Netty网络框架
Netty网络框架
Netty是一个异步的基于事件驱动的网络框架。
为什么要使用Netty而不直接使用JAVA中的NIO
1.Netty支持三种IO模型同时支持三种Reactor模式。
2.Netty支持很多应用层的协议,提供了很多decoder和encoder。
3.Netty能够解决TCP长连接所带来的缺陷(粘包、半包等)
4.Netty支持应用层的KeepAlive。
5.Netty规避了JAVA NIO中的很多BUG,性能更好。
Netty启动服务端
1.创建bossGroup和workerGroup(bossGroup负责接收连接,workerGroup负责处理连接的读写就绪事件)
2.创建ServerBootstrap服务端启动对象,并且调用group()方法传入刚刚创建的bossGroup和workerGroup。
3.调用ServerBootstrap的channel()方法,配置父Channel,一般为NioServerSocketChannel。
4.调用ServerBootstrap的childHandler()方法,配置子Channel与ChannelHandler之间的关系,传入ChannelInitializer实现类,实现initChannel()方法,方法中获取Channel的ChannelPileline,然后往ChannelPipeline中添加ChannelHandler。
5.调用ServerBootstrap的option()方法给父Channel配置参数。
6.调用ServerBootstrap的childOption()方法给子Channel配置参数。
7.绑定端口,启动服务。
private void start() {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap
.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class) // 配置父Channel
.childHandler(new ChannelInitializer<SocketChannel>() { // 配置子Channel与ChannelHandler之间的关系
@Override
protected void initChannel(SocketChannel socketChannel) {
// 往ChannelPipeline中添加ChannelHandler
socketChannel.pipeline().addLast(
new HttpRequestDecoder(),
new HttpObjectAggregator(65535),
new HttpResponseEncoder(),
new HttpServerHandler()
);
}
})
.option(ChannelOption.SO_BACKLOG, 128) // 给父Channel配置参数
.childOption(ChannelOption.SO_KEEPALIVE, true); // 给子Channel配置参数
try {
// 绑定端口,启动服务
System.out.println("start server and bind 8888 port ...");
serverBootstrap.bind(8888).sync();
} catch (InterruptedException e) {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
Netty启动客户端
1.创建workerGroup,负责处理连接的读写就绪事件。
2.创建Bootstrap客户端启动对象,并且调用group()方法传入刚刚创建的workerGroup。
3.调用Bootstrap的channel()方法,配置父Channel,一般为NioSocketChannel。
4.调用Bootstrap的option()方法,给父Channel配置参数。
5.调用Bootstrap的handler()方法,配置父Channel与ChannelHandler之间的关系。
6.连接服务器。
private void start() {
EventLoopGroup workerGroup = new NioEventLoopGroup();
Bootstrap bootstrap = new Bootstrap();
bootstrap.group(workerGroup)
.channel(NioSocketChannel.class) // 配置父Channel
.option(ChannelOption.SO_KEEPALIVE, true) // 给父Channel配置参数
.handler(new ChannelInitializer<SocketChannel>() { // 配置父Channel与ChannelHandler之间的关系
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
socketChannel.pipeline().addLast(new TimeClientHandler());
}
});
try {
bootstrap.connect(new InetSocketAddress(8888)).sync(); // 连接服务器
} catch (InterruptedException e) {
workerGroup.shutdownGracefully();
}
}
ChannelInBoundHandler接口声明了事件的处理方法
channelActive():当接收到一个新的连接时调用该方法
handlerAdd():当往Channel的ChannelPipeline中添加ChannelHandler时调用该方法
handlerRemove():当移除ChannelPipeline中的ChannelHandler时调用该方法
channelRead():当Channel有数据可读时调用该方法
exceptionCaught():当在处理事件发生异常时调用该方法
ServerSocketChannel每接收到一个新的连接时都会调用ChannelInitializer的initChannel()方法,初始化Channel与ChannelHandler之间的关系,最后调用ChannelHandler的handlerAdd()和channelActive()方法。
关于ChannelPipeline
ChannelPipeline底层使用双向链表。

当Channel有数据可读时,会沿着链表从前往后寻找有IN性质的Handler进行处理。
当Channel写入数据时,会沿着链表从后往前寻找有OUT性质的Handler进行处理。
关于write()和flush()方法
S1[Channel的write方法] --将数据写入到缓冲区--> buffer[缓冲区];
S2[Channel的flush方法] --发送缓冲区中的数据并清空--> buffer[缓冲区];
buffer --发送--> S3[SocketChannel];
write():将数据写入到缓冲区
flush():发送缓冲区中的数据并进行清空
writeAndFlush():将数据写入到缓冲区,同时发送缓冲区中的数据并进行清空
Channel的writeAndFlush()和flush()方法会从链表的最后一个节点开始从后往前寻找有OUT性质的Handler进行处理。
ChannelHandlerContext的writeAndFlush()和flush()方法会从当前节点从后往前寻找有OUT性质的Handler进行处理。
关于写就绪事件
当SocketChannel可以写入数据时,将会触发写就绪事件,所以一般不能随便监听,否则将会一直触发。
当SocketChannel在写入数据写不进时(缓冲区已经满了),此时可以将Channel注册到Selector当中并且向Selector传递要监听此Channel的写就绪事件,然后强制发送缓冲区中的数据并进行清空,此时将会触发写就绪事件,当处理完写就绪事件后,应该从Selector当中剔除对此Channel的监听。
为什么说Netty中的所有操作都是异步的
Channel中的所有任务都会放入到其绑定的EventLoop的任务队列中,然后等待被EventLoop中的线程处理。
关于ChannelFuture
由于Netty中的所有操作都是异步的,因此一般会返回ChannelFuture对象,用于存储Channel异步执行的结果。
当创建ChannelFuture实例时,isDone()方法返回false,仅当ChannelFuture被设置成成功或者失败时,isDone()方法才返回true。
可以往ChannelFuture中添加ChannelFutureListener,当任务被执行完毕后由IO线程自动调用。
Netty中的ByteBuf
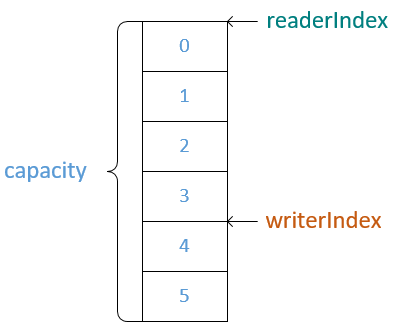
ByteBuf有readerIndex和writerIndex两个指针,默认都为0,当进行写操作时移动writerIndex指针,读操作时移动readerIndex指针。
可读容量 = writerIndex - readerIndex
*只有read()/write()方法才会移动指针,get()/set()方法不会移动指针。
*ByteBuf支持动态扩容。
ByteBuf的创建和管理
使用ByteBufAllocator来创建和管理ByteBuf,其分别提供PooledByteBufAllocator和UnpooledByteBufAllocator实现类,分别代表池化和非池化。
*Netty同时也提供了Pooled和Unpooled工具类来创建和管理ByteBuf。
池化的ByteBuf(Pooled)
每次使用时都从池中取出一个ByteBuf对象,当使用完毕后再放回到池中。
每个ByteBuf都有一个refCount属性,仅当refCount属性为0时才将ByteBuf对象放回到池中。
ByteBuf的release()方法可以使refCount属性减1(一般由最后一个访问ByteBuf的Handler进行处理)
非池化的ByteBuf(Unpooled)
每次使用时都创建一个新的ByteBuf对象。
使用池化ByteBuf的风险
如果每次使用ByteBuf后却不进行释放,那么有可能发生内存泄漏,对象池中会不停的创建ByteBuf对象。
非池化的ByteBuf对象能够依赖JVM自动进行回收。
关于堆内和堆外的ByteBuf
池化和非池化的ByteBufAllocator中都可以创建堆内和堆外的ByteBuf对象。
堆外的ByteBuf可以避免在进行IO操作时数据从堆内内存复制到操作系统内存的过程,所以对于IO操作来说一般使用堆外的ByteBuf,而对于内部业务数据处理来说使用堆内的ByteBuf。
Netty支持的IO模型
Netty支持BIO、NIO、AIO三种IO模型。

*其中AIO模型只在Netty的5.x版本有提供,但不建议使用,因为Netty不再维护同时也废除了5.x版本,其原因是在Linux中AIO比NIO强不了多少。
Netty如何切换IO模型
只需要将EventLoopGroup和ServerSocketChannel换成相应IO模型的API即可。
Netty中使用Reactor模式
Reactor单线程模式
EventLoopGroup eventLoopGroup = new NioEventLoopGroup(1);
Reactor多线程模式

EventLoopGroup eventLoopGroup = new NioEventLoopGroup();
*默认CPU核数 x 2个EventLoop。
主从Reactor多线程模式

EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
关于TCP的粘包和半包
粘包(多个数据包被合并成一个进行发送)
data1[ABC] --> compact[ABCDEF];
data2[DEF] --> compact;
compact --send--> net[网络]
半包(一个数据包被拆分成多个进行发送)
data1[ABCDEF] --> part1[ABC];
data1 --> part2[DEF];
part1 --send--> net1[网络];
part2 --send--> net2[网络];
发生粘包的原因
1.写入的数据远小于缓冲区的大小,TCP协议为了性能的考虑,合并后再进行发送。
发生半包的原因
1.写入的数据大于缓冲区的大小,因此必须拆包后再进行传输(缓冲区已满,强制flush)
2.写入的数据大于协议的MTU(最大传输单元),因此必须拆包后再进行传输。
TCP长连接的缺陷

长连接中可以发送多个请求,同时TCP协议是流式协议,消息无边界,所以有一个很棘手的问题,接收方怎么去知道一个请求中的数据到底是哪里到哪里,以及一个请求中的数据有可能是粘包后的结果,同时多个请求中的数据有可能是半包后的结果。
解决方案
1.使用短连接,连接开始和连接结束之间的数据就是请求的数据。
2.使用固定的长度,每个请求中的数据都使用固定的长度,接收方以接收到固定长度的数据来确定一个完整的请求数据。
3.使用指定的分隔符,每个请求中的数据的末尾都加上一个分隔符,接收方以分隔符来确定一个完整的请求数据。
4.使用特定长度的字段去存储请求数据的长度,接收方根据请求数据的长度来确定一个完整的请求数据。
Netty对TCP长连接缺陷的解决方案
FixedLengthFrameDecoder:使用固定的长度
DelimiterBasedFrameDecoder:使用指定的分隔符
LengthFieldBasedFrameDecoder:使用特定长度的字段去存储请求数据的长度
关于TCP的KeepAlive
正常情况下双方建立连接后是不会断开的,KeepAlive就是防止连接双方中的任意一方由于意外断开而通知不到对方,导致对方一直持有连接,占用资源(发现对方不可用,断开连接)。
*建立连接需要三次握手、正常断开连接需要四次挥手。
KeepAlive有三个核心参数
net.ipv4.tcp_keepalive_timeout:连接的超时时间(默认7200s)
net.ipv4.tcp_keepalive_intvl:发送探测包的间隔(默认75s)
tnet.ipv4.cp_keepalive_probes:发送探测包的个数(默认9个)
这三个参数都是系统参数,会影响部署在机器上的所有应用。
KeepAlive的开关是在应用层开启的,只有当应用层开启了KeepAlive,KeepAlive才会生效。
java.net.Socket.setKeepAlive(boolean on);
当连接在指定时间内没有发送请求时,开启KeepAlive的一端就会向对方发送一个探测包,如果对方没有回应,则每隔指定时间发送一个探测包,总共发送指定个探测包,如果对方都没有回应则认为对方不可用,断开连接。
为什么要做应用层的KeepAlive
1.KeepAlive参数是系统参数,对于应用来说不够灵活。
2.默认检测一个不可用的连接所需要的时间太长。
怎么做应用层的KeepAlive
1.定时任务
客户端定期向所有已经建立连接的服务端发送心跳检测,如果服务端连续没有回应指定个心跳检测,则认为对方不可用,此时客户端应该重连。
服务端定期向所有已经建立连接的客户端发送心跳检测,如果客户端连续没有回应指定个心跳检测,则认为对方不可用,此时应该断开连接。
2.计时器
连接在指定时间内没有发送请求则认为对方不可用
Netty对KeepAlive的支持
Netty开启KeepAlive
Bootstrap.option(ChannelOption.SO_KEEPALIVE,true);
ServerBootstrap.childOption(ChannelOption.SO_KEEPALIVE,true);
Netty提供的KeepAlive机制
Netty提供的IdleStateHandler能够检测处于Idle状态的连接。
Idle状态类型
reader_idle:SocketChannel在指定时间内都没有数据可读
writer_idle:SocketChannel在指定时间内没有写入数据
all_idle:SocketChannel在指定时间内没有数据可读或者没有写入数据
直接将IdleStateHandler添加到ChannelPipeline即可,当Netty检测到处于Idle状态的连接时,将会自动调用其Handler的userEventTriggered()方法,用户只需要在该方法中判断Idle状态的类型,然后做出相应的处理。
关于HTTP的KeepAlive
HTTP的KeepAlive是对长连接和短连接的选择,并不是保持连接存活的一种机制。
HTTP是基于请求和响应的,客户端发送请求给服务端然后等待服务端的响应,当服务端检测到请求头中包含Connection:KeepAlive时,表示客户端使用长连接,此时服务端应该保持连接,当检测到请求头中包含Connection:close时,表示客户端使用短连接,此时服务端应该主动断开连接。
TCP并不是基于请求和响应的,客户端可以发送请求给服务端,同时服务端也可以发送请求给客户端。
Netty网络框架的更多相关文章
- 基于NIO的Netty网络框架
Netty是一个高性能.异步事件驱动的NIO框架,它提供了对TCP.UDP和文件传输的支持,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机制,用户可以方便的主动获取或者 ...
- 【从0到1】android网络框架的选型参考
项目会使用到 socket tcp 级的网络访问,想选取一个使用较成熟异步网络框架, 提到的网络框架: 1. volley, 2. xutils. 3. android 4. netty, 5. mi ...
- Spark1.6之后为何使用Netty通信框架替代Akka
解决方案: 一直以来,基于Akka实现的RPC通信框架是Spark引以为豪的主要特性,也是与Hadoop等分布式计算框架对比过程中一大亮点. 但是时代和技术都在演化,从Spark1.3.1版本开始,为 ...
- 关于Unity的网络框架
注:Unity 5.1里引入了新的网络框架,未来目标应该是WOW那样的,现在还只是个P2P的架子. 网络的框架,无非是如何管理网络数据的收发,通信双方如何约定协议.之前做的框架与GameObject无 ...
- 事件驱动之Twsited异步网络框架
在这之前先了解下什么是事件驱动编程 传统的编程是如下线性模式的: 开始--->代码块A--->代码块B--->代码块C--->代码块D--->......--->结 ...
- GJM : Unity3D 常用网络框架与实战解析 【笔记】
Unity常用网络框架与实战解析 1.Http协议 Http协议 存在TCP 之上 有时候 TLS\SSL 之上 默认端口80 https 默认端口 ...
- Android网络框架源码分析一---Volley
转载自 http://www.jianshu.com/p/9e17727f31a1?utm_campaign=maleskine&utm_content=note&utm_medium ...
- Twsited异步网络框架
Twisted是一个事件驱动的网络框架,其中包含了诸多功能,例如:网络协议.线程.数据库管理.网络操作.电子邮件等. Twisted介绍:http://blog.csdn.net/hanhuili/a ...
- Android中android-async-http开源网络框架的简单使用
android-async-http开源网络框架是专门针对Android在Apache的基础上构建的异步且基于回调的http client.所有的请求全在UI线程之外发生,而callback发生在创建 ...
随机推荐
- Spring Cloud alibaba网关 sentinel zuul 四 限流熔断
spring cloud alibaba 集成了 他内部开源的 Sentinel 熔断限流框架 Sentinel 介绍 官方网址 随着微服务的流行,服务和服务之间的稳定性变得越来越重要.Sentine ...
- Unity5-ABSystem(三):AssetBundle加载
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/lodypig/article/detai ...
- vue学习笔记-遗留问题记录
Node.js是什么?对node.js的理解 官网解释:Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时. 这是一种通过JavaScript语言开发web服务端的东 ...
- 第三十五章 POSIX共享内存
POSIX共享内存函数介绍 shm_open 功能: 用来创建或打开一个共享内存对象 原型: int shm_open(const char *name, int oflag, mode_t mode ...
- Vue学习笔记(五)——配置开发环境及初建项目
前言 在上一篇中,我们通过初步的认识,简单了解 Vue 生命周期的八个阶段,以及可以应用在之后的开发中,针对不同的阶段的钩子采取不同的操作,更好的实现我们的业务代码,处理更加复杂的业务逻辑. 而在这一 ...
- Scrapy爬虫day1——环境配置
安装 Scrapy pip install scrapy 配置虚拟环境 mkvirtualenv Spider 创建项目 在Spider的虚拟环境中运行 scrapy startproject Boo ...
- Python语言基础04-函数和模块的使用
本文收录在Python从入门到精通系列文章系列 在分享本章节的内容之前,先来研究一道数学题,请说出下面的方程有多少组正整数解. 事实上,上面的问题等同于将8个苹果分成四组每组至少一个苹果有多少种方案. ...
- 小白学 Python(21):生成器基础
人生苦短,我选Python 前文传送门 小白学 Python(1):开篇 小白学 Python(2):基础数据类型(上) 小白学 Python(3):基础数据类型(下) 小白学 Python(4):变 ...
- 1011课堂小结 day21
组合 什么是组合 组合指的是一个对象中的属性,是另一个对象. 为什么要使用组合 为了减少代码冗余 封装 什么是封装 封装指的是把一堆属性(特征与技能)封装到一个对象中 为什么要封装 封装的目的为了方便 ...
- Redis实战--Jedis实现分布式锁
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 分布式 ...