数据的查找和提取[2]——xpath解析库的使用
xpath解析库的使用
在上一节,我们介绍了正则表达式的使用,但是当我们提取数据的限制条件增多的时候,正则表达式会变的十分的复杂,出一丁点错就提取不出来东西了。但python已经为我们提供了许多用于解析数据的库,接下来几篇博客就给大家简单介绍一下xpath、beautiful soup以及pyquery的使用。今天首先进入xpath的学习。
1.1实例
在引入实例之前,我们先编写一个html,如下所示:
<div>
<url>
<li class="item-0"><a href="link3.html">first item</a></li>
<li class="item-inactive"><a href="link3.html">second item</a></li>
<li class="item-1"><a href="link4.html">third item</a></li>
<li class="item-0"><a href="link5.html">fourth item</a>
</url>
</div>接下来我们都将围绕这段进行尝试
首先我们使用lxml库
第一步先将这段文本转换为一个etree的对象,再进行转换,输出结果,我们输出之后发现,愿文本中缺失的闭标签被自动的补齐,所以输出的是一段完整的html,如下所示:
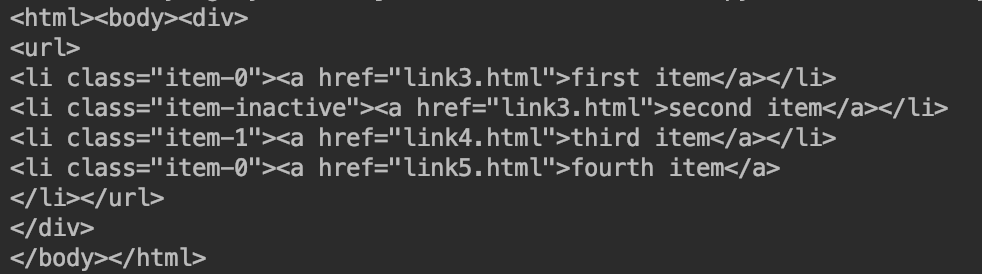
我们可以看到最后一个li标签 被补齐了,又多出来了html和body
这就变成了一段完整的html啦~
1.2找节点
下面主要介绍一下用xpath寻找需要的节点
1.2.1父子节点
与正则表达式相同,xpath也拥有一个书写表达式的准则,如下所示:
/ 直接的子节点
// 所有的子节点
.. 父节点
* 所有节点
@ 属性
[] 中括内是约束条件
接下来先介绍一下如何查找子节点
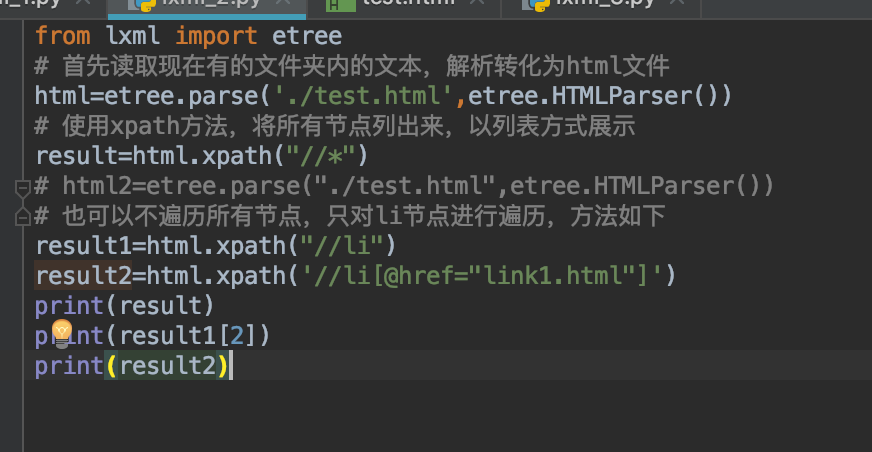
首先看result的值,用//表示所有的子节点,后面跟*代表把所有节点。
再看result1的值,用//表示所有子节点,后面跟li,代表所有的 li 节点。
这里还需要注意一点的是,找到的内容都是一个列表的形式,那么当然也可以用数组的方式去找啦~
第三个我们暂且不看,这就是找对应的子节点的方法。
下面我们看一下如何找父节点
其实规则和之前的一样,我们只需先找到 需要父节点的节点,然后用 .. 就可以定位到上一层的父节点了。就是这么简单。
1.2.2 根据属性值的限制
上面那个代码片的result2,就是在找到需要找的节点类型 li 之后,后面跟了[]来表示约束条件,括号里的内容也很好理解,就是属性href为link1.html的 li 节点
那么有人可能会问了,如果要对一个节点有多个属性同时进行限制呢?
其实也很简单,因为逻辑运算符在这里当然适用,只用在中括号中,用and or 不等号进行连接,就能同时对多属性进行筛选
1.2.3 一个节点有多个属性值
假如说现在有一段html是这样的
<li class="item-0 item"><a href="link3.html">first item</a></li>
如果再用
之前的方法对class值为item-0的节点进行筛选,就找不到这个了,因为,里面不是一个属性,还有另外一个item呢,所以我们这里要用到contains这个方法,
改为
etree.xpath('//li[contains(class,"item-0")]')即可
1.2.3 得到节点的内容
在前面,我们知道了如何找到需要的节点,肯定也想知道如何找到节点的内容(不然找他们干嘛呢),这里py为我们提供了一个text()的用法,我们可以看下面的一段代码

还是上面的文本,这段代码,首先找到class为item-0的节点,有两个,分别是
<li class="item-0"><a href="link3.html">first item</a></li>
<li class="item-0"><a href="link5.html">fourth item</a>
但是又一点要注意的是,在初始化的时候,这段文本已经被自动补齐了,变成如下所示:
<li class="item-0"><a href="link3.html">first item</a></li>
<li class="item-0"><a href="link5.html">fourth item</a>
</li>
先看看这段代码的输出结果
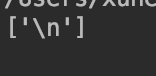
这是因为,我们用的是/ 这个符号,也就是说,只能找到 li 节点自己的文本,所以一个为空,一个为换行符
那么要找到我们想找到的,有两个途径,首先尝试第一个
先找到a节点,再输出其中的内容,代码以及结果如下:

结果:

可以看到输出了我们期待的结果直接// 输出所有的text
代码以及结果如下:
再看第二种方法,也就是

结果:

可以看到,这里还输出了换行符,也是可以理解的。
1.2.5找到对应顺序位次的节点
还是上面的那段文本,有很多 li 节点,其实在筛选的时候,我们可以直接用 节点➕下标来查找节点,但是需要注意的是,这里的下标顺序就是从1开始的
以上就是对于xpath使用的简单介绍,博主也在学习,想通过博客记录成长,有问题欢迎提出,一起讨论!下一篇介绍Beautifu Soup的使用
数据的查找和提取[2]——xpath解析库的使用的更多相关文章
- python爬虫三大解析库之XPath解析库通俗易懂详讲
目录 使用XPath解析库 @(这里写自定义目录标题) 使用XPath解析库 1.简介 XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言. ...
- BeautifulSoup与Xpath解析库总结
一.BeautifulSoup解析库 1.快速开始 html_doc = """ <html><head><title>The Dor ...
- Xpath解析库的使用
### Xpath常用规则 ## nodename 选取此节点的所有子节点 ## / 从当前节点选取直接子节点 ## // 从当前节点选取子孙节点 ## . 选取当前节点 ## .. 选取当前节点的父 ...
- 爬虫之xpath解析库
xpath语法: 1.常用规则: 1. nodename: 节点名定位 2. //: 从当前节点选取子孙节点 3. /: 从当前节点选取直接子节点 4. node ...
- xpath beautiful pyquery三种解析库
这两天看了一下python常用的三种解析库,写篇随笔,整理一下思路.太菜了,若有错误的地方,欢迎大家随时指正.......(conme on.......) 爬取网页数据一般会经过 获取信息-> ...
- Python爬虫3大解析库使用导航
1. Xpath解析库 2. BeautifulSoup解析库 3. PyQuery解析库
- python爬虫使用xpath解析页面和提取数据
XPath解析页面和提取数据 一.简介 关注公众号"轻松学编程"了解更多. XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言.X ...
- 爬虫系列二(数据清洗--->xpath解析数据)
一 xpath介绍 XPath 是一门在 XML 文档中查找信息的语言.XPath 用于在 XML 文档中通过元素和属性进行导航. XPath 使用路径表达式在 XML 文档中进行导航 XPath 包 ...
- xpath解析数据
xpath解析数据 """ xpath 也是一种用于解析xml文档数据的方式 xml path w3c xpath搜索用法 在 XPath 中,有七种类型的节点:元素.属 ...
随机推荐
- Unity3D热更新之LuaFramework篇[09]--资源热更新与代码热更新的具体实现
前言 在上一篇文章 Unity3D热更新之LuaFramework篇[08]--热更新原理及热更服务器搭建 中,我介绍了热更新的基本原理,并且着手搭建一台服务器. 本篇就做一个实战练习,真正的来实现热 ...
- 基于SpringBoot从零构建博客网站 - 新增创建、修改、删除专栏功能
守望博客是支持创建专栏的功能,即可以将一系列相关的文章归档到专栏中,方便用户管理和查阅文章.这里主要讲解专栏的创建.修改和删除功能,至于专栏还涉及其它的功能,例如关注专栏等后续会穿插着介绍. 1.创建 ...
- python 简单的实现文件内容去重
文件去重 这里主要用的是set()函数,特别地,set中的元素是无序的,并且重复元素在set中自动被过滤. 测试文本为 data.txt 具体代码如下: // 文件去重 #!/usr/bin/env ...
- js中数组和对象的合并
1 数组合并 1.1 concat 方法 1 2 3 4 var a=[1,2,3],b=[4,5,6]; var c=a.concat(b); console.log(c);// 1,2,3,4,5 ...
- MySQL操作命令梳理(2)
一.表操作 在mysql运维操作中会经常使用到alter这个修改表的命令,alter tables允许修改一个现有表的结构,比如增加或删除列.创造或消去索引.改变现有列的类型.或重新命名列或表本身,也 ...
- 使用Yapi展示你的api接口
今天研究了下一款非常好用的api集中展示工具---Yapi,具体网址 https://hellosean1025.github.io/yapi/documents/index.html 如图,看下基本 ...
- java根据经纬度查询门店地理位置-完美解决附近门店问题
1.首先我们需要创建一个门店表如下: CREATE TABLE `app_store` ( `store_id` ) NOT NULL AUTO_INCREMENT COMMENT '发布id', ` ...
- openjdk:8u22-jre-alpine在java开发中的NullPointerException错误解决方案
问题描述 ** 在SpringBoot项目中使用了Ureport报表组件, 打包发布部署到docker中启动报错 ** java.lang.NullPointerException at sun.aw ...
- 基于RobotFramework实现自动化测试
Java + robotframework + seleniumlibrary 使用Robot Framework Maven Plugin(http://robotframework.org/Mav ...
- JavaWeb——Servlet开发2
1.HttpServletRequest的使用 获取Request的参数的方法. 方法getParameter将返回参数的单个值 方法getParameterValues将返回参数的值的数组 方法ge ...