[C2P1] Andrew Ng - Machine Learning
About this Course
Machine learning is the science of getting computers to act without being explicitly programmed. In the past decade, machine learning has given us self-driving cars, practical speech recognition, effective web search, and a vastly improved understanding of the human genome. Machine learning is so pervasive today that you probably use it dozens of times a day without knowing it. Many researchers also think it is the best way to make progress towards human-level AI. In this class, you will learn about the most effective machine learning techniques, and gain practice implementing them and getting them to work for yourself. More importantly, you'll learn about not only the theoretical underpinnings of learning, but also gain the practical know-how needed to quickly and powerfully apply these techniques to new problems. Finally, you'll learn about some of Silicon Valley's best practices in innovation as it pertains to machine learning and AI.
This course provides a broad introduction to machine learning, datamining, and statistical pattern recognition. Topics include: (i) Supervised learning (parametric/non-parametric algorithms, support vector machines, kernels, neural networks). (ii) Unsupervised learning (clustering, dimensionality reduction, recommender systems, deep learning). (iii) Best practices in machine learning (bias/variance theory; innovation process in machine learning and AI). The course will also draw from numerous case studies and applications, so that you'll also learn how to apply learning algorithms to building smart robots (perception, control), text understanding (web search, anti-spam), computer vision, medical informatics, audio, database mining, and other areas.
Introduction
Welcome to Machine Learning! In this module, we introduce the core idea of teaching a computer to learn concepts using data—without being explicitly programmed. The Course Wiki is under construction. Please visit the resources tab for the most complete and up-to-date information.
5 videos, 4 readings
Video: Welcome to Machine Learning!
What is machine learning? You probably use it dozens of times a day without even knowing it. Each time you do a web search on Google or Bing, that works so well because their machine learning software has figured out how to rank what pages. When Facebook or Apple's photo application recognizes your friends in your pictures, that's also machine learning. Each time you read your email and a spam filter saves you from having to wade through tons of spam, again, that's because your computer has learned to distinguish spam from non-spam email. So, that's machine learning. There's a science of getting computers to learn without being explicitly programmed. One of the research projects that I'm working on is getting robots to tidy up the house. How do you go about doing that? Well what you can do is have the robot watch you demonstrate the task and learn from that. The robot can then watch what objects you pick up and where to put them and try to do the same thing even when you aren't there. For me, one of the reasons I'm excited about this is the AI, or artificial intelligence problem. Building truly intelligent machines, we can do just about anything that you or I can do. Many scientists think the best way to make progress on this is through learning algorithms called neural networks, which mimic how the human brain works, and I'll teach you about that, too. In this class, you learn about machine learning and get to implement them yourself. I hope you sign up on our website and join us.
Video: Welcome
Welcome to this free online class on machine learning. Machine learning is one of the most exciting recent technologies. And in this class, you learn about the state of the art and also gain practice implementing and deploying these algorithms yourself. You've probably use a learning algorithm dozens of times a day without knowing it. Every time you use a web search engine like Google or Bing to search the internet, one of the reasons that works so well is because a learning algorithm, one implemented by Google or Microsoft, has learned how to rank web pages. Every time you use Facebook or Apple's photo typing application and it recognizes your friends' photos, that's also machine learning. Every time you read your email and your spam filter saves you from having to wade through tons of spam email, that's also a learning algorithm. For me one of the reasons I'm excited is the AI dream of someday building machines as intelligent as you or me. We're a long way away from that goal, but many AI researchers believe that the best way to towards that goal is through learning algorithms that try to mimic how the human brain learns. I'll tell you a little bit about that too in this class. In this class you learn about state-of-the-art machine learning algorithms. But it turns out just knowing the algorithms and knowing the math isn't that much good if you don't also know how to actually get this stuff to work on problems that you care about. So, we've also spent a lot of time developing exercises for you to implement each of these algorithms and see how they work fot yourself. So why is machine learning so prevalent today? It turns out that machine learning is a field that had grown out of the field of AI, or artificial intelligence. We wanted to build intelligent machines and it turns out that there are a few basic things that we could program a machine to do such as how to find the shortest path from A to B. But for the most part we just did not know how to write AI programs to do the more interesting things such as web search or photo tagging or email anti-spam. There was a realization that the only way to do these things was to have a machine learn to do it by itself. So, machine learning was developed as a new capability for computers and today it touches many segments of industry and basic science. For me, I work on machine learning and in a typical week I might end up talking to helicopter pilots, biologists, a bunch of computer systems people (so my colleagues here at Stanford) and averaging two or three times a week I get email from people in industry from Silicon Valley contacting me who have an interest in applying learning algorithms to their own problems. This is a sign of the range of problems that machine learning touches. There is autonomous robotics, computational biology, tons of things in Silicon Valley that machine learning is having an impact on. Here are some other examples of machine learning. There's database mining. One of the reasons machine learning has so pervaded is the growth of the web and the growth of automation All this means that we have much larger data sets than ever before. So, for example tons of Silicon Valley companies are today collecting web click data, also called clickstream data, and are trying to use machine learning algorithms to mine this data to understand the users better and to serve the users better, that's a huge segment of Silicon Valley right now. Medical records. With the advent of automation, we now have electronic medical records, so if we can turn medical records into medical knowledge, then we can start to understand disease better. Computational biology. With automation again, biologists are collecting lots of data about gene sequences, DNA sequences, and so on, and machines running algorithms are giving us a much better understanding of the human genome, and what it means to be human. And in engineering as well, in all fields of engineering, we have larger and larger, and larger and larger data sets, that we're trying to understand using learning algorithms. A second range of machinery applications is ones that we cannot program by hand. So for example, I've worked on autonomous helicopters for many years. We just did not know how to write a computer program to make this helicopter fly by itself. The only thing that worked was having a computer learn by itself how to fly this helicopter. [Helicopter whirling]
4:37
Handwriting recognition. It turns out one of the reasons it's so inexpensive today to route a piece of mail across the countries, in the US and internationally, is that when you write an envelope like this, it turns out there's a learning algorithm that has learned how to read your handwriting so that it can automatically route this envelope on its way, and so it costs us a few cents to send this thing thousands of miles. And in fact if you've seen the fields of natural language processing or computer vision, these are the fields of AI pertaining to understanding language or understanding images. Most of natural language processing and most of computer vision today is applied machine learning. Learning algorithms are also widely used for self- customizing programs. Every time you go to Amazon or Netflix or iTunes Genius, and it recommends the movies or products and music to you, that's a learning algorithm. If you think about it they have million users; there is no way to write a million different programs for your million users. The only way to have software give these customized recommendations is to become learn by itself to customize itself to your preferences. Finally learning algorithms are being used today to understand human learning and to understand the brain. We'll talk about how researches are using this to make progress towards the big AI dream. A few months ago, a student showed me an article on the top twelve IT skills. The skills that information technology hiring managers cannot say no to. It was a slightly older article, but at the top of this list of the twelve most desirable IT skills was machine learning. Here at Stanford, the number of recruiters that contact me asking if I know any graduating machine learning students is far larger than the machine learning students we graduate each year. So I think there is a vast, unfulfilled demand for this skill set, and this is a great time to be learning about machine learning, and I hope to teach you a lot about machine learning in this class. In the next video, we'll start to give a more formal definition of what is machine learning. And we'll begin to talk about the main types of machine learning problems and algorithms. You'll pick up some of the main machine learning terminology, and start to get a sense of what are the different algorithms, and when each one might be appropriate.
Video: What is Machine Learning?
What is machine learning? In this video, we will try to define what it is and also try to give you a sense of when you want to use machine learning. Even among machine learning practitioners, there isn't a well accepted definition of what is and what isn't machine learning. But let me show you a couple of examples of the ways that people have tried to define it. Here's a definition of what is machine learning as due to Arthur Samuel. He defined machine learning as the field of study that gives computers the ability to learn without being explicitly learned.
0:33
Samuel's claim to fame was that back in the 1950, he wrote a checkers playing program and the amazing thing about this checkers playing program was that Arthur Samuel himself wasn't a very good checkers player. But what he did was he had to programmed maybe tens of thousands of games against himself, and by watching what sorts of board positions tended to lead to wins and what sort of board positions tended to lead to losses, the checkers playing program learned over time what are good board positions and what are bad board positions. And eventually learn to play checkers better than the Arthur Samuel himself was able to. This was a remarkable result. Arthur Samuel himself turns out not to be a very good checkers player. But because a computer has the patience to play tens of thousands of games against itself, no human has the patience to play that many games. By doing this, a computer was able to get so much checkers playing experience that it eventually became a better checkers player than Arthur himself.
1:32
This is a somewhat informal definition and an older one. Here's a slightly more recent definition by Tom Mitchell who's a friend of Carnegie Melon. So Tom defines machine learning by saying that a well-posed learning problem is defined as follows. He says, a computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. I actually think he came out with this definition just to make it rhyme. For the checkers playing examples, the experience E would be the experience of having the program play tens of thousands of games itself. The task T would be the task of playing checkers, and the performance measure P will be the probability that wins the next game of checkers against some new opponent.
2:24
Throughout these videos, besides me trying to teach you stuff, I'll occasionally ask you a question to make sure you understand the content. Here's one.
2:33
On top is a definition of machine learning by Tom Mitchell. Let's say your email program watches which emails you do or do not mark as spam. So in an email client like this, you might click the Spam button to report some email as spam but not other emails. And based on which emails you mark as spam, say your email program learns better how to filter spam email. What is the task T in this setting? In a few seconds, the video will pause and when it does so, you can use your mouse to select one of these four radio buttons to let me know which of these four you think is the right answer to this question.
3:16
So hopefully you got that this is the right answer, classifying emails is the task T. In fact, this definition defines a task T performance measure P and some experience E. And so, watching you label emails as spam or not spam, this would be the experience E and and the fraction of emails correctly classified, that might be a performance measure P. And so on the task of systems performance, on the performance measure P will improve after the experience E.
3:55
In this class, I hope to teach you about various different types of learning algorithms. There are several different types of learning algorithms. The main two types are what we call supervised learning and unsupervised learning. I'll define what these terms mean more in the next couple videos. It turns out that in supervised learning, the idea is we're going to teach the computer how to do something. Whereas in unsupervised learning, we're going to let it learn by itself. Don't worry if these two terms don't make sense yet. In the next two videos, I'm going to say exactly what these two types of learning are. You might also hear other ghost terms such as reinforcement learning and recommender systems. These are other types of machine learning algorithms that we'll talk about later. But the two most use types of learning algorithms are probably supervised learning and unsupervised learning. And I'll define them in the next two videos and we'll spend most of this class talking about these two types of learning algorithms. It turns out what are the other things to spend a lot of time on in this class is practical advice for applying learning algorithms. This is something that I feel pretty strongly about. And exactly something that I don't know if any other university teachers. Teaching about learning algorithms is like giving a set of tools. And equally important or more important than giving you the tools as they teach you how to apply these tools. I like to make an analogy to learning to become a carpenter. Imagine that someone is teaching you how to be a carpenter, and they say, here's a hammer, here's a screwdriver, here's a saw, good luck. Well, that's no good. You have all these tools but the more important thing is to learn how to use these tools properly.
5:36
There's a huge difference between people that know how to use these machine learning algorithms, versus people that don't know how to use these tools well. Here, in Silicon Valley where I live, when I go visit different companies even at the top Silicon Valley companies, very often I see people trying to apply machine learning algorithms to some problem and sometimes they have been going at for six months. But sometimes when I look at what their doing, I say, I could have told them like, gee, I could have told you six months ago that you should be taking a learning algorithm and applying it in like the slightly modified way and your chance of success will have been much higher. So what we're going to do in this class is actually spend a lot of the time talking about how if you're actually trying to develop a machine learning system, how to make those best practices type decisions about the way in which you build your system. So that when you're finally learning algorithim, you're less likely to end up one of those people who end up persuing something after six months that someone else could have figured out just a waste of time for six months. So I'm actually going to spend a lot of time teaching you those sorts of best practices in machine learning and AI and how to get the stuff to work and how the best people do it in Silicon Valley and around the world. I hope to make you one of the best people in knowing how to design and build serious machine learning and AI systems. So that's machine learning, and these are the main topics I hope to teach. In the next video, I'm going to define what is supervised learning and after that what is unsupervised learning. And also time to talk about when you would use each of them.
Reading: What is Machine Learning?
What is Machine Learning?
Two definitions of Machine Learning are offered. Arthur Samuel described it as: "the field of study that gives computers the ability to learn without being explicitly programmed." This is an older, informal definition.
Tom Mitchell provides a more modern definition: "A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."
Example: playing checkers.
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
In general, any machine learning problem can be assigned to one of two broad classifications:
Supervised learning and Unsupervised learning.
Video: Supervised Learning
In this video, I'm going to define what is probably the most common type of Machine Learning problem, which is Supervised Learning. I'll define Supervised Learning more formally later, but it's probably best to explain or start with an example of what it is, and we'll do the formal definition later. Let's say you want to predict housing prices. A while back a student collected data sets from the City of Portland, Oregon, and let's say you plot the data set and it looks like this. Here on the horizontal axis, the size of different houses in square feet, and on the vertical axis, the price of different houses in thousands of dollars. So, given this data, let's say you have a friend who owns a house that is say 750 square feet, and they are hoping to sell the house, and they want to know how much they can get for the house. So, how can the learning algorithm help you? One thing a learning algorithm might be want to do is put a straight line through the data, also fit a straight line to the data. Based on that, it looks like maybe their house can be sold for maybe about \$150,000. But maybe this isn't the only learning algorithm you can use, and there might be a better one. For example, instead of fitting a straight line to the data, we might decide that it's better to fit a quadratic function, or a second-order polynomial to this data. If you do that and make a prediction here, then it looks like, well, maybe they can sell the house for closer to \$200,000. One of the things we'll talk about later is how to choose, and how to decide, do you want to fit a straight line to the data? Or do you want to fit a quadratic function to the data? There's no fair picking whichever one gives your friend the better house to sell. But each of these would be a fine example of a learning algorithm. So, this is an example of a Supervised Learning algorithm. The term Supervised Learning refers to the fact that we gave the algorithm a data set in which the, called, "right answers" were given. That is we gave it a data set of houses in which for every example in this data set, we told it what is the right price. So, what was the actual price that that house sold for, and the task of the algorithm was to just produce more of these right answers such as for this new house that your friend may be trying to sell. To define a bit more terminology, this is also called a regression problem. By regression problem, I mean we're trying to predict a continuous valued output. Namely the price. So technically, I guess prices can be rounded off to the nearest cent. So, maybe prices are actually discrete value. But usually, we think of the price of a house as a real number, as a scalar value, as a continuous value number, and the term regression refers to the fact that we're trying to predict the sort of continuous values attribute. Here's another Supervised Learning examples. Some friends and I were actually working on this earlier. Let's say you want to look at medical records and try to predict of a breast cancer as malignant or benign. If someone discovers a breast tumor, a lump in their breast, a malignant tumor is a tumor that is harmful and dangerous, and a benign tumor is a tumor that is harmless. So obviously, people care a lot about this. Let's see collected data set. Suppose you are in your dataset, you have on your horizontal axis the size of the tumor, and on the vertical axis, I'm going to plot one or zero, yes or no, whether or not these are examples of tumors we've seen before are malignant, which is one, or zero or not malignant or benign. So, let's say your dataset looks like this, where we saw a tumor of this size that turned out to be benign, one of this size, one of this size, and so on. Sadly, we also saw a few malignant tumors cell, one of that size, one of that size, one of that size, so on. So in this example, I have five examples of benign tumors shown down here, and five examples of malignant tumors shown with a vertical axis value of one. Let's say a friend who tragically has a breast tumor, and let's say her breast tumor size is maybe somewhere around this value, the Machine Learning question is, can you estimate what is the probability, what's the chance that a tumor as malignant versus benign? To introduce a bit more terminology, this is an example of a classification problem. The term classification refers to the fact, that here, we're trying to predict a discrete value output zero or one, malignant or benign. It turns out that in classification problems, sometimes you can have more than two possible values for the output. As a concrete example, maybe there are three types of breast cancers. So, you may try to predict a discrete value output zero, one, two, or three, where zero may mean benign, benign tumor, so no cancer, and one may mean type one cancer, maybe three types of cancer, whatever type one means, and two mean a second type of cancer, and three may mean a third type of cancer. But this will also be a classification problem because this are the discrete value set of output corresponding to you're no cancer, or cancer type one, or cancer type two, or cancer types three. In classification problems, there is another way to plot this data. Let me show you what I mean. I'm going to use a slightly different set of symbols to plot this data. So, if tumor size is going to be the attribute that I'm going to use to predict malignancy or benignness, I can also draw my data like this. I'm going to use different symbols to denote my benign and malignant, or my negative and positive examples. So, instead of drawing crosses, I'm now going to draw O's for the benign tumors, like so, and I'm going to keep using X's to denote my malignant tumors. I hope this figure makes sense. All I did was I took my data set on top, and I just mapped it down to this real line like so, and started to use different symbols, circles and crosses to denote malignant versus benign examples. Now, in this example, we use only one feature or one attribute, namely the tumor size in order to predict whether a tumor is malignant or benign. In other machine learning problems, when we have more than one feature or more than one attribute. Here's an example, let's say that instead of just knowing the tumor size, we know both the age of the patients and the tumor size. In that case, maybe your data set would look like this, where I may have a set of patients with those ages, and that tumor size, and they look like this, and different set of patients that look a little different, whose tumors turn out to be malignant as denoted by the crosses. So, let's say you have a friend who tragically has a tumor, and maybe their tumor size and age falls around there. So, given a data set like this, what the learning algorithm might do is fit a straight line to the data to try to separate out the malignant tumors from the benign ones, and so the learning algorithm may decide to put a straight line like that to separate out the two causes of tumors. With this, hopefully we can decide that your friend's tumor is more likely, if it's over there that hopefully your learning algorithm will say that your friend's tumor falls on this benign side and is therefore more likely to be benign than malignant. In this example, we had two features namely, the age of the patient and the size of the tumor. In other Machine Learning problems, we will often have more features. My friends that worked on this problem actually used other features like these, which is clump thickness, clump thickness of the breast tumor, uniformity of cell size of the tumor, uniformity of cell shape the tumor, and so on, and other features as well. It turns out one of the most interesting learning algorithms that we'll see in this course, as the learning algorithm that can deal with not just two, or three, or five features, but an infinite number of features. On this slide, I've listed a total of five different features. Two on the axis and three more up here. But it turns out that for some learning problems what you really want is not to use like three or five features, but instead you want to use an infinite number of features, an infinite number of attributes, so that your learning algorithm has lots of attributes, or features, or cues with which to make those predictions. So, how do you deal with an infinite number of features? How do you even store an infinite number of things in the computer when your computer is going to run out of memory? It turns out that when we talk about an algorithm called the Support Vector Machine, there will be a neat mathematical trick that will allow a computer to deal with an infinite number of features. Imagine that I didn't just write down two features here and three features on the right, but imagine that I wrote down an infinitely long list. I just kept writing more and more features, like an infinitely long list of features. It turns out we will come up with an algorithm that can deal with that. So, just to recap, in this course, we'll talk about Supervised Learning, and the idea is that in Supervised Learning, in every example in our data set, we are told what is the correct answer that we would have quite liked the algorithms have predicted on that example. Such as the price of the house, or whether a tumor is malignant or benign. We also talked about the regression problem, and by regression that means that our goal is to predict a continuous valued output. We talked about the classification problem where the goal is to predict a discrete value output. Just a quick wrap up question. Suppose you're running a company and you want to develop learning algorithms to address each of two problems. In the first problem, you have a large inventory of identical items. So, imagine that you have thousands of copies of some identical items to sell, and you want to predict how many of these items you sell over the next three months. In the second problem, problem two, you have lots of users, and you want to write software to examine each individual of your customer's accounts, so each one of your customer's accounts. For each account, decide whether or not the account has been hacked or compromised. So, for each of these problems, should they be treated as a classification problem or as a regression problem? When the video pauses, please use your mouse to select whichever of these four options on the left you think is the correct answer.
11:19
So hopefully, you got that. This is the answer. For problem one, I would treat this as a regression problem because if I have thousands of items, well, I would probably just treat this as a real value, as a continuous value. Therefore, the number of items I sell as a continuous value. For the second problem, I would treat that as a classification problem, because I might say set the value I want to predict with zero to denote the account has not been hacked, and set the value one to denote an account that has been hacked into. So, just like your breast cancers where zero is benign, one is malignant. So, I might set this be zero or one depending on whether it's been hacked, and have an algorithm try to predict each one of these two discrete values. Because there's a small number of discrete values, I would therefore treat it as a classification problem. So, that's it for Supervised Learning. In the next video, I'll talk about Unsupervised Learning, which is the other major category of learning algorithm.
Reading: Supervised Learning
Supervised Learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
Supervised learning problems are categorized into "regression" and "classification" problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
Example 1:
Given data about the size of houses on the real estate market, try to predict their price. Price as a function of size is a continuous output, so this is a regression problem.
We could turn this example into a classification problem by instead making our output about whether the house "sells for more or less than the asking price." Here we are classifying the houses based on price into two discrete categories.
Example 2:
(a) Regression - Given a picture of a person, we have to predict their age on the basis of the given picture
(b) Classification - Given a patient with a tumor, we have to predict whether the tumor is malignant or benign.
Video: Unsupervised Learning
In this video, we'll talk about the second major type of machine learning problem, called Unsupervised Learning.
0:06
In the last video, we talked about Supervised Learning. Back then, recall data sets that look like this, where each example was labeled either as a positive or negative example, whether it was a benign or a malignant tumor.
0:20
So for each example in Supervised Learning, we were told explicitly what is the so-called right answer, whether it's benign or malignant. In Unsupervised Learning, we're given data that looks different than data that looks like this that doesn't have any labels or that all has the same label or really no labels.
0:39
So we're given the data set and we're not told what to do with it and we're not told what each data point is. Instead we're just told, here is a data set. Can you find some structure in the data? Given this data set, an Unsupervised Learning algorithm might decide that the data lives in two different clusters. And so there's one cluster
0:59
and there's a different cluster.
1:01
And yes, Supervised Learning algorithm may break these data into these two separate clusters.
1:06
So this is called a clustering algorithm. And this turns out to be used in many places.
1:11
One example where clustering is used is in Google News and if you have not seen this before, you can actually go to this URL news.google.com to take a look. What Google News does is everyday it goes and looks at tens of thousands or hundreds of thousands of new stories on the web and it groups them into cohesive news stories.
1:30
For example, let's look here.
1:33
The URLs here link to different news stories about the BP Oil Well story.
1:41
So, let's click on one of these URL's and we'll click on one of these URL's. What I'll get to is a web page like this. Here's a Wall Street Journal article about, you know, the BP Oil Well Spill stories of "BP Kills Macondo", which is a name of the spill and if you click on a different URL
2:00
from that group then you might get the different story. Here's the CNN story about a game, the BP Oil Spill,
2:07
and if you click on yet a third link, then you might get a different story. Here's the UK Guardian story about the BP Oil Spill.
2:16
So what Google News has done is look for tens of thousands of news stories and automatically cluster them together. So, the news stories that are all about the same topic get displayed together. It turns out that clustering algorithms and Unsupervised Learning algorithms are used in many other problems as well.
2:35
Here's one on understanding genomics.
2:38
Here's an example of DNA microarray data. The idea is put a group of different individuals and for each of them, you measure how much they do or do not have a certain gene. Technically you measure how much certain genes are expressed. So these colors, red, green, gray and so on, they show the degree to which different individuals do or do not have a specific gene.
3:02
And what you can do is then run a clustering algorithm to group individuals into different categories or into different types of people.
3:10
So this is Unsupervised Learning because we're not telling the algorithm in advance that these are type 1 people, those are type 2 persons, those are type 3 persons and so on and instead what were saying is yeah here's a bunch of data. I don't know what's in this data. I don't know who's and what type. I don't even know what the different types of people are, but can you automatically find structure in the data from the you automatically cluster the individuals into these types that I don't know in advance? Because we're not giving the algorithm the right answer for the examples in my data set, this is Unsupervised Learning.
3:44
Unsupervised Learning or clustering is used for a bunch of other applications.
3:48
It's used to organize large computer clusters.
3:51
I had some friends looking at large data centers, that is large computer clusters and trying to figure out which machines tend to work together and if you can put those machines together, you can make your data center work more efficiently.
4:04
This second application is on social network analysis.
4:07
So given knowledge about which friends you email the most or given your Facebook friends or your Google+ circles, can we automatically identify which are cohesive groups of friends, also which are groups of people that all know each other?
4:22
Market segmentation.
4:24
Many companies have huge databases of customer information. So, can you look at this customer data set and automatically discover market segments and automatically
4:33
group your customers into different market segments so that you can automatically and more efficiently sell or market your different market segments together?
4:44
Again, this is Unsupervised Learning because we have all this customer data, but we don't know in advance what are the market segments and for the customers in our data set, you know, we don't know in advance who is in market segment one, who is in market segment two, and so on. But we have to let the algorithm discover all this just from the data.
5:01
Finally, it turns out that Unsupervised Learning is also used for surprisingly astronomical data analysis and these clustering algorithms gives surprisingly interesting useful theories of how galaxies are formed. All of these are examples of clustering, which is just one type of Unsupervised Learning. Let me tell you about another one. I'm gonna tell you about the cocktail party problem.
5:26
So, you've been to cocktail parties before, right? Well, you can imagine there's a party, room full of people, all sitting around, all talking at the same time and there are all these overlapping voices because everyone is talking at the same time, and it is almost hard to hear the person in front of you. So maybe at a cocktail party with two people,
5:45
two people talking at the same time, and it's a somewhat small cocktail party. And we're going to put two microphones in the room so there are microphones, and because these microphones are at two different distances from the speakers, each microphone records a different combination of these two speaker voices.
6:05
Maybe speaker one is a little louder in microphone one and maybe speaker two is a little bit louder on microphone 2 because the 2 microphones are at different positions relative to the 2 speakers, but each microphone would cause an overlapping combination of both speakers' voices.
6:23
So here's an actual recording
6:26
of two speakers recorded by a researcher. Let me play for you the first, what the first microphone sounds like. One (uno), two (dos), three (tres), four (cuatro), five (cinco), six (seis), seven (siete), eight (ocho), nine (nueve), ten (y diez).
6:41
All right, maybe not the most interesting cocktail party, there's two people counting from one to ten in two languages but you know. What you just heard was the first microphone recording, here's the second recording.
6:57
Uno (one), dos (two), tres (three), cuatro (four), cinco (five), seis (six), siete (seven), ocho (eight), nueve (nine) y diez (ten). So we can do, is take these two microphone recorders and give them to an Unsupervised Learning algorithm called the cocktail party algorithm, and tell the algorithm - find structure in this data for you. And what the algorithm will do is listen to these audio recordings and say, you know it sounds like the two audio recordings are being added together or that have being summed together to produce these recordings that we had. Moreover, what the cocktail party algorithm will do is separate out these two audio sources that were being added or being summed together to form other recordings and, in fact, here's the first output of the cocktail party algorithm.
7:39
One, two, three, four, five, six, seven, eight, nine, ten.
7:47
So, I separated out the English voice in one of the recordings.
7:52
And here's the second of it. Uno, dos, tres, quatro, cinco, seis, siete, ocho, nueve y diez. Not too bad, to give you
8:03
one more example, here's another recording of another similar situation, here's the first microphone : One, two, three, four, five, six, seven, eight, nine, ten.
8:16
OK so the poor guy's gone home from the cocktail party and he 's now sitting in a room by himself talking to his radio.
8:23
Here's the second microphone recording.
8:28
One, two, three, four, five, six, seven, eight, nine, ten.
8:33
When you give these two microphone recordings to the same algorithm, what it does, is again say, you know, it sounds like there are two audio sources, and moreover,
8:42
the album says, here is the first of the audio sources I found.
8:47
One, two, three, four, five, six, seven, eight, nine, ten.
8:54
So that wasn't perfect, it got the voice, but it also got a little bit of the music in there. Then here's the second output to the algorithm.
9:10
Not too bad, in that second output it managed to get rid of the voice entirely. And just, you know, cleaned up the music, got rid of the counting from one to ten.
9:18
So you might look at an Unsupervised Learning algorithm like this and ask how complicated this is to implement this, right? It seems like in order to, you know, build this application, it seems like to do this audio processing you need to write a ton of code or maybe link into like a bunch of synthesizer Java libraries that process audio, seems like a really complicated program, to do this audio, separating out audio and so on.
9:42
It turns out the algorithm, to do what you just heard, that can be done with one line of code - shown right here.
9:50
It take researchers a long time to come up with this line of code. I'm not saying this is an easy problem, But it turns out that when you use the right programming environment, many learning algorithms can be really short programs.
10:03
So this is also why in this class we're going to use the Octave programming environment.
10:08
Octave, is free open source software, and using a tool like Octave or Matlab, many learning algorithms become just a few lines of code to implement. Later in this class, I'll just teach you a little bit about how to use Octave and you'll be implementing some of these algorithms in Octave. Or if you have Matlab you can use that too.
10:27
It turns out the Silicon Valley, for a lot of machine learning algorithms, what we do is first prototype our software in Octave because software in Octave makes it incredibly fast to implement these learning algorithms.
10:38
Here each of these functions like for example the SVD function that stands for singular value decomposition; but that turns out to be a linear algebra routine, that is just built into Octave.
10:49
If you were trying to do this in C++ or Java, this would be many many lines of code linking complex C++ or Java libraries. So, you can implement this stuff as C++ or Java or Python, it's just much more complicated to do so in those languages.
11:03
What I've seen after having taught machine learning for almost a decade now, is that, you learn much faster if you use Octave as your programming environment, and if you use Octave as your learning tool and as your prototyping tool, it'll let you learn and prototype learning algorithms much more quickly.
11:22
And in fact what many people will do to in the large Silicon Valley companies is in fact, use an algorithm like Octave to first prototype the learning algorithm, and only after you've gotten it to work, then you migrate it to C++ or Java or whatever. It turns out that by doing things this way, you can often get your algorithm to work much faster than if you were starting out in C++.
11:44
So, I know that as an instructor, I get to say "trust me on this one" only a finite number of times, but for those of you who've never used these Octave type programming environments before, I am going to ask you to trust me on this one, and say that you, you will, I think your time, your development time is one of the most valuable resources.
12:04
And having seen lots of people do this, I think you as a machine learning researcher, or machine learning developer will be much more productive if you learn to start in prototype, to start in Octave, in some other language.
12:17
Finally, to wrap up this video, I have one quick review question for you.
12:24
We talked about Unsupervised Learning, which is a learning setting where you give the algorithm a ton of data and just ask it to find structure in the data for us. Of the following four examples, which ones, which of these four do you think would will be an Unsupervised Learning algorithm as opposed to Supervised Learning problem. For each of the four check boxes on the left, check the ones for which you think Unsupervised Learning algorithm would be appropriate and then click the button on the lower right to check your answer. So when the video pauses, please answer the question on the slide.
13:01
So, hopefully, you've remembered the spam folder problem. If you have labeled data, you know, with spam and non-spam e-mail, we'd treat this as a Supervised Learning problem.
13:11
The news story example, that's exactly the Google News example that we saw in this video, we saw how you can use a clustering algorithm to cluster these articles together so that's Unsupervised Learning.
13:23
The market segmentation example I talked a little bit earlier, you can do that as an Unsupervised Learning problem because I am just gonna get my algorithm data and ask it to discover market segments automatically.
13:35
And the final example, diabetes, well, that's actually just like our breast cancer example from the last video. Only instead of, you know, good and bad cancer tumors or benign or malignant tumors we instead have diabetes or not and so we will use that as a supervised, we will solve that as a Supervised Learning problem just like we did for the breast tumor data.
13:58
So, that's it for Unsupervised Learning and in the next video, we'll delve more into specific learning algorithms and start to talk about just how these algorithms work and how we can, how you can go about implementing them.
Reading: Unsupervised Learning
Unsupervised Learning
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don't necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results.
Example:
Clustering: Take a collection of 1,000,000 different genes, and find a way to automatically group these genes into groups that are somehow similar or related by different variables, such as lifespan, location, roles, and so on.
Non-clustering: The "Cocktail Party Algorithm", allows you to find structure in a chaotic environment. (i.e. identifying individual voices and music from a mesh of sounds at a cocktail party).
Reading: Lecture Slides
Linear Algebra Review
This optional module provides a refresher on linear algebra concepts. Basic understanding of linear algebra is necessary for the rest of the course, especially as we begin to cover models with multiple variables.
6 videos, 7 readings
Video: Matrices and Vectors
Let's get started with our linear algebra review.
0:02
In this video I want to tell you what are matrices and what are vectors.
0:09
A matrix is a rectangular array of numbers written between square brackets.
0:16
So, for example, here is a matrix on the right, a left square bracket.
0:22
And then, write in a bunch of numbers.
0:27
These could be features from a learning problem or it could be data from somewhere else, but
0:35
the specific values don't matter, and then I'm going to close it with another right bracket on the right. And so that's one matrix. And, here's another example of the matrix, let's write 3, 4, 5,6. So matrix is just another way for saying, is a 2D or a two dimensional array.
0:53
And the other piece of knowledge that we need is that the dimension of the matrix is going to be written as the number of row times the number of columns in the matrix. So, concretely, this example on the left, this has 1, 2, 3, 4 rows and has 2 columns,
1:14
and so this example on the left is a 4 by 2 matrix - number of rows by number of columns. So, four rows, two columns. This one on the right, this matrix has two rows. That's the first row, that's the second row, and it has three columns.
1:35
That's the first column, that's the second column, that's the third column So, this second matrix we say it is a 2 by 3 matrix.
1:45
So we say that the dimension of this matrix is 2 by 3.
1:50
Sometimes you also see this written out, in the case of left, you will see this written out as R4 by 2 or concretely what people will sometimes say this matrix is an element of the set R 4 by 2. So, this thing here, this just means the set of all matrices that of dimension 4 by 2 and this thing on the right, sometimes this is written out as a matrix that is an R 2 by 3. So if you ever see, 2 by 3. So if you ever see something like this are 4 by 2 or are 2 by 3, people are just referring to matrices of a specific dimension.
2:26
Next, let's talk about how to refer to specific elements of the matrix. And by matrix elements, other than the matrix I just mean the entries, so the numbers inside the matrix.
2:37
So, in the standard notation, if A is this matrix here, then A sub-strip IJ is going to refer to the i, j entry, meaning the entry in the matrix in the ith row and jth column.
2:51
So for example a1-1 is going to refer to the entry in the 1st row and the 1st column, so that's the first row and the first column and so a1-1 is going to be equal to 1, 4, 0, 2. Another example, 8 1 2 is going to refer to the entry in the first row and the second column and so A 1 2 is going to be equal to one nine one.
3:20
This come from a quick examples.
3:22
Let's see, A, oh let's say A 3 2, is going to refer to the entry in the 3rd row, and second column,
3:33
right, because that's 3 2 so that's equal to 1 4 3 7. And finally, 8 4 1 is going to refer to this one right, fourth row, first column is equal to 1 4 7 and if, hopefully you won't, but if you were to write and say well this A 4 3, well, that refers to the fourth row, and the third column that, you know, this matrix has no third column so this is undefined,
4:06
you know, or you can think of this as an error. There's no such element as 8 4 3, so, you know, you shouldn't be referring to 8 4 3. So, the matrix gets you a way of letting you quickly organize, index and access lots of data. In case I seem to be tossing up a lot of concepts, a lot of new notations very rapidly, you don't need to memorize all of this, but on the course website where we have posted the lecture notes, we also have all of these definitions written down. So you can always refer back, you know, either to these slides, possible coursework, so audible lecture notes if you forget well, A41 was that? Which row, which column was that? Don't worry about memorizing everything now. You can always refer back to the written materials on the course website, and use that as a reference. So that's what a matrix is. Next, let's talk about what is a vector. A vector turns out to be a special case of a matrix. A vector is a matrix that has only 1 column so you have an N x 1 matrix, then that's a remember, right? N is the number of rows, and 1 here is the number of columns, so, so matrix with just one column is what we call a vector. So here's an example of a vector, with I guess I have N equals four elements here.
5:23
so we also call this thing, another term for this is a four dmensional
5:30
vector, just means that
5:32
this is a vector with four elements, with four numbers in it. And, just as earlier for matrices you saw this notation R3 by 2 to refer to 2 by 3 matrices, for this vector we are going to refer to this as a vector in the set R4.
5:49
So this R4 means a set of four-dimensional vectors.
5:56
Next let's talk about how to refer to the elements of the vector.
6:01
We are going to use the notation yi to refer to the ith element of the vector y. So if y is this vector, y subscript i is the ith element. So y1 is the first element,four sixty, y2 is equal to the second element,
6:19
two thirty two -there's the first. There's the second. Y3 is equal to 315 and so on, and only y1 through y4 are defined consistency 4-dimensional vector.
6:32
Also it turns out that there are actually 2 conventions for how to index into a vector and here they are. Sometimes, people will use one index and sometimes zero index factors. So this example on the left is a one in that specter where the element we write is y1, y2, y3, y4.
6:53
And this example in the right is an example of a zero index factor where we start the indexing of the elements from zero.
7:01
So the elements go from a zero up to y three. And this is a bit like the arrays of some primary languages
7:09
where the arrays can either be indexed starting from one. The first element of an array is sometimes a Y1, this is sequence notation I guess, and sometimes it's zero index depending on what programming language you use. So it turns out that in most of math, the one index version is more common For a lot of machine learning applications, zero index
7:33
vectors gives us a more convenient notation.
7:36
So what you should usually do is, unless otherwised specified,
7:40
you should assume we are using one index vectors. In fact, throughout the rest of these videos on linear algebra review, I will be using one index vectors.
7:50
But just be aware that when we are talking about machine learning applications, sometimes I will explicitly say when we need to switch to, when we need to use the zero index
7:59
vectors as well. Finally, by convention, usually when writing matrices and vectors, most people will use upper case to refer to matrices. So we're going to use capital letters like A, B, C, you know, X, to refer to matrices,
8:16
and usually we'll use lowercase, like a, b, x, y,
8:21
to refer to either numbers, or just raw numbers or scalars or to vectors. This isn't always true but this is the more common notation where we use lower case "Y" for referring to vector and we usually use upper case to refer to a matrix.
8:37
So, you now know what are matrices and vectors. Next, we'll talk about some of the things you can do with them.
Reading: Matrices and Vectors
Matrices and Vectors
Matrices are 2-dimensional arrays:
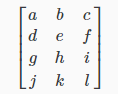
The above matrix has four rows and three columns, so it is a 4 x 3 matrix.
A vector is a matrix with one column and many rows:
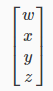
So vectors are a subset of matrices. The above vector is a 4 x 1 matrix.
Notation and terms:
- \(A_{ij}\) refers to the element in the ith row and jth column of matrix A.
- A vector with 'n' rows is referred to as an 'n'-dimensional vector.
- \(v_i\) refers to the element in the ith row of the vector.
- In general, all our vectors and matrices will be 1-indexed. Note that for some programming languages, the arrays are 0-indexed.
- Matrices are usually denoted by uppercase names while vectors are lowercase.
- "Scalar" means that an object is a single value, not a vector or matrix.
- \(\mathbb{R}\) refers to the set of scalar real numbers.
- \(\mathbb{R^n}\) refers to the set of n-dimensional vectors of real numbers.
Run the cell below to get familiar with the commands in Octave/Matlab. Feel free to create matrices and vectors and try out different things.
% The ; denotes we are going back to a new row.
A = [1, 2, 3; 4, 5, 6; 7, 8, 9; 10, 11, 12]
% Initialize a vector
v = [1;2;3]
% Get the dimension of the matrix A where m = rows and n = columns
[m,n] = size(A)
% You could also store it this way
dim_A = size(A)
% Get the dimension of the vector v
dim_v = size(v)
% Now let's index into the 2nd row 3rd column of matrix A
A_23 = A(2,3)
Video: Addition and Scalar Multiplication
In this video we'll talk about matrix addition and subtraction, as well as how to multiply a matrix by a number, also called Scalar Multiplication. Let's start an example. Given two matrices like these, let's say I want to add them together. How do I do that? And so, what does addition of matrices mean? It turns out that if you want to add two matrices, what you do is you just add up the elements of these matrices one at a time. So, my result of adding two matrices is going to be itself another matrix and the first element again just by taking one and four and multiplying them and adding them together, so I get five. The second element I get by taking two and two and adding them, so I get four; three plus three plus zero is three, and so on. I'm going to stop changing colors, I guess. And, on the right is open five, ten and two.
0:56
And it turns out you can add only two matrices that are of the same dimensions. So this example is a three by two matrix,
1:07
because this has 3 rows and 2 columns, so it's 3 by 2. This is also a 3 by 2 matrix, and the result of adding these two matrices is a 3 by 2 matrix again. So you can only add matrices of the same dimension, and the result will be another matrix that's of the same dimension as the ones you just added.
1:29
Where as in contrast, if you were to take these two matrices, so this one is a 3 by 2 matrix, okay, 3 rows, 2 columns. This here is a 2 by 2 matrix. And because these two matrices are not of the same dimension, you know, this is an error, so you cannot add these two matrices and, you know, their sum is not well-defined. So that's matrix addition. Next, let's talk about multiplying matrices by a scalar number. And the scalar is just a, maybe a overly fancy term for, you know, a number or a real number. Alright, this means real number. So let's take the number 3 and multiply it by this matrix. And if you do that, the result is pretty much what you'll expect. You just take your elements of the matrix and multiply them by 3, one at a time. So, you know, one times three is three. What, two times three is six, 3 times 3 is 9, and let's see, I'm going to stop changing colors again. Zero times 3 is zero. Three times 5 is 15, and 3 times 1 is three. And so this matrix is the result of multiplying that matrix on the left by 3. And you notice, again, this is a 3 by 2 matrix and the result is a matrix of the same dimension. This is a 3 by 2, both of these are 3 by 2 dimensional matrices. And by the way, you can write multiplication, you know, either way. So, I have three times this matrix. I could also have written this matrix and 0, 2, 5, 3, 1, right. I just copied this matrix over to the right. I can also take this matrix and multiply this by three. So whether it's you know, 3 times the matrix or the matrix times three is the same thing and this thing here in the middle is the result. You can also take a matrix and divide it by a number. So, turns out taking this matrix and dividing it by four, this is actually the same as taking the number one quarter, and multiplying it by this matrix. 4, 0, 6, 3 and so, you can figure the answer, the result of this product is, one quarter times four is one, one quarter times zero is zero. One quarter times six is, what, three halves, about six over four is three halves, and one quarter times three is three quarters. And so that's the results of computing this matrix divided by four. Vectors give you the result. Finally, for a slightly more complicated example, you can also take these operations and combine them together. So in this calculation, I have three times a vector plus a vector minus another vector divided by three. So just make sure we know where these are, right. This multiplication. This is an example of scalar multiplication because I am taking three and multiplying it. And this is, you know, another scalar multiplication. Or more like scalar division, I guess. It really just means one zero times this. And so if we evaluate these two operations first, then what we get is this thing is equal to, let's see, so three times that vector is three, twelve, six, plus my vector in the middle which is a 005 minus
4:59
one, zero, two-thirds, right? And again, just to make sure we understand what is going on here, this plus symbol, that is matrix addition, right? I really, since these are vectors, remember, vectors are special cases of matrices, right? This, you can also call this vector addition This minus sign here, this is again a matrix subtraction, but because this is an n by 1, really a three by one matrix, that this is actually a vector, so this is also vector, this column. We call this matrix a vector subtraction, as well. OK? And finally to wrap this up. This therefore gives me a vector, whose first element is going to be 3+0-1, so that's 3-1, which is 2. The second element is 12+0-0, which is 12. And the third element of this is, what, 6+5-(2/3), which is 11-(2/3), so that's 10 and one-third and see, you close this square bracket. And so this gives me a 3 by 1 matrix, which is also just called a 3 dimensional vector, which is the outcome of this calculation over here. So that's how you add and subtract matrices and vectors and multiply them by scalars or by row numbers. So far I have only talked about how to multiply matrices and vectors by scalars, by row numbers. In the next video we will talk about a much more interesting step, of taking 2 matrices and multiplying 2 matrices together.
Reading: Addition and Scalar Multiplication
Addition and Scalar Multiplication
Addition and subtraction are element-wise, so you simply add or subtract each corresponding element:
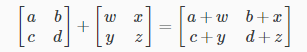
Subtracting Matrices:
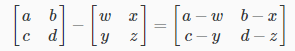
To add or subtract two matrices, their dimensions must be the same.
In scalar multiplication, we simply multiply every element by the scalar value:
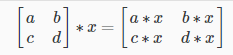
In scalar division, we simply divide every element by the scalar value:
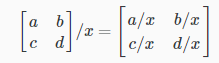
Experiment below with the Octave/Matlab commands for matrix addition and scalar multiplication. Feel free to try out different commands. Try to write out your answers for each command before running the cell below.
% Initialize matrix A and B
A = [1, 2, 4; 5, 3, 2]
B = [1, 3, 4; 1, 1, 1]
% Initialize constant s
s = 2
% What happens if we have a Matrix + scalar?
add_As = A + s
Video: Matrix Vector Multiplication
In this video, I'd like to start talking about how to multiply together two matrices. We'll start with a special case of that, of matrix vector multiplication - multiplying a matrix together with a vector. Let's start with an example. Here is a matrix, and here is a vector, and let's say we want to multiply together this matrix with this vector, what's the result? Let me just work through this example and then we can step back and look at just what the steps were. It turns out the result of this multiplication process is going to be, itself, a vector. And I'm just going work with this first and later we'll come back and see just what I did here. To get the first element of this vector I am going to take these two numbers and multiply them with the first row of the matrix and add up the corresponding numbers. Take one multiplied by one, and take three and multiply it by five, and that's what, that's one plus fifteen so that gives me sixteen. I'm going to write sixteen here. then for the second row, second element, I am going to take the second row and multiply it by this vector, so I have four times one, plus zero times five, which is equal to four, so you'll have four there. And finally for the last one I have two one times one five, so two by one, plus one by 5, which is equal to a 7, and so I get a 7 over there. It turns out that the results of multiplying that's a 3x2 matrix by a 2x1 matrix is also just a two-dimensional vector. The result of this is going to be a 3x1 matrix, so that's why three by one 3x1 matrix, in other words a 3x1 matrix is just a three dimensional vector. So I realize that I did that pretty quickly, and you're probably not sure that you can repeat this process yourself, but let's look in more detail at what just happened and what this process of multiplying a matrix by a vector looks like. Here's the details of how to multiply a matrix by a vector. Let's say I have a matrix A and want to multiply it by a vector x. The result is going to be some vector y. So the matrix A is a m by n dimensional matrix, so m rows and n columns and we are going to multiply that by a n by 1 matrix, in other words an n dimensional vector. It turns out this "n" here has to match this "n" here. In other words, the number of columns in this matrix, so it's the number of n columns. The number of columns here has to match the number of rows here. It has to match the dimension of this vector. And the result of this product is going to be an n-dimensional vector y. Rows here. "M" is going to be equal to the number of rows in this matrix "A". So how do you actually compute this vector "Y"? Well it turns out to compute this vector "Y", the process is to get "Y""I", multiply "A's" "I'th" row with the elements of the vector "X" and add them up. So here's what I mean. In order to get the first element of "Y", that first number--whatever that turns out to be--we're gonna take the first row of the matrix "A" and multiply them one at a time with the elements of this vector "X". So I take this first number multiply it by this first number. Then take the second number multiply it by this second number. Take this third number whatever that is, multiply it the third number and so on until you get to the end. And I'm gonna add up the results of these products and the result of paying that out is going to give us this first element of "Y". Then when we want to get the second element of "Y", let's say this element. The way we do that is we take the second row of A and we repeat the whole thing. So we take the second row of A, and multiply it elements-wise, so the elements of X and add up the results of the products and that would give me the second element of Y. And you keep going to get and we going to take the third row of A, multiply element Ys with the vector x, sum up the results and then I get the third element and so on, until I get down to the last row like so, okay? So that's the procedure. Let's do one more example. Here's the example: So let's look at the dimensions. Here, this is a three by four dimensional matrix. This is a four-dimensional vector, or a 4 x 1 matrix, and so the result of this, the result of this product is going to be a three-dimensional vector. Write, you know, the vector, with room for three elements. Let's do the, let's carry out the products. So for the first element, I'm going to take these four numbers and multiply them with the vector X. So I have 1x1, plus 2x3, plus 1x2, plus 5x1, which is equal to - that's 1+6, plus 2+6, which gives me 14. And then for the second element, I'm going to take this row now and multiply it with this vector (0x1)+3. All right, so 0x1+ 3x3 plus 0x2 plus 4x1, which is equal to, let's see that's 9+4, which is 13. And finally, for the last element, I'm going to take this last row, so I have minus one times one. You have minus two, or really there's a plus next to a two I guess. Times three plus zero times two plus zero times one, and so that's going to be minus one minus six, which is going to make this seven, and so that's vector seven. Okay? So my final answer is this vector fourteen, just to write to that without the colors, fourteen, thirteen, negative seven.
7:01
And as promised, the result here is a three by one matrix. So that's how you multiply a matrix and a vector. I know that a lot just happened on this slide, so if you're not quite sure where all these numbers went, you know, feel free to pause the video you know, and so take a slow careful look at this big calculation that we just did and try to make sure that you understand the steps of what just happened to get us these numbers,fourteen, thirteen and eleven. Finally, let me show you a neat trick. Let's say we have a set of four houses so 4 houses with 4 sizes like these. And let's say I have a hypotheses for predicting what is the price of a house, and let's say I want to compute, you know, H of X for each of my 4 houses here. It turns out there's neat way of posing this, applying this hypothesis to all of my houses at the same time. It turns out there's a neat way to pose this as a Matrix Vector multiplication. So, here's how I'm going to do it. I am going to construct a matrix as follows. My matrix is going to be 1111 times, and I'm going to write down the sizes of my four houses here and I'm going to construct a vector as well, And my vector is going to this vector of two elements, that's minus 40 and 0.25. That's these two co-efficients; data 0 and data 1. And what I am going to do is to take matrix and that vector and multiply them together, that times is that multiplication symbol. So what do I get? Well this is a four by two matrix. This is a two by one matrix. So the outcome is going to be a four by one vector, all right. So, let me, so this is going to be a 4 by 1 matrix is the outcome or really a four diminsonal vector, so let me write it as one of my four elements in my four real numbers here. Now it turns out and so this first element of this result, the way I am going to get that is, I am going to take this and multiply it by the vector. And so this is going to be -40 x 1 + 4.25 x 2104. By the way, on the earlier slides I was writing 1 x -40 and 2104 x 0.25, but the order doesn't matter, right? -40 x 1 is the same as 1 x -40. And this first element, of course, is "H" applied to 2104. So it's really the predicted price of my first house. Well, how about the second element? Hope you can see where I am going to get the second element. Right? I'm gonna take this and multiply it by my vector. And so that's gonna be -40 x 1 + 0.25 x 1416. And so this is going be "H" of 1416. Right?
10:25
And so on for the third and the fourth elements of this 4 x 1 vector. And just there, right? This thing here that I just drew the green box around, that's a real number, OK? That's a single real number, and this thing here that I drew the magenta box around--the purple, magenta color box around--that's a real number, right? And so this thing on the right--this thing on the right overall, this is a 4 by 1 dimensional matrix, was a 4 dimensional vector. And, the neat thing about this is that when you're actually implementing this in software--so when you have four houses and when you want to use your hypothesis to predict the prices, predict the price "Y" of all of these four houses. What this means is that, you know, you can write this in one line of code. When we talk about octave and program languages later, you can actually, you'll actually write this in one line of code. You write prediction equals my, you know, data matrix times parameters, right? Where data matrix is this thing here, and parameters is this thing here, and this times is a matrix vector multiplication. And if you just do this then this variable prediction - sorry for my bad handwriting - then just implement this one line of code assuming you have an appropriate library to do matrix vector multiplication. If you just do this, then prediction becomes this 4 by 1 dimensional vector, on the right, that just gives you all the predicted prices. And your alternative to doing this as a matrix vector multiplication would be to write eomething like , you know, for I equals 1 to 4, right? And you have say a thousand houses it would be for I equals 1 to a thousand or whatever. And then you have to write a prediction, you know, if I equals. and then do a bunch more work over there and it turns out that When you have a large number of houses, if you're trying to predict the prices of not just four but maybe of a thousand houses then it turns out that when you implement this in the computer, implementing it like this, in any of the various languages. This is not only true for Octave, but for Supra Server Java or Python, other high-level, other languages as well. It turns out, that, by writing code in this style on the left, it allows you to not only simplify the code, because, now, you're just writing one line of code rather than the form of a bunch of things inside. But, for subtle reasons, that we will see later, it turns out to be much more computationally efficient to make predictions on all of the prices of all of your houses doing it the way on the left than the way on the right than if you were to write your own formula. I'll say more about this later when we talk about vectorization, but, so, by posing a prediction this way, you get not only a simpler piece of code, but a more efficient one. So, that's it for matrix vector multiplication and we'll make good use of these sorts of operations as we develop the living regression in other models further. But, in the next video we're going to take this and generalize this to the case of matrix matrix multiplication.
Reading: Matrix Vector Multiplication
Matrix-Vector Multiplication
We map the column of the vector onto each row of the matrix, multiplying each element and summing the result.
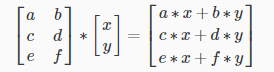
The result is a vector. The number of columns of the matrix must equal the number of rows of the vector.
An m x n matrix multiplied by an n x 1 vector results in an m x 1 vector.
Below is an example of a matrix-vector multiplication. Make sure you understand how the multiplication works. Feel free to try different matrix-vector multiplications.
% Initialize matrix A
A = [1, 2, 3; 4, 5, 6;7, 8, 9]
% Initialize vector v
v = [1; 1; 1]
% Multiply A * v
Av = A * v
Video: Matrix Matrix Multiplication
In this video we'll talk about matrix-matrix multiplication, or how to multiply two matrices together. When we talk about the method in linear regression for how to solve for the parameters theta 0 and theta 1 all in one shot, without needing an iterative algorithm like gradient descent. When we talk about that algorithm, it turns out that matrix-matrix multiplication is one of the key steps that you need to know.
0:24
So let's, as usual, start with an example.
0:28
Let's say I have two matrices and I want to multiply them together. Let me again just run through this example and then I'll tell you a little bit of what happened. So the first thing I'm gonna do is I'm going to pull out the first column of this matrix on the right. And I'm going to take this matrix on the left and multiply it by a vector that is just this first column.
0:55
And it turns out, if I do that, I'm going to get the vector 11, 9. So this is the same matrix-vector multiplication as you saw in the last video.
1:06
I worked this out in advance, so I know it's 11, 9. And then the second thing I want to do is I'm going to pull out the second column of this matrix on the right. And I'm then going to take this matrix on the left, so take that matrix, and multiply it by that second column on the right. So again, this is a matrix-vector multiplication step which you saw from the previous video. And it turns out that if you multiply this matrix and this vector you get 10, 14. And by the way, if you want to practice your matrix-vector multiplication, feel free to pause the video and check this product yourself.
1:43
Then I'm just gonna take these two results and put them together, and that'll be my answer. So it turns out the outcome of this product is gonna be a two by two matrix. And the way I'm gonna fill in this matrix is just by taking my elements 11, 9, and plugging them here. And taking 10, 14 and plugging them into the second column, okay? So that was the mechanics of how to multiply a matrix by another matrix. You basically look at the second matrix one column at a time and you assemble the answers. And again, we'll step through this much more carefully in a second. But I just want to point out also, this first example is a 2x3 matrix. Multiply that by a 3x2 matrix, and the outcome of this product turns out to be a 2x2 matrix. And again, we'll see in a second why this was the case. All right, that was the mechanics of the calculation. Let's actually look at the details and look at what exactly happened. Here are the details. I have a matrix A and I want to multiply that with a matrix B and the result will be some new matrix C.
2:55
It turns out you can only multiply together matrices whose dimensions match. So A is an m x n matrix, so m rows, n columns. And we multiply with an n x o matrix. And it turns out this n here must match this n here. So the number of columns in the first matrix must equal to the number of rows in the second matrix. And the result of this product will be a m x o matrix, like the matrix C here. And in the previous video everything we did corresponded to the special case of o being equal to 1. That was to the case of B being a vector. But now we're gonna deal with the case of values of o larger than 1. So here's how you multiply together the two matrices. What I'm going to do is I'm going to take the first column of B and treat that as a vector, and multiply the matrix A by the first column of B. And the result of that will be a n by 1 vector, and I'm gonna put that over here.
4:05
Then I'm gonna take the second column of B, right? So this is another n by 1 vector. So this column here, this is n by 1. It's an n-dimensional vector. Gonna multiply this matrix with this n by 1 vector. The result will be a m-dimensional vector, which we'll put there, and so on.
4:29
And then I'm gonna take the third column, multiply it by this matrix. I get a m-dimensional vector. And so on, until you get to the last column. The matrix times the last column gives you the last column of C.
4:46
Just to say that again, the ith column of the matrix C is obtained by taking the matrix A and multiplying the matrix A with the ith column of the matrix B for the values of i = 1, 2, up through o. So this is just a summary of what we did up there in order to compute the matrix C.
5:11
Let's look at just one more example. Let's say I want to multiply together these two matrices. So what I'm going to do is first pull out the first column of my second matrix. That was my matrix B on the previous slide and I therefore have this matrix times that vector. And so, oh, let's do this calculation quickly. This is going to be equal to the 1, 3 x 0, 3, so that gives 1 x 0 + 3 x 3. And the second element is going to be 2, 5 x 0, 3, so that's gonna be 2 x 0 + 5 x 3. And that is 9, 15. Oh, actually let me write that in green. So this is 9, 15. And then next I'm going to pull out the second column of this and do the corresponding calculations. So that's this matrix times this vector 1, 2. Let's also do this quickly, so that's 1 x 1 + 3 x 2, so that was that row. And let's do the other one. So let's see, that gives me 2 x 1 + 5 x 2 and so that is going to be equal to, lets see, 1 x 1 + 3 x 1 is 7 and 2 x 1 + 5 x 2 is 12. So now I have these two and so my outcome, the product of these two matrices, is going to be this goes here and this goes here. So I get 9, 15 and 4, 12. [It should be 7,12] And you may notice also that the result of multiplying a 2x2 matrix with another 2x2 matrix, the resulting dimension is going to be that first 2 times that second 2. So the result is itself also a 2x2 matrix.
7:34
Finally, let me show you one more neat trick that you can do with matrix-matrix multiplication. Let's say, as before, that we have four houses whose prices we wanna predict.
7:48
Only now, we have three competing hypotheses shown here on the right. So if you want to apply all three competing hypotheses to all four of your houses, it turns out you can do that very efficiently using a matrix-matrix multiplication. So here on the left is my usual matrix, same as from the last video where these values are my housing prices [he means housing sizes] and I've put 1s here on the left as well. And what I am going to do is construct another matrix where here, the first column is this -40 and 0.25 and the second column is this 200, 0.1 and so on. And it turns out that if you multiply these two matrices, what you find is that this first column, I'll draw that in blue. Well, how do you get this first column?
8:47
Our procedure for matrix-matrix multiplication is, the way you get this first column is you take this matrix and you multiply it by this first column. And we saw in the previous video that this is exactly the predicted housing prices of the first hypothesis, right, of this first hypothesis here.
9:08
And how about the second column? Well, [INAUDIBLE] second column. The way you get the second column is, well, you take this matrix and you multiply it by this second column. And so the second column turns out to be the predictions of the second hypothesis up there, and similarly for the third column.
9:34
And so I didn't step through all the details, but hopefully you can just feel free to pause the video and check the math yourself and check that what I just claimed really is true. But it turns out that by constructing these two matrices, what you can therefore do is very quickly apply all 3 hypotheses to all 4 house sizes to get all 12 predicted prices output by your 3 hypotheses on your 4 houses.
10:00
So with just one matrix multiplication step you managed to make 12 predictions. And even better, it turns out that in order to do that matrix multiplication, there are lots of good linear algebra libraries in order to do this multiplication step for you. And so pretty much any reasonable programming language that you might be using. Certainly all the top ten most popular programming languages will have great linear algebra libraries. And there'll be good linear algebra libraries that are highly optimized in order to do that matrix-matrix multiplication very efficiently. Including taking advantage of any sort of parallel computation that your computer may be capable of, whether your computer has multiple cores or multiple processors. Or within a processor sometimes there's parallelism as well called SIMD parallelism that your computer can take care of. And there are very good free libraries that you can use to do this matrix-matrix multiplication very efficiently, so that you can very efficiently make lots of predictions with lots of hypotheses.
Reading: Matrix Matrix Multiplication
Matrix-Matrix Multiplication
We multiply two matrices by breaking it into several vector multiplications and concatenating the result.
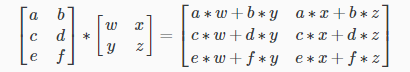
An m x n matrix multiplied by an n x o matrix results in an m x o matrix. In the above example, a 3 x 2 matrix times a 2 x 2 matrix resulted in a 3 x 2 matrix.
To multiply two matrices, the number of columns of the first matrix must equal the number of rows of the second matrix.
For example:
% Initialize a 3 by 2 matrix
A = [1, 2; 3, 4;5, 6]
% Initialize a 2 by 1 matrix
B = [1,2; 2, 3]
% We expect a resulting matrix of (3 by 2)*(2 by 1) = (3 by 1)
mult_AB = A*B
% Make sure you understand why we got that result
Video: Matrix Multiplication Properties
Matrix multiplication is really useful, since you can pack a lot of computation into just one matrix multiplication operation. But you should be careful of how you use them. In this video, I wanna tell you about a few properties of matrix multiplication.
0:18
When working with just real numbers or when working with scalars, multiplication is commutative. And what I mean by that is that if you take 3 times 5, that is equal to 5 times 3. And the ordering of this multiplication doesn't matter. And this is called the commutative property
0:40
of multiplication of real numbers. It turns out this property, they can reverse the order in which you multiply things. This is not true for matrix multiplication. So concretely, if A and B are matrices. Then in general, A times B is not equal to B times A. So, just be careful of that. Its not okay to arbitrarily reverse the order in which you multiply matrices. Matrix multiplication in not commutative, is the fancy way of saying it. As a concrete example, here are two matrices. This matrix 1 1 0 0 times 0 0 2 0 and if you multiply these two matrices you get this result on the right. Now let's swap around the order of these two matrices. So I'm gonna take this two matrices and just reverse them. It turns out if you multiply these two matrices, you get the second answer on the right. And well clearly, right, these two matrices are not equal to each other.
1:36
So, in fact, in general if you have a matrix operation like A times B, if A is an m by n matrix, and B is an n by m matrix, just as an example. Then, it turns out that the matrix A times B,
1:58
right, is going to be an m by m matrix. Whereas the matrix B times A is going to be an n by n matrix. So the dimensions don't even match, right? So if A x B and B x A may not even be the same dimension. In the example on the left, I have all two by two matrices. So the dimensions were the same, but in general, reversing the order of the matrices can even change the dimension of the outcome. So, matrix multiplication is not commutative.
2:34
Here's the next property I want to talk about. So, when talking about real numbers or scalars, let's say I have 3 x 5 x 2. I can either multiply 5 x 2 first. Then I can compute this as 3 x 10. Or, I can multiply 3 x 5 first, and I can compute this as 15 x 2. And both of these give you the same answer, right? Both of these is equal to 30. So it doesn't matter whether I multiply 5 x 2 first or whether I multiply 3 x 5 first, because sort of, well, 3 x (5 x 2) = (3 x 5) x 2. And this is called the associative property of real number multiplication. It turns out that matrix multiplication is associative. So concretely, let's say I have a product of three matrices A x B x C. Then, I can compute this either as A x (B x C) or I can computer this as (A x B) x C, and these will actually give me the same answer. I'm not gonna prove this but you can just take my word for it I guess. So just be clear, what I mean by these two cases. Let's look at the first one, right. This first case. What I mean by that is if you actually wanna compute A x B x C. What you can do is you can first compute B x C. So that D = B x C then compute A x D. And so this here is really computing A x B x C. Or, for this second case, you can compute this as, you can set E = A x B, then compute E times C. And this is then the same as A x B x C, and it turns out that both of these options will give you this guarantee to give you the same answer. And so we say that matrix multiplication thus enjoy the associative property. Okay? And don't worry about the terminology associative and commutative. That's what it's called, but I'm not really going to use this terminology later in this class, so don't worry about memorizing those terms. Finally, I want to tell you about the Identity Matrix, which is a special matrix. So let's again make the analogy to what we know of real numbers. When dealing with real numbers or scalar numbers, the number 1, you can think of it as the identity of multiplication. And what I mean by that is that for any number z, 1 x z = z x 1. And that's just equal to the number z for any real number z.
5:25
So 1 is the identity operation and so it satisfies this equation. So it turns out, that this in the space of matrices there's an identity matrix as well and it's usually denoted I or sometimes we write it as I of n x n if we want to make it explicit to dimensions. So I subscript n x n is the n x n identity matrix. And so that's a different identity matrix for each dimension n. And here are few examples. Here's the 2 x 2 identity matrix, here's the 3 x 3 identity matrix, here's the 4 x 4 matrix. So the identity matrix has the property that it has ones along the diagonals.
6:07
All right, and so on. And 0 everywhere else. And so, by the way, the 1 x 1 identity matrix is just a number 1, and so the 1 x 1 matrix with just 1 in it. So it's not a very interesting identity matrix. And informally, when I or others are being sloppy, very often we'll write the identity matrices in fine notation. We'll draw square brackets, just write one one one dot dot dot dot one, and then we'll maybe somewhat sloppily write a bunch of zeros there. And these zeroes on the, this big zero and this big zero, that's meant to denote that this matrix is zero everywhere except for the diagonal. So this is just how I might swap you the right D identity matrix. And it turns out that the identity matrix has its property that for any matrix A, A times identity equals I times A equals A so that's a lot like this equation that we have up here. Right? So 1 times z equals z times 1 equals z itself. So I times A equals A times I equals A.
7:12
Just to make sure we have the dimensions right. So if A is an m by n matrix, then this identity matrix here, that's an n by n identity matrix.
7:23
And if is and by then, then this identity matrix, right? For matrix multiplication to make sense, that has to be an m by m matrix. Because this m has the match up that m, and in either case, the outcome of this process is you get back the matrix A which is m by n.
7:44
So whenever we write the identity matrix I, you know, very often the dimension Mention, right, will be implicit from the content. So these two I's, they're actually different dimension matrices. One may be n by n, the other is n by m. But when we want to make the dimension of the matrix explicit, then sometimes we'll write to this I subscript n by n, kind of like we had up here. But very often, the dimension will be implicit.
8:10
Finally, I just wanna point out that earlier I said that AB is not, in general, equal to BA. Right? For most matrices A and B, this is not true. But when B is the identity matrix, this does hold true, that A times the identity matrix does indeed equal to identity times A is just that you know this is not true for other matrices B in general.
8:39
So, that's it for the properties of matrix multiplication and special matrices like the identity matrix I want to tell you about. In the next and final video on our linear algebra review, I'm going to quickly tell you about a couple of special matrix operations and after that everything you need to know about linear algebra for this class.
Reading: Matrix Multiplication Properties
Matrix Multiplication Properties
Matrices are not commutative: A\∗B≠B\∗A
Matrices are associative: (A\∗B)\∗C=A\∗(B\∗C)
The identity matrix, when multiplied by any matrix of the same dimensions, results in the original matrix. It's just like multiplying numbers by 1. The identity matrix simply has 1's on the diagonal (upper left to lower right diagonal) and 0's elsewhere.

When multiplying the identity matrix after some matrix (A∗I), the square identity matrix's dimension should match the other matrix's columns. When multiplying the identity matrix before some other matrix (I∗A), the square identity matrix's dimension should match the other matrix's rows.
% Initialize random matrices A and B
A = [1,2;4,5]
B = [1,1;0,2]
% Initialize a 2 by 2 identity matrix
I = eye(2)
% The above notation is the same as I = [1,0;0,1]
% What happens when we multiply I*A ?
IA = I*A
% How about A*I ?
AI = A*I
% Compute A*B
AB = A*B
% Is it equal to B*A?
BA = B*A
% Note that IA = AI but AB != BA
Video: Inverse and Transpose
In this video, I want to tell you about a couple of special matrix operations, called the matrix inverse and the matrix transpose operation.
0:08
Let's start by talking about matrix inverse, and as usual we'll start by thinking about how it relates to real numbers. In the last video, I said that the number one plays the role of the identity in the space of real numbers because one times anything is equal to itself. It turns out that real numbers have this property that very number have an, that each number has an inverse, for example, given the number three, there exists some number, which happens to be three inverse so that that number times gives you back the identity element one. And so to me, inverse of course this is just one third. And given some other number, maybe twelve there is some number which is the inverse of twelve written as twelve to the minus one, or really this is just one twelve. So that when you multiply these two things together. the product is equal to the identity element one again. Now it turns out that in the space of real numbers, not everything has an inverse. For example the number zero does not have an inverse, right? Because zero's a zero inverse, one over zero that's undefined. Like this one over zero is not well defined. And what we want to do, in the rest of this slide, is figure out what does it mean to compute the inverse of a matrix. Here's the idea: If A is a n by n matrix, and it has an inverse, I will say a bit more about that later, then the inverse is going to be written A to the minus one and A times this inverse, A to the minus one, is going to equal to A inverse times A, is going to give us back the identity matrix. Okay? Only matrices that are m by m for some the idea of M having inverse. So, a matrix is M by M, this is also called a square matrix and it's called square because the number of rows is equal to the number of columns. Right and it turns out only square matrices have inverses, so A is a square matrix, is m by m, on inverse this equation over here. Let's look at a concrete example, so let's say I have a matrix, three, four, two, sixteen. So this is a two by two matrix, so it's a square matrix and so this may just could have an and it turns out that I happen to know the inverse of this matrix is zero point four, minus zero point one, minus zero point zero five, zero zero seven five. And if I take this matrix and multiply these together it turns out what I get is the two by two identity matrix, I, this is I two by two. Okay? And so on this slide, you know this matrix is the matrix A, and this matrix is the matrix A-inverse. And it turns out if that you are computing A times A-inverse, it turns out if you compute A-inverse times A you also get back the identity matrix. So how did I find this inverse or how did I come up with this inverse over here? It turns out that sometimes you can compute inverses by hand but almost no one does that these days. And it turns out there is very good numerical software for taking a matrix and computing its inverse. So again, this is one of those things where there are lots of open source libraries that you can link to from any of the popular programming languages to compute inverses of matrices. Let me show you a quick example. How I actually computed this inverse, and what I did was I used software called Optive. So let me bring that up. We will see a lot about Optive later. Let me just quickly show you an example. Set my matrix A to be equal to that matrix on the left, type three four two sixteen, so that's my matrix A right. This is matrix 34, 216 that I have down here on the left. And, the software lets me compute the inverse of A very easily. It's like P over A equals this. And so, this is right, this matrix here on my four minus, on my one, and so on. This given the numerical solution to what is the inverse of A. So let me just write, inverse of A equals P inverse of A over that I can now just verify that A times A inverse the identity is, type A times the inverse of A and the result of that is this matrix and this is one one on the diagonal and essentially ten to the minus seventeen, ten to the minus sixteen, so Up to numerical precision, up to a little bit of round off error that my computer had in finding optimal matrices and these numbers off the diagonals are essentially zero so A times the inverse is essentially the identity matrix. Can also verify the inverse of A times A is also equal to the identity, ones on the diagonals and values that are essentially zero except for a little bit of round dot error on the off diagonals.
5:45
If a definition that the inverse of a matrix is, I had this caveat first it must always be a square matrix, it had this caveat, that if A has an inverse, exactly what matrices have an inverse is beyond the scope of this linear algebra for review that one intuition you might take away that just as the number zero doesn't have an inverse, it turns out that if A is say the matrix of all zeros, then this matrix A also does not have an inverse because there's no matrix there's no A inverse matrix so that this matrix times some other matrix will give you the identity matrix so this matrix of all zeros, and there are a few other matrices with properties similar to this. That also don't have an inverse. But it turns out that in this review I don't want to go too deeply into what it means matrix have an inverse but it turns out for our machine learning application this shouldn't be an issue or more precisely for the learning algorithms where this may be an to namely whether or not an inverse matrix appears and I will tell when we get to those learning algorithms just what it means for an algorithm to have or not have an inverse and how to fix it in case. Working with matrices that don't have inverses. But the intuition if you want is that you can think of matrices as not have an inverse that is somehow too close to zero in some sense. So, just to wrap up the terminology, matrix that don't have an inverse Sometimes called a singular matrix or degenerate matrix and so this matrix over here is an example zero zero zero matrix. is an example of a matrix that is singular, or a matrix that is degenerate. Finally, the last special matrix operation I want to tell you about is to do matrix transpose. So suppose I have matrix A, if I compute the transpose of A, that's what I get here on the right. This is a transpose which is written and A superscript T, and the way you compute the transpose of a matrix is as follows. To get a transpose I am going to first take the first row of A one to zero. That becomes this first column of this transpose. And then I'm going to take the second row of A, 3 5 9, and that becomes the second column. of the matrix A transpose. And another way of thinking about how the computer transposes is as if you're taking this sort of 45 degree axis and you are mirroring or you are flipping the matrix along that 45 degree axis. so here's the more formal definition of a matrix transpose. Let's say A is a m by n matrix. And let's let B equal A transpose and so BA transpose like so. Then B is going to be a n by m matrix with the dimensions reversed so here we have a 2x3 matrix. And so the transpose becomes a 3x2 matrix, and moreover, the BIJ is equal to AJI. So the IJ element of this matrix B is going to be the JI element of that earlier matrix A. So for example, B 1 2 is going to be equal to, look at this matrix, B 1 2 is going to be equal to this element 3 1st row, 2nd column. And that equal to this, which is a two one, second row first column, right, which is equal to two and some [It should be 3] of the example B 3 2, right, that's B 3 2 is this element 9, and that's equal to a two three which is this element up here, nine. And so that wraps up the definition of what it means to take the transpose of a matrix and that in fact concludes our linear algebra review. So by now hopefully you know how to add and subtract matrices as well as multiply them and you also know how, what are the definitions of the inverses and transposes of a matrix and these are the main operations used in linear algebra for this course. In case this is the first time you are seeing this material. I know this was a lot of linear algebra material all presented very quickly and it's a lot to absorb but if you there's no need to memorize all the definitions we just went through and if you download the copy of either these slides or of the lecture notes from the course website. and use either the slides or the lecture notes as a reference then you can always refer back to the definitions and to figure out what are these matrix multiplications, transposes and so on definitions. And the lecture notes on the course website also has pointers to additional resources linear algebra which you can use to learn more about linear algebra by yourself.
10:48
And next with these new tools. We'll be able in the next few videos to develop more powerful forms of linear regression that can view of a lot more data, a lot more features, a lot more training examples and later on after the new regression we'll actually continue using these linear algebra tools to derive more powerful learning algorithims as well.
Reading: Inverse and Transpose
Inverse and Transpose
The inverse of a matrix A is denoted \(A^{-1}\). Multiplying by the inverse results in the identity matrix.
A non square matrix does not have an inverse matrix. We can compute inverses of matrices in octave with the pinv(A) function and in Matlab with the inv(A) function. Matrices that don't have an inverse are singular or degenerate.
The transposition of a matrix is like rotating the matrix 90° in clockwise direction and then reversing it. We can compute transposition of matrices in matlab with the transpose(A) function or A':
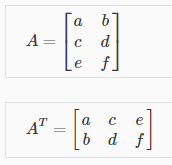
In other words:
\]
% Initialize matrix A
A = [1,2,0;0,5,6;7,0,9]
% Transpose A
A_trans = A'
% Take the inverse of A
A_inv = inv(A)
% What is A^(-1)*A?
A_invA = inv(A)*A
Reading: Lecture Slides
Octave/Matlab Tutorial
This course includes programming assignments designed to help you understand how to implement the learning algorithms in practice. To complete the programming assignments, you will need to use Octave or MATLAB. This module introduces Octave/Matlab and shows you how to submit an assignment.
6 videos, 1 reading
Video: Basic Operations
You now know a bunch about machine learning. In this video, I like to teach you a programing language, Octave, in which you'll be able to very quickly implement the the learning algorithms we've seen already, and the learning algorithms we'll see later in this course. In the past, I've tried to teach machine learning using a large variety of different programming languages including C++ Java, Python, NumPy, and also Octave, and what I found was that students were able to learn the most productively learn the most quickly and prototype your algorithms most quickly using a relatively high level language like octave. In fact, what I often see in Silicon Valley is that if even if you need to build. If you want to build a large scale deployment of a learning algorithm, what people will often do is prototype and the language is Octave. Which is a great prototyping language. So you can sort of get your learning algorithms working quickly. And then only if you need to a very large scale deployment of it. Only then spend your time re-implementing the algorithm to C++ Java or some of the language like that. Because all the lessons we've learned is that a time or develop a time. That is your time. The machine learning's time is incredibly valuable. And if you can get your learning algorithms to work more quickly in Octave. Then overall you have a huge time savings by first developing the algorithms in Octave, and then implementing and maybe C++ Java, only after we have the ideas working. The most common prototyping language I see people use for machine learning are: Octave, MATLAB, Python, NumPy, and R. Octave is nice because open sourced. And MATLAB works well too, but it is expensive for to many people. But if you have access to a copy of MATLAB. You can also use MATLAB with this class. If you know Python, NumPy, or if you know R. I do see some people use it. But, what I see is that people usually end up developing somewhat more slowly, and you know, these languages. Because the Python, NumPy syntax is just slightly clunkier than the Octave syntax. And so because of that, and because we are releasing starter code in Octave. I strongly recommend that you not try to do the following exercises in this class in NumPy and R. But that I do recommend that you instead do the programming exercises for this class in octave instead. What I'm going to do in this video is go through a list of commands very, very quickly, and its goal is to quickly show you the range of commands and the range of things you can do in Octave. The course website will have a transcript of everything I do, and so after watching this video you can refer to the transcript posted on the course website when you want find a command. Concretely, what I recommend you do is first watch the tutorial videos. And after watching to the end, then install Octave on your computer. And finally, it goes to the course website, download the transcripts of the things you see in the session, and type in whatever commands seem interesting to you into Octave, so that it's running on your own computer, so you can see it run for yourself. And with that let's get started. Here's my Windows desktop, and I'm going to start up Octave. And I'm now in Octave. And that's my Octave prompt. Let me first show the elementary operations you can do in Octave. So you type in 5 + 6. That gives you the answer of 11. 3 - 2. 5 x 8, 1/2, 2^6
3:35
is 64. So those are the elementary math operations. You can also do logical operations. So one equals two. This evaluates to false. The percent command here means a comment. So, one equals two, evaluates to false. Which is represents by zero. One not equals to two. This is true. So that returns one. Note that a not equal sign is this tilde equals symbol. And not bang equals. Which is what some other programming languages use. Lets see logical operations one and zero use a double ampersand sign to the logical AND. And that evaluates false. One or zero is the OR operation. And that evaluates to true. And I can XOR one and zero, and that evaluates to one. This thing over on the left, this Octave 324.x equals 11, this is the default Octave prompt. It shows the, what, the version in Octave and so on. If you don't want that prompt, there's a somewhat cryptic command PF quote, greater than, greater than and so on, that you can use to change the prompt. And I guess this quote a string in the middle. Your quote, greater than, greater than, space. That's what I prefer my Octave prompt to look like. So if I hit enter. Oops, excuse me. Like so. PS1 like so. Now my Octave prompt has changed to the greater than, greater than sign.Which, you know, looks quite a bit better. Next let's talk about Octave variables. I can take the variable A and assign it to 3. And hit enter. And now A is equal to 3. You want to assign a variable, but you don't want to print out the result. If you put a semicolon, the semicolon suppresses the print output. So to do that, enter, it doesn't print anything. Whereas A equals 3. mix it, print it out, where A equals, 3 semicolon doesn't print anything. I can do string assignment. B equals hi Now if I just enter B it prints out the variable B. So B is the string hi C equals 3 greater than colon 1. So, now C evaluates the true.
5:55
If you want to print out or display a variable, here's how you go about it. Let me set A equals Pi. And if I want to print A I can just type A like so, and it will print it out. For more complex printing there is also the DISP command which stands for Display. Display A just prints out A like so. You can also display strings so: DISP, sprintf, two decimals, percent 0.2, F, comma, A. Like so. And this will print out the string. Two decimals, colon, 3.14. This is kind of an old style C syntax. For those of you that have programmed C before, this is essentially the syntax you use to print screen. So the Sprintf generates a string that is less than the 2 decimals, 3.1 plus string. This percent 0.2 F means substitute A into here, showing the two digits after the decimal points. And DISP takes the string DISP generates it by the Sprintf command. Sprintf. The Sprintf command. And DISP actually displays the string. And to show you another example, Sprintf six decimals percent 0.6 F comma A. And, this should print Pi with six decimal places. Finally, I was saying, a like so, looks like this. There are useful shortcuts that type type formats long. It causes strings by default. Be displayed to a lot more decimal places. And format short is a command that restores the default of just printing a small number of digits. Okay, that's how you work with variables. Now let's look at vectors and matrices. Let's say I want to assign MAT A to the matrix. Let me show you an example: 1, 2, semicolon, 3, 4, semicolon, 5, 6. This generates a three by two matrix A whose first row is 1, 2. Second row 3, 4. Third row is 5, 6. What the semicolon does is essentially say, go to the next row of the matrix. There are other ways to type this in. Type A 1, 2 semicolon 3, 4, semicolon, 5, 6, like so. And that's another equivalent way of assigning A to be the values of this three by two matrix. Similarly you can assign vectors. So V equals 1, 2, 3. This is actually a row vector. Or this is a 3 by 1 vector. Where that is a fat Y vector, excuse me, not, this is a 1 by 3 matrix, right. Not 3 by 1. If I want to assign this to a column vector, what I would do instead is do v 1;2;3. And this will give me a 3 by 1. There's a 1 by 3 vector. So this will be a column vector. Here's some more useful notation. V equals 1: 0.1: 2. What this does is it sets V to the bunch of elements that start from 1. And increments and steps of 0.1 until you get up to 2. So if I do this, V is going to be this, you know, row vector. This is what one by eleven matrix really. That's 1, 1.1, 1.2, 1.3 and so on until we get up to two.
9:31
Now, and I can also set V equals one colon six, and that sets V to be these numbers. 1 through 6, okay. Now here are some other ways to generate matrices. Ones 2.3 is a command that generates a matrix that is a two by three matrix that is the matrix of all ones. So if I set that c2 times ones two by three this generates a two by three matrix that is all two's. You can think of this as a shorter way of writing this and c2,2,2's and you can call them 2,2,2, which would also give you the same result. Let's say W equals one's, one by three, so this is going to be a row vector or a row of three one's and similarly you can also say w equals zeroes, one by three, and this generates a matrix. A one by three matrix of all zeros. Just a couple more ways to generate matrices . If I do W equals Rand one by three, this gives me a one by three matrix of all random numbers. If I do Rand three by three. This gives me a three by three matrix of all random numbers drawn from the uniform distribution between zero and one. So every time I do this, I get a different set of random numbers drawn uniformly between zero and one. For those of you that know what a Gaussian random variable is or for those of you that know what a normal random variable is, you can also set W equals Rand N, one by three. And so these are going to be three values drawn from a Gaussian distribution with mean zero and variance or standard deviation equal to one. And you can set more complex things like W equals minus six, plus the square root ten, times, lets say Rand N, one by ten thousand. And I'm going to put a semicolon at the end because I don't really want this printed out. This is going to be a what? Well, it's going to be a vector of, with a hundred thousand, excuse me, ten thousand elements. So, well, actually, you know what? Let's print it out. So this will generate a matrix like this. Right? With 10,000 elements. So that's what W is. And if I now plot a histogram of W with a hist command, I can now. And Octave's print hist command, you know, takes a couple seconds to bring this up, but this is a histogram of my random variable for W. There was minus 6 plus zero ten times this Gaussian random variable. And I can plot a histogram with more buckets, with more bins, with say, 50 bins. And this is my histogram of a Gaussian with mean minus 6. Because I have a minus 6 there plus square root 10 times this. So the variance of this Gaussian random variable is 10 on the standard deviation is square root of 10, which is about what? Three point one. Finally, one special command for generator matrix, which is the I command. So I stands for this is maybe a pun on the word identity. It's server set eye 4. This is the 4 by 4 identity matrix. So I equals eye 4. This gives me a 4 by 4 identity matrix. And I equals eye 5, eye 6. That gives me a 6 by 6 identity matrix, i3 is the 3 by 3 identity matrix. Lastly, to wrap up this video, there's one more useful command. Which is the help command. So you can type help i and this brings up the help function for the identity matrix. Hit Q to quit. And you can also type help rand. Brings up documentation for the rand or the random number generation function. Or even help help, which shows you, you know help on the help function. So, those are the basic operations in Octave. And with this you should be able to generate a few matrices, multiply, add things. And use the basic operations in Octave. In the next video, I'd like to start talking about more sophisticated commands and how to use data around and start to process data in Octave.
Video: Moving Data Around
In this second tutorial video on Octave, I'd like to start to tell you how to move data around in Octave. So, if you have data for a machine learning problem, how do you load that data in Octave? How do you put it into matrix? How do you manipulate these matrices? How do you save the results? How do you move data around and operate with data? Here's my Octave window as before, picking up from where we left off in the last video. If I type A, that's the matrix so we generate it, right, with this command equals one, two, three, four, five, six, and this is a three by two matrix. The size command in Octave lets you, tells you what is the size of a matrix. So size A returns three, two. It turns out that this size command itself is actually returning a one by two matrix. So you can actually set SZ equals size of A and SZ is now a one by two matrix where the first element of this is three, and the second element of this is two. So, if you just type size of SZ. Does SZ is a one by two matrix whose two elements contain the dimensions of the matrix A. You can also type size A one to give you back the first dimension of A, size of the first dimension of A. So that's the number of rows and size A two to give you back two, which is the number of columns in the matrix A. If you have a vector V, so let's say V equals one, two, three, four, and you type length V. What this does is it gives you the size of the longest dimension. So you can also type length A and because A is a three by two matrix, the longer dimension is of size three, so this should print out three. But usually we apply length only to vectors. So you know, length one, two, three, four, five, rather than apply length to matrices because that's a little more confusing. Now, let's look at how the load data and find data on the file system. When we start an Octave we're usually, we're often in a path that is, you know, the location of where the Octave location is. So the PWD command shows the current directory, or the current path that Octave is in. So right now we're in this maybe somewhat off scale directory. The CD command stands for change directory, so I can go to C:/Users/Ang/Desktop, and now I'm in, you know, in my Desktop and if I type ls, ls is, it comes from a Unix or a Linux command. But, ls will list the directories on my desktop and so these are the files that are on my Desktop right now.
3:15
In fact, on my desktop are two files: Features X and Price Y that's maybe come from a machine learning problem I want to solve. So, here's my desktop. Here's Features X, and Features X is this window, excuse me, is this file with two columns of data. This is actually my housing prices data. So I think, you know, I think I have forty-seven rows in this data set. And so the first house has size two hundred four square feet, has three bedrooms; second house has sixteen hundred square feet, has three bedrooms; and so on. And Price Y is this file that has the prices of the data in my training set. So, Features X and Price Y are just text files with my data. How do I load this data into Octave? Well, I just type the command load Features X dot dat and if I do that, I load the Features X and can load Price Y dot dat. And by the way, there are multiple ways to do this. This command if you put Features X dot dat on that in strings and load it like so. This is a typo there. This is an equivalent command. So you can, this way I'm just putting the file name of the string in the founding in a string and in an Octave use single quotes to represent strings, like so. So that's a string, and we can load the file whose name is given by that string. Now the WHO command now shows me what variables I have in my Octave workspace. So Who shows me whether the variables that Octave has in memory currently. Features X and Price Y are among them, as well as the variables that, you know, we created earlier in this session. So I can type Features X to display features X. And there's my data. And I can type size features X and that's my 47 by two matrix. And some of these size, press Y, that gives me my 47 by one vector. This is a 47 dimensional vector. This is all common vector that has all the prices Y in my training set. Now the who function shows you one of the variables that, in the current workspace. There's also the who S variable that gives you the detailed view. And so this also, with an S at the end this also lists my variables except that it now lists the sizes as well. So A is a three by two matrix and features X as a 47 by 2 matrix. Price Y is a 47 by one matrix. Meaning this is just a vector. And it shows, you know, how many bytes of memory it's taking up. As well as what type of data this is. Double means double position floating point so that just means that these are real values, the floating point numbers. Now if you want to get rid of a variable you can use the clear command. So clear features X and type whose again. You notice that the features X variable has now disappeared. And how do we save data? Let's see. Let's take the variable V and say that it's a price Y 1 colon 10. This sets V to be the first 10 elements of vector Y. So let's type who or whose. Whereas Y was a 47 by 1 vector. V is now 10 by 1. B equals price Y, one column ten that sets it to the just the first ten elements of Y. Let's say I wanna save this to date to disc the command save, hello.mat V. This will save the variable V into a file called hello.mat. So let's do that. And now a file has appeared on my Desktop, you know, called Hello.mat. I happen to have MATLAB installed in this window, which is why, you know, this icon looks like this because Windows is recognized as it's a MATLAB file,but don't worry about it if this file looks like it has a different icon on your machine and let's say I clear all my variables. So, if you type clear without anything then this actually deletes all of the variables in your workspace. So there's now nothing left in the workspace. And if I load hello.mat, I can now load back my variable v, which is the data that I previously saved into the hello.mat file. So, hello.mat, what we did just now to save hello.mat to view, this save the data in a binary format, a somewhat more compressed binary format. So if v is a lot of data, this, you know, will be somewhat more compressing. Will take off less the space. If you want to save your data in a human readable format then you type save hello.text the variable v and then -ascii. So, this will save it as a text or as ascii format of text. And now, once I've done that, I have this file. Hello.text has just appeared on my desktop, and if I open this up, we see that this is a text file with my data saved away. So that's how you load and save data. Now let's talk a bit about how to manipulate data. Let's set a equals to that matrix again so is my three by two matrix. So as indexing. So type A 3, 2. This indexes into the 3, 2 elements of the matrix A. So, this is what, you know, in normally, we will write this as a subscript 3, 2 or A subscript,
9:03
you know, 3, 2 and so that's the element and third row and second column of A which is the element of six. I can also type A to comma colon to fetch everything in the second row. So, the colon means every element along that row or column. So, a of 2 comma colon is this second row of a. Right. And similarly, if I do a colon comma 2 then this means get everything in the second column of A. So, this gives me 2 4 6. Right this means of A. everything, second column. So, this is my second column A, which is 2 4 6. Now, you can also use somewhat most of the sophisticated index in the operations. So So, we just click each of an example. You do this maybe less often, but let me do this A 1 3 comma colon. This means get all of the elements of A who's first indexes one or three. This means I get everything from the first and third rows of A and from all columns. So, this was the matrix A and so A 1 3 comma colon means get everything from the first row and from the second row and from the third row and the colon means, you know, one both of first and the second columns and so this gives me this 1 2 5 6. Although, you use the source of more subscript index operations maybe somewhat less often. To show you what else we can do. Here's the A matrix and this source A colon, to give me the second column. You can also use this to do assignments. So I can take the second column of A and assign that to 10, 11, 12, and if I do that I'm now, you know, taking the second column of a and I'm assigning this column vector 10, 11, 12 to it. So, now a is this matrix that's 1, 3, 5. And the second column has been replaced by 10, 11, 12. And here's another operation. Let's set A to be equal to A comma 100, 101, 102 like so and what this will do is depend another column vector to the right. So, now, oops. I think I made a little mistake. Should have put semicolons there and now A is equals to this. Okay? I hope that makes sense. So this 100, 101, 102. This is a column vector and what we did was we set A, take A and set it to the original definition. And then we put that column vector to the right and so, we ended up taking the matrix A and--which was these six elements on the left. So we took matrix A and we appended another column vector to the right; which is now why A is a three by three matrix that looks like that. And finally, one neat trick that I sometimes use if you do just a and just a colon like so. This is a somewhat special case syntax. What this means is that put all elements with A into a single column vector and this gives me a 9 by 1 vector. They adjust the other ones are combined together.
12:39
Just a couple more examples. Let's see. Let's say I set A to be equal to 123456, okay? And let's say I set a B to B equal to 11, 12, 13, 14, 15, 16. I can create a new matrix C as A B. This just means my Matrix A. Here's my Matrix B and I've set C to be equal to AB. What I'm doing is I'm taking these two matrices and just concatenating onto each other. So the left, matrix A on the left. And I have the matrix B on the right. And that's how I formed this matrix C by putting them together. I can also do C equals A semicolon B. The semi colon notation means that I go put the next thing at the bottom. So, I'll do is a equals semicolon B. It also puts the matrices A and B together except that it now puts them on top of each other. so now I have A on top and B at the bottom and C here is now in 6 by 2 matrix. So, just say the semicolon thing usually means, you know, go to the next line. So, C is comprised by a and then go to the bottom of that and then put b in the bottom and by the way, this A B is the same as A, B and so you know, either of these gives you the same result.
14:10
So, with that, hopefully you now know how to construct matrices and hopefully starts to show you some of the commands that you use to quickly put together matrices and take matrices and, you know, slam them together to form bigger matrices, and with just a few lines of code, Octave is very convenient in terms of how quickly we can assemble complex matrices and move data around. So that's it for moving data around. In the next video we'll start to talk about how to actually do complex computations on this, on our data. So, hopefully that gives you a sense of how, with just a few commands, you can very quickly move data around in Octave. You know, you load and save vectors and matrices, load and save data, put together matrices to create bigger matrices, index into or select specific elements on the matrices. I know I went through a lot of commands, so I think the best thing for you to do is afterward, to look at the transcript of the things I was typing. You know, look at it. Look at the coursework site and download the transcript of the session from there and look through the transcript and type some of those commands into Octave yourself and start to play with these commands and get it to work. And obviously, you know, there's no point at all to try to memorize all these commands. It's just, but what you should do is, hopefully from this video you have gotten a sense of the sorts of things you can do. So that when later on when you are trying to program a learning algorithms yourself, if you are trying to find a specific command that maybe you think Octave can do because you think you might have seen it here, you should refer to the transcript of the session and look through that in order to find the commands you wanna use. So, that's it for moving data around and in the next video what I'd like to do is start to tell you how to actually do complex computations on our data, and how to compute on the data, and actually start to implement learning algorithms.
Video: Computing on Data
Now that you know how to load and save data in Octave, put your data into matrices and so on. In this video, I'd like to show you how to do computational operations on data. And later on, we'll be using these source of computational operations to implement our learning algorithms.
0:17
Let's get started.
0:19
Here's my Octave window. Let me just quickly initialize some variables to use for our example. So set A to be a three by two matrix, and set B to a three by two matrix, and let's set C to a two by two matrix like so.
0:39
Now let's say I want to multiply two of my matrices. So let's say I want to compute AC, I just type AC, so it's a three by two matrix times a two by two matrix, this gives me this three by two matrix. You can also do element wise operations and do A.* B and what this will do is it'll take each element of A and multiply it by the corresponding elements B, so that's A, that's B, that's A .* B. So for example, the first element gives 1 times 11, which gives 11. The second element gives 2 time 12 Which gives 24, and so on. So this is element-wise multiplication of two matrices. And in general, the period tends to, is usually used to denote element-wise operations in Octave. So here's a matrix A, and if I do A .^ 2, this gives me the element wise squaring of A. So 1 squared is 1, 2 squared is 4, and so on.
1:41
Let's set v as a vector. Let's set v as one, two, three as a column vector. You can also do one dot over v to do the element-wise reciprocal of v, so this gives me one over one, one over two, and one over three, and this is where I do the matrices, so one dot over a gives me the element wise inverse of a.
2:02
And once again, the period here gives us a clue that this an element-wise operation. We can also do things like log(v), this is a element-wise logarithm of the v E to the V is base E exponentiation of these elements, so this is E, this is E squared EQ, because this was V, and I can also do abs V to take the element-wise absolute value of V. So here, V was our positive, abs, minus one, two minus 3, the element-wise absolute value gives me back these non-negative values. And negative v gives me the minus of v. This is the same as negative one times v, but usually you just write negative v instead of -1*v. And what else can you do? Here's another neat trick. So, let's see. Let's say I want to take v an increment each of its elements by one. Well one way to do it is by constructing a three by one vector that's all ones and adding that to v. So if I do that, this increments v by from 1, 2, 3 to 2, 3, 4. The way I did that was, length(v) is 3, so ones(length(v),1), this is ones of 3 by 1, so that's ones(3,1) on the right and what I did was v plus ones v by one, which is adding this vector of our ones to v, and so this increments v by one,
3:40
and another simpler way to do that is to type v plus one. So she has v, and v plus one also means to add one element wise to each of my elements of v.
3:52
Now, let's talk about more operations. So here's my matrix A, if you want to buy A transposed, the way to do that is to write A prime, that's the apostrophe symbol, it's the left quote, so it's on your keyboard, you have a left quote and a right quote. So this is actually the standard quotation mark. Just type A transpose, this gives me the transpose of my matrix A. And, of course, A transpose, if I transpose that again, then I should get back my matrix A.
4:25
Some more useful functions. Let's say lower case a is 1 15 2 0.5, so it's 1 by 4 matrix. Let's say val equals max of A this returns the maximum value of A which in this case is 15 and I can do val, ind max(a) and this returns val and ind which are going to be the maximum value of A which is 15, as well as the index. So it was the element number two of A that was 15 so ind is my index into this. Just as a warning, if you do max(A), where A is a matrix, what this does is this actually does the column wise maximum. But say a little more about this in a second.
5:11
Still using this example that there for lowercase a. If I do a < 3, this does the element wise operation. Element wise comparison, so the first element of A is less than three so this one. Second element of A is not less than three so this value says zero cuz it's false. The third and fourth elements of A are less than three, so that's just 1 1. So that's the element-wise comparison of all four elements of the variable a < 3. And it returns true or false depending on whether or not there's less than three. Now, if I do find(a < 3), this will tell me which are the elements of a, the variable a, that are less than 3, and in this case, the first, third and fourth elements are less than 3. For our next example, let me set a to be equal to magic(3). The magic function returns, let's type help magic. The magic function returns these matrices called magic squares. They have this, you know, mathematical property that all of their rows and columns and diagonals sum up to the same thing. So, you know, it's not actually useful for machine learning as far as I know, but I'm just using this as a convenient way to generate a three by three matrix. And these magic squares have the property that each row, each column, and the diagonals all add up to the same thing, so it's kind of a mathematical construct. I use this magic function only when I'm doing demos or when I'm teaching octave like those in, I don't actually use it for any useful machine learning application. But let's see, if I type RC = find(A > 7) this finds All the elements of A that are greater than equal to seven, and so r, c stands for row and column. So the 1,1 element is greater than 7, the 3,2 element is greater than 7, and the 2,3 element is greater than 7. So let's see. The 2,3 element, for example, is A(2,3), is 7 is this element out here, and that is indeed greater than equal seven. By the way, I actually don't even memorize myself what these find functions do and what all of these things do myself. And whenever I use the find function, sometimes I forget myself exactly what it does, and now I would type help find to look at the document. Okay, just two more things that I'll quickly show you. One is the sum function, so here's my a, and then type sum(a). This adds up all the elements of a, and if I want to multiply them together, I type prod(a) prod sends the product, and this returns the product of these four elements of A. Floor(a) rounds down these elements of A, so 0.5 gets rounded down to 0. And ceil, or ceiling(A) gets rounded up to the nearest integer, so 0.5 gets rounded up to 1. You can also, let's see. Let me type rand(3), this generates a three by three matrix. If i type max(rand(3), what this does is it takes the element-wise maximum of 3 random 3 by 3 matrices. So you notice all of these numbers tend to be a bit on the large side because each of these is actually the max of a element
8:34
wise max of two randomly generated matrices. This is my magic number. This is my magic square, three by three A. Let's say I type max A, and then this will be a [], 1, what this does is this texts the column wise maximum. So the max of the first column is 8, max of second column is 9, the max of the third column is 7. This 1 means to take the max among the first dimension of 8.
9:05
In contrast, if I were to type max A, this funny notation, two, then this takes the per row maximum. So the max of the first row is eight, max of second row is seven, max of the third row is nine, and so this allows you to take maxes either per row or per column.
9:24
And remember the default's to a column wise element. So if you want to find the maximum element in the entire matrix A, you can type max(max(A)) like so, which is 9. Or you can turn A into a vector and type max(A(
[C2P1] Andrew Ng - Machine Learning的更多相关文章
- Andrew Ng Machine Learning 专题【Linear Regression】
此文是斯坦福大学,机器学习界 superstar - Andrew Ng 所开设的 Coursera 课程:Machine Learning 的课程笔记. 力求简洁,仅代表本人观点,不足之处希望大家探 ...
- Andrew Ng Machine Learning 专题【Logistic Regression & Regularization】
此文是斯坦福大学,机器学习界 superstar - Andrew Ng 所开设的 Coursera 课程:Machine Learning 的课程笔记. 力求简洁,仅代表本人观点,不足之处希望大家探 ...
- [C2P2] Andrew Ng - Machine Learning
##Linear Regression with One Variable Linear regression predicts a real-valued output based on an in ...
- [C2P3] Andrew Ng - Machine Learning
##Advice for Applying Machine Learning Applying machine learning in practice is not always straightf ...
- Andrew Ng Machine learning Introduction
1. 机器学习的定义:Machine learning is programming computers to optimize a performance criterion(优化性能标准) usi ...
- Andrew Ng Machine Learning Coursera学习笔记
课程记录笔记如下: 1.目前ML的应用 包括:数据挖掘database mining.邮件过滤email anti-spam.机器人autonomous robotics.计算生物学computati ...
- 机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho
机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho 总述 本书是 2014 ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- Machine Learning and Data Mining(机器学习与数据挖掘)
Problems[show] Classification Clustering Regression Anomaly detection Association rules Reinforcemen ...
随机推荐
- 201871010113-刘兴瑞《面向对象程序设计(java)》第十一周学习总结
项目 内容 这个作业属于哪个课程 <任课教师博客主页链接> https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 <作业链接地址>htt ...
- luoguP4022 [CTSC2012]熟悉的文章
题意 显然这个\(L\)是可以二分的,我们只需要判断\(L\)是否合法即可. 显然有一个\(O(n^2)\)的DP: 设\(f_i\)表示当前匹配到\(i\)的最大匹配长度. \(f_i=max(f_ ...
- MYSQL ERROR:1130 解决
MYSQL ERROR:1130 解决 ERROR 1130: Host '127.0.0.7' is not allowed to connect to this MySQL server 解决 ...
- 2019CSP-J/S受虐记
emmmm...... 今年noip很波折,我从7月开始准备 但CCF居然停了noip,这搞得我很迷茫,CCF你在干什么! 然后又恢复了,这有搞得我很懵逼?(还改名叫csp了) 就换了个名,CCF你搞 ...
- 【Notepad++】notepad++主题和字体设置(非常好看舒服的)
#效果图 1.字体:Courier New 字号:14号字体 2.字体:Consolas 字号:14号字体 #设置方法 1.设置---语言格式设置 2.选择主题,同时勾选“使用全局字体”“使用全局字体 ...
- Android Monkey的用法(一)
Monkey 简介 ü Monkey 是一个命令行工具,可以运行在 Android 模拟器里或真实设备中.它可以向系统发送伪随机(pseudo-random)的用户事件流(如按键输入.触摸屏输入 ...
- 安装torch
一.实验环境 1.Windows7x64_SP1 2.anaconda3.7 + python3.7(anaconda集成,不需单独安装) 二.问题描述 1.使用如下命令进行安装: pip3 inst ...
- 掌握Spring REST TypeScript生成器
在优锐课的java分享中,讨论了关于Spring REST TypeScript生成器,该生成器创建反映后端模型和REST服务的模型和服务.码了很多干货,分享给大家参考学习. 我注意到网络开发人员创建 ...
- 明解C语言 入门篇 第八章答案
练习8-1 #include<stdio.h> #define diff(x,y)(x-y) int main() { int x; int y; printf("x=" ...
- C# - WinFrm应用程序调用SharpZipLib实现文件的压缩和解压缩
前言 本篇主要记录:VS2019 WinFrm桌面应用程序调用SharpZipLib,实现文件的简单压缩和解压缩功能. SharpZipLib 开源地址戳这里. 准备工作 搭建WinFrm前台界面 添 ...