神奇的 SQL 之团结的力量 → JOIN
前言
开心一刻
闺蜜家暴富,买了一栋大别野,喊我去吃饭,菜挺丰盛的,筷子有些不给力,银筷子,好重,我说换个竹子的,闺蜜说,这种银筷子我家总共才五双,只有贵宾才能用~我咬着牙享受着贵宾待遇,终于,在第三次夹虾排滑落盘子时,我爆发了:去它喵的贵宾,我要虾排……不是……我要竹筷子!

连接
简单来说,就是将其他表中的列添加过来,进行"添加列"的运算,如下图所示。

为什么需要进行"添加列"的操作 了? 因为我们在设计数据库的时候,往往需要满足范式(具体满足范式几,无法一概而论,这里不做细究),会导致我们某个需求的全部列分散在不同的表中,所以为了满足需求,我们需要将某些表的列进行连接。我们来看个简单例子,假如我们有两张表(t_user,t_login_log):
DROP TABLE IF EXISTS t_user;
CREATE TABLE t_user (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
user_name VARCHAR(50) NOT NULL COMMENT '用户名',
sex TINYINT(1) NOT NULL COMMENT '性别, 1:男,0:女',
age TINYINT(3) UNSIGNED NOT NULL COMMENT '年龄',
phone_number VARCHAR(11) NOT NULL DEFAULT '' COMMENT '电话号码',
email VARCHAR(50) NOT NULL DEFAULT '' COMMENT '电子邮箱',
create_time datetime NOT NULL COMMENT '创建时间',
update_time datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (id)
) COMMENT='用户表'; DROP TABLE IF EXISTS t_login_log;
CREATE TABLE t_login_log (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
user_name VARCHAR(50) NOT NULL COMMENT '用户名',
ip VARCHAR(15) NOT NULL COMMENT '登录IP',
client TINYINT(1) NOT NULL COMMENT '登录端, 1:android, 2:ios, 3:PC, 4:H5',
create_time datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY (id)
) COMMENT='登录日志'; INSERT INTO t_user(user_name, sex, age, phone_number,email,create_time,update_time) VALUES
('Bruce Lee', 1, 32, '', 'brucelee@126.com', NOW(), NOW()),
('Jackie Chan', 1, 65, '', 'JackieChan@126.com', NOW(), NOW()),
('Jet Li', 1, 56, '', 'JetLi@126.com', NOW(), NOW()),
('Jack Ma', 1, 55, '', 'JackMa@126.com', NOW(), NOW()),
('Pony', 1, 48, '', 'Pony@126.com', NOW(), NOW()),
('Robin Li', 1, 51, '', 'RobinLi@126.com', NOW(), NOW()); INSERT INTO t_login_log(user_name, ip, client, create_time) VALUES
('Jackie Chan', '10.53.56.78',2, '2019-10-12 12:23:45'),
('Jackie Chan', '10.53.56.78',2, '2019-10-12 22:23:45'),
('Jet Li', '10.53.56.12',1, '2018-08-12 22:23:45'),
('Jet Li', '10.53.56.12',1, '2019-10-19 10:23:45'),
('Jack Ma', '198.11.132.198',2, '2018-05-12 22:23:45'),
('Jack Ma', '198.11.132.198',2, '2018-11-11 22:23:45'),
('Jack Ma', '198.11.132.198',2, '2019-06-18 22:23:45'),
('Robin Li', '220.181.38.148',3, '2019-10-21 09:45:56'),
('Robin Li', '220.181.38.148',3, '2019-10-26 22:23:45'),
('Pony', '104.69.160.60',4, '2019-10-12 10:23:45'),
('Pony', '104.69.160.60',4, '2019-10-15 20:23:45');
如果我们需要展示如下列表(需求:展示用户列表,并显示其最近登录时间、最近登录 IP),那么就需要 t_user 和 t_login_log 连表查了
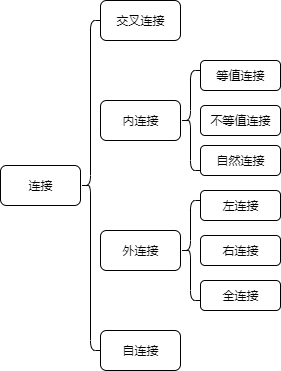
连接的类型有很多种,细分如下图
交叉连接
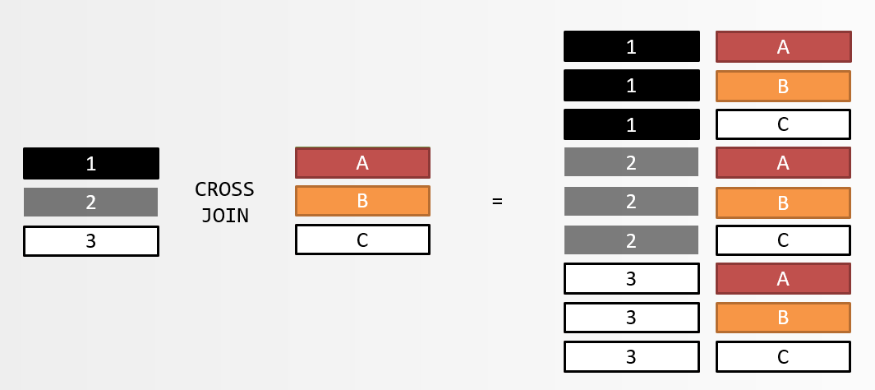
讲交叉连接之前了,我们先来看看笛卡尔积,假设我们两个集合,集合A={a, b},集合B={0, 1, 2},则A与B的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)},表示为AxB,也就是集合A中的任一元素与集合B的每个元素组合后的新集合则为A与B的笛卡尔积(AxB)。数学上的笛卡尔积反映到数据库中就是交叉连接(CROSS JOIN),结合上述的案例如下:
SELECT * FROM t_user CROSS JOIN t_login_log; -- 与 CROSS JOIN 得到的结果相同
-- 过时的写法,不符合 SQL标准,能读懂就好,不推荐使用
SELECT * FROM t_user, t_login_log;
t_user 中有 6 条记录, t_login_log 中有 11 条记录,t_user CROSS JOIN t_login_log 的结果是 66( 6 乘以 11) 条记录
交叉连接就是对两张表中的全部记录进行交叉组合,因此其结果是两张表的乘积,这也是为什么交叉连接无法使用内连接或外连接中所使用的 ON 子句的原因。交叉连接基本不会应用到实际业务之中,原因有两个,一是其结果没有实用价值,二是结果行数太多,需要花费大量的运算时间和硬件资源。虽说交叉连接的实际使用场景几乎没有,但还是有它的理论价值的,交叉连接是其他所有连接运算的基础,内连接是交叉连接的一部分,其结果是交叉连接的一部分(子集),外连接有点特殊,其结果包含交叉连接之外的内容;更多详情,我们接着往下看。
内连接
只返回两张表匹配的记录,就叫内连接,直观的表现就是关键字:INNER JOIN ... ON,ON 表示两张表连接所使用的列(连接键);而内连接中又属等值连接最常用
等值连接
简单点来说,就是连接键相等
-- 等值连接
SELECT * FROM t_user tu INNER JOIN t_login_log ttl ON tu.user_name = ttl.user_name; -- INNER JOIN 可以简写成 JOIN
SELECT * FROM t_user tu JOIN t_login_log ttl ON tu.user_name = ttl.user_name; -- 不加连接键, 结果与 CROSS JOIN 一样
SELECT * FROM t_user tu INNER JOIN t_login_log ttl
等值连接的结果中,每一条记录的连接键的列的值是想等的,如上图中的 user_name 和 user_name1(为了区别于第一个user_name,数据库系统自动取的别名,我们可以显示的指定)
不等值连接
连接键的比较谓词除了 = 之外的所有情况,比如 >、<、<>(!=);不等值连接使用场景比较少,反正我在实际工作中几乎没用到过
SELECT * FROM t_user tu INNER JOIN t_login_log ttl ON tu.user_name <> ttl.user_name;
SELECT * FROM t_user tu INNER JOIN t_login_log ttl ON tu.user_name > ttl.user_name;
自然连接
不需要指定连接条件,数据库系统会自动用相同的字段作为连接键,直观的表现就是关键字:NATURAL JOIN,NATURAL LEFT JOIN、NATURAL RIGHT JOIN;
连接键不直观,需要去看两张表中相同的字段有哪些;对于自然连接,了解即可,不推荐使用,反正我工作这么久,一次都没用过。
外连接
外连接的使用方式与内连接一样,也是通过 ON 使用连接键将两张表连接,从结果中获取我们想要的数据,但是返回的结果与内连接有区别,具体我们往下看
左连接
返回匹配的记录,以及左表多余的记录,关键字:LEFT JOIN(LEFT OUTER JOIN 的简写)
SELECT * FROM t_user tu LEFT OUTER JOIN t_login_log ttl ON tu.user_name = ttl.user_name;
-- LEFT JOIN 是 LEFT OUTER JOIN 的简写
SELECT * FROM t_user tu LEFT JOIN t_login_log ttl ON tu.user_name = ttl.user_name;
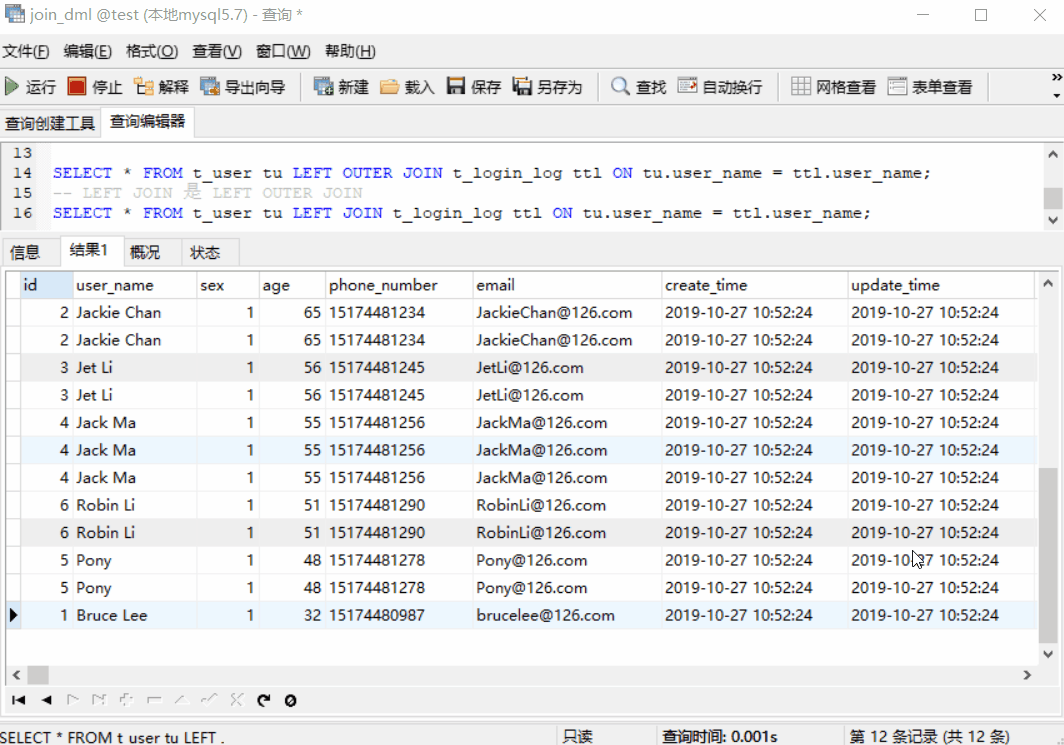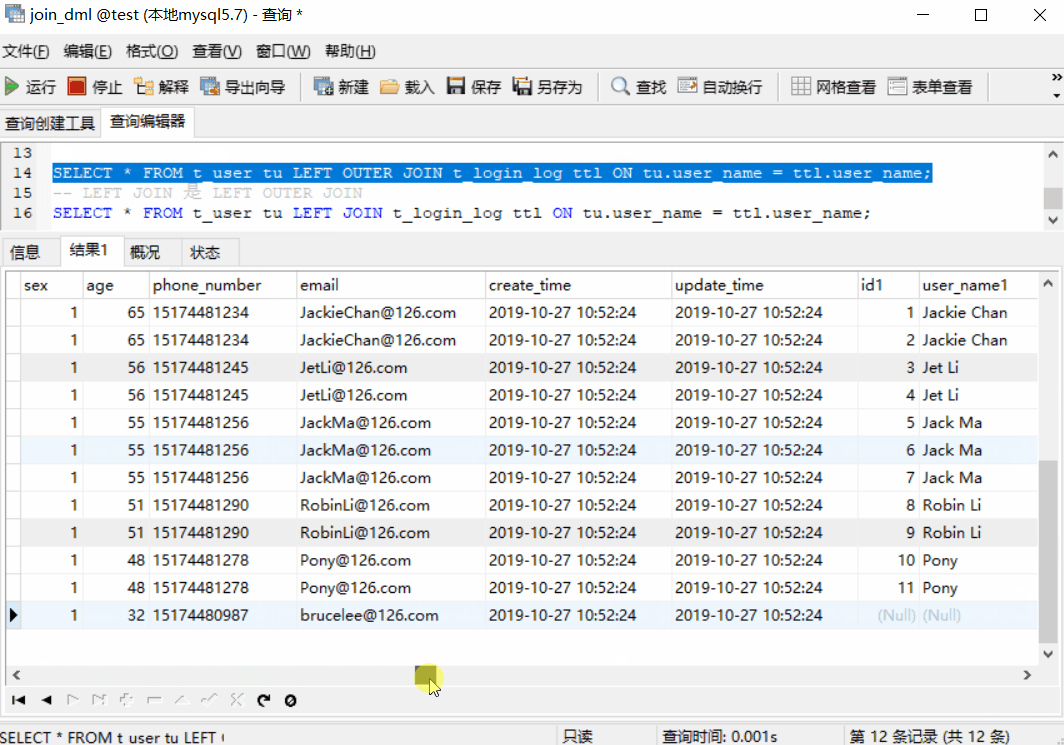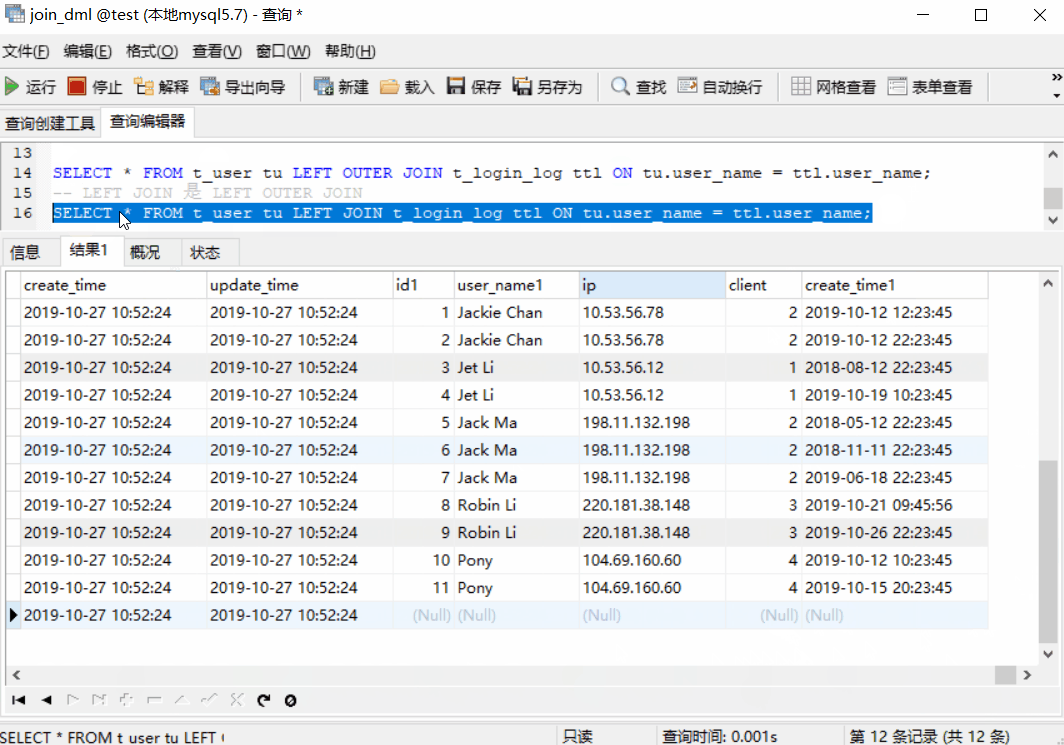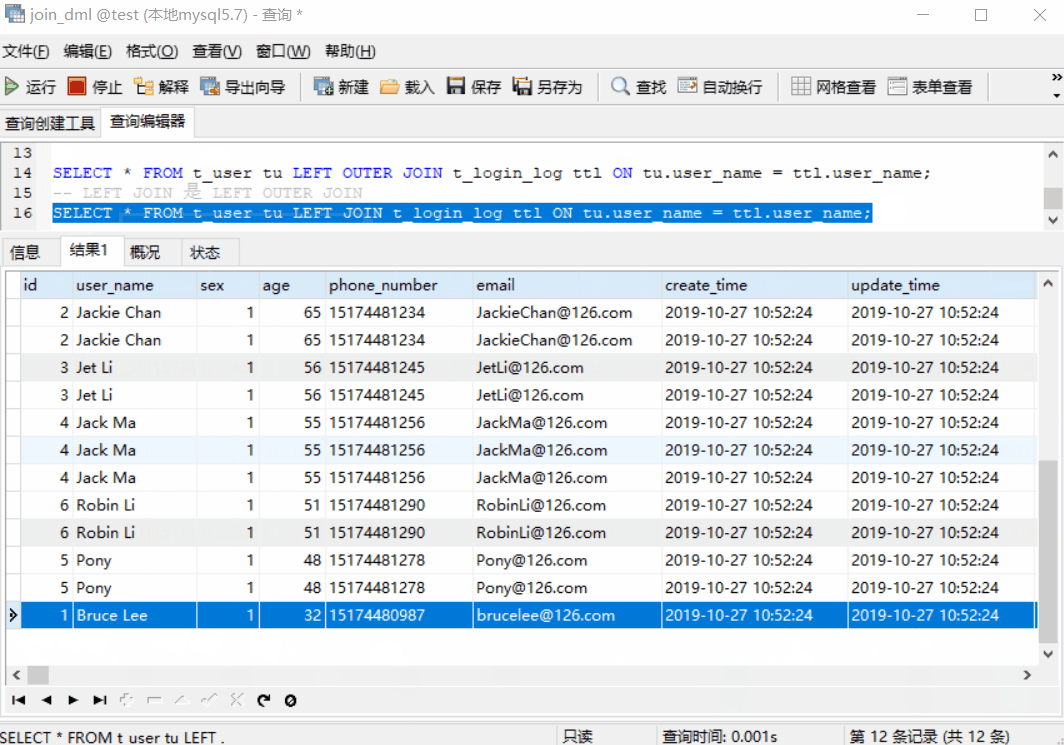
上图中,前 11 条记录是匹配的记录,而第 12 条是不匹配、左表的记录
右连接
返回匹配的记录,以及表 B 多余的记录,关键字:RIGHT JOIN(RIGHT OUTER JOIN 的简写)
SELECT * FROM t_login_log ttl RIGHT OUTER JOIN t_user tu ON tu.user_name = ttl.user_name;
-- RIGHT JOIN 是 RIGHT OUTER JOIN 的简写
SELECT * FROM t_login_log ttl RIGHT JOIN t_user tu ON tu.user_name = ttl.user_name;
由于我们习惯了从左往右(阅读方式、写作方式),因此在实际项目中,基本上用的都是左连接
全连接
返回匹配的记录,以及左表和右表各自的多余记录,关键字:FULL JOIN (FULL OUTER JOIN 的简写)
SELECT * FROM t_user tu FULL OUTER JOIN t_login_log ttl ON tu.user_name = ttl.user_name;
-- FULL JOIN 是 FULL OUTER JOIN 的简写
SELECT * FROM t_user tu FULL JOIN t_login_log ttl ON tu.user_name = ttl.user_name;
注意:MySQL 不支持 全连接,我们可以通过 左连接、右连接之后,再 UNION 来实现全连接
自连接
一张表,自己连接自己,简单点来理解就是,左表、右表是同一张表;连接方式可以是内连接、也可以是外连接
更多详情大家可以去看:项目上线后,谈一下感触比较深的一点:查询优化
需求:展示用户列表,并显示最近登录时间、最近登录 IP
对于此需求,大家会如何来写这个 SQL ? 也许大家很容易想到左连接,如下所示
SELECT * FROM t_user tu LEFT JOIN t_login_log ttl ON tu.user_name = ttl.user_name;
可结果如下:
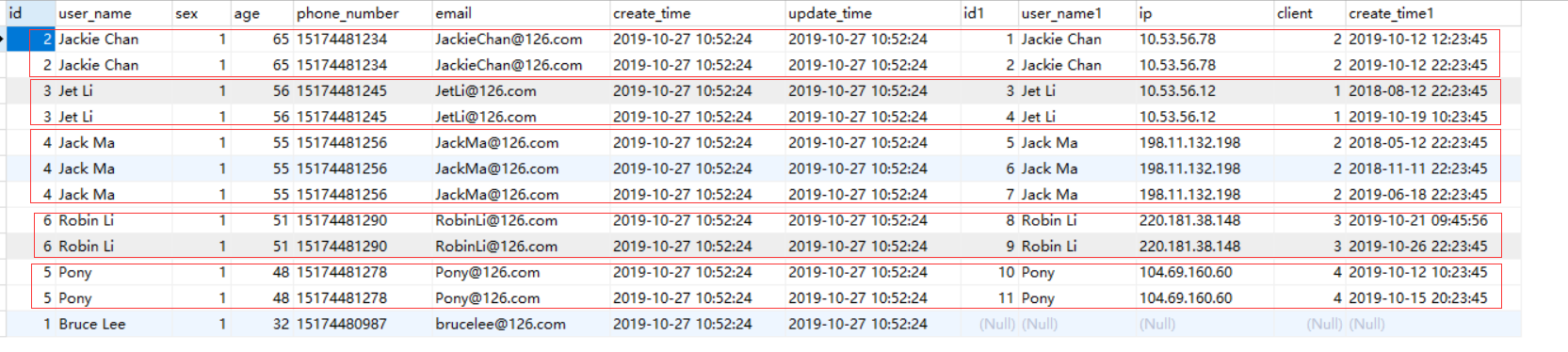
显示的是每个用户的所有登录日志,不是我们想要的结果;原因是 t_user 中的一条记录在 t_login_log 对应的记录有多种情况:0 条对应、1 条对应、多条对应,那这个 SQL 要怎么写呢,方式有多种,不局限于如下实现
-- 1、连接配合子查询,注意 Bruce Lee 从未登陆过
SELECT tu.user_name, tu.sex,tu.age, tu.phone_number,tu.email,tll.create_time,tll.ip
FROM t_user tu LEFT JOIN t_login_log tll ON tu.user_name = tll.user_name
WHERE tll.id = (SELECT MAX(id) FROM t_login_log WHERE user_name = tu.user_name) OR tll.user_name IS NULL; -- 2、t_login_log分组统计出各个用户的最近一次登录信息后,再与 t_user 联表
SELECT tu.user_name, tu.sex,tu.age, tu.phone_number,tu.email,tll.create_time,tll.ip
FROM t_user tu LEFT JOIN (
SELECT tb.* FROM(
SELECT user_name, MAX(id) id FROM t_login_log GROUP BY user_name
) ta LEFT JOIN t_login_log tb ON ta.id = tb.id
) tll ON tu.user_name = tll.user_name;
具体的实现还得结合具体的业务和需求来实现,那样才能写出高效的 SQL;另外结合执行计划来建立合适的索引。总之,没有一成不变的、通用的高效 SQL,结合具体的业务才能写出最合适的 SQL。
总结
1、连接的描述方式
常用的维恩图,描述如下

维恩图描述有他的优势,但它不好表示交叉连接,同时容易让人误解成 SQL 中的集合操作;这里推荐另外一种描述方式,我觉得描述的更准确
CROSS JOIN
常用 JOIN
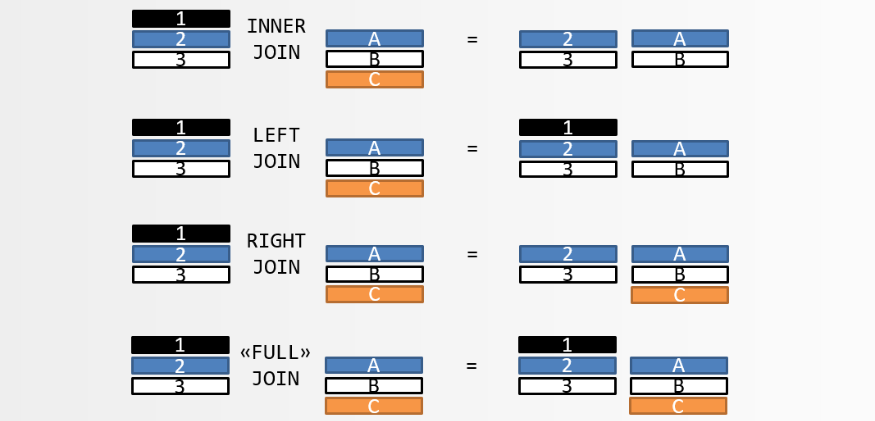
上图中,颜色表示匹配关系,颜色相同表示匹配。返回结果中,如果另一张表没有匹配的记录,则用 null 填充, 在上图中则表示为空白。
2、连接中 ON 指定连接键,连接键可以指定多个,而 WHERE 还是平时的作用,用来指定过滤条件;不推荐将连接键放于 WHERE 后;
3、实际工作中,用的最多的是 左连接 和 等值连接,其他的用的特别少
参考
《SQL基础教程》
《SQL进阶教程》
神奇的 SQL 之团结的力量 → JOIN的更多相关文章
- 神奇的 SQL 之 联表细节 → MySQL JOIN 的执行过程(二)
开心一刻 一头母牛在吃草,突然一头公牛从远处狂奔而来说:“快跑啊!!楼主来了!” 母牛说:“楼主来了关我屁事啊?” 公牛急忙说:“楼主吹牛逼呀!” 母牛大惊,拔腿就跑,边跑边问:“你是公牛你怕什么啊? ...
- 神奇的 SQL 之谓词 → 难理解的 EXISTS
前言 开心一刻 我要飞的更高,飞的更高,啊! 谓词 SQL 中的谓词指的是:返回值是逻辑值的函数.我们知道函数的返回值有可能是数字.字符串或者日期等等,但谓词的返回值全部是逻辑值(TRUE/FALSE ...
- 神奇的 SQL 之扑朔迷离 → ON 和 WHERE,好多细节!
开心一刻 楼主:心都让你吓出来了! 狮王:淡定,打个小喷嚏而已 前情回顾 神奇的 SQL 之 联表细节 → MySQL JOIN 的执行过程(一)中,我们讲到了 3 种联表算法:SNL.BNL 和 I ...
- 神奇的 SQL 之性能优化 → 让 SQL 飞起来
开心一刻 一天,一个男人去未婚妻家玩,晚上临走时下起了大雨 未婚妻劝他留下来过夜,说完便去准备被褥,准备就绪后发现未婚夫不见了 过了好久,全身淋的像只落汤鸡的未婚夫回来了 未婚妻吃惊的问:" ...
- sql之left join、right join、inner join的区别
sql之left join.right join.inner join的区别 left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录 right join(右联接) 返回包括 ...
- SQL中inner join、outer join和cross join的区别
对于SQL中inner join.outer join和cross join的区别简介:现有两张表,Table A 是左边的表.Table B 是右边的表.其各有四条记录,其中有两条记录name是相同 ...
- SQL的inner join、left join、right join、full outer join、union、union all
主题: SQL的inner join.left join.right join.full outer join.union.union all的学习. Table A和Table B表如下所示: 表A ...
- 把两个DataTable连接起来,相当于Sql的Inner Join方法
在C#中把两个DataTable连接起来,相当于Sql的Inner Join方法 作者:浪漫十一狼在下面的例子中实现了3个Join方法,其目的是把两个DataTable连接起来,相当于Sql的Inne ...
- paip.sql索引优化----join 代替子查询法
paip.sql索引优化----join 代替子查询法 作者Attilax , EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog.csdn.n ...
随机推荐
- 23 (OC)* 推送、APNS
1:APNS的推送机制 2:APNS推送通知的详细工作流程 3:准备工作 4:TCP长连接 5:消息格式 6:卸载后接受不到消息 1.APNS的推送机制 首先我们看一下苹果官方给出的对ios推送机制的 ...
- spring使用ehcache实现页面缓存
ehcache缓存最后一篇,介绍页面缓存: 如果将应用的结构分为"page-filter-action-service-dao-db",那page层就是最接近用户的一层,一些特定的 ...
- [VB.NET Tips]VB.NET专有的字符串处理函数
.NET Framework类库中含有专门为Visual Basic.NET程序员设计的函数和过程. 这些方法虽然是为VB.NET程序员设计的,但是也可以被.NET Framework上支持的任何语言 ...
- [Leetcode] 第307题 区域和检索-数组可修改
参考博客:(LeetCode 307) Range Sum Query - Mutable(Segment Tree) 一.题目描述 给定一个整数数组 nums,求出数组从索引 i 到 j (i ...
- 前台提交数据到node服务器(get方式)
.有两种办法,一种是表单提交,一种是ajax方式提交. 1.form提交 在前台模板文件上写: <form action="/reg" method="get&q ...
- Django REST Framework序列化器
Django序列化和json模块的序列化 从数据库中取出数据后,虽然不能直接将queryset和model对象以及datetime类型序列化,但都可以将其转化成可以序列化的类型,再序列化. 功能需求都 ...
- Scrapy项目 - 实现百度贴吧帖子主题及图片爬取的爬虫设计
要求编写的程序可获取任一贴吧页面中的帖子链接,并爬取贴子中用户发表的图片,在此过程中使用user agent 伪装和轮换,解决爬虫ip被目标网站封禁的问题.熟悉掌握基本的网页和url分析,同时能灵活使 ...
- Spring Data JPA 梳理 - 使用方法
1.下载需要的包. 需要先 下载Spring Data JPA 的发布包(需要同时下载 Spring Data Commons 和 Spring Data JPA 两个发布包,Commons 是 Sp ...
- Two progressions CodeForce 125D 思维题
An arithmetic progression is such a non-empty sequence of numbers where the difference between any t ...
- jenkins+ant构建项目时候build.xml需要改动的地方说明
上一节将build.xml文件代码列出来了,这一节给出说明,要想使用该文件,需要变更的地方有哪些.