Python网络爬虫_Scrapy框架_2.logging模块的使用
logging模块提供日志服务
在scrapy框架中已经对其进行一些操作所以使用更为简单

在Scrapy框架中使用:
1.在setting.py文件中设置LOG_LEVEL(设置日志等级,只有高于等于本等级的日志会显示)
LOG_FILE(设置日志保存位置,设定后不会在终端显示日志)

2.实例化logger(getLogger方法可以显示__name__也就是文件名)
logger.warning("消息"): 以waring等级输出日志消息
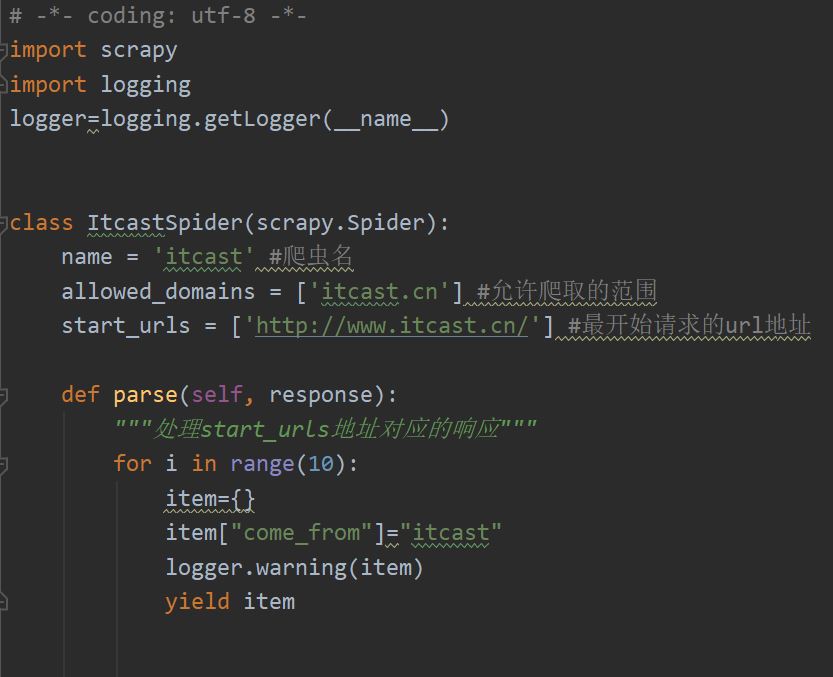

在普通文件中使用:
该代码只显示消息 HDU, 没有其他日志信息


在普通文件中使用logging需要自定义日志格式


logging模块详细学习:https://blog.csdn.net/zyz511919766/article/details/25136485
Python网络爬虫_Scrapy框架_2.logging模块的使用的更多相关文章
- Python网络爬虫_Scrapy框架_1.新建项目
在Pycharm中新建一个基于Scrapy框架的爬虫项目(Scrapy库已经导入) 在终端中输入: ''itcast.cn''是为爬虫限定爬取范围 创建完成后的目录 将生成的itcast.py文件移动 ...
- 【python网络爬虫】之requests相关模块
python网络爬虫的学习第一步 [python网络爬虫]之0 爬虫与反扒 [python网络爬虫]之一 简单介绍 [python网络爬虫]之二 python uillib库 [python网络爬虫] ...
- Python网络爬虫-Scrapy框架
一.简介 Spider是所有爬虫的基类,其设计原则只是为了爬取start_url列表中网页,而从爬取到的网页中提取出的url进行继续的爬取工作使用CrawlSpider更合适. 二.使用 1.创建sc ...
- Python网络爬虫Scrapy框架研究
看到一个爬虫比较完整的教程.保留一下. https://github.com/yidao620c/core-scrapy
- Python网络爬虫Scrapy框架研究 以及 代理设置
地址:https://github.com/yidao620c/core-scrapy 例子:https://github.com/geekan/scrapy-examples 中文翻译文档: htt ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 学习推荐《精通Python网络爬虫:核心技术、框架与项目实战》中文PDF+源代码
随着大数据时代的到来,我们经常需要在海量数据的互联网环境中搜集一些特定的数据并对其进行分析,我们可以使用网络爬虫对这些特定的数据进行爬取,并对一些无关的数据进行过滤,将目标数据筛选出来.对特定的数据进 ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
随机推荐
- OSC2019关于开源的见闻-开源让世界更美好 社会更文明
一.开源生态报告-红薯-开源中国创始人 1.协作乏力-大厂同样 2.协议许可证使用不当 新许可证-木兰 3.开发者对法律认识完全不够 著作权意识不够 红线意识不够 相关法律法规的熟悉不够 维权及其弱势 ...
- ESP8266调试(UDP调试)
1.设置STA模式 AT+CWMODE=1 2.加入热点 AT+CWJAP="Admin_name","password" 3.开启单路连接 AT+CIPMUX ...
- 导入做好的java项目出现下面的错误:The project cannot be built until build path errors are resolved
例子: 作者在eclipse中导入一个新的项目时,出现了三个错误,如图1中所示: 图1 3 errors 原因分析: 在这个工程中,作者在写的时候,在build path中添 ...
- 7个点说清楚spring cloud微服务架构
前言 spring cloud作为当下主流的微服务框架,让我们实现微服务架构简单快捷,spring cloud中各个组件在微服务架构中扮演的角色如下图所示,黑线表示注释说明,蓝线由A指向B,表示B从A ...
- 《MySQL数据库》MySQL数据库安装(windows)
MySQL安装包和操作工具 链接: https://pan.baidu.com/s/1BTfrHwVR1uNBuB_E27N55g 提取码: dhbv 1.首先解压文件包,我这解压到E:\instal ...
- Docker图形化工具Portainer详解
一.介绍 说明: Portainer是易于使用的软件,可为软件开发人员和IT操作人员提供直观的界面. Portainer为你提供Docker环境的详细概述,并允许你管理容器,镜像,网络和数据卷 ...
- 爬虫(七):BeatifulSoup模块
1. Beautiful Soup介绍 Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库.能将即将要进行解析的源码加载到bs对象,调用bs对象中相关的方法或属性进 ...
- 【前端学习】网页tab键的实现 01
友情提醒:阅读本文需要了解一些基本的html/Css/Javascript知识 前端常用tab键的实现,用到的原理是当点击一个元素时,通过javascript操作css的display属性,达到控制另 ...
- 弹性盒子中的order
order order 属性 设置或检索弹性盒模型对象的子元素出现的順序.. 注意:如果元素不是弹性盒对象的元素,则 order 属性不起作用. <!DOCTYPE html> <h ...
- 【iOS bug记录】UICollectionviewCell刷新变得这么莫名其妙?
项目是一个即时聊天的社交软件,聊天流采用的是UICollectionView,随着进度的完善,发现一个特别的bug,UICollectionviewCell的复用,并没有直接insert进去,而是出现 ...