MySql的数据库优化到底优化啥了都(3)
嘟嘟在上两个文章里面简单粗糙的讲了讲关于MySql存储引擎的一些特性以及选择。个人感觉如果面试官给我机会的话,至少能说个10分钟了吧。只可惜有时候生活就是这样:骨感的皮包骨头了还在那美呢。牢骚两句,北京的夏天真的是热的胶粘。昨天上班儿忙到了晚上11点多,本想着昨儿晚上就把关于数据库优化的文章写完了,今天就能写个关于高并发的。结果嘟嘟这个小屋子就好比那商务大洗浴的汗蒸房一样。嘟嘟昨夜属实有点晕乎。只好晚上锻炼锻炼身体之后看了一集《长安十二时辰》。。。。。话不多说,今天学学关于索引的一些问题。
索引简介
优点
(索引可以大大大大大大的提高查询性能!)
1.通过创建唯一性索引,保证数据库每一行数据的唯一性
2.大大加快检索速度
3.加速表和表之间的连接
4.减少查询中分组和排序的时间
5.通过使用索引,在查询的过程中,使用查询优化器,提高系统性能
缺点
1.创建索引和维护索引消耗时间,这种时间随数据量增加而增加
2.索引需要占用物理空间,如果建立聚簇索引,占用空间更大
3.如果表中增删改,索引需要动态维护,降低数据的维护速度
什么字段适合创建索引
1.常搜索的列上,加快搜索速度
2.主键列上(MySql 在主键上面默认增加索引)
3.常用的连接列上(外键),加快连接速度
4.在经常根据范围进行搜索的列上创建索引,因为索引已经排序,其指定范围是连续的 (a between xxx and xxx 但是不是 in (5,10,15)这种)可以在a上面加上索引
5.经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加速查询时间
6.经常使用where子句中的列上创建索引,加快条件的判断速度
需要注意的一点是 :比如在 where f1。。。 and f2。。。,那么我们在字段f1或者f2上建立索引是没有用的,只有在f1和f2上同时建立索引才有用
什么样的字段不适合创建索引
1.查询中很少使用到的,或者参考的列就没必要加索引
2.数据值相对少的列也不适合。举个极端点的栗子:people 字段有20万条。sex 字段有三条(男,女,不男不女) 在sex字段上面添加索引就是没有用的
3.大文本数据不应该增加索引。
4.经常增删改,但是查询比较少的时候就不需要做索引啦
停停停停!因为索引的具体介绍涉及到了关于查找机制(怎么查找一个东西更快的方法)的一些问题,所以嘟嘟先在这里恶补一下查找的相关机制,便于后面继续学习索引种类。
1.树是什么玩应?(B-Tree ,这 Tree 那Tree的)
首先一棵小树,必须先有一个根,然后依靠这个根来开枝散叶。就形成了一棵树。
2.怎么查询快?
设想一下,如果在查找一大堆数据的过程中,我们能依靠某些办法,去舍弃一些没有必要去查找的东西。那么查找的速度就会比一个一个查的速度快的多。
基于以上两点,网上给大家扒下来一棵能够让我们查找数据时候快一些的树
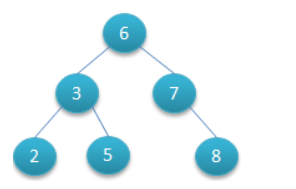
6那个地方是根, 258 是叶子,37是分支,235678的值叫做键值
1. 这棵树的形成是有一定的规则的:
根的左边(235)叫做左子树,根的右边(78)叫做右子树,首先第一个规则就是右子树的键值要大于根键值,左子树相反。
2. 给定的这6个数字235678为什么就把根选成6了?因为6是中间数,至于为什么不是5?嘟嘟个人觉得也可以,就这么画呗:
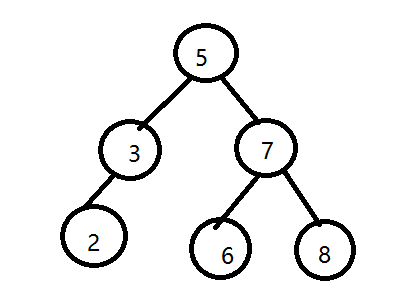
3.我们把每一个数值对应的那个点叫做节点。那么我这棵树也满足上边的那个规则:相对于每一个节点,他左侧的子节点都会比他小,右侧的子节点都会比他大。
4.这么做有什么好处呢?用嘟嘟自己画的那张图为例子奥,比如嘟嘟要查6这个数字需要查几次?(1)先查到了5,发现6比5大 ,根据规则,往右侧走到了7。(2)发现6比7小根据规则往左侧走到了6!查完了。用了两步。那么正常按照顺序查询的话,就不一定查多少次了。
5.那么6个随机数字,在我们按照上述规则进行排序之后想要查询一个数字,需要查询多少次?(1)查询第一个数字5需要一步.(2)查询第二层数字3或者7需要2次并且有两种可能,意思是你想查3需要两次,你想查7也得需要两次。(3) 同理,在查询第三层的数字的时候3种可能,并且第三层的任意数字你都需要查三次。所以平均下来就是:
(1+2+2+3+3+3)/(1+2+3)=2.3次平均
相比正常排序的查询(1+2+3+4+5+6)/6=3.5次 查询确实快了一些。原因就是通过比大小的方式,将一些没有必要查询的数字给舍弃了。
6.听说这种树叫做二叉树。而二叉树也有别的画法:
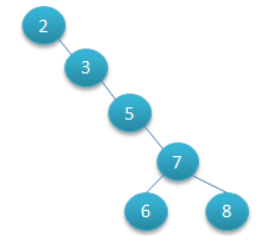
(很明显这种数的查询效率就底下) (1+2+3+4+5+5)/6=3.3次
针对上面那个效率低下的二叉树,就又引入一条规则,进而产生了一种平衡二叉树(AVL Tree)
1.这条规则就是,对于任何一个节点下面的两个子树的高度差都<=1
嘟嘟个人推测这种平衡的机制可以保证搜索效率的最大化(因为嘟嘟时间有限,这个结论是看上面三颗树对比之下的效率感觉的)
2.如果在一棵已经平衡的树上面增加一个数,减少一个数,或者修改一个数,树的平衡就可能被打破了(嘿嘿嘿,嘟嘟想起来文章开头写的,如果某些字段经常发生增删改就不太适合使用索引,因为平衡机制被打破了得话,就得重新耗费资源区重构这种平衡)。
3.如果平衡被打破,需要重构(通过一种叫做旋转的办法保证二叉树的平衡,详细的流程嘟嘟推荐大家看看别的博客),旋转的方式嘟嘟在这里就不再赘述了,意思就是通过位置的调换,保证二叉树的原则就是了。
B-Tree(平衡多路查找树)
1.B-Tree 是针对磁盘等外存储设备设计的一种平衡查找树
2.为什么会出现B-Tree 这种查找机制呢? 因为InnoDB 存储引擎,InnoDB管理磁盘的最小单位是页(16KB),而磁盘存储数据的最小单位是磁盘块block(远远小于16KB),这就造成了,InnoDB在进行数据读取(比如查找的时候)会将连续的好几个磁盘块读入(老子必须读够16KB!)。这是个硬伤。因为读取也是浪费资源的。而InnoDB你一次读的太多了。
3.针对2中读的太多的问题。如果有一种查找机制可以继续减少查找的时候IO的次数,就会降低资源的浪费。
4.B-Tree诞生了。
下面这张图片能够比较完美的诠释B-Tree的特性
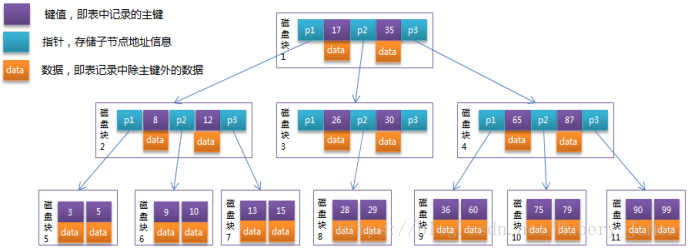
嘟嘟在别的哥哥的博客上扒下来的图片。第一眼看的时候可能是因为天气太热,有点晕乎。但是睡一觉起床以后再看它(MD豁然开朗)
1.首先每一个磁盘块都是一个节点,每个节点都有三个指针两条数据。
2.数据都是以【key,data】的方式存储的。每条指针都存储子节点的地址。两条数据的key值是从小到大排序。
3.于是乎以磁盘块1为例子,就形成了三个区间 {小于17的,17至35的,35以上的},并分别有不同的指针指向对应的磁盘块。
4.对比平衡二叉树的话,在单次的选择上,二叉树只能选择出到底我要查询的数是比现在大还是比现在小(也就是2选1),而B-Tree每一次可以选择出来我要查的数具体在哪个区间(多选一),导向更加精确,自然查询次数会更少。
关于索引和查找的相关介绍。嘟嘟就讲到这里啦,下次嘟嘟会继续学习关于具体索引的知识。以上写的东西嘟嘟基本上是粗浅理解了一下然后现学现卖。毕竟嘟嘟是个新手,对数据结构与算法什么的并没有太高的要求。但是理解一下,既为以后打下一个引子,又不至于学的脑袋疼。
MySql的数据库优化到底优化啥了都(3)的更多相关文章
- MySql的数据库优化到底优啥了都??(1)
嘟嘟最不愿意做的就是翻招聘信息. 因为一翻招聘信息,工作经历你写低于两年都不好意思,前后端必须炉火纯青融汇贯通,各式框架必须如数家珍不写精通咋的你也得熟练熟练, 对了你是985吗?你是211吗??你不 ...
- 【mysql】数据库Schema的优化
由于MySQL数据库是基于行(Row)存储的数据库,而数据库操作 IO 的时候是以 page(block)的方式,也就是说,如果我们每条记录所占用的空间量减小,就会使每个page中可存放的数据行数增大 ...
- MySql的数据库优化到底优啥了都??(2)
嘟嘟在写此篇文章之前心里先默念(简单,通俗,工整)*10 吟唱完了,进入正题 3.Memory存储引擎 除了存放一个表结构相关信息的.frm文件在磁盘上,其他数据都存储在内存中.说白点哪天你数据库死机 ...
- mysql之数据库添加索引优化查询效率
项目中如果表中的数据过多的话,会影响查询的效率,那么我们需要想办法优化查询,通常添加索引就是我们的选择之一: 1.添加PRIMARY KEY(主键索引) mysql>ALTER TABLE `t ...
- 第 8 章 MySQL 数据库 Query 的优化
前言: 在之前“影响 MySQL 应用系统性能的相关因素”一章中我们就已经分析过了Query语句对数据库性能的影响非常大,所以本章将专门针对 MySQL 的 Query 语句的优化进行相应的分析. ...
- MySQL 数据库 Query 的优化
理解MySQL的Query Optimizer MySQL Optimizer是一个专门负责优化SELECT 语句的优化器模块,它主要的功能就是通过计算分析系统中收集的各种统计信息,为客户端请求的Qu ...
- MySQL性能调优与架构设计——第8章 MySQL数据库Query的优化
第8章 MySQL数据库Query的优化 前言: 在之前“影响 MySQL 应用系统性能的相关因素”一章中我们就已经分析过了Query语句对数据库性能的影响非常大,所以本章将专门针对 MySQL 的 ...
- (5)MySQL进阶篇SQL优化(优化数据库对象)
1.概述 在数据库设计过程中,用户可能会经常遇到这种问题:是否应该把所有表都按照第三范式来设计?表里面的字段到底改设置为多大长度合适?这些问题虽然很小,但是如果设计不当则可能会给将来的应用带来很多的性 ...
- MySQL数据库高并发优化配置
在Apache, PHP, mysql的体系架构中,MySQL对于性能的影响最大,也是关键的核心部分.对于Discuz!论坛程序也是如此,MySQL的设置是否合理优化,直接 影响到论坛的速度和承载量! ...
随机推荐
- 如何自学PHP做一个网站 PHP可以做什么项目?网站 小程序 公众号能用PHP开发吗?
很多想从事程序开发的人员,想自学一门语言,不知道从哪里下手学习,如何入门学习?今天我们就以PHP为例子,来讲述一下如何快速的学习一门开发语言,让你快速入门.PHP是一个什么语言?它能开发什么项目呢?下 ...
- Unity 通用透明物体漫反射Shader(双面渲染&多光源&光照衰减&法线贴图&凹凸透明度控制)
Shader "MyUnlit/AlphaBlendDiffuse" { Properties { _Color("Color Tint(贴图染色)",Colo ...
- Flume —— 安装部署
一.前置条件 Flume需要依赖JDK 1.8+,JDK安装方式见本仓库: Linux环境下JDK安装 二 .安装步骤 2.1 下载并解压 下载所需版本的Flume,这里我下载的是CDH版本的Flum ...
- ZooKeeper学习之路(二)—— Zookeeper单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 下载对应版本Zookeeper,这里我下载的版本3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # w ...
- spring cloud 系列第3篇 —— ribbon 客户端负载均衡 (F版本)
源码仓库地址:https://github.com/heibaiying/spring-samples-for-all 一.ribbon 简介 ribbon是Netfix公司开源的负载均衡组件,采用服 ...
- 【转载】JDK自带的log工具
版权声明:本文为Jaiky_杰哥原创,转载请注明出处.This blog is written by Jaiky, reproduced please indicate. https://blog.c ...
- ajax:error:function (XMLHttpRequest, textStatus, errorThrown) 中status、readyState和textStatus状态意义
textStatus: "timeout", 超时 "error", 出错 "notmodified" , 未修改 "parser ...
- iOS开发系列之性能优化(上)
本篇主要记录一下我对界面优化上的一些探索.关于时间优化的探索将会在中篇里进行介绍.下篇将主要介绍一些耗电优化.安装包瘦身的探索. ### 1.卡顿原理 要了解卡顿原理,需要对帧缓冲区.垂直同步.CPU ...
- 分布式事务(1)---2PC和3PC理论
分布式事务(1)---2PC和3PC理论 分布式事物基本理论:基本遵循CPA理论,采用柔性事物特征,软状态或者最终一致性特点保证分布式事物一致性问题. 分布式事物常见解决方案: 2PC两段提交协议 3 ...
- HDU 1724:Ellipse(自适应辛普森积分)
题目链接 题意 给出一个椭圆,问一个[l, r] 区间(蓝色区域)的面积是多少. 思路 自适应辛普森积分 具体一些分析如上. 很方便,套上公式就可以用了. 注意 eps 的取值影响了跑的时间,因为决定 ...