HBase学习与实践

Photo by bealach verse on Unsplash
参考书籍:《HBase 权威指南》 —— Lars George著。
文章为个人从零开始学习记录,如有错误,还请不吝赐教。
本文链接:https://www.cnblogs.com/novwind/p/11637404.html
· HBase 简述

HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。HBase以极高的容错和弹性方式处理稀疏数据,以及它可以处理多种类型的数据的方式,这也使其适用于各种业务场景。
HBase在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来访问数据,也可以通过REST、Avro或者Thrift的API来访问。
PS:NoSQL最初指“非SQL”或“非关系”,有时也称“Not Only SQL”,即“不仅SQL”,或对关系型SQL数据系统的补充。传统关系型数据库在处理数据密集型应用方面显得力不从心,主要表现在灵活性差、扩展性差、性能差等方面。
· 表的特点
HBase是一个面向列的数据库,在HBase中,最基本的单位是列(column).一列或多列形成一行(row),并由唯一的行键(row key)来确定存储。反过来,一个表(table)中有若干行,其中每列可能有多个版本,在每一个单元格(cell)中存储了不同的值。表架构仅定义列族,即键-值对。但是,一个表可能具有多个列族,并且此处每个列族可以具有任意数量的列。此外,在此之后的磁盘上,连续的列值被连续存储。除了每个单元格可以保留若干个版本的数据这一点,整个结构看起来像典型的数据库的描述,但很明显有比这更重要的因素在所有的行按照RowKey字典序进行排序存储。附一张自己画的图,画的不是很好还请谅解,而右图则是《HBase权威指南》一书中对HBase表与传统数据库表区别的描述。
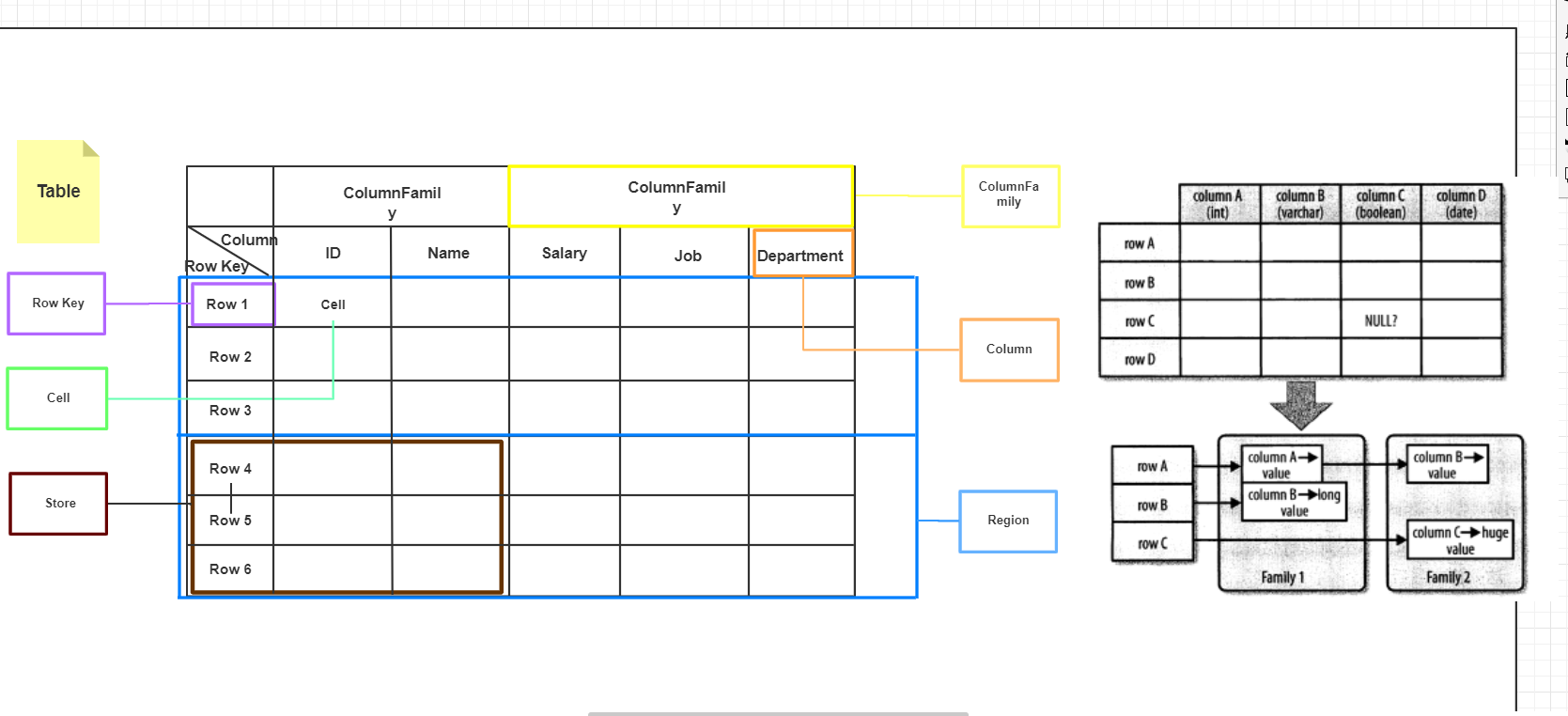
一行由若干列组成,若干列又构成一个列族(Column Family),这不仅有助于构建数据的语义边界或者局部边界,还有助于给它们设置某些特性(如压缩),或者指示它们存储在内存中。一个列族的所有列存储在同一个底层的存储文件里,这个存储文件叫做HFile。
列族需要在表创建时就定义好,并且不能修改得太频繁,数量也不能太多。在当前的实现中有少量己知的缺陷,这些缺陷使得列族数量只限于几十,实际情况可能还小得多。列族名必须由可打印字符组成,这与其他名字或值的命名规范有显著不同。
常见的引用列的格式为和family:qualifier,qualifier是任意的字节数组。与列族的数量有限制相反,列的数量没有限制:一个列族里可以有数百万个列。列值也没有类型和长度的限定。
HBase中扩展和负载均衡的基本单元称为region,region本质上是以行键排序的连续存储的区间。如果region太大,系统就会把它们动态拆分,相反地,就把多个region合并,以减少存储文件数量。每一个region只能由一台region服务器(region server)加载,每一台region服务器可以同时加载多个region。
数据的版本化:
HBase的一个特殊功能是,能为一个单元格(一个特定列的值)存储多个版本的数据这是通过每个版本梗用一个时间戳.并且按照降序存储来实现的.每个时间戳是一个长整型值,以毫秒为单位。它表示自世界标准时间(UTC)四70年1月1日0时以来所经过的时间,大多数繰作系统都有一个时钟获取函数来读取这个时间。将数据存入HBase时,要么显式地提供一个时间戳,要么忽略该时间戳.如果用户忽略该时间戳的话,RegionServer会在执行put操作的时候填充该时间戳。
· 基础架构
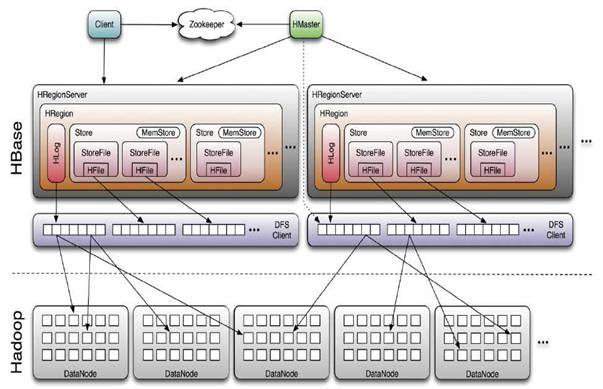
架构简述:
- HMaster:HBASE体系结构遵循传统的Master-Slave模型,其中有一个Master负责决策,一个或多个Slave执行真正的任务。在HBASE中,Master Server称为HMaster,HMaster是Master Server的实现,它负责监视集群中的所有RegionServer实例并实现负载均衡,是所有元数据更改的接口。在分布式集群中,Master Server通常运行在NameNode.
- RegionServer:HBase中Slave称为HRegionServers,是RegionServer的实现,负责管理Region,通常运行在DataNode。
- Regions:Region是表的可用性和分发的基本元素,由每个列族的存储库组成。
- Client:HBase Client通过查询Hbase:meta表寻找RegionServer特定的行范围。定位所需Region后,Client与服务于该区域的RegionServer联系,而不是通过Master,并发出读写请求。此信息被缓存在Client中,因此后续请求不必经过查找过程。如果某个Region由Master负载均衡重新分配,或者由于RegionServer已死,Client将再次请求meta表以确定User Region的新位置。
- ZooKeeper:Zookeeper集群用于存放整个 HBase集群的元数据以及集群的状态信息。并实现HMaster主从节点的故障转移。
之所以是简述是因为发现有这块已经有很多优秀、详尽的资料可供参考,那么附上这些链接:
- Apache HBase ™ Reference Guide
- HBase and MapR Database: Designed for Distribution, Scale, and Speed
- An In-Depth Look at the HBase Architecture
- Overview of HBase Architecture and its Components
- 深入HBase架构解析(一)
· HBase Shell
这部分的学习过程参考了HBase 入门指南中推荐的链接(需要梯子):HBase shell commands
其实即使没有其他资料,开启HBase Shell,输入命令 help,可以看到命令的提示(以下截取部分非完整),对于每条命令都可以使用 help "command"的方式查看其详细参数和使用方式,只要理解了表的逻辑结构再搭配上提示即使是刚接触HBase也应该能进行CRUD操作。
hbase(main):006:0* help
HBase Shell, version 2.1.6, rba26a3e1fd5bda8a84f99111d9471f62bb29ed1d, Mon Aug 26 20:40:38 CST 2019
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
COMMAND GROUPS:
Group name: general
Commands: processlist, status, table_help, version, whoami
Group name: ddl
Commands: alter, alter_async, alter_status, clone_table_schema, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, list_regions, locate_region, show_filters
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
Group name: tools
Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, cleaner_chore_enabled, cleaner_chore_run, cleaner_chore_switch, clear_block_cache, clear_compaction_queues, clear_deadservers, close_region, compact, compact_rs, compaction_state, flush, hbck_chore_run, is_in_maintenance_mode, list_deadservers, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch, split, splitormerge_enabled, splitormerge_switch, stop_master, stop_regionserver, trace, unassign, wal_roll, zk_dump
。。。。。。
hbase(main):009:0> help "create"
Creates a table. Pass a table name, and a set of column family
specifications (at least one), and, optionally, table configuration.
Column specification can be a simple string (name), or a dictionary
(dictionaries are described below in main help output), necessarily
including NAME attribute.
Examples:
Create a table with namespace=ns1 and table qualifier=t1
hbase> create 'ns1:t1', {NAME => 'f1', VERSIONS => 5}
Create a table with namespace=default and table qualifier=t1
hbase> create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'}
hbase> # The above in shorthand would be the following:
hbase> create 't1', 'f1', 'f2', 'f3'
hbase> create 't1', {NAME => 'f1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true}
hbase> create 't1', {NAME => 'f1', CONFIGURATION => {'hbase.hstore.blockingStoreFiles' => '10'}}
hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 1000000, MOB_COMPACT_PARTITION_POLICY => 'weekly'}
Table configuration options can be put at the end.
Examples:
hbase> create 'ns1:t1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt', OWNER => 'johndoe'
。。。。。。
这里的操作大部分都可以不言自明,所以只写一段基本的流程用于和HBase API部分作对比。至于其重要的部分可能会补充在文章的后半部分。
//创建NameSpache
hbase(main):019:0> create_namespace 'company'
Took 0.2666 seconds
//创建表,分配两个列族
hbase(main):020:0> create 'company:employees',{NAME => 'p_info'},{NAME => 'job_info'}
Created table company:employees
Took 1.4237 seconds
=> Hbase::Table - company:employees
//创建表并指定存储版本
hbase(main):021:0> create 'company:department',{NAME => 'info',VERSIONS => 3},{NAME => 'manager',VERSIONS => 3}
Created table company:department
Took 1.3701 seconds
=> Hbase::Table - company:department
//增,在p_info列族中添加eid列,下方同理
hbase(main):022:0> put 'company:employees','0001','p_info:eid','0001'
Took 0.1115 seconds
hbase(main):023:0> put 'company:employees','0001','p_info:ename','john'
Took 1.1250 seconds
hbase(main):024:0> put 'company:employees','0001','p_info:age',23
Took 0.0093 seconds
hbase(main):025:0> put 'company:employees','0002','p_info:eid',0002
Took 0.0053 seconds
hbase(main):026:0> put 'company:employees','0002','p_info:ename','Steven'
Took 0.0060 seconds
//查,扫描全表
hbase(main):027:0> scan 'company:employees'
ROWCOLUMN+CELL
0001 column=p_info:age, timestamp=1570353400606, value=23
0001 column=p_info:eid, timestamp=1570353050029, value=0001
0001 column=p_info:ename, timestamp=1570353286962, value=john
0002 column=p_info:eid, timestamp=1570353430138, value=2
0002 column=p_info:ename, timestamp=1570353477462, value=Steven
2 row(s)
Took 0.0356 seconds
//查,row级查询
hbase(main):028:0> get 'company:employees','0001'
COLUMN CELL
p_info:age timestamp=1570353400606, value=23
p_info:eid timestamp=1570353050029, value=0001
p_info:ename timestamp=1570353286962, value=john
1 row(s)
Took 0.0278 seconds
//column查询
hbase(main):029:0> get 'company:employees','0001','p_info:ename'
COLUMN CELL
p_info:ename timestamp=1570353286962, value=john 1 row(s)
Took 0.0094 seconds
hbase(main):030:0> get 'company:employees','0001','p_info:ename','p_info:age'
COLUMN CELL
p_info:age timestamp=1570353400606, value=23
p_info:ename timestamp=1570353286962, value=john 1 row(s)
Took 0.0227 seconds
//改,依旧用put,只不过会存储多个版本
hbase(main):004:0> put "company:employees","0001","p_info:age",25
Took 0.0555 seconds
hbase(main):006:0> put "company:employees","0002","p_info:eid","0002"
Took 0.0088 seconds
hbase(main):013:0> put "company:department","00001","info:partName","finance"
Took 0.0654 seconds
hbase(main):014:0> put "company:department","00001","manager:minister","katrina"
Took 0.0107 seconds
hbase(main):015:0> put "company:department","00001","manager:minister","lucy"
Took 0.0093 seconds
//指定查询的版本数
hbase(main):017:0> scan "company:department",{RAW => true,VERSIONS => 3}
ROW COLUMN+CELL
00001 column=info:partName, timestamp=1570359496407, value=finance
00001 column=manager:minister, timestamp=1570359596742, value=lucy
00001 column=manager:minister, timestamp=1570359578748, value=katrina
1 row(s)
Took 0.0223 seconds
//删,删除列
hbase(main):020:0> delete "company:department","00001","info:partName"
Took 0.0651 seconds
//删列族
hbase(main):021:0> delete "company:department","00001","manager"
Took 0.0187 seconds
//删行
hbase(main):023:0> deleteall "company:department","00001"
Took 0.0105 seconds
//下线和删除表
hbase(main):024:0> disable "company:department"
Took 0.8700 seconds
hbase(main):025:0> drop "company:department"
Took 0.4792 seconds
· HBase API
Admin API
表示HBASE中的Admin的类是HBaseAdmin。用户可以使用这个类执行管理员的任务(如DDL),通过使用Connection.getAdmin()方法来获得Admin的实例,示例API:
| 方法 | 描述 |
|---|---|
| void createTable(TableDescriptor desc) | 创建一个新表。 |
| void addColumnFamily(TableName tableName, ColumnFamilyDescriptor columnFamily) | 添加列族到表 |
| void createNamespace(NamespaceDescriptor descriptor) | 新建一个Namespace |
| void flush(TableName tableName) | 刷新缓冲区表的操作 |
| TableDescriptor getDescriptor(TableName tableName) | 获取一个表的描述符 |
。。。。。。
Table API
当使用Admin实例获取到一个Table实例时,就可以对表进行一系列的操作,如(DML)。在HBase中表示HBASE表的类是org.apache.hadoop.hbase.client.HTable。
- put
表的put操作可粗略分为单行和多行,根据需求构建Put对象,通过调用addColumn来给数据添加列,如果不传入时间戳则由RegionServer来补充时间戳,那么保证Server端的时间准确就是非常重要的工作了,确保不会出现无序的版本历史。另外如上面的代码所示,使用Put方法也可以传入一个List集合来达到插入多行的目的。
每一个Put作实际上都是一个RPC操作,它将客户端数据传送到服务器然后返回。这只适合小数据量的操作,不太合适大规模数据的读写。关于这里参考书籍中提到的写缓冲区 SetAutoFlush 和其他部分API已经被HBase版本遗弃了,找遍了各种博客发现很多今年的文章内容也是参考了旧的书籍,最后还是自己翻看源码和查阅文档找到了一些描述,如:HBASE-18500
默认情况下,HBase会保留3个版本的数据,在命令行使用 scan tableName,{RAW => TRUE,VERSIONS => 3} ,RAW选项表示扫描器返回所有的单元格(包括删除标记和未收集的已删除单元格)。还有需要注意当使用基于列表的put调用时,用户无法控制服务器端执行put的顺序,这意味着服务器被调用的顺序也不受用户控制。如果要保证写入的顺序,需要小心地使用这个操作,最坏的情况是,要减少每一批量处理的操作数,并显示地刷写客户端写缓冲区,强制把操作发送到远程服务器。 - get
与Put对应,get用于获取指定的一行或多行数据,根据需求构建Get对象以获得Result实例,当用户使用get()方法获取数据时,HBase返回的结果包含所有匹配的单元格数据,这些数据将被封装在一个Result实例中返回给用户。用它提供的方法,可以从服务器端获取匹配指定行的特定返回值,这些值包括列族、列限定符和时间戳等。HBase还封装了不少工具类,如上方代码用到的Bytes和CellUtil来方便开发。另外Result类中封装了一些面向列的存取方法,如
public List<Cell> getColumnCells(byte [] family, byte [] qualifier)
当用户创建Get实例时默认的版本数是1,可以通过如 readVersions(int versions) 方法来设置Get实例的版本数来达到获取多个版本的目的。
与Put多行相对的是 Result[] get(List gets) 这个方法,在示例代码中并未用到get来获取数据而实使用了getScanner,就像在命令行中使用Scan tableName 一样。
- delete
delete方法依旧是需要Delete示例作参数传入,在Delete示例中可以非常灵活的添加要删除的Row、Column、Family、Cell,如果指定了删除列且没有指定时间戳将会删除该列的所有版本。而如果指定了时间戳将匹配小于等于这个这个时间戳值的版本。如果尝试删除未设置时间戳的单元格,什么都不会发生。例如,某一列有版本10和版本20,则删除版本15将不会影响现存的任何版本。在删除列表时如Put一样,依旧无法确定执行的顺序。 - batch
batch方法要求传入的参数是一个实现了Row接口的实例集合,该方法对delete、get、put、increment、append、RowMutations进行批处理调用。未定义操作的执行顺序。意思是说,如果你做了一个PUT和一个GET相同的batch调用时,不一定保证get返回PUT所放的内容。事实上,上面所述方法的基于列表操作都是基于batch方法来实现的。
这里在Java代码中以HBase的API完成对数据库的增删改查操作
Configuration conf = HBaseConfiguration.create();
//指定Zookeeper集群地址
conf.set("hbase.zookeeper.quorum", "master,node1,node2");
//获取连接
Connection conn = ConnectionFactory.createConnection(conf);
//获取Admin对象
Admin admin = conn.getAdmin();
//创建一个NameSpace
NamespaceDescriptor mydata = NamespaceDescriptor.create("mydata").build();
admin.createNamespace(mydata);
//如果存在则删除表
TableName zooName = TableName.valueOf("zoo");
if (admin.tableExists(zooName)) {
admin.disableTable(zooName);
admin.deleteTable(zooName);
}
//表描述器构建者
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(zooName);
List<ColumnFamilyDescriptor> columnFamily = new ArrayList<>();
//列族描述器
columnFamily.add(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("member")).build());
//从构建者获取表描述器
TableDescriptor zoo = tableDescriptorBuilder.setColumnFamilies(columnFamily).build();
//创建表
admin.createTable(zoo);
System.out.println("zoo表是否存在:"+admin.tableExists(zooName));
//获取HTable对象
Table tableZoo = conn.getTable(zooName);
//增
List<Put> data = new ArrayList<>();
data.add(new Put("0001".getBytes())
.addColumn(Bytes.toBytes("member"),Bytes.toBytes("id"),Bytes.toBytes("0001"))
.addColumn(Bytes.toBytes("member"),Bytes.toBytes("name"),Bytes.toBytes("hadoop")));
data.add(new Put(Bytes.toBytes("0002"))
.addColumn(Bytes.toBytes("member"),Bytes.toBytes("id"),Bytes.toBytes("0002"))
.addColumn(Bytes.toBytes("member"),Bytes.toBytes("name"),Bytes.toBytes("zookeeper")));
tableZoo.put(data);
//查 Scanner或者get
ResultScanner results = tableZoo.getScanner(new Scan()
.addColumn("member".getBytes(), "id".getBytes())
.addColumn("member".getBytes(), "name".getBytes()));
System.out.println("ROW"+"\t\t\tCOLUMN+CELL");
for (Result result : results) {
for (Cell cell : result.rawCells()) {
System.out.println( Bytes.toString(CellUtil.cloneRow(cell))
+"\t\t\tcolumn="+Bytes.toString(CellUtil.cloneFamily(cell))
+":"+Bytes.toString(CellUtil.cloneQualifier(cell))
+","+Bytes.toString(CellUtil.cloneValue(cell)));
}
}
//删
tableZoo.delete(new Delete("0002".getBytes()));
tableZoo.close();
admin.disableTable(zooName);
admin.deleteTable(zooName);
System.out.println("zoo表是否存在:"+admin.tableExists(zooName));
admin.close();
conn.close();
· HBase & MapReduce
HBase的特点之一就是可以紧密地与MapReduce集成。下面一步一步的学习与MapReduce交互的知识。
首先是文档中给出的RowCounter示例。要让MapReduce作业获得所需的访问权限可以添加HBase所需的依赖项并使用HADOOP_CLASSPATH或-libjars选项。另外文档还给出了其他两种方法但明确表示不推荐:
- 添加HBASE-site.xml到Hadoop_home/conf并将HBASE的Jar包添加到$Hadoop_home/lib目录并分发到集群的各个节点。
- 可以编辑$Hadoop_home/conf/Hadoop-env.sh并将HBASE依赖项添加到HADOOP_CLASSPATH变量。
这两种方法都不值得推荐,因为这将使用HBASE引用来污染Hadoop安装。它还要求您重新启动Hadoop集群,然后Hadoop才能使用HBASE数据。
那么开始动手,因为我安装的每个大数据组件都在环境变量里有声明,再将HBase的lib路径引入到HADOOP_CLASSPATH中就可以直接启动,记得在这之前把该启动的组件都启动起来,然后根据文档的提示使用hadoop 运行jar包
{HBASE_HOME}../hadoop-2.6.0/bin/hadoop jar lib/hbase-mapreduce-2.1.6.jar
An example program must be given as the first argument.
Valid program names are:
CellCounter: Count cells in HBase table.
WALPlayer: Replay WAL files.
completebulkload: Complete a bulk data load.
copytable: Export a table from local cluster to peer cluster.
export: Write table data to HDFS.
exportsnapshot: Export the specific snapshot to a given FileSystem.
import: Import data written by Export.
importtsv: Import data in TSV format.
rowcounter: Count rows in HBase table.
verifyrep: Compare data from tables in two different clusters. It doesn't work for incrementColumnValues'd cells since timestamp is changed after appending to WAL.
可以看到给出了几个选项的提示,那么选择rowcounter和一个HBase中存在的表。
{HBASE_HOME}../hadoop-2.6.0/bin/hadoop jar lib/hbase-mapreduce-2.1.6.jar rowcounter student
19/09/25 20:29:37 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.0.212:8032
19/09/25 20:29:40 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT
19/09/25 20:29:40 INFO zookeeper.ZooKeeper: Client environment:host.name=Master
19/09/25 20:29:40 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_212
19/09/25 20:29:40 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation
....................省略去一大串,熟悉的MapReduce结果
HBase Counters
BYTES_IN_REMOTE_RESULTS=113
BYTES_IN_RESULTS=113
MILLIS_BETWEEN_NEXTS=1043
NOT_SERVING_REGION_EXCEPTION=0
NUM_SCANNER_RESTARTS=0
NUM_SCAN_RESULTS_STALE=0
REGIONS_SCANNED=1
REMOTE_RPC_CALLS=1
REMOTE_RPC_RETRIES=0
ROWS_FILTERED=0
ROWS_SCANNED=3
RPC_CALLS=1
RPC_RETRIES=0
org.apache.hadoop.hbase.mapreduce.RowCounter$RowCounterMapper$Counters
ROWS=3
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
这些驱动类可以在org.apache.hadoop.hbase.mapreduce.Driver类中看到其实现代码,下面贴出一小段源码以模仿实现
public static void main(String[] args) throws Throwable {
ProgramDriver pgd = new ProgramDriver();
pgd.addClass(RowCounter.NAME, RowCounter.class,
"Count rows in HBase table.");
pgd.addClass(CellCounter.NAME, CellCounter.class,
"Count cells in HBase table.");
..........
ProgramDriver.class.getMethod("driver", new Class [] {String[].class}).
invoke(pgd, new Object[]{args});
}
*invoke调用的代码段*
public int run(String[] args) throws Throwable {
if (args.length == 0) { //如果没有传入参数就打印提示信息
System.out.println("An example program must be given as the first argument.");
printUsage(this.programs);
return -1;
首先第一个问题是Hadoop如何读取HBase中的数据,想想之前学习Hadoop时提取和输出数据用的InputFormat和OutputFormat,而HBase提供了一组专用的实现为TableInputFormatBase,用户可使用其子类TableInputFormat来实现数据的输入。至于数据的导入过程可参考文章附录部分的 ImportTSV小节,下面贴出代码实现,由于是第一次编写,代码的读写方式参考了 CellCounter 和 ImportTsv且练习代码并未考虑扩展性,仅作新手学习阶段的记录。
public class PhoneDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Phone Sales Volume");
job.setJarByClass(PhoneDriver.class);
Scan scan = getConfiguredScanForJob(conf, args);
//这里参考了两个工具类的设置方式,表名是写死的,需要通过参数传递的话则可以改成变量
TableMapReduceUtil.initTableMapperJob("phone",scan,PhongMapper.class,ImmutableBytesWritable.class, Result.class,job);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
TableMapReduceUtil.initTableReducerJob("saleVolume",PhoneReducer.class,job);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Mutation.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
private static Scan getConfiguredScanForJob(Configuration conf, String[] args)
throws IOException {
// create scan with any properties set from TableInputFormat
Scan s = TableInputFormat.createScanFromConfiguration(conf);
s.setCacheBlocks(false);
return s;
}
static class PhongMapper extends TableMapper<Text, IntWritable> {
private Text deviceModel;
private static final IntWritable one = new IntWritable(1);
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
if(value==null){
throw new IllegalStateException("values passed to the map is null");
}
deviceModel = new Text( value.getValue(Bytes.toBytes("orderInfo"), Bytes.toBytes("device_model")));
context.write(deviceModel,one);
}
}
static class PhoneReducer extends TableReducer<Text,IntWritable, NullWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum +=value.get();
}
context.write(NullWritable.get(), new Put(key.getBytes())
.addColumn(Bytes.toBytes("info"),Bytes.toBytes("sale_count"),Bytes.toBytes(sum)));
}
}
}
打包上传到Linux,在HBase中建表并运行
hbase(main):015:0> create 'saleVolume','info'
${HBASE_HOME}../hadoop-2.6.0/bin/hadoop jar learn/part2/HBase01-1.0-SNAPSHOT.jar YouQualifiedClassName
确认数据无误
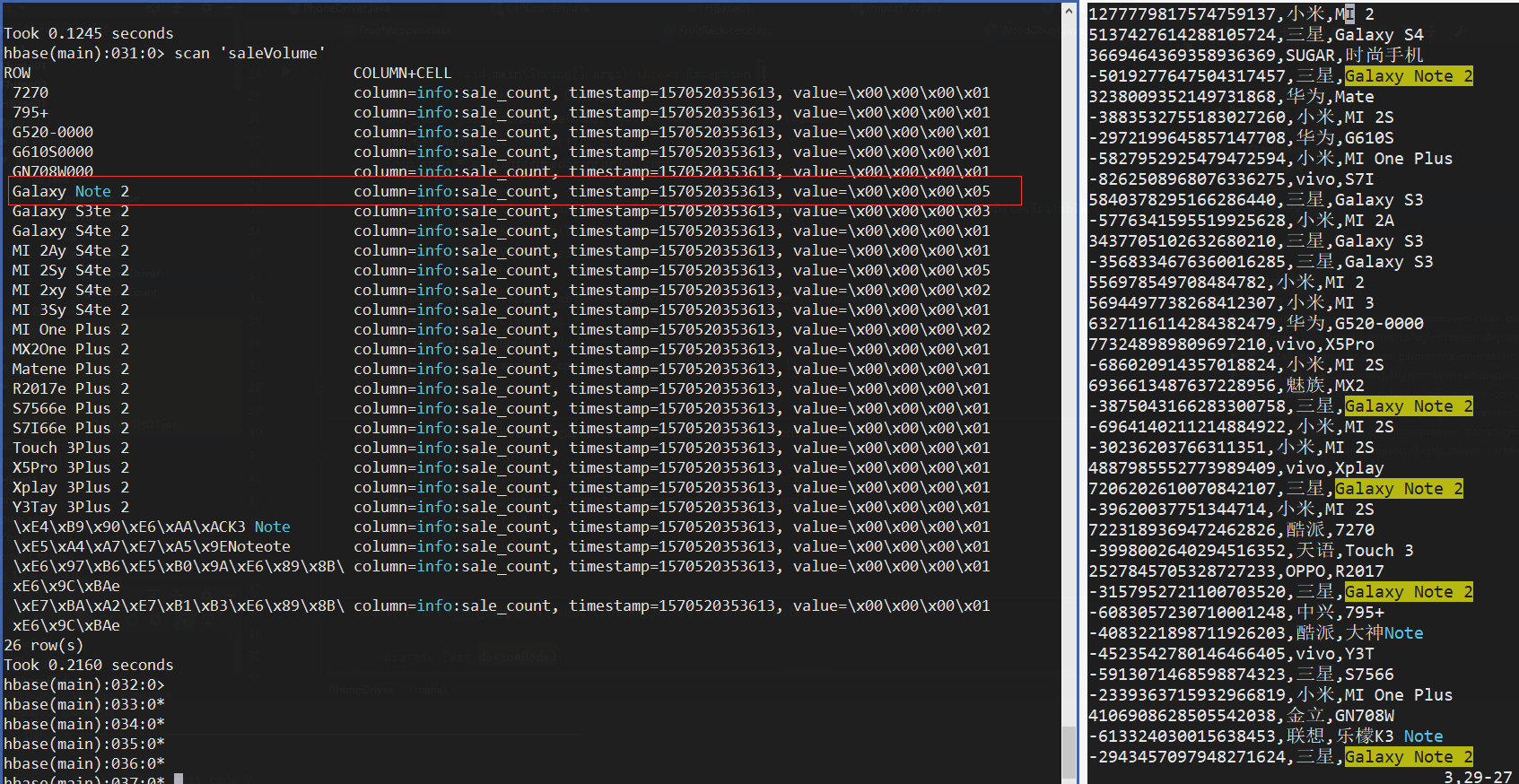
· 附录
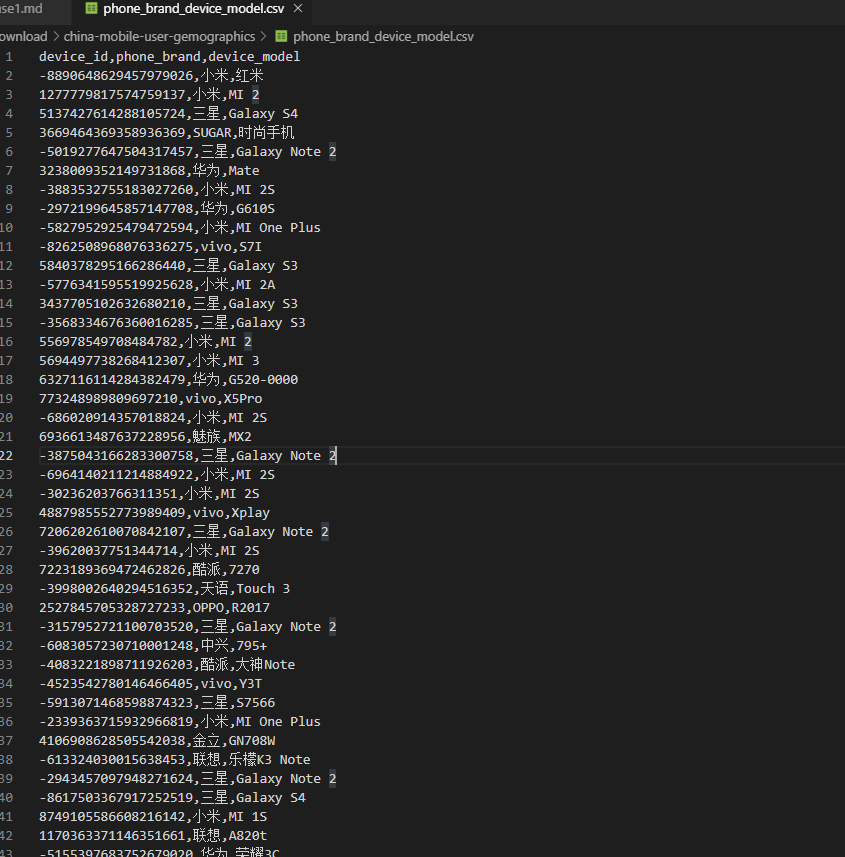
ImportTSV
测试导入这么一张CSV数据文件:
使用HBase-Mapreduce包下的的ImportTsv程序,这个程序的使用方法可以通过看文档:ImportTsv或者查阅源码的方式来学习使用,这里简单翻译概述一下其用法:
importTsv是将TSV格式的数据加载到HBASE中的实用工具。它有两种不同的用法:通过PUT将TSV格式的HDFS数据加载到HBASE,或生成StoreFiles通过completebulkload加载到HBase。
将给定的TSV数据输入目录导入指定的表中。必须使用-Dimporttsv.columns指定TSV数据的列名。此选项采用逗号分隔的列名形式,其中每个列名可以是一个简单的列族,也可以是一个columnfamily:qualifier。特殊的列名HBASE_ROW_KEY用于指定应该使用该列作为每个导入记录的行键。你必须精确地指定一列要成为RowKey,且必须为每个存在的列指定列名。
By default importtsv will load data directly into HBase. To instead generate
HFiles of data to prepare for a bulk data load, pass the option:
-Dimporttsv.bulk.output=/path/for/output
Note: the target table will be created with default column family descriptors if it does not already exist.
Other options that may be specified with -D include:
-Dimporttsv.skip.bad.lines=false - fail if encountering an invalid line
'-Dimporttsv.separator=|' - eg separate on pipes instead of tabs
-Dimporttsv.timestamp=currentTimeAsLong - use the specified timestamp for the import
-Dimporttsv.mapper.class=my.Mapper - A user-defined Mapper to use instead of org.apache.hadoop.hbase.mapreduce.TsvImporterMapper
hadoop fs -put phone.csv /mydata #上传文件到HDFS
cd ${HADOOP_HOME}
##以下三行为一条命令
bin/hadoop jar ../hbase-2.1.6/lib/hbase-mapreduce-2.1.6.jar importtsv \
'-Dimporttsv.separator=,' \
-Dimporttsv.columns=HBASE_ROW_KEY,orderInfo:phone_brand,orderInfo:device_model phone hdfs://Master:9000/mydata/phone.csv
通过源码可以得知默认的列分隔符是"\t",根据情况写参数,部分默认值:
......
final static String DEFAULT_SEPARATOR = "\t";
final static String DEFAULT_ATTRIBUTES_SEPERATOR = "=>";
final static String DEFAULT_MULTIPLE_ATTRIBUTES_SEPERATOR = ",";
final static Class DEFAULT_MAPPER = TsvImporterMapper.class;
......
执行完成后:
......
Map-Reduce Framework
Map input records=39
Map output records=39
Input split bytes=100
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=232
CPU time spent (ms)=2380
Physical memory (bytes) snapshot=132243456
Virtual memory (bytes) snapshot=2129027072
Total committed heap usage (bytes)=22409216
ImportTsv
Bad Lines=0
File Input Format Counters
Bytes Read=1376
......
......
hbase(main):016:0> scan 'phone'
ROW COLUMN+CELL
-2339363715932966819 column=orderInfo:device_model, timestamp=1570458713990, value=MI One Plus
-2339363715932966819 column=orderInfo:phone_brand, timestamp=1570458713990, value=\xE5\xB0\x8F\xE7\xB1\xB3
-2943457097948271624 column=orderInfo:device_model, timestamp=1570458713990, value=Galaxy Note 2
-2943457097948271624 column=orderInfo:phone_brand, timestamp=1570458713990, value=\xE4\xB8\x89\xE6\x98\x9F
-2972199645857147708 column=orderInfo:device_model, timestamp=1570458713990, value=G610S
-2972199645857147708 column=orderInfo:phone_brand, timestamp=1570458713990, value=\xE5\x8D\x8E\xE4\xB8\xBA
-30236203766311351 column=orderInfo:device_model, timestamp=1570458713990, value=MI 2S
-30236203766311351 column=orderInfo:phone_brand, timestamp=1570458713990, value=\xE5\xB0\x8F\xE7\xB1\xB3
-3157952721100703520 column=orderInfo:device_model, timestamp=1570458713990, value=Galaxy Note 2
-3157952721100703520 column=orderInfo:phone_brand, timestamp=1570458713990, value=\xE4\xB8\x89\xE6\x98\x9F
-3568334676360016285 column=orderInfo:device_model, timestamp=1570458713990, value=Galaxy S3
......
补充:KeyValue
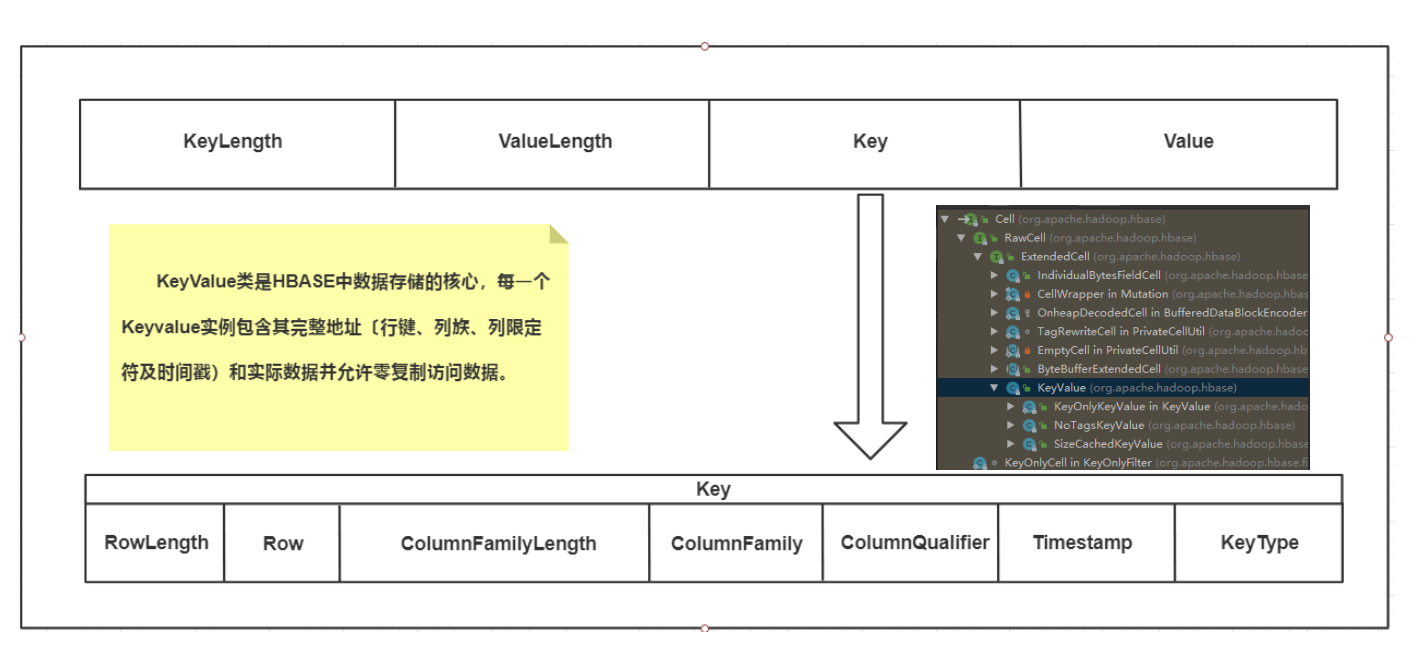
KeyValue类是HBASE中数据存储的核心,每一个KeyValue实例包含其完整地址〔行键、列族、列限定符及时间戳)和实际数据并允许零复制访问数据。KeyValue封装一个字节数组,并在传递的数组中提取偏移量和长度,该数组指定从何处开始将内容解释为KeyValue。字节数组中的KeyValue格式组成是KeyLength、ValueLength、Key、Value。
该结构以两个分别表示键长度(KeyLengh)和值长度(ValueLengh)的定长数字开始。有了这个信息,用户就可以在数据中跳跃,例如,可以忽略键直接访问值。其他情况下,用户也可以从键中获取必要的信息。一旦其被转换成一个KeyValue的Java实例,用户就能通过对应的getter方法得到更多的细节信息,
Key进一步分解为:RowLength、Row、ColumnFamilyLength、ColumnFamily、ColumnQualifier、Timestamp、KeyType
· 未完部分
- HBase架构和存储
- HBase表设计和事务、高级模式
- HBase集群监控和管理
- HBase性能优化
......
Mark一下,随缘更新,看书...
HBase学习与实践的更多相关文章
- hadoop2.5.2学习及实践笔记(二)—— 编译源代码及导入源码至eclipse
生产环境中hadoop一般会选择64位版本,官方下载的hadoop安装包中的native库是32位的,因此运行64位版本时,需要自己编译64位的native库,并替换掉自带native库. 源码包下的 ...
- ansible 学习与实践
title: ansible 学习与实践 date: 2016-05-06 16:17:28 tags: --- ansible 学习与实践 一 介绍 ansible是新出现的运维工具是基于Pytho ...
- Google App Engine 学习和实践
这个周末玩了玩Google App Engine,随手写点东西,算是学习笔记吧.不当之处,请多多指正. 作者:liigo,2009/04/26夜,大连 原创链接:http://blog.csdn.ne ...
- PMBOK 学习与实践分享视频
本系列为自己在学习PMBOK时进行的总结与分享,每一节主要包括两部分: 对PMBOK本身的一个结构笔记和讲解. 对自己项目管理工作的一个总结和思考. PMBOK 学习与实践分享视频内容清单 人力资源管 ...
- NLP+词法系列(二)︱中文分词技术简述、深度学习分词实践(CIPS2016、超多案例)
摘录自:CIPS2016 中文信息处理报告<第一章 词法和句法分析研究进展.现状及趋势>P4 CIPS2016 中文信息处理报告下载链接:http://cips-upload.bj.bce ...
- Weex学习与实践
Weex学习与实践(一):Weex,你需要知道的事 本文主要介绍包括Weex基本介绍.Weex源码结构.初始化工程.we代码结构.Weex的生命周期.Weex的工作原理.页面间通信.boxmodel ...
- 免考final linux提权与渗透入门——Exploit-Exercise Nebula学习与实践
免考final linux提权与渗透入门--Exploit-Exercise Nebula学习与实践 0x0 前言 Exploit-Exercise是一系列学习linux下渗透的虚拟环境,官网是htt ...
- RabbitMQ学习系列四-EasyNetQ文档跟进式学习与实践
EasyNetQ文档跟进式学习与实践 https://www.cnblogs.com/DjlNet/p/7603554.html 这里可能有人要问了,为什么不使用官方的nuget包呐:RabbitMQ ...
- 孤荷凌寒自学python第七十天学习并实践beautifulsoup对象用法3
孤荷凌寒自学python第七十天学习并实践beautifulsoup对象用法3 (完整学习过程屏幕记录视频地址在文末) 今天继续学习beautifulsoup对象的属性与方法等内容. 一.今天进一步了 ...
随机推荐
- P2762 太空飞行计划问题 最大权闭合子图
link:https://www.luogu.org/problemnew/show/P2762 题意 承担实验赚钱,但是要花去对应仪器的费用,仪器可能共用.求最大的收益和对应的选择方案. 思路 这道 ...
- POJ-3660 Cow Contest( 最短路 )
题目链接:http://poj.org/problem?id=3660 Description N (1 ≤ N ≤ 100) cows, conveniently numbered 1..N, ar ...
- hdu 2615 Division(暴力)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2615 题解:挺简单的暴力枚举,小小的分治主要是看没人写题解就稍微写一下 #include <io ...
- 左偏树 P3377【模板】左偏树(可并堆)
题目传送门 代码: /* code by: zstu wxk time: 2019/03/01 */ #include<bits/stdc++.h> using namespace std ...
- 天梯杯 L2-003. 月饼
L2-003. 月饼 时间限制 100 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不 ...
- 【Offer】[23] 【链表中环的入口结点】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 一个链表中包含环,如何找出环的入口结点?  思路分析 判断链表中是否有环:用快慢指针的方法,慢指针走一步,快指针走两步,如果快指针追上 ...
- 解开Batch Normalization的神秘面纱
停更博客好长一段时间了,其实并不是没写了,而是转而做笔记了,但是发现做笔记其实印象无法更深刻,因此决定继续以写博客来记录或者复习巩固所学的知识,与此同时跟大家分享下自己对深度学习或者机器学习相关的知识 ...
- 【LeetCode】524-通过删除字母匹配到字典里最长单词
题目描述 给定一个字符串和一个字符串字典,找到字典里面最长的字符串,该字符串可以通过删除给定字符串的某些字符来得到.如果答案不止一个,返回长度最长且字典顺序最小的字符串.如果答案不存在,则返回空字符串 ...
- rpm简单使用
rpm描述:利用源码包编译成rpm时,会去指定安装好这个包的位置本质:解压,然后拷贝到相关的目录,然后执行脚本 vstpd-3.0.2-9.el7.x86_64.rpm 包名 版本 release 架 ...
- 安全性测试:OWASP ZAP 2.8 使用指南(二):ZAP基础操作
ZAP桌面应用 ZAP桌面应用由以下元素组成: 1. 菜单栏 – 提供多种自动化和手动工具的访问 2. 工具栏 – 提供快速访问最常用组件的用户接口 3. 树结构窗口 – 展示被测网站树结构和脚 ...