Blog object.
你可以通过外键属性获取和设置。和你预期的一样,对外键的修改不会保存到数据库中直至你调用save()。例如:
>>> e = Entry.objects.get(id=2)
>>> e.blog = some_blog
>>> e.save()
如果ForeignKey 字段有null=True 设置(即它允许NULL 值),你可以分配None 来删除对应的关联性。例如:
>>> e = Entry.objects.get(id=2)
>>> e.blog = None
>>> e.save() # "UPDATE blog_entry SET blog_id = NULL ...;"
一对多关联关系的前向访问在第一次访问关联的对象时被缓存。以后对同一个对象的外键的访问都使用缓存。例如:
>>> e = Entry.objects.get(id=2)
>>> print(e.blog) # Hits the database to retrieve the associated Blog.
>>> print(e.blog) # Doesn't hit the database; uses cached version.
注意select_related() 查询集方法递归地预填充所有的一对多关系到缓存中。例如:
>>> e = Entry.objects.select_related().get(id=2)
>>> print(e.blog) # Doesn't hit the database; uses cached version.
>>> print(e.blog) # Doesn't hit the database; uses cached version.
反向查询¶
如果模型有一个ForeignKey,那么该ForeignKey 所指的模型实例可以通过一个管理器返回前一个模型的所有实例。默认情况下,这个管理器的名字为foo_set,其中foo 是源模型的小写名称。该管理器返回的查询集可以用上一节提到的方式进行过滤和操作。
例如:
>>> b = Blog.objects.get(id=1)
>>> b.entry_set.all() # Returns all Entry objects related to Blog. # b.entry_set is a Manager that returns QuerySets.
>>> b.entry_set.filter(headline__contains='Lennon')
>>> b.entry_set.count()
你可以在ForeignKey 定义时设置related_name 参数来覆盖foo_set 的名称。例如,如果Entry 模型改成blog =ForeignKey(Blog, related_name='entries'),那么上面的示例代码应该改成这样:
>>> b = Blog.objects.get(id=1)
>>> b.entries.all() # Returns all Entry objects related to Blog. # b.entries is a Manager that returns QuerySets.
>>> b.entries.filter(headline__contains='Lennon')
>>> b.entries.count()
使用自定义的反向管理器¶
默认情况下,用于反向关联关系的RelatedManager 是该模型默认管理器 的子类。如果你想为一个查询指定一个不同的管理器,你可以使用下面的语法:
from django.db import models class Entry(models.Model):
#...
objects = models.Manager() # Default Manager
entries = EntryManager() # Custom Manager b = Blog.objects.get(id=1)
b.entry_set(manager='entries').all()
如果EntryManager 在它的get_queryset() 方法中使用默认的过滤,那么该过滤将适用于all() 调用。
当然,指定一个自定义的管理器还可以让你调用自定义的方法:
b.entry_set(manager='entries').is_published()
处理关联对象的其它方法¶
除了在上面”获取对象“一节中定义的查询集 方法之外,ForeignKey 管理器 还有其它方法用于处理关联的对象集合。下面是每个方法的大概,完整的细节可以在关联对象参考 中找到。
- add(obj1, obj2, ...)
- 添加一指定的模型对象到关联的对象集中。
- create(**kwargs)
- 创建一个新的对象,将它保存并放在关联的对象集中。返回新创建的对象。
- remove(obj1, obj2, ...)
- 从关联的对象集中删除指定的模型对象。
- clear()
- 从关联的对象集中删除所有的对象。
若要一次性给关联的对象集赋值,只需要给它赋值一个可迭代的对象。这个可迭代的对象可以包含对象的实例,或者一个主键值的列表。例如:
b = Blog.objects.get(id=1)
b.entry_set = [e1, e2]
在这个例子中,e1 和e2 可以是Entry 实例,也可以是主键的整数值。
如果有clear() 方法,那么在将可迭代对象中的成员添加到集合中之前,将从entry_set 中删除所有已经存在的对象。如果没有clear() 方法,那么将直接添加可迭代对象中的成员而不会删除所有已存在的对象。
这一节中提到的每个”反向“操作都会立即对数据库产生作用。每个添加、创建和删除操作都会立即并自动保存到数据库中。
多对多关系¶
多对多关系的两端都会自动获得访问另一端的API。这些API 的工作方式与上面提到的“方向”一对多关系一样。
唯一的区别在于属性的名称:定义 ManyToManyField 的模型使用该字段的属性名称,而“反向”模型使用源模型的小写名称加上'_set' (和一对多关系一样)。
一个例子可以让它更好理解:
e = Entry.objects.get(id=3)
e.authors.all() # Returns all Author objects for this Entry.
e.authors.count()
e.authors.filter(name__contains='John') a = Author.objects.get(id=5)
a.entry_set.all() # Returns all Entry objects for this Author.
类似ForeignKey,ManyToManyField 可以指定related_name。在上面的例子中,如果Entry 中的ManyToManyField 指定related_name='entries',那么Author 实例将使用 entries 属性而不是entry_set。
一对一关系¶
一对一关系与多对一关系非常相似。如果你在模型中定义一个OneToOneField,该模型的实例将可以通过该模型的一个简单属性访问关联的模型。
例如:
class EntryDetail(models.Model):
entry = models.OneToOneField(Entry)
details = models.TextField() ed = EntryDetail.objects.get(id=2)
ed.entry # Returns the related Entry object.
在“反向”查询中有所不同。一对一关系中的关联模型同样具有一个管理器对象,但是该管理器表示一个单一的对象而不是对象的集合:
e = Entry.objects.get(id=2)
e.entrydetail # returns the related EntryDetail object
如果没有对象赋值给这个关联关系,Django 将引发一个DoesNotExist 异常。
实例可以赋值给反向的关联关系,方法和正向的关联关系一样:
e.entrydetail = ed
反向的关联关系是如何实现的?¶
其它对象关系映射要求你在关联关系的两端都要定义。Django 的开发人员相信这是对DRY(不要重复你自己的代码)原则的违背,所以Django 只要求你在一端定义关联关系。
但是这怎么可能?因为一个模型类直到其它模型类被加载之后才知道哪些模型类是关联的。
答案在app registry 中。当Django 启动时,它导入INSTALLED_APPS 中列出的每个应用,然后导入每个应用中的models 模块。每创建一个新的模型时,Django 添加反向的关系到所有关联的模型。如果关联的模型还没有导入,Django 将保存关联关系的记录并在最终关联的模型导入时添加这些关联关系。
由于这个原因,你使用的所有模型都定义在INSTALLED_APPS 列出的应用中就显得特别重要。否则,反向的关联关系将不能正确工作。
通过关联的对象进行查询¶
在关联对象字段上的查询与正常字段的查询遵循同样的规则。当你指定查询需要匹配的一个值时,你可以使用一个对象实例或者对象的主键的值。
例如,如果你有一个id=5 的Blog 对象b,下面的三个查询将是完全一样的:
Entry.objects.filter(blog=b) # Query using object instance
Entry.objects.filter(blog=b.id) # Query using id from instance
Entry.objects.filter(blog=5) # Query using id directly
回归到原始的 SQL¶
如果你发现需要编写的SQL 查询对于Django 的数据库映射机制太复杂,你可以回归到手工编写SQL。Django 对于编写原始的SQL 查询有多个选项;参见执行原始的SQL 查询。
最后,值得注意的是Django 的数据库层只是数据库的一个接口。你可以利用其它工具、编程语言或数据库框架来访问数据库;对于数据库,Django 没有什么特别的地方。
更多信息,http://www.cnblogs.com/alex3714/articles/5457672.html
Django中的ORM的更多相关文章
- Django中的ORM进阶操作
Django中的ORM进阶操作 Django中是通过ORM来操作数据库的,通过ORM可以很easy的实现与数据库的交互.但是仍然有几种操作是非常绕也特别容易混淆的.于是,针对这一块,来一个分类总结吧. ...
- 在Django中使用ORM创建图书管理系统
一.ORM(对象关系映射) 很多语言的web框架中都有这个概念 1. 为什么要有ORM? 1. 写程序离不开数据,要使用数据就需要连接数据库,但是不同的数据库在sql语句上(mysql,oracle等 ...
- Django中的ORM框架使用小技巧
Django中的ORM框架使用小技巧 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Django对各个数据提供了很好的支持,包括PostgreSQL,MySQL,SQLite ...
- django中的ORM介绍和字段及字段参数
Object Relational Mapping(ORM) ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据 ...
- Django中的ORM介绍,字段以及字段的参数。
Object Relational Mapping(ORM) ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据 ...
- Django 中得ORM介绍和字段及字段参数
ORM 介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说 ORM 是通过使用 ...
- django中的ORM与 应用与补充
目录 django中的ORM与 应用与补充 ORM与数据的对应关系 ORM 常用字段 ORM 其他字段 自定义字段 字段参数 Model Meta参数 常用13中查询(必会) 单表查询的双下划线应用 ...
- Django中使用ORM
一.ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描述对象和数 ...
- Django中的ORM如何通过数据库中的表格信息自动化生成Model 模型类?
Inspectdb Django项目通过绑定的数据库中的相应表格直接自动化生成Model 模型类 python manage.py inspectdb Django 中的 ORM 可以实现对象关系映射 ...
随机推荐
- jmeter压力测试的简单实例+badboy脚本录制(一个简单的网页用户登录测试的结果)
JMeter的安装:在网上下载,在下载后的zip解压后,在bin目录下找到JMeter.bat文件,双击就可以运行JMeter. http://jmeter.apache.org/ 在使用jmeter ...
- Mysql之CentOS初探
1. 卸载mysql 查看CentOS是否已经安装mysql数据库 rpm -qa | grep mysqlrpm -qa | grep MySQL 如果有,则卸载 // --nodeps表示强制rp ...
- weak引用变量是否线程安全
1.在ARC出现之前,Objetive-C的内存管理需要手工执行release&retain操作,这些极大增加了代码的编写难度,同时带来很多的crash. 同时大量的delegate是unr ...
- js中setTimeout()的使用
setTimeout()在js类中的使用方法 setTimeout (表达式,延时时间)setTimeout(表达式,交互时间)延时时间/交互时间是以豪秒为单位的(1000ms=1s) setTi ...
- sass 安装和使用
1,安装ruby :检查本地是否安装ruby: #ruby -v 2,安装sass: #gem install sass 3,检查是否安装成功:#sass -v 4,.scss文件不能直接被浏览器解析 ...
- MyBatis 学习-动态 SQL 篇
MyBatis 为我们提供了如下几个动态 SQL 元素: if choose foreach where/set trim 一.IF 元素 <select id="selectProj ...
- socket编程之TCP/UDP
目标: 1.编写TCP服务端客户端,实现客户端发送数据,服务端接收打印 2.采用OOP方式编写TCP服务端客户端,实现客户端发送数据,服务端添加时间戳,返回给客户端 3.采用OOP方式编写UDP服务端 ...
- 【NOIP2006提高组】能量项链
说好的好好写人话的题解 嗯很多题解都说过这是一个石子合并的模型它也确实就是一个石子合并的模型.然而就算这样我也不会写最后仍然写了个记忆化搜索 首先我们不论环状,就直接一条链型,当只剩下两个珠子的时候, ...
- mac上设置sudo不要密码
觉得每次sudo都需要设置密码太过麻烦,于是折腾了一番,谁知走了一番弯路记录下来. 以下是网上找到的步骤 chmod u+w /etc/sudoers 给当前用户增加写权限 vi /etc/sudo ...
- js 冒泡排序
var arr = []; for(var i=0; i<100000; i++){ arr.push(parseInt(Math.random()*100)) }; var t1 = Date ...