常见的几种 Normalization 算法
神经网络中有各种归一化算法:Batch Normalization (BN)、Layer Normalization (LN)、Instance Normalization (IN)、Group Normalization (GN)。从公式看它们都差不多,如 (1) 所示:无非是减去均值,除以标准差,再施以线性映射。
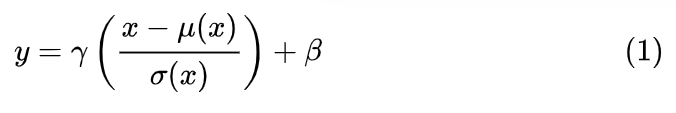
Batch Normalization
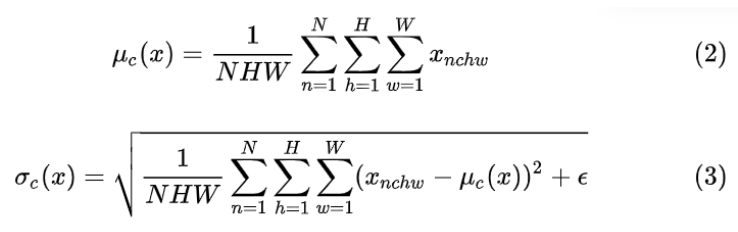
Batch Normalization (BN) 是最早出现的,也通常是效果最好的归一化方式。feature map: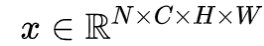 包含 N 个样本,每个样本通道数为 C(在NLP中为词向量长度),高为 H(在NLP中为时间长度),宽为 W(在NLP中为1)。对其求均值和方差时,将在 N、H、W上操作,而保留通道 C 的维度。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。具体公式为:
包含 N 个样本,每个样本通道数为 C(在NLP中为词向量长度),高为 H(在NLP中为时间长度),宽为 W(在NLP中为1)。对其求均值和方差时,将在 N、H、W上操作,而保留通道 C 的维度。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。具体公式为:
如果把类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页......),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),有C页,求标准差时也是同理。最后求出来应该是:1*C, 保证每个样本两两之间不会偏差太大
Layer Normalization
BN 的一个缺点是需要较大的 batchsize 才能合理估训练数据的均值和方差,这导致内存很可能不够用,同时它也很难应用在训练数据长度不同的 RNN 模型上。Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化
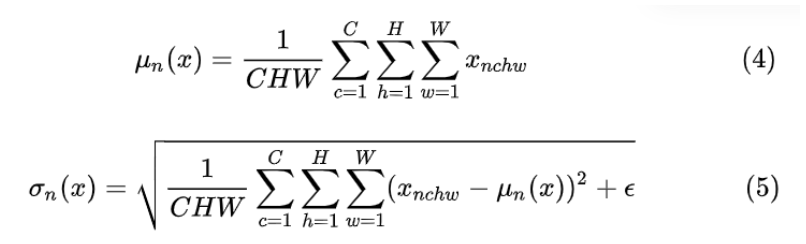
对于LN 对每个样本的 C、H、W 维度上的数据求均值和标准差,保留 N 维度。其均值和标准差公式为:
继续采用上一节的类比,把一个 batch 的 feature 类比为一摞书。LN 求均值时,相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”,有N本书,求标准差时也是同理。最后求出来的是:N*1,保证的是每个批次两两之间不会偏差较大。
Instance Normalization
Instance Normalization (IN) 最初用于图像的风格迁移。作者发现,在生成模型中, feature map 的各个 channel 的均值和方差会影响到最终生成图像的风格,因此可以先把图像在 channel 层面归一化,然后再用目标风格图片对应 channel 的均值和标准差“去归一化”,以期获得目标图片的风格。IN 操作也在单个样本内部进行,不依赖 batch。
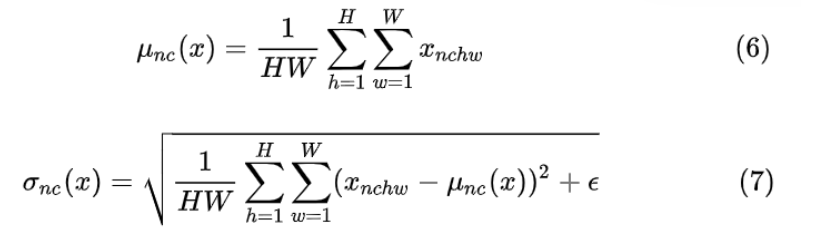
IN 求均值时,相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每页书的“平均字”,求标准差时也是同理。
常见的几种 Normalization 算法的更多相关文章
- Java常见的几种排序算法-插入、选择、冒泡、快排、堆排等
本文就是介绍一些常见的排序算法.排序是一个非常常见的应用场景,很多时候,我们需要根据自己需要排序的数据类型,来自定义排序算法,但是,在这里,我们只介绍这些基础排序算法,包括:插入排序.选择排序.冒泡排 ...
- 用 Java 实现常见的 8 种内部排序算法
一.插入类排序 插入类排序就是在一个有序的序列中,插入一个新的关键字.从而达到新的有序序列.插入排序一般有直接插入排序.折半插入排序和希尔排序. 1. 插入排序 1.1 直接插入排序 /** * 直接 ...
- [Math] 常见的几种最优化方法
我们每个人都会在我们的生活或者工作中遇到各种各样的最优化问题,比如每个企业和个人都要考虑的一个问题“在一定成本下,如何使利润最大化”等.最优化方法是一种数学方法,它是研究在给定约束之下如何寻求某些因素 ...
- 几种排序算法的学习,利用Python和C实现
之前学过的都忘了,也没好好做过总结,现在总结一下. 时间复杂度和空间复杂度的概念: 1.空间复杂度:是程序运行所以需要的额外消耗存储空间,一般的递归算法就要有o(n)的空间复杂度了,简单说就是递归集算 ...
- PHP四种基础算法详解
许多人都说 算法是程序的核心,一个程序的好于差,关键是这个程序算法的优劣.作为一个初级phper,虽然很少接触到算法方面的东西 .但是对于冒泡排序,插入排序,选择排序,快速排序四种基本算法,我想还是要 ...
- 学习Java绝对要懂的,Java编程中最常用的几种排序算法!
今天给大家分享一下Java中几种常见的排序算法的Java代码 推荐一下我的Java学习羊君前616,中959,最后444.把数字串联起来! ,群里有免费的学习视频和项目给大家练手.大神有空时也 ...
- 常见的四种文本自动分词详解及IK Analyze的代码实现
以下解释来源于网络-百度百科 1.word分词器 word分词 [1] 是一个Java实现的分布式的中文分词组件,提供了多种基于词典的分词算法,并利用ngram模型来消除歧义.能准确识别英文.数字, ...
- 10 种机器学习算法的要点(附 Python 和 R 代码)
本文由 伯乐在线 - Agatha 翻译,唐尤华 校稿.未经许可,禁止转载!英文出处:SUNIL RAY.欢迎加入翻译组. 前言 谷歌董事长施密特曾说过:虽然谷歌的无人驾驶汽车和机器人受到了许多媒体关 ...
- 一文学会最常见的10种NLP处理技术
一文学会最常见的10种NLP处理技术(附资源&代码) 技术小能手 2017-11-21 11:08:29 浏览2562 评论0 算法 HTTPS 序列 自然语言处理 神经网络 摘要: 自然 ...
随机推荐
- HTML5 Canvas 为网页添加文字水印
<!DOCTYPE html> <html> <body> <canvas id=" style="border:1px solid #d ...
- Python的定时执行
最近手把手教妹子写Python,被一篇博客误导了,这里记录一下. 妹子需要的是一个定时闹钟,到点往钉钉群里推个消息.她一顿搜索猛如虎,参照着其他人的博客,搞了一个while: target_time ...
- opencv Mat基础
Mat Mat由两部分构成 matrix header pointer to the matrix containing the pixel values Mat is basically a cla ...
- ElasticSearch简介(三)——中文分词
很多时候,我们需要在ElasticSearch中启用中文分词,本文这里简单的介绍一下方法.首先安装中文分词插件.这里使用的是 ik,也可以考虑其他插件(比如 smartcn). $ ./bin/ela ...
- 第2个word发布的博客
//接收的为空时,则表示客户端下线,跳出循环 if (r == 0) { break; }; string str = Encoding.UTF8.GetString(buffer, 0, r); ...
- mybatis关联关系映射
1.一对多关联关系 2.多对多关联关系 首先先用逆向生成工具生成t_hibernate_order.t_hibernate_order_item t_hibernate_book.t_hibernat ...
- list方法补充
在上一个随便我们写了list 常用的方法,该随便为一些需要补充的内容 注:本次例子为: student = ["张天赐","小明","小红" ...
- 函数的防抖---js
执行规定一段时间后执行 <input type="text" id="inp" /> <script> var oInp = docum ...
- [转]Doing more with Outlook filter and SQL DASL syntax
本文转自:https://blogs.msdn.microsoft.com/andrewdelin/2005/05/10/doing-more-with-outlook-filter-and-sql- ...
- Xcode打印如下错误:Unbalanced calls to begin/end appearance transitions 解决办法
今天在做自己的项目时遇到如下错误,项目运行以后,打印台打印如下: Unbalanced calls to begin/end appearance transitions for <HomeVi ...