6.1 Spark SQL
一、从shark到Spark SQL
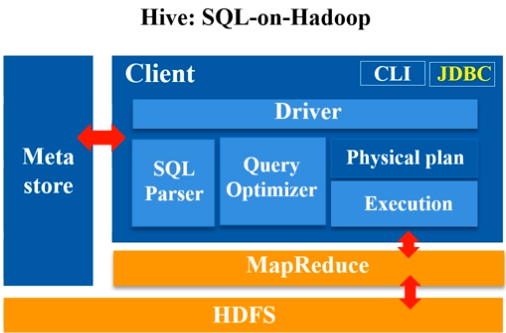
Hive能够把SQL程序转换成map-reduce程序
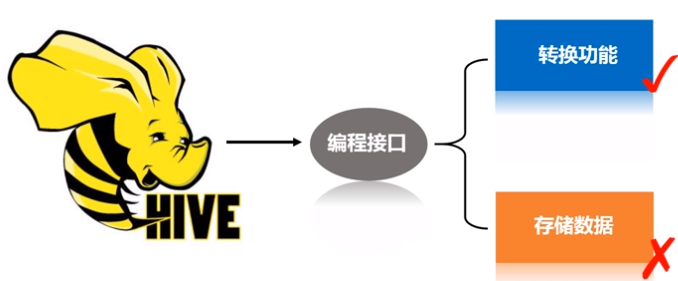
可以把Hadoop中的Hive看作是一个接口,主要起到了转换的功能,并没有实际存储数据。

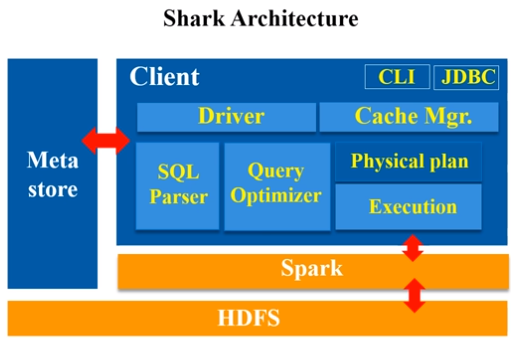
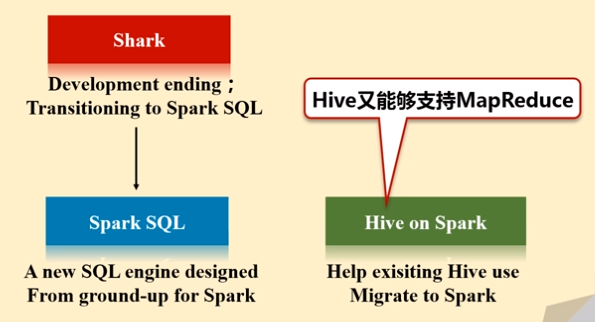
Shark即Hive on Spark,为了实现与Hive兼容,Shark在HiveQL方面重用了Hive中HiveQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MapReduce作业替换成了Spark作业,通过Hive的HiveQL解析,把HiveQL翻译成Spark上的RDD操作(shark相当于是hive的引进版,它把hive里的各种模块,基本上一五一十地照搬过来,就做了一个最底层的修改,hive是从最底层转成MapReduce程序,而到了shark,它的其他模块都没变,就把最底层翻译成spark应用程序。)
 、
、
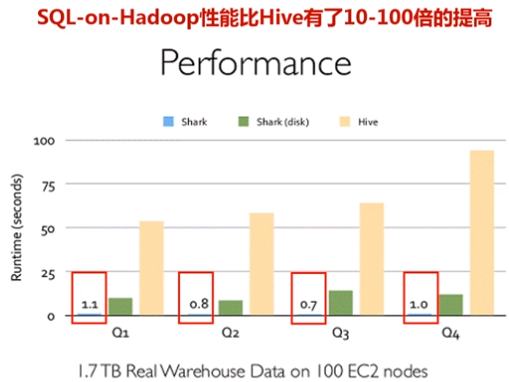
Shark的出现,使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高
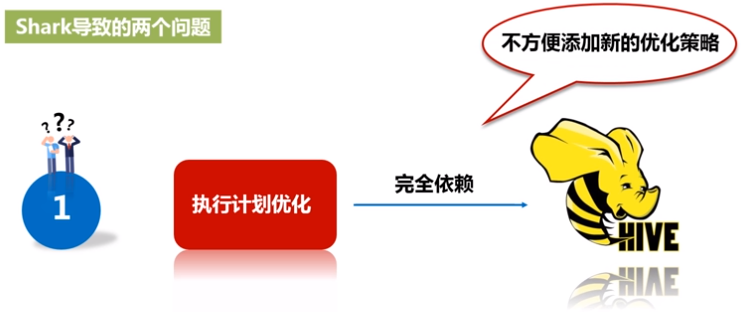
因为shark是基于hive修改的,会带来两个问题:
1)执行计划优化完全依赖于Hive,不方便添加新的优化策略;
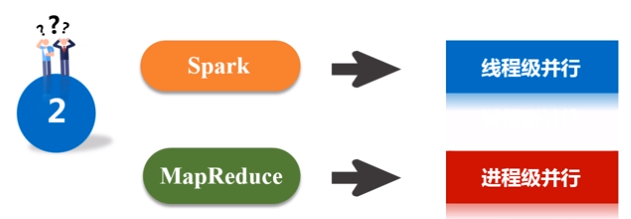
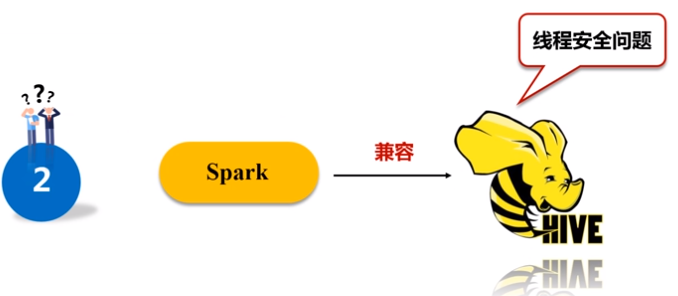
2)spark是线程级并行,MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支
2014年6月1日Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话,但也因此发展出两个直线:SparkSQL和Hive on Spark
- Spark SQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive
- Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎
二、Spark SQL设计
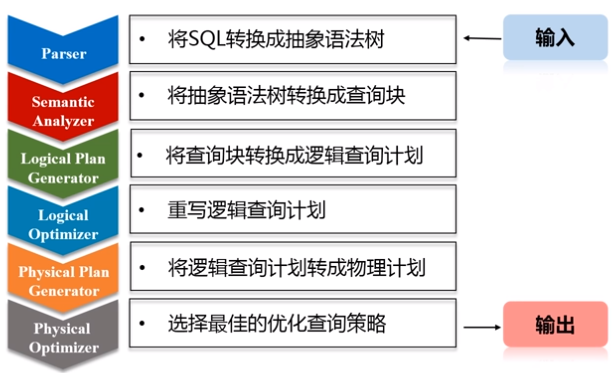
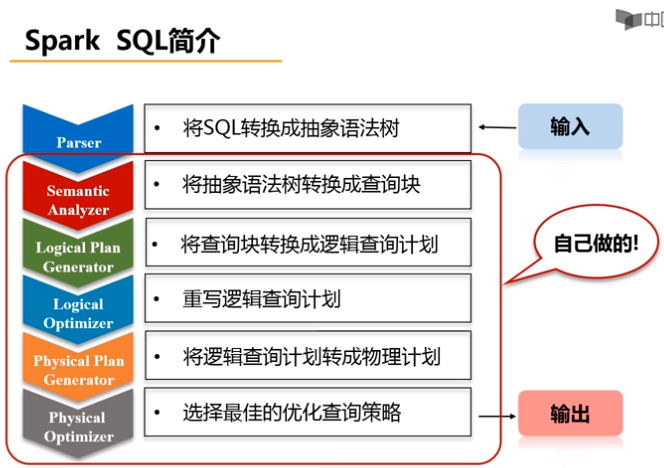
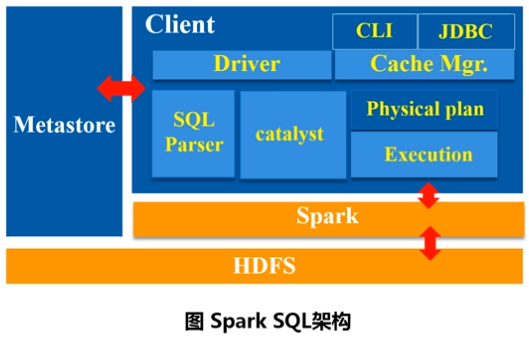
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。(Spark SQL除了沿用Parser(把SQL转换成抽象语法树)这一个模块外,其他模块全部自己定义。)


三、为什么推出Spark SQL

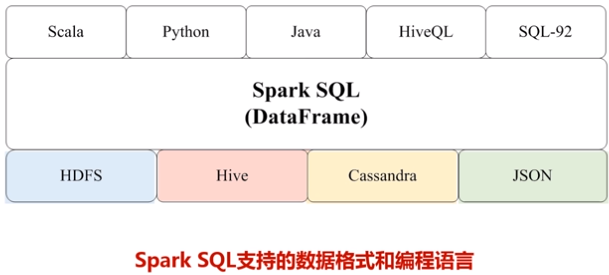
(1)关系型数据库中只存储了一部分的结构化数据,但是实际上现在要处理的相关数据类型不仅仅包括关系数据库,现在大数据时代90%的数据都是非结构化数据和半结构化数据,对于这种数据,不能用SQL语句分析。而spark SQL同时支持非结构化、半结构化、结构化数据分析。


(2)关系型数据库没有办法处理类似机器学习和图像处理的图结构数据
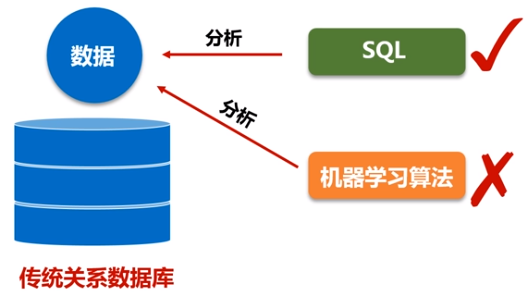
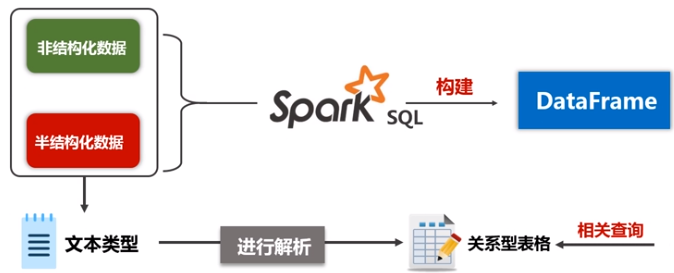
Spark SQL可以有效地把关系数据查询和复杂分析算法融合。

参考文献:
6.1 Spark SQL的更多相关文章
- Spark SQL 之 Data Sources
#Spark SQL 之 Data Sources 转载请注明出处:http://www.cnblogs.com/BYRans/ 数据源(Data Source) Spark SQL的DataFram ...
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL Example
Spark SQL Example This example demonstrates how to use sqlContext.sql to create and load a table ...
- 通过Spark SQL关联查询两个HDFS上的文件操作
order_created.txt 订单编号 订单创建时间 -- :: -- :: -- :: -- :: -- :: order_picked.txt 订单编号 订单提取时间 -- :: ...
- Spark SQL 之 Migration Guide
Spark SQL 之 Migration Guide 支持的Hive功能 转载请注明出处:http://www.cnblogs.com/BYRans/ Migration Guide 与Hive的兼 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
- 基于Spark1.3.0的Spark sql三个核心部分
基于Spark1.3.0的Spark sql三个核心部分: 1.可以架子啊各种结构化数据源(JSON,Hive,and Parquet) 2.可以让你通过SQL,saprk内部程序或者外部攻击,通过标 ...
随机推荐
- [译]ABP v1.0终于发布了!
ABP v1.0终于发布了! 今天是个大日子!经过约3年的不断开发,第一个稳定的ABP版本,1.0,已经发布了.感谢为该项目做出贡献或试用过的每个人. 立即开始使用新的ABP框架:abp.io/get ...
- H5混合应用之webview元素定位工具
一.工具选择 webview元素定位有三种方式: 使用driver.page_source方法,将获取到的页面内容写入到一个html文件中,然后使用浏览器打开html文件,使用F12调试用具进行元素定 ...
- pytest框架与unittest框架的对比
一.pytest的优势 pytest是基于unittest之上的单元测试框架,它的优势如下: 自动发现测试模块和测试方法 断言使用 assert + 表达式 可以设置测试会话级(session).模块 ...
- 华为mate10 pro内置浏览器出现的令人头疼的样式兼容问题
问题描述: 下图红色框区域内容在华为mate10 pro(以下简称mate10)内置浏览器中整体向左偏移,没有居中,其它手机浏览器都无该问题,如下图 问题分析 经过一番追根溯源,我发现是 bo ...
- 五分钟搞定 HTTPS 配置,二哥手把手教
01.关于 FreeSSL.cn FreeSSL.cn 是一个免费提供 HTTPS 证书申请.HTTPS 证书管理和 HTTPS 证书到期提醒服务的网站,旨在推进 HTTPS 证书的普及与应用,简化证 ...
- 【CF933E】A Preponderant Reunion(动态规划)
[CF933E]A Preponderant Reunion(动态规划) 题面 CF 洛谷 题解 直接做很不好搞,我们把条件放宽,我们每次可以选择两个相邻的非零数让他们减少任意值,甚至可以减成负数(虽 ...
- jackson json转实体对象 com.fasterxml.jackson.databind.exc.UnrecognizedPropertyException
Jackson反序列化错误:com.fasterxml.jackson.databind.exc.UnrecognizedPropertyException: Unrecognized field的解 ...
- 用友的SPS定义
基于标准产品的支持服务(Standard Product Support,SPS).主要包括:更新升级(软件补丁更新与产品升级).问题解决(产品问题在线或热线解析).知识转移(用友到客户的知识传递). ...
- EF框架访问access数据库入门(后附官方推荐“驱动”版本)
vs2017调试通过. 1.添加需要的provider,有点添加驱动的意思.右击项目,NUGET “浏览”,“JetEntityFrameworkProvider”,安装,如图 完成后配置文件(控制台 ...
- centos查找文件及文件内容
1.查找文件 find / -name 'filename' 2.查找文件夹(目录) find / -name 'path' -type d 3.查找内容 find . | xargs grep -r ...